- The paper presents PaperScope, a benchmark for agentic research that integrates text, figures, tables, and algorithms across diverse scientific documents.
- It employs a knowledge-graph-based sampling and an optimized random-walk method to generate over 2,000 QA pairs with robust multi-modal dependencies.
- Experimental results reveal challenges in multi-source reasoning and tool integration, with top models scoring 40.95 and performance drops up to 81.7% without multi-modal cues.
PaperScope: A Multi-Modal Multi-Document Benchmark for Agentic Deep Research Across Massive Scientific Papers
Motivation and Benchmark Scope
PaperScope addresses a critical gap in the evaluation of agentic deep research systems—specifically, the lack of rigorous, realistic benchmarks for multi-modal, multi-document scientific reasoning. Existing evaluations remain predominantly single-document and unimodal, falling short of capturing the complexity of legitimate research workflows that involve integration of text, tables, figures, formulas, and algorithms across heterogeneous sources. PaperScope is constructed to facilitate robust measurement of large agents’ capacity for end-to-end scientific research tasks, supporting four meta-task categories: Topic Induction, Multi-Document Reasoning, Summarization, and Solution Generation, with strong emphasis on multi-source retrieval, multi-hop inference, and modality fusion.
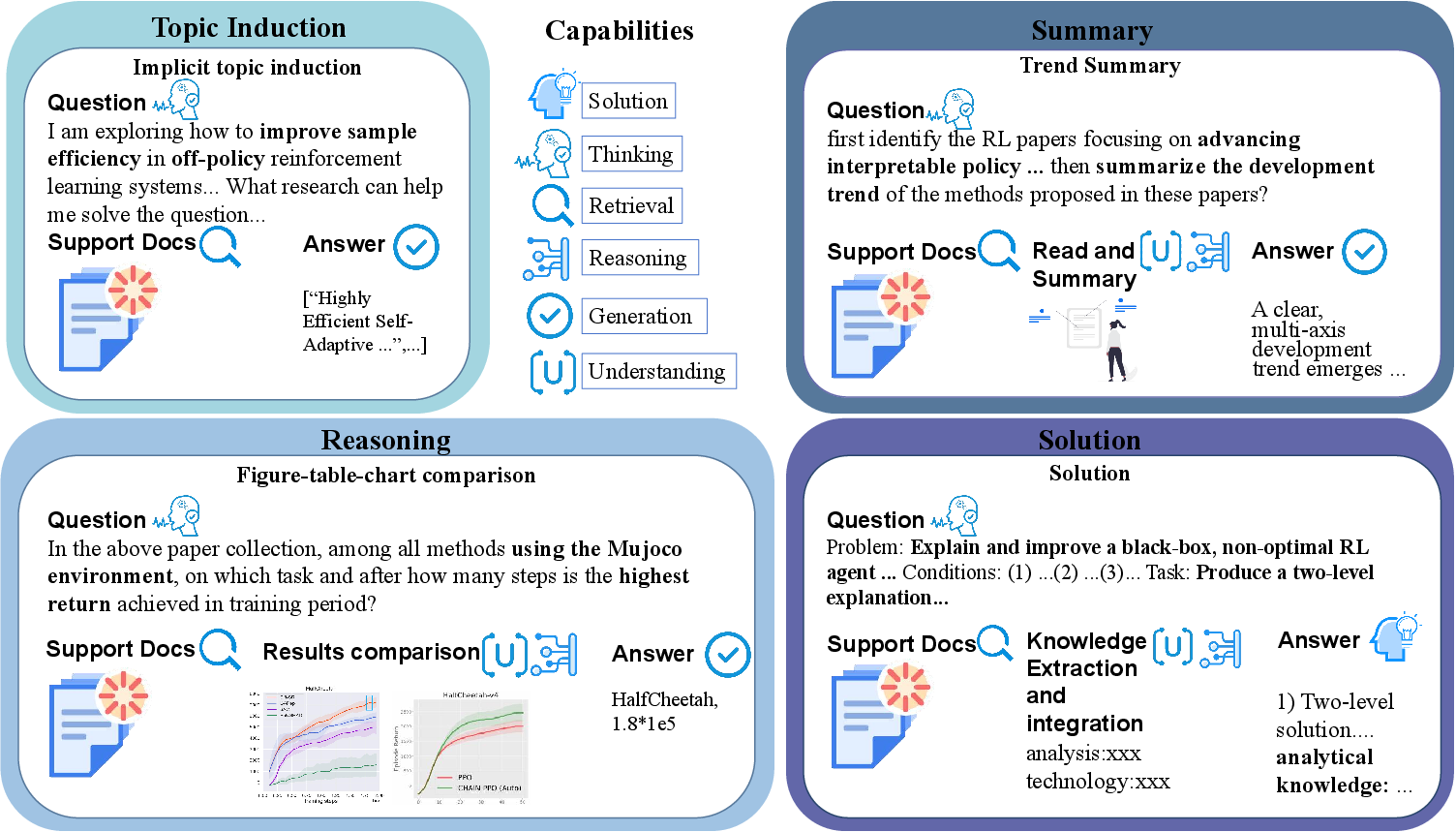
Figure 1: Sub-task illustrations from four meta-tasks are shown, with task stages requiring multi-modal reasoning, retrieval, and synthesis across scientific documents.
