- The paper demonstrates that token-level cancellation arises from gradient coupling in critic-free RL, challenging conventional outcome-level reward assignment.
- It reveals that nearly half the tokens are updated contrary to the rollout advantage, with masked experiments confirming the causal impact of same-token, low-confidence pairs.
- The study proposes batching interventions like Query-Preserved and Reward-Balanced techniques to stabilize training and enhance performance across LLM scales.
The Cancellation Hypothesis in Critic-Free RL: A Token-Level Perspective on Credit Assignment
Introduction and Motivation
LLM alignment with reinforcement learning from human or verifiable feedback increasingly leverages critic-free methods such as Group Relative Policy Optimization (GRPO). These approaches eschew token-level critics, instead assigning a uniform outcome-level reward (the advantage) to every token in a sampled rollout. The canonical intuition is that such methods reinforce successful sequences and penalize failed ones, thereby steering the overall policy distribution toward more desirable responses. However, this paper interrogates the validity of this intuition at the token level, revealing that it breaks down under empirical scrutiny.
Token Flipping: Empirical Discrepancy between Rollout- and Token-Level Updates
A key empirical finding is the token flipping phenomenon, wherein nearly half the tokens in a rollout are updated in the direction opposite to that predicted by the rollout-level advantage sign. That is, both positively and negatively rewarded rollouts feature similar proportions of tokens with increased (boosted) and decreased (suppressed) log-probability following an RL update. Rollout-level reward is thus a poor predictor of individual token updates. Notably, this symmetry in token displacement profiles is consistent across architectures and tasks.
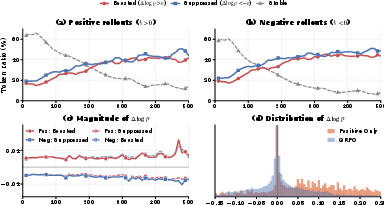
Figure 1: Positive and negative rollouts exhibit nearly identical ratios of boosted, suppressed, and stable tokens and similar update magnitudes; the effect is abolished when only positive rollouts are used, highlighting interaction-induced (coupling) effects.
Further, when training is limited to only positive rollouts, the flipping effect largely vanishes, implicating a critical role for interaction (i.e., gradient coupling) between simultaneously present positive and negative rollouts in the batch.
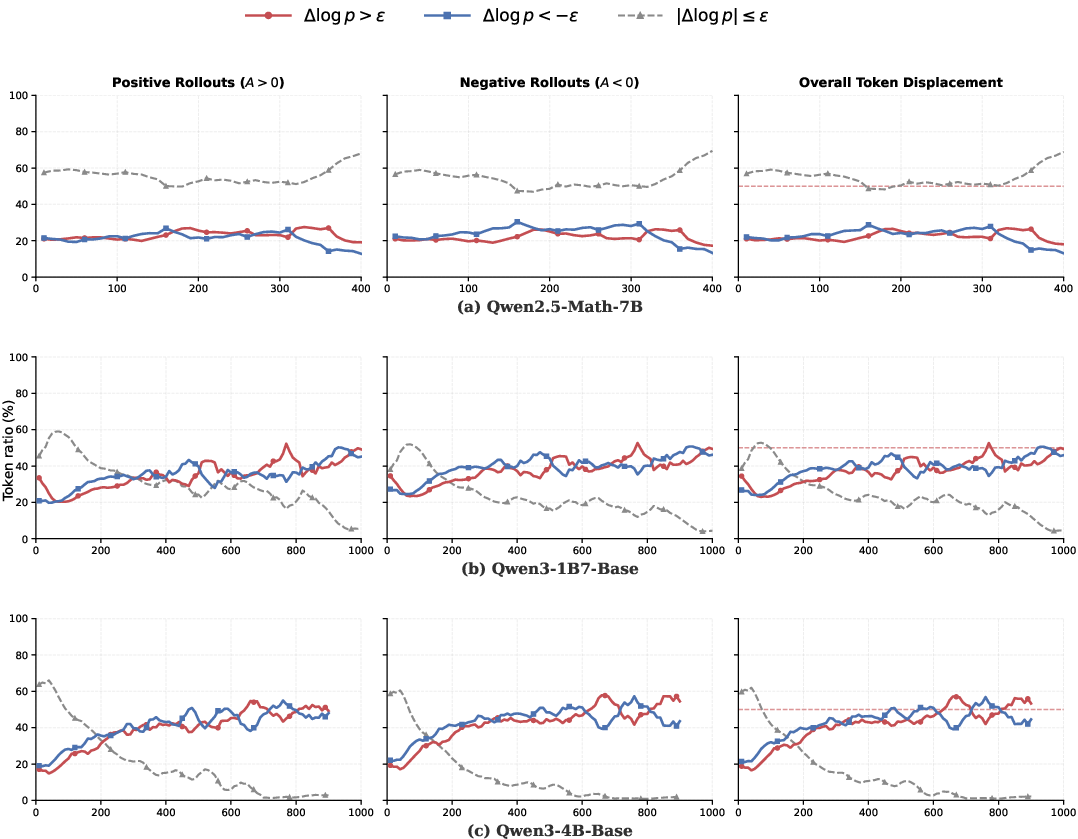
Figure 2: Across multiple LLM backbones, positive and negative rollouts always yield similar token-level displacement profiles, underscoring the robustness of the flipping phenomenon.
