- The paper's main contribution is the development of a benchmark for multi-document analytical QA that scales to hundreds of documents using metadata-aware, multi-agent workflows.
- It details a modular methodology incorporating planning, document extraction, normalization, and code agents to enhance both process coverage and final-answer accuracy.
- Empirical results show that while traditional RAG systems struggle with inter-document synthesis, the multi-agent workflow significantly improves extraction and reasoning, though challenges remain compared to human performance.
Multi-Document Analytical QA at Scale: An Expert Analysis of MuDABench
Motivation and Benchmark Design
Conventional QA paradigms, built upon RAG-enabled LLMs, have primarily focused on retrieving and synthesizing information from small sets of passages—usually few documents fitting a context window—reflecting the structure of mainstream datasets such as HotPotQA and its derivatives. However, real-world analytical QA tasks often require robust quantitative reasoning and aggregation across dozens or even hundreds of complementary documents organized as a semi-structured database. In finance, this includes multi-year regulatory surveillance, ESG comparisons, and abnormality detection across annual reports, disclosures, and corporate announcements.
MuDABench addresses this gap by constructing a benchmark with 80,000+ pages and 332 analytical QA instances, each requiring extensive inter-document reasoning and aggregation. The benchmark employs explicit metadata annotations (ticker, fiscal year, document type) and intermediate information sets, enabling systematic process coverage evaluation.
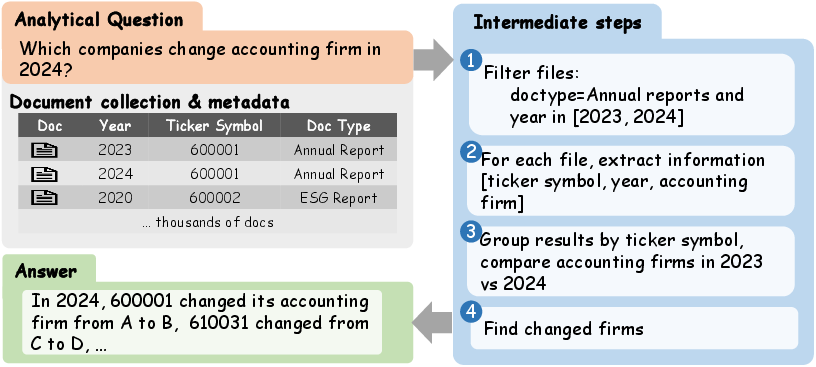
Figure 1: An example of multi-doc analytical QA, illustrating metadata-driven organization and targeted extraction for aggregate answers.
The benchmark encompasses heterogeneous document sets—annual reports, ESG filings, and announcements—divided across varied document formats to probe extraction robustness. Distributional statistics show significant scale differences compared to prior datasets, ensuring that most QA tasks exceed the context length limits of state-of-the-art LLMs.
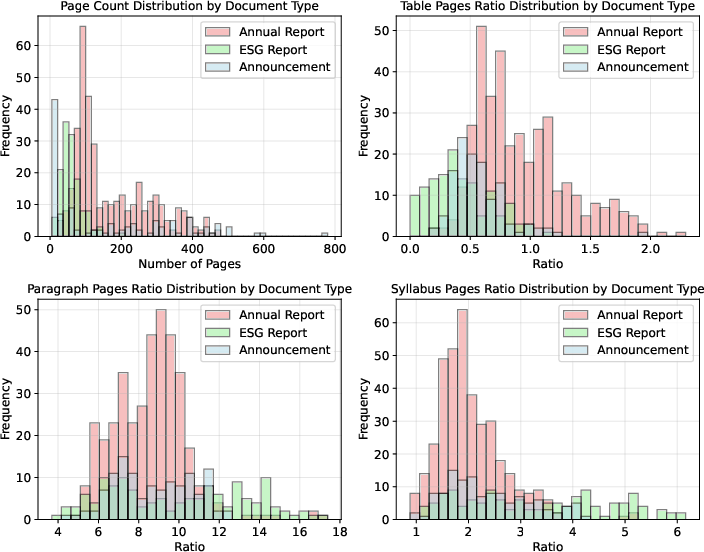
Figure 2: Document Elements Distribution across annual reports, ESG reports, and announcements in the benchmark corpus.
