Soft Tokens, Hard Truths
Abstract: The use of continuous instead of discrete tokens during the Chain-of-Thought (CoT) phase of reasoning LLMs has garnered attention recently, based on the intuition that a continuous mixture of discrete tokens could simulate a superposition of several reasoning paths simultaneously. Theoretical results have formally proven that continuous tokens have much greater expressivity and can solve specific problems more efficiently. However, practical use of continuous tokens has been limited by strong training difficulties: previous works either just use continuous tokens at inference time on a pre-trained discrete-token model, or must distill the continuous CoT from ground-truth discrete CoTs and face computational costs that limit the CoT to very few tokens. This is the first work introducing a scalable method to learn continuous CoTs via reinforcement learning (RL), without distilling from reference discrete CoTs. We use "soft" tokens: mixtures of tokens together with noise on the input embedding to provide RL exploration. Computational overhead is minimal, enabling us to learn continuous CoTs with hundreds of tokens. On math reasoning benchmarks with Llama and Qwen models up to 8B, training with continuous CoTs match discrete-token CoTs for pass@1 and surpass them for pass@32, showing greater CoT diversity. In systematic comparisons, the best-performing scenario is to train with continuous CoT tokens then use discrete tokens for inference, meaning the "soft" models can be deployed in a standard way. Finally, we show continuous CoT RL training better preserves the predictions of the base model on out-of-domain tasks, thus providing a softer touch to the base model.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies a new way for LLMs to “think” during problem solving. Usually, LLMs think step-by-step using regular words or symbols, called tokens. The authors replace those hard, step-by-step tokens with “soft” tokens—smooth mixtures of many possible tokens at once—so the model can explore multiple reasoning paths in parallel. They also show how to train this kind of thinking efficiently using reinforcement learning (RL), and test it on math problems.
What questions does the paper ask?
In simple terms, the paper asks:
- Can LLMs learn to think with soft, continuous tokens instead of only hard, discrete ones?
- Can we train this soft thinking at scale using RL, without needing lots of human-written explanations?
- Does soft thinking make models more accurate or more diverse in their reasoning?
- Does training with soft thinking avoid hurting the model’s performance on other tasks?
How does the method work?
To make this understandable, let’s start with some key ideas.
Discrete vs. continuous tokens
- Discrete tokens are like picking one LEGO brick at a time: the model chooses one exact word or symbol for each step.
- Continuous tokens are like blending many LEGO bricks into a “smoothie”: the model keeps a weighted mix of many possible tokens at each step. This keeps options open and can represent several reasoning paths at once.
Soft and fuzzy tokens
- Soft tokens: a probability-weighted mix of many tokens (like that smoothie), used during the model’s chain-of-thought. The authors add a small amount of noise to these inputs—like shaking the smoothie—so the model explores different reasoning trails.
- Fuzzy tokens: similar to soft tokens, but the mix is made very sharp (temperature close to zero), so it looks almost like a single hard token with a tiny bit of noise. Think of it as a “nearly solid” token with a light wiggle.
Reinforcement learning (RL), simplified
RL is training by trial and error:
- The model tries to solve a problem and gets a reward if the final answer is correct.
- Because they add noise to the soft/fuzzy tokens, the model naturally tries different variations of the reasoning steps.
- Over time, it learns which kinds of “soft thinking” lead to good answers.
Key point: Previous methods either didn’t train soft thinking at all or needed to copy from many human-written chains-of-thought. This paper’s RL approach learns soft thinking directly and scales to hundreds of thinking steps without heavy computation.
What are pass@1 and pass@32?
- pass@1: The model tries once. This is the percent of problems solved correctly on the first try.
- pass@32: The model is allowed to sample 32 different attempts. This measures both accuracy and the diversity of its reasoning. If the model can try varied paths, it’s more likely to get it right in one of the 32 attempts.