Token Coupling: Mechanistic Analysis and Empirical Validation
To explain token flipping, the paper decomposes the GRPO update on token j into a self-term (due to that token's own advantage) and a coupling term (where gradient interactions with all other tokens in the batch contribute). Critically, non-negligible coupling occurs primarily for pairs of identical tokens that are both predicted with low confidence (high entropy). Mathematically, the coupling kernel decomposes into a product of a hidden-state similarity and an output-distribution factor, which is only large for same-token, high-entropy pairs.
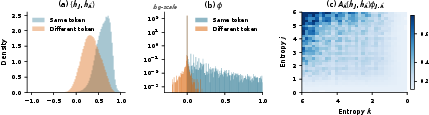
Figure 3: Coupling is strongest between same-token, low-confidence pairs—these pairs show higher hidden representation similarity and non-negligible gradient interaction.
Masked update experiments verify this analytic sparsity: when masking tokens selected by the coupling criterion (same token, low confidence), their omission yields a marked decrease in boosting candidate tokens’ log-probabilities, confirming their strong causal effect.
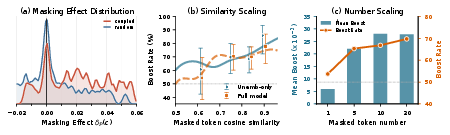
Figure 4: Masking coupled tokens (same-token, low-confidence) robustly reduces token-level log-prob boosts, validating their causal impact on other tokens.
The Cancellation Hypothesis: Hidden Token-Level Credit Assignment
Building on the sparse, structured nature of token coupling, the cancellation hypothesis is introduced. When both positive and negative rollouts for a given prompt coexist in a batch, tokens shared between successes and failures receive opposite (and thus canceling) updates, whereas tokens unique to successful rollouts are preferentially reinforced. This batch-level filtering mechanism enacts hidden token-level credit assignment from outcome-level supervision, even without an explicit critic network.
Empirically, cancellation:
- Diminishes updates to template and formatting tokens (common to both success and failure), and shifts the learning signal towards reasoning or decision tokens more diagnostic of successful outcomes.
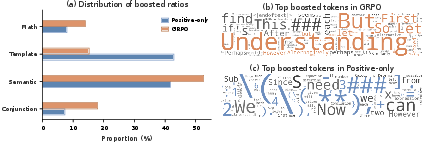
Figure 5: GRPO shifts token-level boosts from formatting (template) tokens toward reasoning and conjunction (semantic) tokens, in contrast to positive-only training that overemphasizes template tokens.
- Boosted tokens (post-update) empirically possess higher expected future reward, regardless of their originating rollout’s reward sign, confirming that cancellation surfaces action-relevant credit.
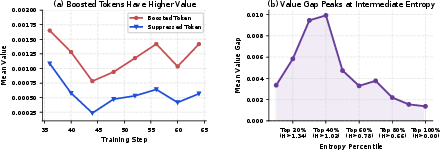
Figure 6: Boosted tokens, as identified by cancellation, have consistently higher Monte Carlo estimated token-value than suppressed tokens.
The value gap between boosted and suppressed tokens is maximized among intermediate-entropy tokens—tokens too low in entropy are anchored by the pretraining prior and contribute little learning signal, while extremely high-entropy tokens are too uncertain to reliably infer value.
Repeated updates on the same batch amplify the value gap, underlining the stable, accumulative nature of the cancellation-induced credit assignment.