Evaluation Protocol and Diagnostic Metrics
Traditional end-task accuracy metrics are retained for MuDABench, but the benchmark innovates by introducing process-oriented auxiliary metrics capturing intermediate extraction fidelity. Final-answer accuracy is judged for semantic equivalence by an LLM-based protocol. Intermediate extraction quality is measured via fact coverage (RAG) and cell-wise correctness (document-grounded workflows), with semantic matching and robust cross-verification to resolve ambiguity in atomic fact representations. A strict joint metric ("full accuracy") is also reported, counting only instances that are correct at both process and final-answer levels.
Standard RAG systems, which treat document collections as flat pools for retrieval, exhibit limited performance on MuDABench's analytical QA tasks even under high retrieval budgets. The paper advances a modular, metadata-aware multi-agent workflow:
- Planning Agent: Decomposes global analytical queries into document-level sub-query templates using metadata constraints for scalable targeting.
- Document-Level Extractor: Executes single-document QA using RAG, instantiated with metadata-guided queries, generating local evidence.
- Normalization Agent: Transforms free-form extractions into structured JSON batches, facilitating programmatic aggregation.
- Code Agent: Synthesizes executable programs for downstream aggregation and quantitative reasoning, leveraging only schema and sample records rather than full corpus ingestion.
This approach explicitly aligns extraction and aggregation with document metadata, scaling analytical QA to corpora of arbitrary size.
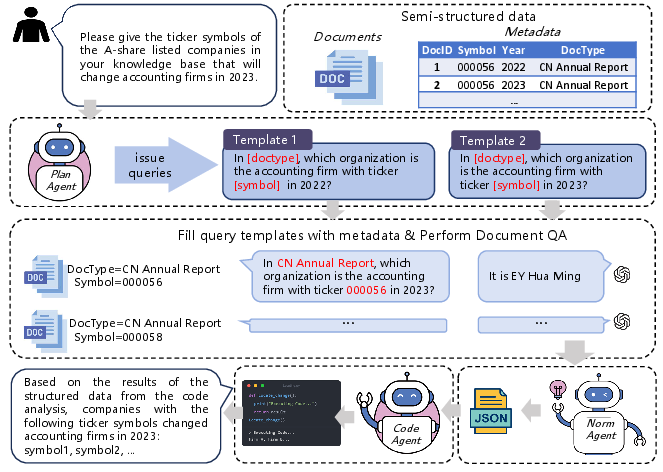
Figure 3: Document agentic workflow depicting planning, document-targeted extraction, batch normalization, and programmatic analysis.
Empirical Results and Failure Mode Analysis
Experimental findings indicate that RAG pipelines—despite metadata injection and expanded chunk budgets—increase process coverage but do not yield corresponding gains in final-answer accuracy. Synthesis across retrieved fragments is the primary bottleneck, not recall alone. The multi-agent workflow markedly improves both process coverage and end-task accuracy, but a substantial gap persists relative to human experts, particularly for complex queries requiring nuanced cross-document reasoning and aggregation.
Process-oriented diagnostic analysis identifies the main error sources:
- Single-Document Extraction: Accuracy decreases with document length (token count), with visual and tabular heterogeneity further compounding extraction failures.
