- The paper presents GenAC, a generative critic framework that replaces scalar value prediction with chain-of-thought reasoning to improve credit assignment in LLM RL.
- It demonstrates that generative critics reduce approximation error and variance, achieving higher sample efficiency and validation accuracy on mathematical reasoning benchmarks.
- The study illustrates enhanced interpretability and robustness through In-Context Conditioning, offering precise token-level credit assignment for complex, long-horizon tasks.
Generative Critics for Value Modeling in LLM Reinforcement Learning
Motivation and Problem Statement
The landscape of LLM reinforcement learning is shaped by the need for effective credit assignment. Modern RL-centric LLM post-training, across alignment, mathematical reasoning, and code generation, is constrained by the inability of prevalent methods to provide informative policy gradients over long-horizon trajectories. Value-free methods like GRPO and RLOO, popular for computational simplicity, are fundamentally limited—they estimate uniform trajectory-level advantage, essentially reducing sequence modeling to bandit feedback. This results in poor credit assignment for complex, multi-step tasks. While traditional actor-critic methods such as PPO once addressed this through token-level advantage estimation, their practical impact has diminished at LLM scale due to unreliable value modeling.
This work challenges the notion that value-based approaches are intractable in LLM RL, analyzing the expressivity failure of conventional discriminative critics and proposing an alternative: Generative Actor-Critic (GenAC). GenAC replaces scalar value prediction with chain-of-thought generative value estimation, bolstered by In-Context Conditioning (ICC) for robust policy-awareness throughout training.
Theoretical Limits of Discriminative Critics