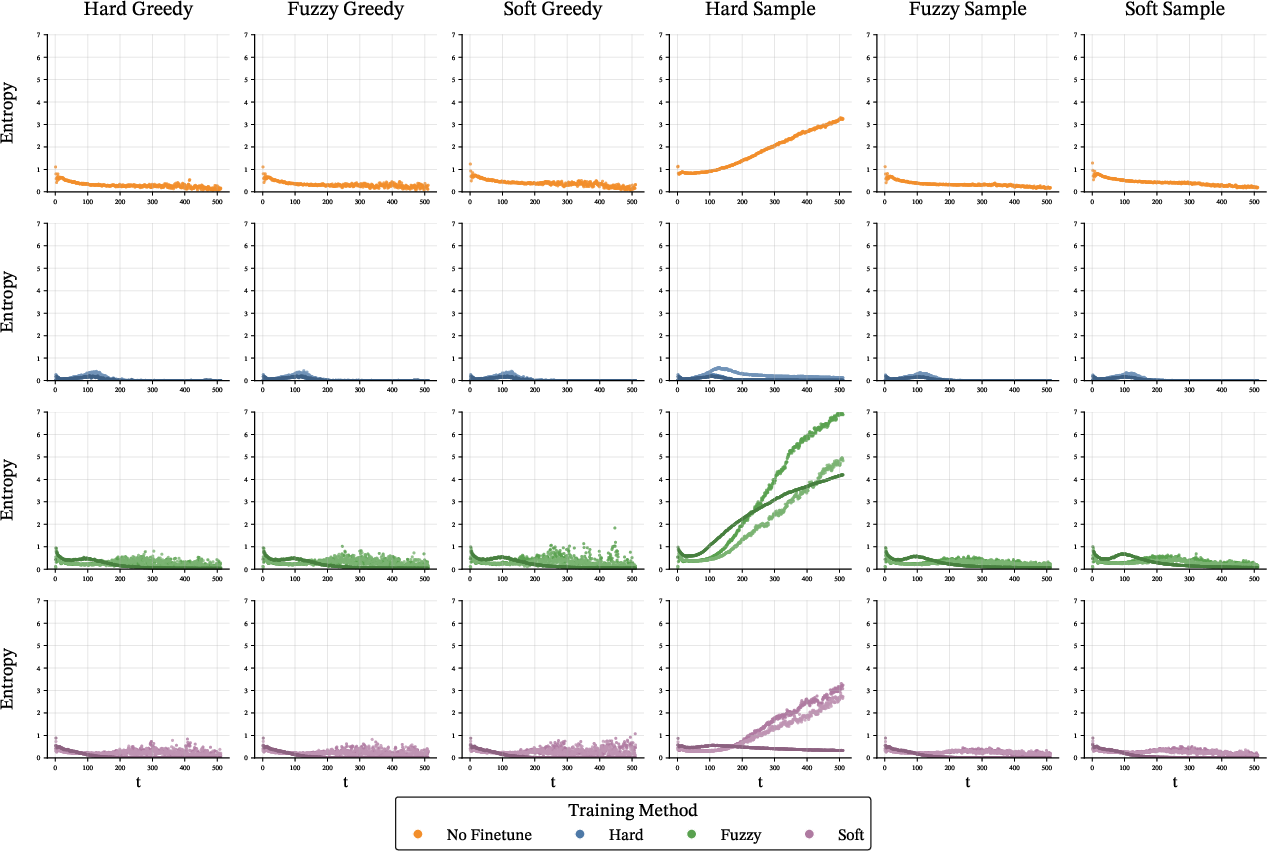
A quick note on “entropy”
- Entropy here measures how uncertain or varied the model’s next-token choices are during thinking.
- Higher entropy means the model is exploring; very low entropy means it’s overly confident and may be narrow in its thinking.
What did they find?