Benchmark Construction and Methodology
PaperScope’s construction is grounded in a knowledge-graph-based selection framework. The corpus draws from 25,495 AI papers (arXiv and OpenReview, 2023–2025), rigorously filtered for quality and representativeness. Key information is extracted from each paper, forming nodes for a heterogeneous semantic graph—including title, methods, results, figures, tables, algorithms, metrics, and limitations. Cross-paper connectivity is determined via semantic similarity using high-dimensional (~4096d) embeddings, yielding large graphs (e.g., ~30,000 nodes, ~2M edges per corpus) that capture entity-level overlap.
Document clusters are synthesized into candidate task sets using the Optimized Random-Walk Article Selector (ORWAS), a stratified and bias-adjustable random walk procedure ensuring semantic density, diversity, and unique solution paths. This construction yields over 2,000 QA pairs with strictly enforced answer uniqueness and high multi-modal dependence. Annotation relies on an inverted construction paradigm, minimizing open-world ambiguity, and is validated through multi-stage expert and AI auditing. Key evidentiary cues are carefully placed primarily in non-textual modalities to prevent shortcut exploitation.
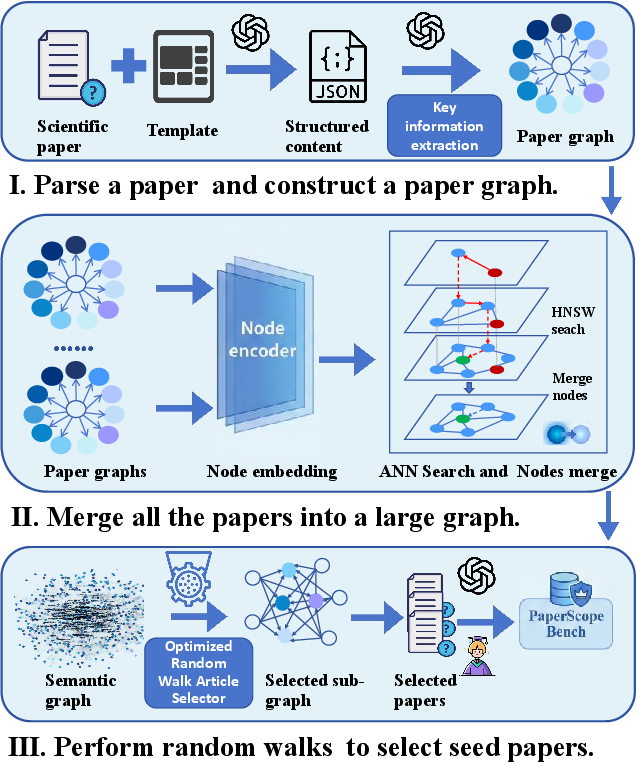
Figure 2: Schematic overview of the hierarchical semantic graph construction and optimized sampling process utilized in PaperScope.
