- The paper introduces DocScope, a benchmark that evaluates verifiable reasoning trajectories in long-document multimodal QA using a structured four-stage protocol.
- It benchmarks six proprietary MLLMs and twelve state-of-the-art systems, revealing a pronounced gap between answer accuracy and complete evidence-chain verification.
- The study identifies fact extraction as the primary bottleneck and highlights the need for improved spatial grounding and evidence aggregation in long-document understanding.
DocScope: Auditing Verifiable Reasoning in Long-Document Multimodal QA
Motivation and Benchmark Design
The proliferation of Multimodal LLMs (MLLMs) in complex document processing naturally instigates a shift from conventional answer accuracy metrics toward rigorous verification of reasoning trajectories. "DocScope: Benchmarking Verifiable Reasoning for Trustworthy Long-Document Understanding" (2605.08888) addresses this critical requirement by introducing a benchmark that operationalizes long-document QA as structured reasoning trajectory prediction: given a full PDF document and a question, the system outputs explicit evidence pages, grounded regions, extracted atomic facts, and a final answer.
The DocScope framework implements a four-stage evaluation protocol—Page Localization, Region Grounding, Fact Extraction, and Answer Verification—each independently audited and decoupled, enabling granular diagnosis of failures at any stage. The evaluation protocol is illustrated below.
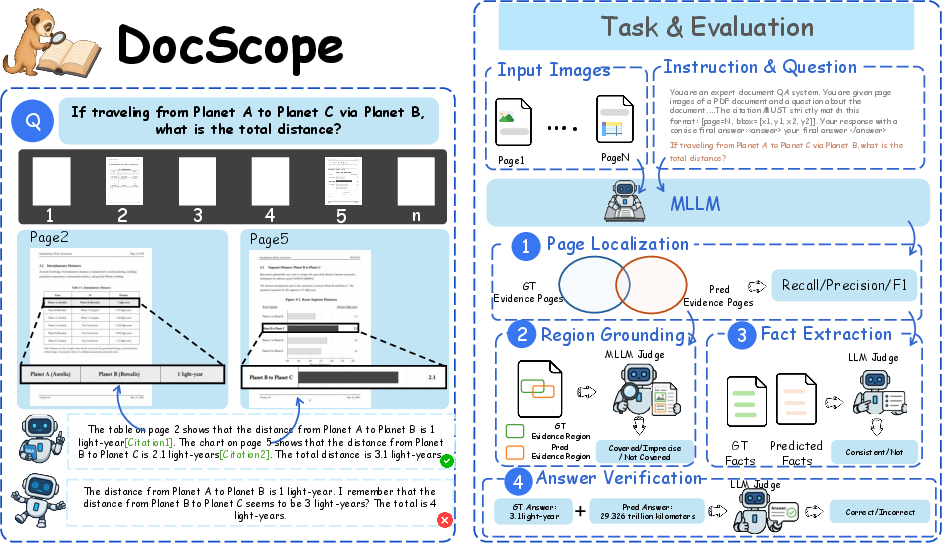
Figure 1: DocScope requires explicit evidence chains in responses and evaluates four reasoning trajectory levels: Page Localization, Region Grounding, Fact Extraction, and Answer Verification.
Dataset Construction and Evidence Hierarchy
DocScope comprises 1,124 QA instances sourced from 273 visually rich documents of substantial length (mean 51.3 pages per document). Questions are systematically generated with the assistance of advanced MLLMs to span eight distinct categories, including visual counting, structural extraction, numerical reasoning, procedural understanding, relational queries, semantic and temporal reasoning, and explicit unanswerable cases. Gold answers and hierarchical evidence annotations (pages, bounding boxes, factual statements) are provided by trained annotators.
A striking feature is DocScope's fully hierarchical evidence annotation protocol, enabling evaluation at progressively finer spectral levels. This hierarchy allows for decoupled, explicit assessment of whether claimed answers are both correct and verifiable via traceable evidence chains.
