- The paper introduces Double-Bench, a novel benchmark that addresses deficiencies in current document RAG evaluations through realistic, multi-hop query synthesis.
- It demonstrates rigorous performance comparisons across embedding models and RAG frameworks, underscoring retrieval accuracy as the primary bottleneck.
- Results reveal overconfidence in complex agents versus cautious abstention in simpler pipelines, emphasizing the need for trustworthy and robust RAG systems.
Rigorous Evaluation of Document Retrieval-Augmented Generation: The Double-Bench Benchmark
Introduction
The paper "Are We on the Right Way for Assessing Document Retrieval-Augmented Generation?" (2508.03644) addresses critical deficiencies in the evaluation of Retrieval-Augmented Generation (RAG) systems, particularly those leveraging Multimodal LLMs (MLLMs) for complex document understanding. Existing benchmarks are shown to be inadequate for realistic, fine-grained assessment due to limited scope, unrealistic prior knowledge assumptions, ambiguous evidence, and poorly constructed multi-hop queries. The authors introduce Double-Bench, a large-scale, multilingual, multimodal benchmark designed to overcome these limitations and provide a comprehensive evaluation framework for document RAG systems.
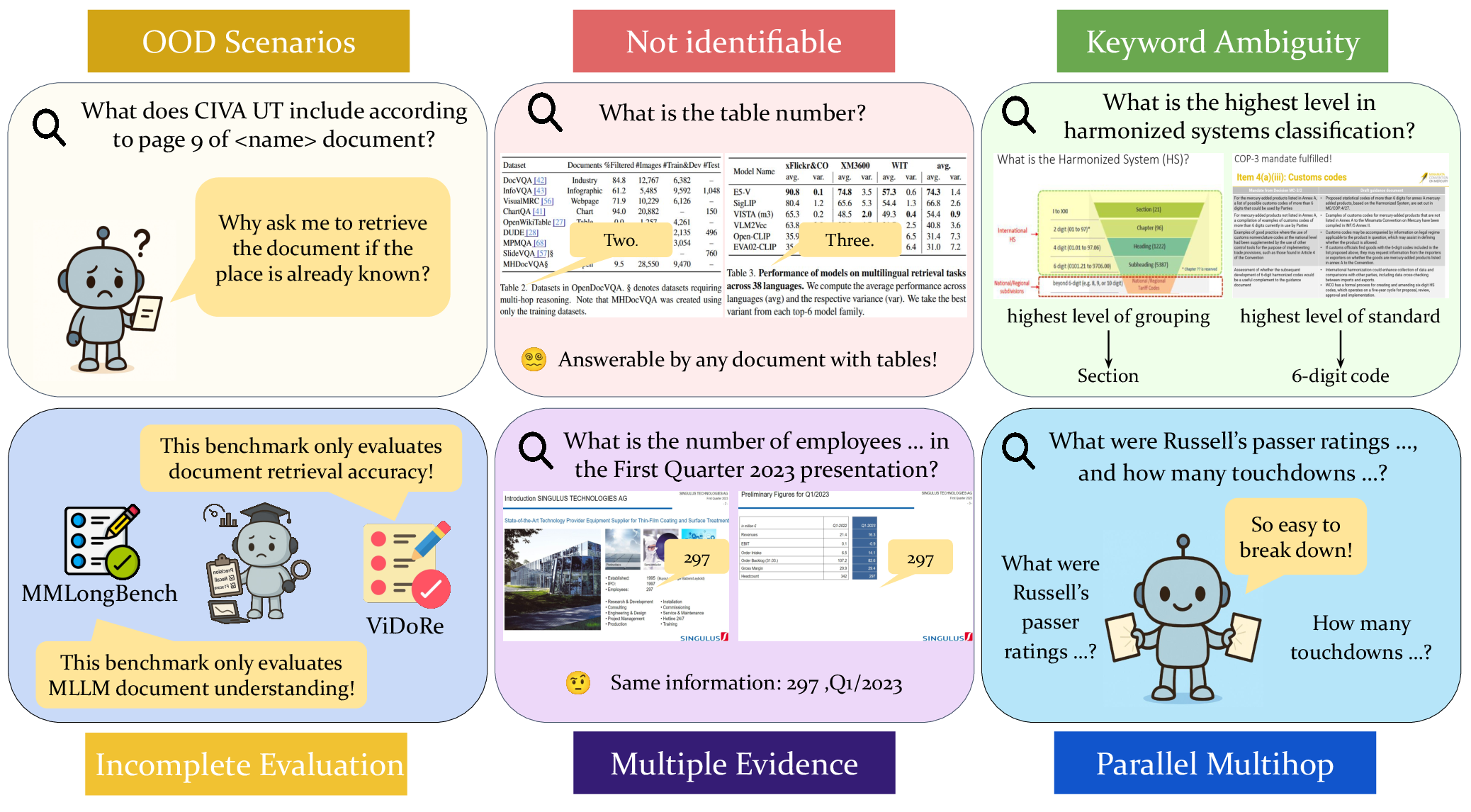
Figure 1: Existing document RAG benchmarks suffer from ambiguous queries and insufficient evidence specification, failing to authentically evaluate retrieval models and systems.