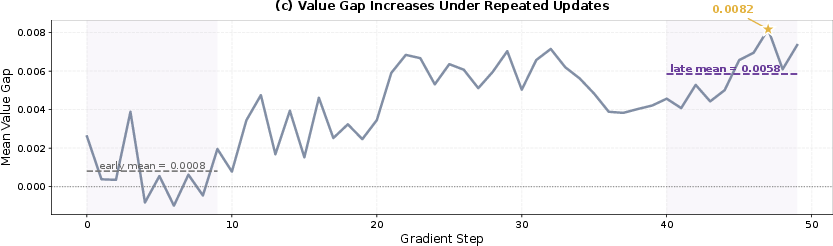
Figure 7: The value gap between boosted and suppressed tokens monotically widens over repeated updates, reflecting progressive refinement of token-level credit assignment.
Practical Implications: Batch Design Interventions Based on Cancellation
The paper leverages the cancellation insight to suggest and validate two batching interventions that preserve or enhance this phenomenon:
- Query-Preserved Mini-Batching (QB): Ensures all rollouts from a given prompt are processed in the same mini-batch, maintaining the natural grouping required for cancellation to be effective. Random minibatch splitting can fragment these groups, undermining cancellation.
- Reward-Balanced Batching (RB): Ensures each batch contains a sufficient mix of positive and negative rollouts, preventing reward sparsity or saturation—which was shown to degrade the cancellation effect—by discarding batches with imbalanced sign representation.
Combining these strategies significantly stabilizes critic-free RL training and yields improved empirical performance across LLM scales and math reasoning benchmarks, especially for base models that are prone to collapse.
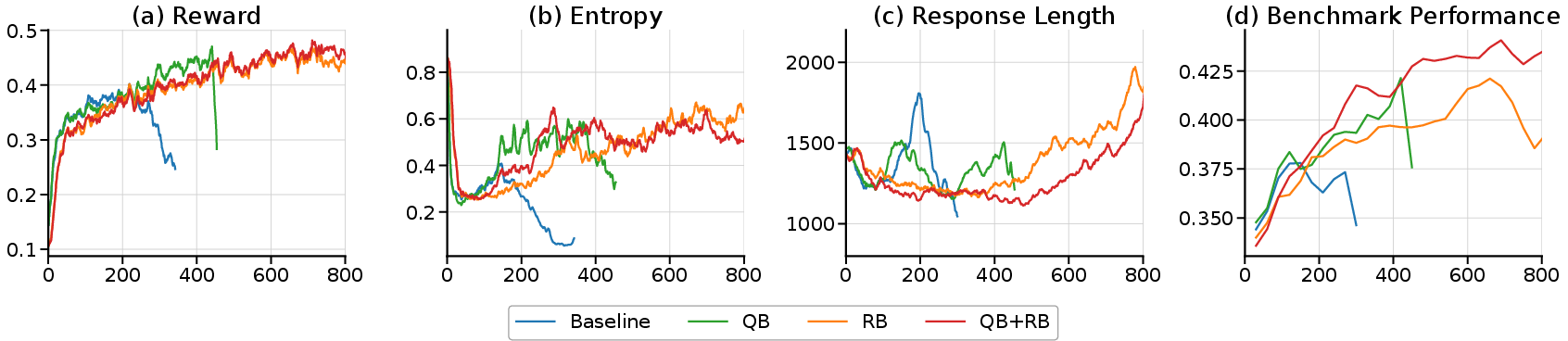
Figure 8: QB and RB individually and synergistically stabilize training, with the QB+RB combination yielding the best performance and stability across math benchmarks.
Theoretical and Future Directions
The work recontextualizes critic-free RL for LLM alignment as an instance of implicit, batch-coupling-induced credit assignment. Rather than reinforcing all actions in a winning sequence, GRPO with cancellation effectively prioritizes tokens with the strongest causal link to success—those that differ between positive and negative outcomes—using structural properties of the batch rather than explicit local advantage signals.
The cancellation hypothesis opens new avenues for research, including:
- Optimal batch construction strategies for maximal signal extraction.
- Extension to multi-turn or more complex structured tasks.
- Integration with explicit token-level value modeling.
- Theoretical investigations into coupling-induced regularization and generalization properties.
- Scaling analyses: the strength and selectivity of cancellation grow with batch and rollout size, suggesting practical directions for resource allocation.
Conclusion
This work demonstrates that critic-free RL methods for LLMs, such as GRPO, distribute learning signals at a finer granularity than previously assumed, through batch-induced cancellation mechanisms. Token-level credit assignment emerges implicitly via structured coupling in the batch, challenging sequence-level reinforcement intuitions. The analysis provides actionable guidelines for batching strategies and opens the door for more principled, interpretable, and effective RL alignment protocols for large-scale autoregressive models.