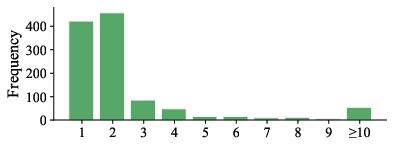
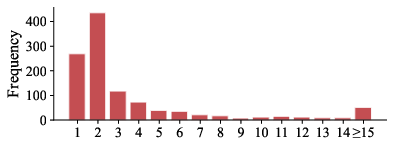
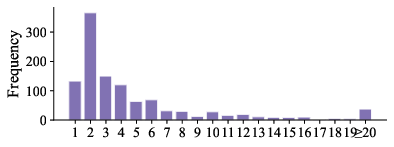
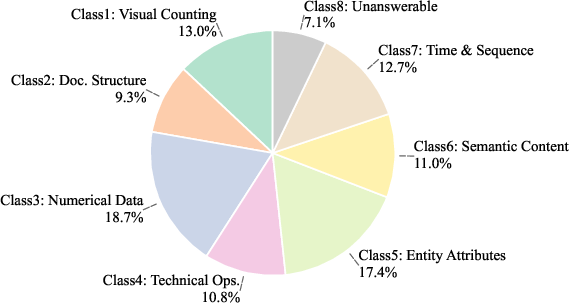
Figure 2: DocScope's evidence and fact annotation distribution: per-question evidence and fact counts exhibit considerable diversity, strongly challenging retrieval and grounding.
Structured Evaluation Protocol
For each QA-instance output (P,R,F,a), DocScope applies inter-stage decoupling:
- Page Localization: Micro-precision, recall, and F1 for exact page retrieval.
- Region Grounding: Multimodal LLM judge labels predicted regions as "covered," "imprecise," or "not_covered" for each gold region.
- Fact Extraction: Text-only judge labels each extracted fact as "consistent" or "not_consistent" w.r.t. ground truth.
- Answer Verification: Text-only judge checks semantic answer equivalence, tolerating surface variation but strictly penalizing missing or incorrect content.
These LLM judges are calibrated via rigorous human alignment studies, showing superior robustness and correlation with human annotation compared to rule-based geometric metrics.
Main Results and Model Comparison
Six proprietary MLLMs and twelve state-of-the-art open-weight or domain-specific systems are benchmarked. While best-in-class proprietary models achieve moderate answer accuracy (max 78.9%), they exhibit a pronounced decoupling between answer correctness and evidence-chain completeness; e.g., Gemini 3.1 Pro attains only 39.7% strict region F1 despite leading in answer accuracy.
Region Grounding emerges as the weakest stage, with substantial F1 drops relative to page localization—over 40 percentage points for most models. Notably, even among correctly answered samples, complete evidence chains are present in only 29% of cases, underscoring substantial unreliability in reasoning trace verifiability. Additionally, the analysis reveals that the number of activated parameters dominates model trajectory performance far more than total parameter scale or architecture family.
Evidence Distribution and Trajectory Difficulty
Answer accuracy declines sharply as evidence becomes more dispersed. DocScope quantifies this along three axes: evidence page count, maximum adjacent page gap, and number of disconnected clusters.
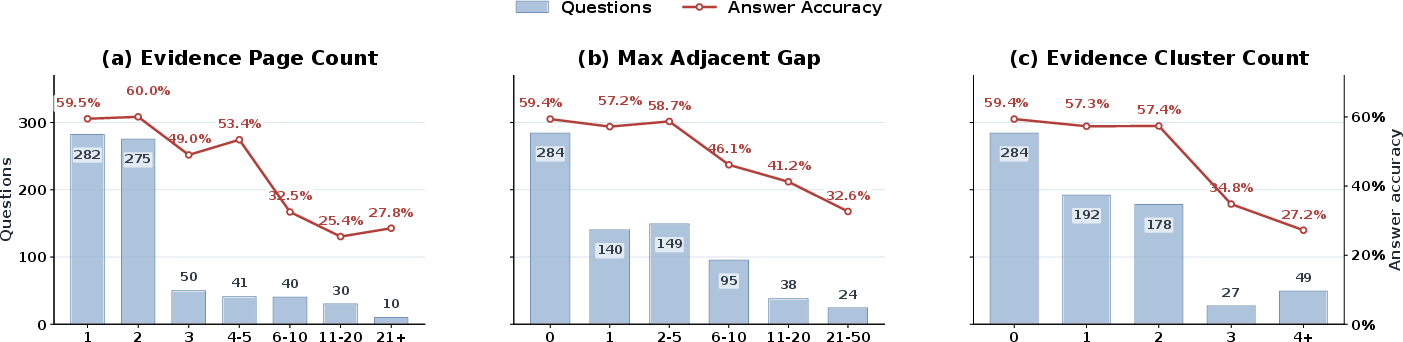
Figure 3: Accuracy sharply decreases as evidence is distributed across more pages, separated by larger gaps, and fragmented into more clusters.