The central claim advanced is that the difficulty in value modeling for LLM RL is not purely an optimization artifact, but a representational bottleneck driven by model architecture choices. Discriminative critics, limited by one-shot scalar prediction, cannot express the function complexity required for value estimation in language MDPs. Grounding this, the paper references representation complexity theory, demonstrating that the computation for optimal value functions in MDPs indexed by polynomial-time languages can be P-complete, while constant-depth Transformers are confined to TC0 [feng2024rethinking]. As a result, scaling model parameters does not yield improved value function approximation if the model cannot perform serial reasoning steps.
Empirical scaling studies substantiate this: discriminative critics (initialized from variously sized LLMs) show stable but high approximation error regardless of parameter count and high seed sensitivity, confirming the theoretical analysis.
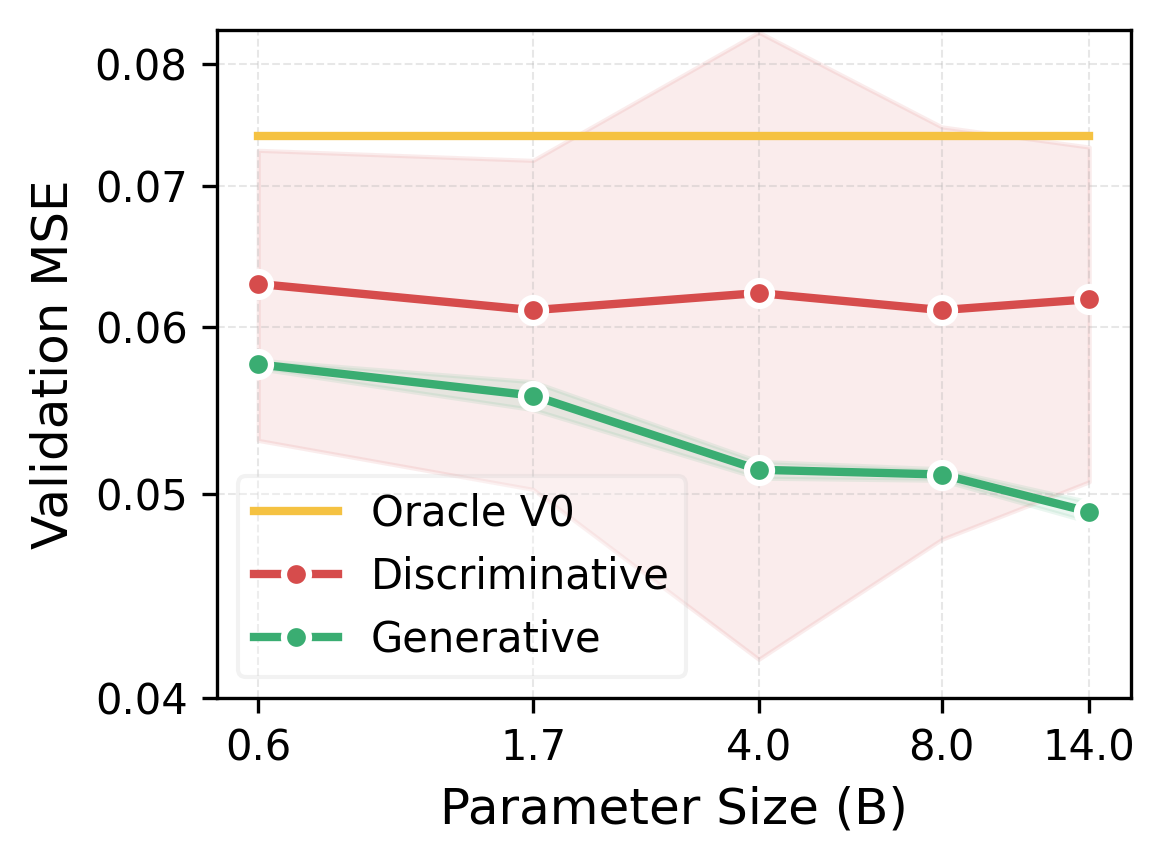
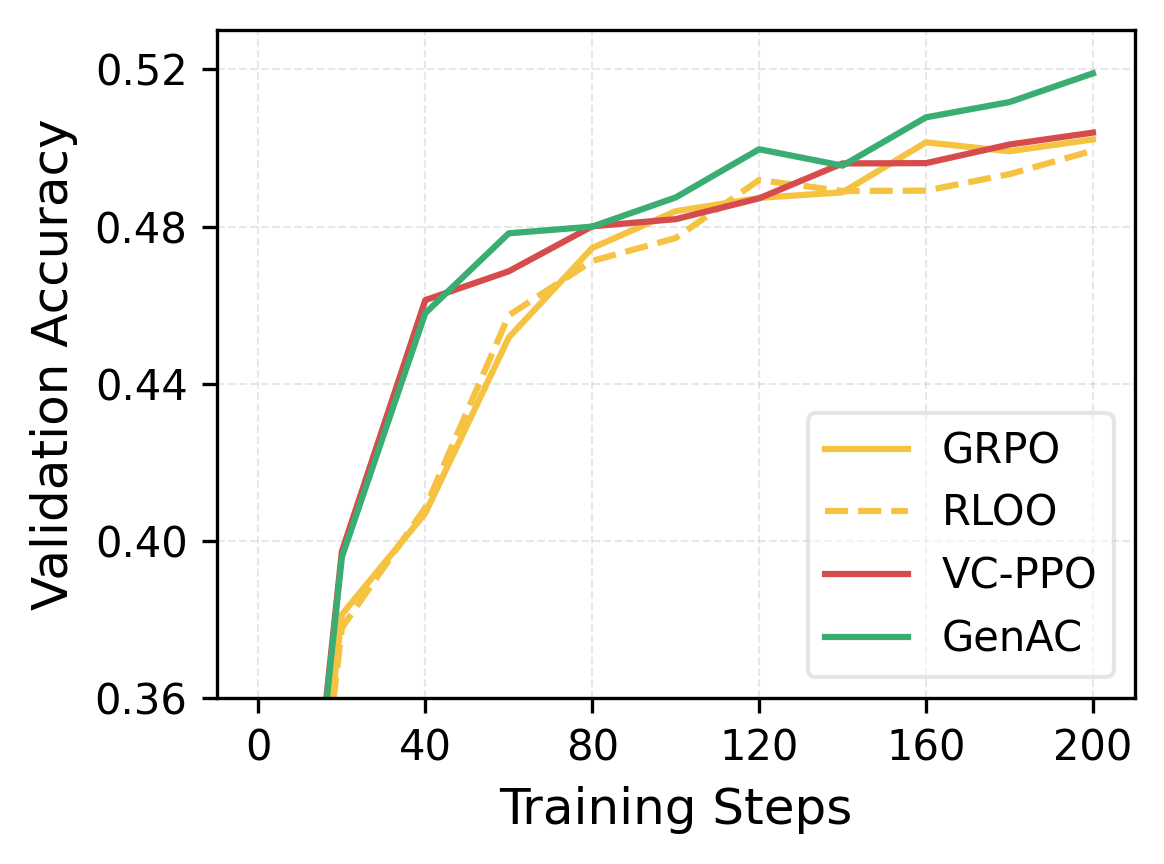
Figure 1: (a) Generative critics outperform discriminative critics in value approximation and scale better with model size. (b) GenAC yields stronger sample efficiency and converges to higher downstream RL validation accuracy on mathematical reasoning benchmarks.
The GenAC Architecture
GenAC's principal innovation is a generative critic that leverages chain-of-thought reasoning prior to emitting a final value estimate. By exploiting the LLM’s natural capacity for autoregressive reasoning, the generative critic can decompose the evaluation problem into sequential subcomputations, addressing expressiveness shortcomings inherent to shallow, single-pass architectures.
In contrast to replacing the LM head with a single-value regressor (standard in discriminative critics), GenAC retains the generative LM head and prompts the model to output a structured reasoning trace terminating with an integer-valued "score" (0–10, normalized), naturally suited for LLMs.