Task Design and Multi-Modal Challenge
PaperScope’s QA set spans 11 sub-tasks covering:
- Reasoning: Cross-paper integration of heterogeneous evidence (figures, tables, algorithms, formulas, full-text synthesis).
- Topic Induction: Both explicit and implicit topic queries requiring corpus-level retrieval and theme identification.
- Summarization: Generation of trend, method, and comparative summaries across multi-source input.
- Solution Generation: Synthesis of actionable, grounded solutions using multi-document, multi-modal evidence.
Tasks are designed such that text-only ablations trigger up to 81.7% average performance drop, confirming genuine multi-modal dependency. Multi-document support is intrinsic: a large fraction (>58%) of questions require 3+ support documents.
Experimental Evaluation and Observations
PaperScope evaluates two major agent classes: MLLM-based ReAct agents and specialized Deep Research agents (16 systems total). Agents operate with both Local FileSearch and FileVisit tools, enabling joint high-resolution document and image parsing. Task performances are measured with tailored metrics: Recall@K for induction, Exact Match (EM) for reasoning, hybrid GPT-5 evaluation for summarization, and structured analysis/technology scores for solution generation.
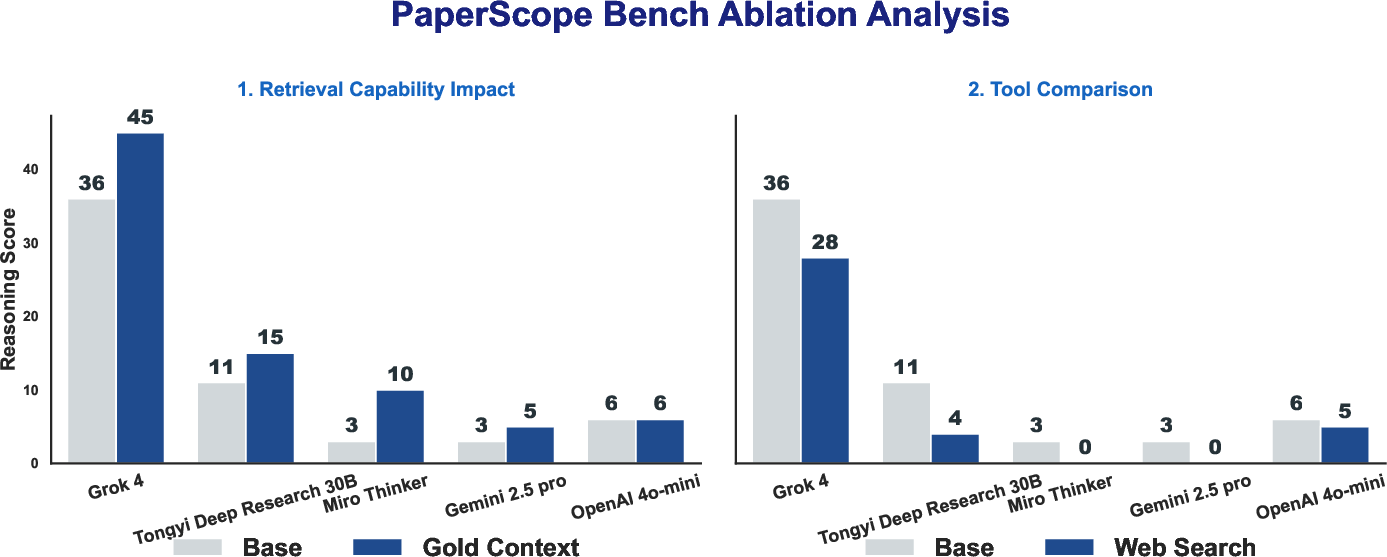
Figure 3: Ablation analysis demonstrates the dominant effect of reasoning complexity compared to retrieval, with large gaps even when golden documents are provided.
Results across categories exhibit the following:
- Reasoning remains the primary bottleneck: SOTA models including Grok-4 and OpenAI deep research agents attain limited scores (Best: 40.95 for Grok-4) on Reasoning and Solution tasks, indicating major limitations in cross-modal fusion, logical decomposition, and alignment robustness.
- ReAct models are competitive on Summarization: Models such as Kimi k2 and DeepSeek-V3.1 achieve higher scores on summary-type tasks, but significantly underperform on multi-resource reasoning and solution generation.