Models are particularly challenged by questions requiring retrieval and aggregation of evidence across separated, long-context spans—a scenario largely bypassed in benchmarks with fixed evidence-pools or pre-retrieval settings. This finding motivates architectural advances in context management and long-range retrieval.
Oracle Evidence Access and Bottleneck Identification
A comprehensive Oracle Evidence Access Study concretely identifies bottlenecks in the reasoning pipeline. Supplying gold evidence pages, regions, and atomic facts incrementally, it is observed that fact extraction, not region grounding, is the primary limiting factor in answer accuracy. Even when provided with oracle facts, significant gaps persist, indicating that intrinsic reasoning capacity remains a critical bounding constraint.
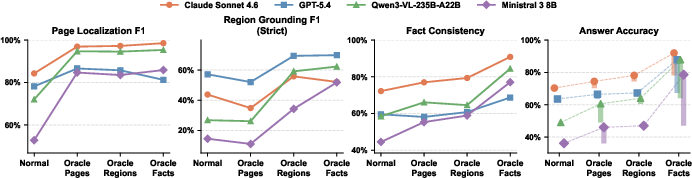
Figure 4: Fact extraction is the main bottleneck affecting answer accuracy when removing demands on evidence retrieval and grounding.
Strategy shifts are observed under oracle settings: models transition from conservative bounding regions to aggressive localization, typically leading to mislocalized but smaller boxes.
Error Taxonomy and Stage-Specific Failure Modes
Manual error analysis reveals distinct stage-wise failure patterns across nearly 200 sampled errors. Early-stage failures are dominated by evidence location errors, whereas fact extraction errors primarily result from perceptual failures such as misreading tables or charts. Final answer-stage errors usually derive from question misinterpretation or calculation mistakes.
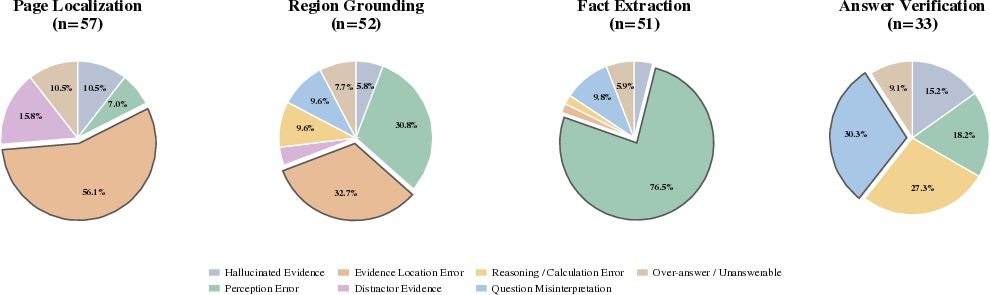
Figure 5: Distribution of error types by trajectory stage, highlighting shifting bottlenecks from localization to perception and reasoning.
Theoretical and Practical Implications
DocScope establishes evidence-chain verifiability as an indispensable audit for trustworthy document QA. It reveals fundamental limits in current MLLM reasoning reliability, especially regarding spatial grounding and factual extraction. The pronounced gap between answer accuracy and evidence-chain completeness mandates trajectory-level evaluation protocols for real-world deployment. For practical applications—education, legal, finance, and healthcare—DocScope's audit trail ensures responses are not only plausible but auditable, mitigating hallucination and error propagation.
Theoretically, the distinction between accurate answers and verifiable reasoning trajectories necessitates new architectural targets: robust region localization, enhanced perceptual precision, and explicit evidence aggregation over long contexts. Oracle studies and strategy-shift analyses suggest that future developments must balance conservative over-covering with targeted retrieval, all while retaining factual integrity. Continued research will likely focus on trajectory consistency metrics, hybrid retrieval-augmented architectures, and multimodal perception improvements.
Conclusion
DocScope represents a rigorous benchmark for fine-grained diagnosis of reasoning trajectories in long-document QA, uniquely exposing deficiencies in evidence-chain reliability among modern MLLMs. Its decoupled, stage-wise evaluation protocol demonstrates that answer accuracy is insufficient; only explicit, verifiable evidence chains confer trustworthy auditing. These findings are expected to catalyze architectural advances and more transparent evaluation practices in multimodal document understanding systems.