Limitations of Existing Benchmarks
The pilot study conducted by the authors reveals four major issues in current document RAG benchmarks:
- Fragmented Evaluation Scope: Most benchmarks focus on isolated components (e.g., embedding or VQA models) rather than the full RAG pipeline, obscuring interaction effects between retrieval and generation.
- Unrealistic Prior Knowledge: Many benchmarks assume the target document or page is known, which is not representative of real-world retrieval scenarios.
- Ambiguous or Non-Unique Evidence: Synthetic queries often map to a single page, ignoring cases where multiple pages are relevant, especially in large corpora.
- Trivial Multi-Hop Query Construction: Multi-hop queries are frequently constructed by loosely connecting single-hop queries, failing to evaluate genuine multi-step reasoning.
These limitations result in benchmarks that do not reflect the true challenges faced by document RAG systems in practical deployments.
Double-Bench: Benchmark Design and Construction
Double-Bench is constructed through a multi-stage pipeline that ensures diversity, realism, and high-quality annotation:
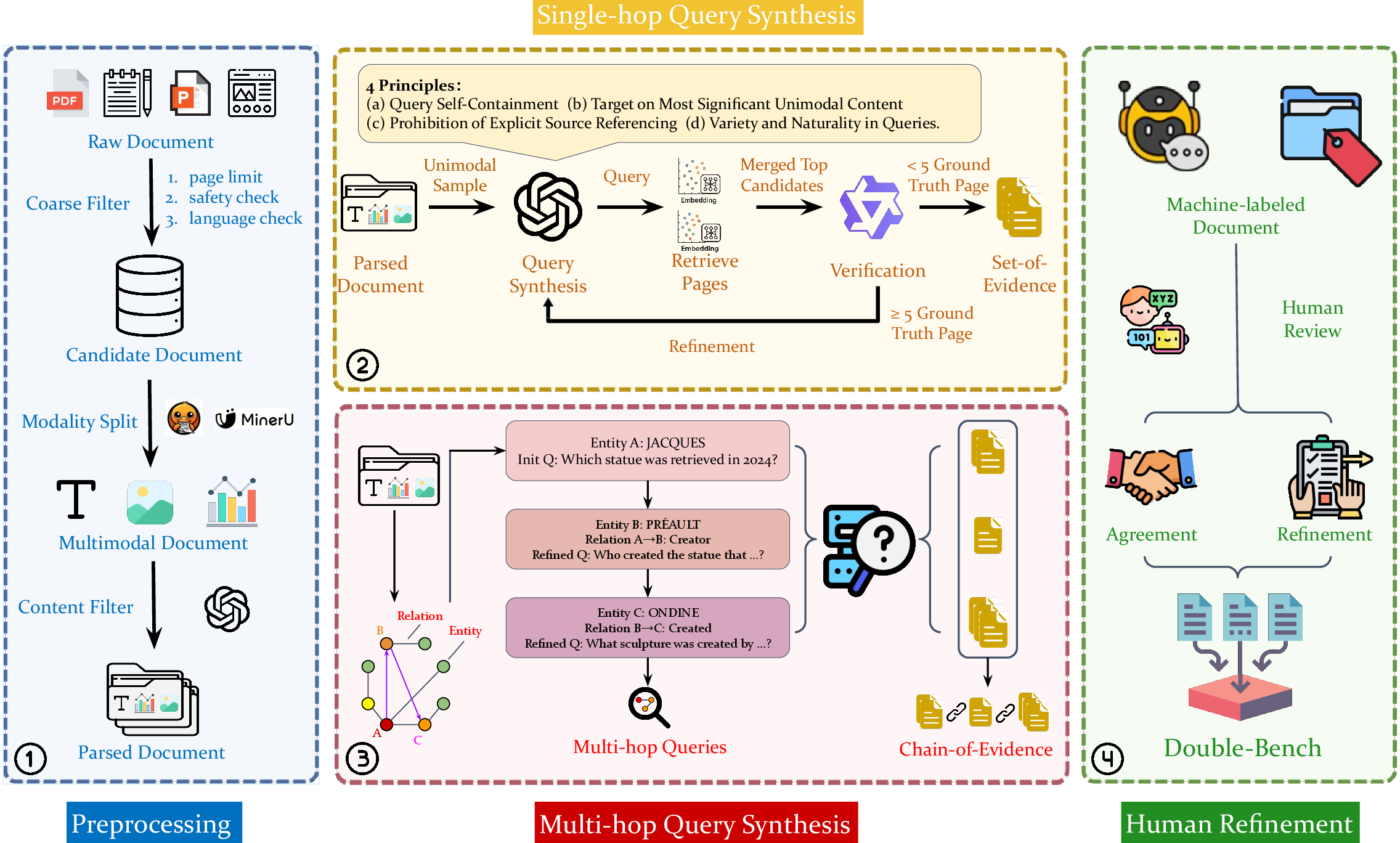
Figure 2: Overview of the Double-Bench construction pipeline, including corpus filtering, modality decomposition, iterative query refinement, knowledge graph-based multi-hop synthesis, and expert annotation.