To enhance the policy-awareness of the critic and prevent miscalibration or reward hacking, GenAC introduces the ICC mechanism. The ICC prompt explicitly inserts a summary of the current actor’s policy traits (e.g., model size, recent performance statistics) as context for the critic. This ensures that the value estimate is tied to the evolving actor and not a static or off-policy assessment.
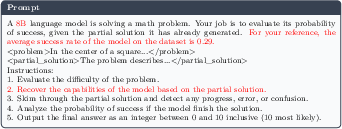
Figure 2: GenAC’s ICC-based prompt template provides explicit policy context to the generative critic.
Training Pipeline and Cost Analysis
The generative critic undergoes multi-stage training: (1) supervised fine-tuning on synthetic reasoning traces, (2) RL-based value pretraining using empirical Monte Carlo returns, and (3) joint actor-critic optimization via PPO. During RL, segment-level value predictions from the critic are mapped to token-level advantages using GAE with λ=1, achieving densely informative gradients for the actor.
The cost analysis highlights that GenAC’s computational overhead (~2.1× PPO’s FLOPs) is moderate compared to rollout-based approaches (e.g., VinePPO at 4.3×). The efficiency is achieved by generating relatively short reasoning traces per prefix (rather than multiple full rollouts per segment, as in VinePPO).
Empirical Results and Analysis
Value Approximation and Stability
GenAC's critics exhibit superior value approximation compared to discriminative baselines, as seen in markedly reduced validation MSE and decreased variance with increasing model size. This is further validated through ranking performance probes: generative critics achieve higher top-1 accuracy in selecting the highest-value candidate among sampled segments, with this gap widening as the candidate set grows.
On six mathematical reasoning benchmarks, GenAC outperforms both value-free (GRPO, RLOO) and value-based (VC-PPO) baselines in final policy accuracy and sample efficiency. VC-PPO trails off as training progresses, illustrating saturation due to critic expressiveness limits, while GenAC maintains performance improvements throughout.
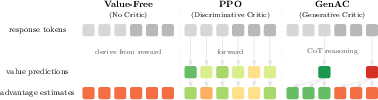
Figure 3: GenAC assigns token-level advantage reflecting actual reasoning dynamics, whereas value-free and discriminative critic methods fail to differentiate segmental quality, especially on erroneous answer trajectories.
Out-of-Distribution Generalization
Testing critics on datasets with progressive distributional shifts reveals that generative critics consistently generalize better, with higher MSE reductions on OOD evaluation sets compared to discriminative critics. This robustness underlies the sustained RL performance advantage as the actor policy diverges during training.
Interpretability and Credit Assignment
Case studies show that GenAC’s generative critic can pinpoint the precise step in a reasoning trajectory where a conceptual error emerges, assigning appropriately lowered value and providing interpretable rationale.
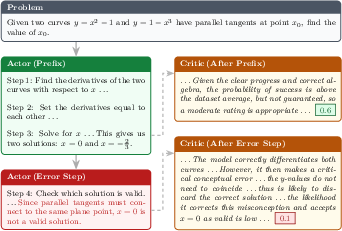
Figure 4: Example where the generative critic accurately detects and rationalizes a stepwise conceptual error in mathematical reasoning.
Ablations and Design Insights
Ablations disabling ICC or skipping RL-based critic training deliver degraded value approximation and RL performance. Notably, even highly capable LLMs (e.g., GPT-5) fail as value critics when used in a zero-shot, prompt-based manner, confirming the necessity of policy-aware, specialized value modeling.
Implications and Future Directions
The findings directly challenge the recent trend away from value-based RL in LLMs, establishing that architectural limitations of discriminative critics—rather than inherent infeasibility—explain degraded performance at scale. Introducing generative critics with chain-of-thought and policy conditioning enables reliable, expressive value modeling, unlocking fine-grained credit assignment critical for complex LLM behaviors.
The theoretical implication is that for MDPs induced by long-horizon, language-based tasks, only value functions that match the sequence-processing demands of the problem class can be learned. Practically, these results anticipate that the RL fine-tuning of next-generation LLMs in agentic, reasoning-intensive settings will benefit from a renewed emphasis on value modeling, provided that the critic architectures are sufficiently expressive.
Ongoing engineering work is required to optimize the computational footprint of generative critics. Further research should extend the empirical study beyond mathematical reasoning to domains involving multi-agent, interactive, and multi-modal LLM settings, where precise temporal credit assignment is likely to be even more crucial.
Conclusion
This work repositions explicit value modeling at the core of RL for LLMs, diagnosing the expressiveness limitations of classical discriminative critics and demonstrating the effectiveness of generative, chain-of-thought critics with ICC. The resulting GenAC framework achieves higher sample efficiency, stability, and final performance in mathematical reasoning tasks, with robust generalization and interpretable error attribution. These results suggest that scalable, expressive value modeling will be foundational for future advances in RL-driven LLMs as tasks grow in complexity and temporal horizon.