- The paper presents DailyClue, a benchmark designed to isolate and evaluate visual clue-driven reasoning capabilities in MLLMs across everyday scenarios.
- It demonstrates that even state-of-the-art models rarely surpass 60% accuracy, highlighting deficiencies in evidence extraction and chain-of-thought reasoning.
- The study emphasizes the necessity for clue-grounded training and reveals the current limitations of agentic tool integration in advancing multimodal reasoning.
Seek-and-Solve: Benchmarking Visual Clue-Driven Reasoning in Multimodal LLMs
Motivation and Benchmark Design
The paper presents DailyClue, a benchmark aimed at isolating and rigorously evaluating the visual clue-driven reasoning capabilities of Multimodal LLMs (MLLMs). Existing VQA and multimodal benchmarks primarily assess perception and factual retrieval, with reasoning tasks often confounded by reliance on memorized priors or direct textual cues. DailyClue directly targets the bottleneck of visual reasoning: models must actively filter rich, noisy daily-life scenes to identify decisive visual evidence and employ it within a chain-of-thought (CoT) process.
The benchmark features four core domains—location identification, spatial relationship reasoning, daily commonsense reasoning, and scientific commonsense reasoning—spanning sixteen subtasks and 666 curated question-clue-answer triplets. Generation is model-assisted but strictly human-verified, and filtering employs consensus rejection among multiple top-tier MLLMs and rigorous manual review. The difficulty is calibrated such that all questions require deduction via visual clues rather than superficial inspection or world knowledge.
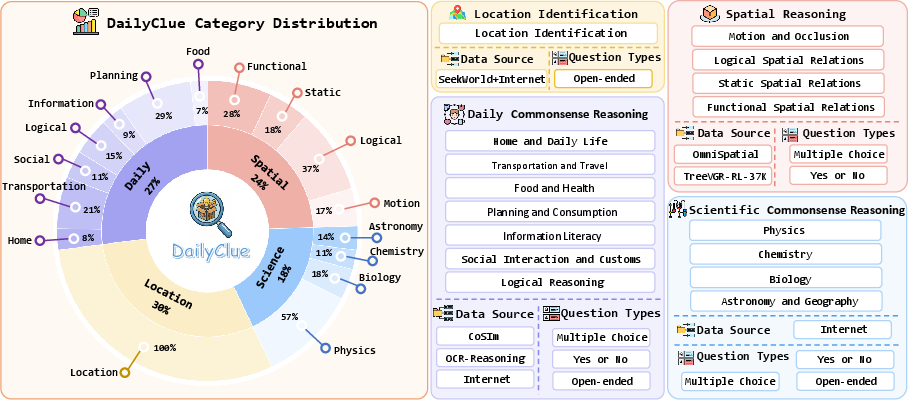
Figure 1: DailyClue's hierarchical taxonomy, scenario distribution, and data sources, illustrating full coverage across daily reasoning subtasks.
Construction Pipeline and Task Examples
The pipeline comprises three stages: (1) image collection from diverse sources, prioritizing visual richness and common daily scenarios; (2) GPT-5 and Gemini-2.5-Pro are used to synthesize candidate triplets, with prompt engineering ensuring requirement for indirect reasoning; (3) filtering by peer model consensus and expert annotators, rejecting trivial and hallucinated samples.
In Spatial Relationship Reasoning, system/user prompts target indirect occlusion or motion questions. For Scientific Commonsense, questions are designed around scenarios where external domain knowledge is insufficient and deduction requires precise visual semantic extraction. A subset of qualitative examples underscores that even tasks trivial for humans pose significant reasoning challenges for MLLMs due to the need for clue localization and integration.