Experimental Evaluation
Double-Bench enables rigorous comparison of nine state-of-the-art embedding models (textual, visual, and multimodal). Notably, the gap between text and visual embedding models is narrowing, with Colqwen2.5-3B achieving a hit@5 score of 0.795, outperforming general multimodal models. Text embedding models, such as Qwen3-Embedding-4B, demonstrate competitive performance, especially in low-resource languages (e.g., Arabic, Japanese), highlighting the challenge of generalizability for multimodal models.
RAG Frameworks and MLLMs
Four advanced document RAG frameworks (MDocAgent, ViDoRAG, M3DocRAG, Colqwen-gen) are evaluated. Retrieval accuracy is shown to be the primary bottleneck, with answer accuracy strongly correlated to retrieval performance. Colqwen-gen, a simple pairing of the strongest embedding model with GPT-4o, matches or exceeds more complex agentic frameworks on multi-hop queries, indicating that retrieval optimization is more impactful than elaborate answer synthesis pipelines.
MLLMs exhibit low accuracy on long document understanding tasks, especially for multi-hop queries, even when provided with ground truth pages. Oracle experiments (direct evidence provision) reveal substantial accuracy improvements, validating the benchmark's ability to distinguish context-grounded reasoning from model memorization.
Overconfidence and Trustworthiness
A critical finding is the "overconfidence dilemma" in current RAG frameworks: complex agents tend to answer every query regardless of evidence sufficiency, leading to hallucinated or speculative content. Simpler agents abstain when retrieval fails, trading off answer coverage for trustworthiness. This highlights the need for evaluation protocols and system designs that reward epistemic humility and reliable abstention.
In-Depth Analysis
- Language and Modality Coverage: Double-Bench provides fine-grained analysis across languages, document types, and modalities. Retrieval and answer accuracy are higher for high-resource languages and structured documents (PDFs, HTML), while scanned documents and low-resource languages remain challenging.
- Multi-Hop Reasoning Patterns: MLLMs do not process multi-hop queries sequentially; instead, they aggregate signature information and perform inclusion-based elimination, challenging the assumption that increasing hops linearly increases difficulty.
- Efficiency: Agentic frameworks incur significant inference latency due to sequential coordination, whereas simpler pipelines are more time-efficient.
Implications and Future Directions
Double-Bench establishes a new standard for evaluating document RAG systems, enabling:
- Holistic System Assessment: Fine-grained breakdown of retrieval and generation components, supporting targeted optimization.
- Robustness and Trustworthiness: Evaluation protocols that penalize overconfident, hallucinated answers and reward reliable abstention.
- Generalizability: Multilingual and multimodal coverage exposes limitations in current models, motivating research into more robust embedding and retrieval strategies.
- Dynamic Benchmark Updates: Support for streamlined updates mitigates data contamination and ensures ongoing relevance.
Future research should focus on developing retrieval models that better exploit document structure and semantics, integrating interleaved multimodal embeddings, and designing RAG frameworks that balance answer coverage with trustworthiness. Evaluation metrics must evolve to reflect not only accuracy but also the ability to identify and communicate informational gaps.
Conclusion
Double-Bench provides a rigorous, large-scale, multilingual, and multimodal benchmark for document RAG systems, addressing critical limitations in prior evaluation methodologies. Experimental results reveal persistent bottlenecks in retrieval accuracy, narrowing modality gaps, and systemic overconfidence in answer generation. The benchmark's open-source release and dynamic update capability lay a robust foundation for future research in advanced document retrieval-augmented generation, with implications for both practical deployment and theoretical advancement in AI.