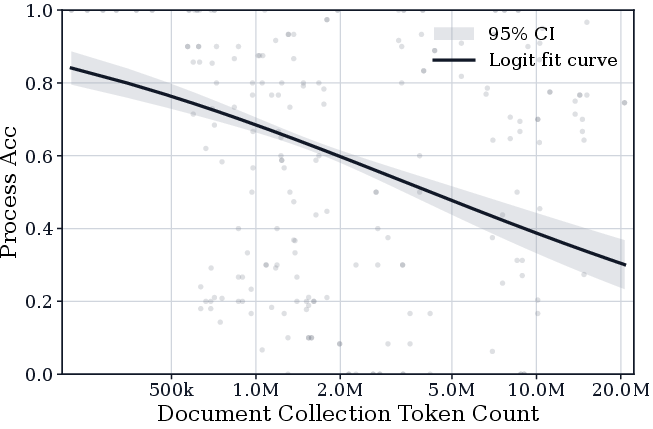
Figure 4: The Impact of Document Collection Token Count on Document Information Extraction, highlighting extraction deterioration with increasing document size.
- Planning Failures: Agents often misalign query decomposition with domain conventions (e.g., misunderstanding event frequency, neglecting multi-step extraction required for transition identification).
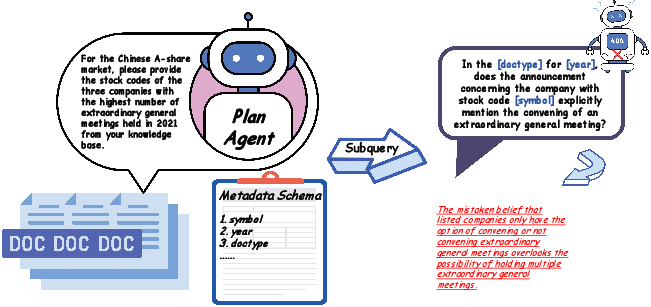
Figure 5: Case Study: Planning errors stemming from a lack of knowledge regarding shareholder meetings.
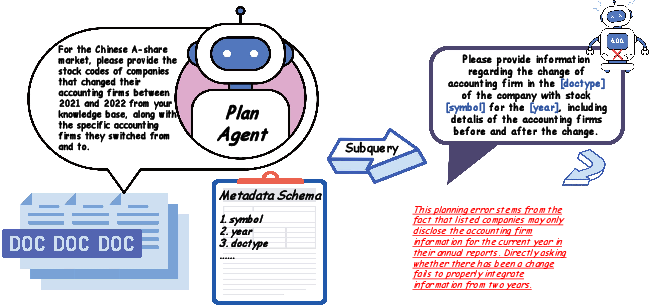
Figure 6: Case Study: Planning errors stemming from a misunderstanding of annual report protocols.
- Normalization and Schema Alignment: Extraction ambiguity across multi-year entries complicates normalization; schema deviations propagate to downstream programmatic analysis failures.

Figure 7: Case Study: Ambiguous Information Extraction and Normalization Failure.

Figure 8: Case Study: Schema Alignment Error in Code Execution.
Analysis of document categories reveals that extraction difficulty is jointly determined by average document length, structural complexity, and domain language, rather than any single factor.
Implications and Future Directions
MuDABench sets a rigorous testbed for scalable, agentic document analysis workflows targeting analytical QA with high compositional complexity. The persistent gap between agentic workflows and human expertise underscores the limitations of current LLMs and RAG systems in domain-sensitive planning, robust extraction, and cross-document aggregation. Practical implications include the need for advancements in document parsing, schema robustness, and metadata-driven query decomposition.
Theoretical implications extend to the study of context limitations, modular decomposition strategies, and evaluation protocols for multi-agent reasoning across semi-structured repositories. The benchmark's process-oriented metrics could inform the design of future diagnostic signals and evaluation pipelines for long-context QA.
Further research should explore domain adaptation strategies, hierarchical memory mechanisms, and tighter integration between planning, extraction, and aggregation modules. Addressing the extraction bottleneck for complex document formats and improving domain-specific reasoning capacity represent immediate areas for investigation.
Conclusion
MuDABench operationalizes the transition from snippet-based retrieval to large-scale analytical QA over semi-structured document collections. It reveals fundamental challenges in extraction, aggregation, and planning for RAG and agentic LLM-based systems, motivating future advances in scalable document analysis, modular multi-agent workflows, and robust metadata-driven reasoning architectures.