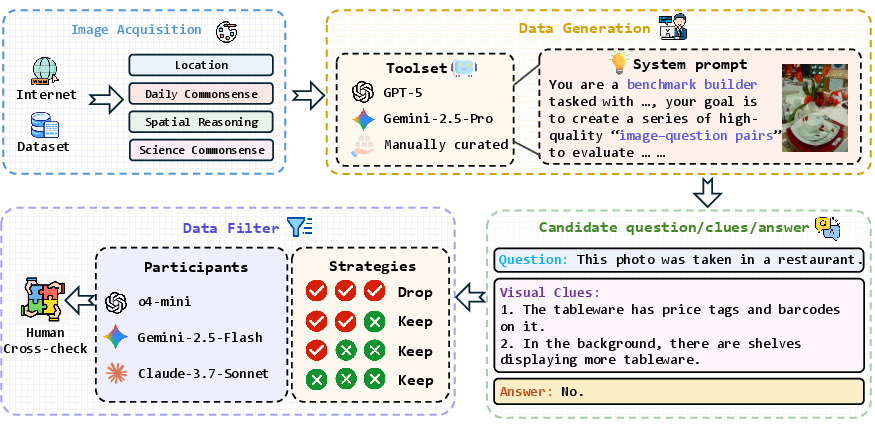
Figure 2: DailyClue construction pipeline detailing staged data sourcing and filtering.

Figure 3: DailyClue scenario examples highlighting non-trivial reasoning tasks and visual complexity.
Experimental Results and Analysis
Twenty-five MLLMs (open, closed, and agentic/tool-based) are benchmarked, alongside a human baseline (undergraduate annotators), employing both General and Rigorous Evaluation Protocols. The latter demands not only answer correctness but explicit intersection between model-extracted and ground-truth visual clues.
Key findings:
Visual Clue Injection and Chain-of-Thought Ablations
Explicit injection of high-quality visual clues markedly improves reasoning accuracy across all models. Conditioning Gemini-2.5-Pro and Claude-3.7 on ground-truth clues increases accuracy by +1.65% and +14.86%, respectively. However, conditioning on inferior clues (e.g., from Qwen2.5-VL-72B) degrades performance by ~4%, demonstrating textual bias and visual sycophancy: MLLMs favor injected textual context over intrinsic visual perception, which may induce incorrect reasoning trajectories.
Chain-of-thought ablation reveals that enforcing active clue extraction within reasoning—rather than vanilla CoT or direct answering—consistently boosts accuracy. Clue-guided CoT acts as an anchoring constraint, mitigating reasoning drift and hallucination.
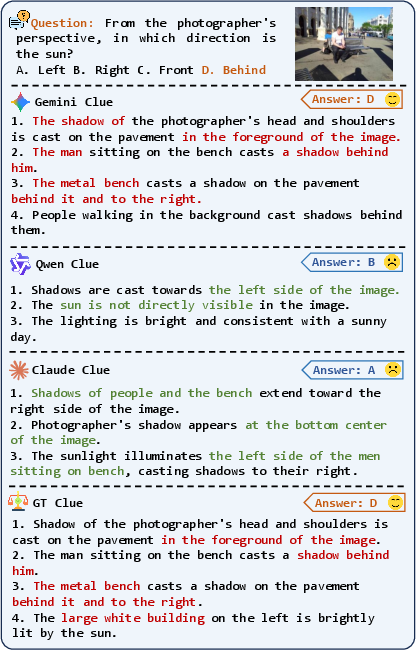
Figure 5: Answer generation under different clue contexts, illustrating the impact of clue source quality.