- Tool-calling reliability is critical: Deep research agents perform strongly when tool invocation is stable but degrade rapidly otherwise, pointing to brittle execution pipelines.
- Domain-specific retrieval is required: Substituting local retrieval with open web search reduces scores substantially. This confirms dependency on retrieval of precise, corpus-local evidence rather than generic parametric or web-based information.
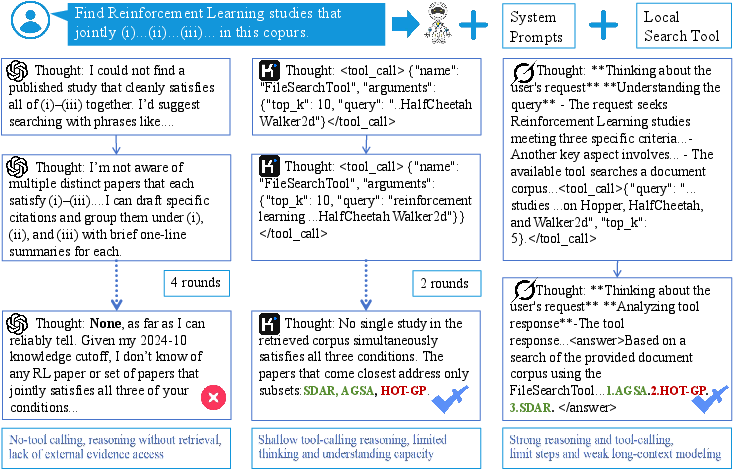
Figure 4: Empirical case study contrasting performance of models with no tool support, shallow tool usage, and robust tool-mediated reasoning, highlighting the importance of compositional pipeline competence for complex multi-document retrieval.
Ablative and Error Analysis
Ablation reveals that providing oracle support documents elevates performance, but does not suffice—a gap persists, attributable to inherent complexity in evidence chaining, visual parsing, and semantic synthesis under long-document scenarios. ORWAS parameter ablations suggest nontrivial trade-offs in document set diversity, quality, and discovery given graph walk lengths and bias levels.
A detailed error breakdown on top-performing agents indicates the greatest weakness is fine-grained visual extraction from charts or tables (37.5% of failures), followed by errors in multi-step reasoning (22.5%), retrieval granularity, and hallucination. Context truncation only marginally impacts (<5%).
Cross-Domain Evaluation and Generalization
Extension to non-AI domains (Medicine, Mechanics) required minimal schema adaptation and yielded high expert satisfaction rates (95%). The pipeline maintained strong ability to generate multi-modal, multi-document tasks with automatic random walk linking of relevant entities, evidencing domain-agnostic applicability.
Theoretical and Practical Implications
PaperScope reveals that long-context, multi-modal, multi-document deep research remains unsolved for current LLM agents, with clear distinction between summarization and genuine multi-source reasoning/solution design. The construction methodology establishes a reproducible, scaleable pipeline for benchmark generation that can be extended across domains. For practitioners, the dataset's design ensures robust diagnostic coverage of retrieval, evidence fusion, and structured inference—the real challenges in agentic automation of scientific workflows.
The findings call for dedicated advances in document-level visual-semantic alignment, context-aware retrieval, compositional reasoning, and systematic reduction of tool-calling brittleness. Methodologically, PaperScope sets a new standard for benchmark construction, leveraging knowledge-graph-based sampling over simple manual curation, and forces models to engage with authentic, heterogeneously-structured scientific artifacts.
Figure 5: Visualization of selected semantic graphs, illustrating the high-entity-density document interconnections central to PaperScope’s construction.
Conclusion
PaperScope provides a rigorous environment for evaluation and development of agentic systems targeting complex scientific workflows, diagnosing key failure points in reasoning, multi-modal integration, and tool use. The benchmark demonstrates that even highly advanced agents remain substantially below human-level competence in research-style tasks beyond summarization. Future work should focus on improving visual-semantic information extraction, agent pipeline robustness, and more advanced retrieval/reasoning architectures adapted to the realities of large, heterogeneous scientific corpora.
[Paper (2604.11307)]