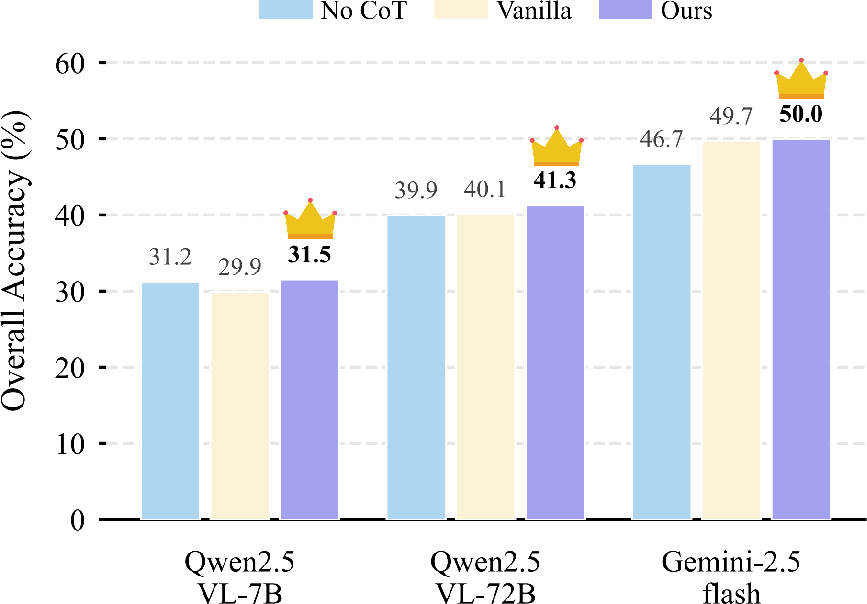
Figure 6: Visual clue-guided CoT reasoning consistently improves accuracy across MLLMs.
Rigorous Evaluation Findings
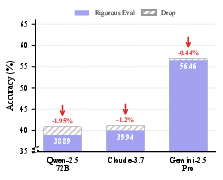
Rigorous Evaluation underlines the instability of reasoning pathways: models often arrive at correct answers via illusionary or irrelevant clues, i.e., "right for the wrong reason." Accuracy drops are modest for top models (Gemini-2.5-Pro: -0.44%), but more substantial for others (Qwen2.5-VL-72B: -1.95%), indicating residual reliance on superficial or confounded evidence. Qualitative visualization reaffirms that Rigorous Evaluation is essential for distinguishing genuine reasoning from random guessing.
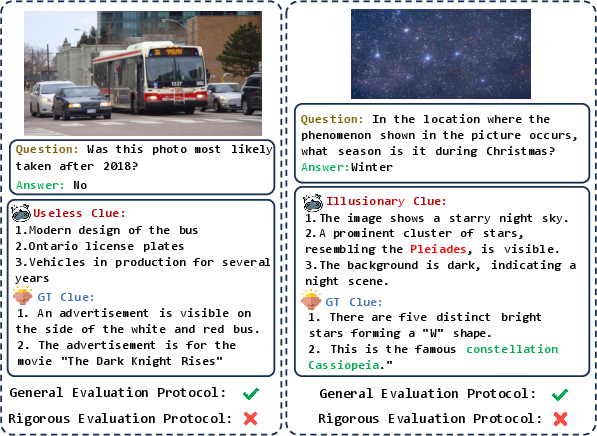
Figure 7: Visualizations of clues used by MLLMs under rigorous protocol, exposing illusionary and useless reasoning anchors.
Implications and Future Directions
DailyClue exposes both strengths and persistent deficiencies in multimodal reasoning. Accurate visual clue extraction is presently the primary bottleneck, with even large proprietary models (e.g., Gemini-2.5-Pro, GPT-5) failing to saturate benchmark accuracy. The findings emphasize:
- Necessity for Clue-Grounded Training: Further pretraining and fine-tuning explicitly targeting clue grounding, and architectural innovations that reduce textual bias and sycophancy, are required.
- Agentic Integration Limits: Current tool-use augmentation does not sufficiently overcome clue extraction weaknesses; future multimodal agents must improve active visual exploration, multi-step evidence aggregation, and adaptive tool employment in complex daily scenarios.
- Benchmark Utility: DailyClue's moderate scale, rich scenario complexity, and rigorous construction make it a discriminative platform for cross-family and cross-paradigm evaluation.
Future research should expand scenario diversity, volume, and incorporate dynamic video-based reasoning. Addressing textual bias, evidence hallucination, and compositional reasoning fidelity will be pivotal for next-generation multimodal agentic intelligence.
Conclusion
DailyClue establishes a new standard for clue-driven visual reasoning evaluation in daily scenarios, revealing substantial gaps in current MLLM performance, particularly in evidence localization. Benchmark results clearly demonstrate that robust reasoning in complex environments is contingent upon accurate clue identification and grounded CoT processes; improving these mechanisms should be a central focus for forthcoming multimodal model research and development.