Here are the most important results:
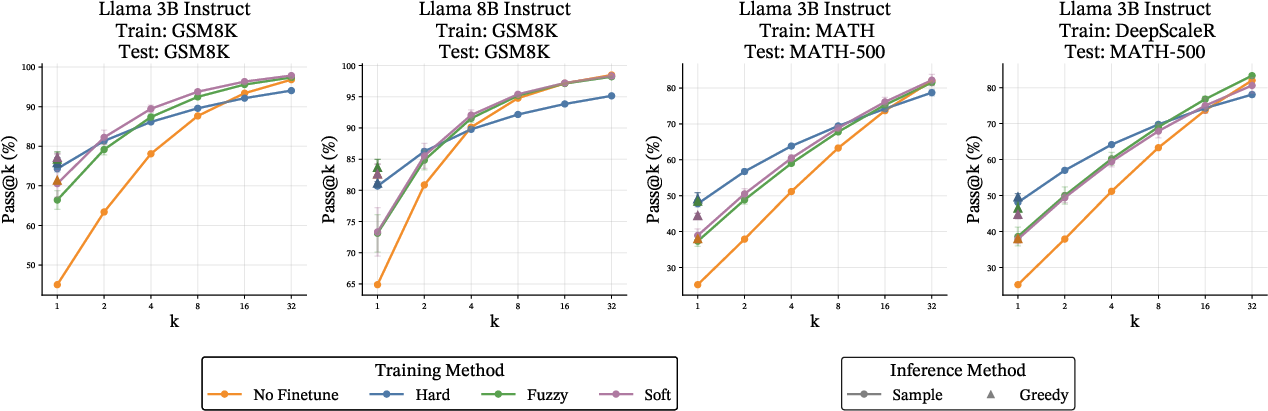
- Similar accuracy on first try: Models trained with soft or fuzzy tokens do about as well as standard hard-token models on pass@1. In other words, soft thinking doesn’t hurt first-try accuracy.
- Better with multiple tries: Soft/fuzzy training improves pass@32 compared to hard training. This means the model keeps more diverse reasoning paths, so when you sample multiple solutions, it’s more likely to get one right.
- Best way to use it: Train with soft/fuzzy tokens, but do normal hard-token inference when you deploy. In plain terms: teach the model to think softly, then let it speak normally. This worked best overall.
- More robust to other tasks: Models trained with soft/fuzzy tokens kept their general abilities better (on benchmarks like HellaSwag, ARC, MMLU). Hard-token training tended to make models overconfident and slightly worse on those out-of-domain tasks.
- A notable case: For Llama-8B trained on GSM8K, hard-token training hurt performance on the tougher MATH benchmark. Soft/fuzzy training maintained or improved performance there.
- Healthier uncertainty profiles: Entropy analysis showed soft/fuzzy training preserved a natural level of uncertainty during thinking, instead of becoming too “certain” too early. This is linked to better diversity and robustness.
Why does this matter?
- More flexible reasoning: Soft tokens let the model “consider more than one idea at once,” which can help explore complex problems better.
- Scalable training: Their RL method learns soft thinking without needing tons of handcrafted reasoning examples, and it works for long chains-of-thought.
- Practical deployment: You can train with soft thinking but still run the model in the standard way (hard tokens) when serving users. That means no special inference tricks are required.
- Better generalization: Soft/fuzzy training tends to keep the model’s broader skills intact, avoiding the “overfitting” that sometimes happens with hard-token fine-tuning.
- Future impact: This suggests a path where LLMs think in richer, more flexible internal spaces, leading to stronger reasoning, more varied solutions, and safer fine-tuning.
In short, the paper shows that teaching models to think with soft, continuous tokens—and using RL with a bit of controlled noise—can make them both accurate and more diverse in their reasoning, while staying easy to deploy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- Scaling and compute characterization: The paper claims “minimal overhead” but provides no quantitative measurements (GPU-hours, memory footprint, wall-clock, throughput) for training and inference, especially given storing full probability vectors per CoT step and sampling 32 rollouts per prompt. Systematic profiling across model sizes, vocabularies, and CoT lengths is needed.
- Model scale generalization: Results are limited to ≤8B models. It remains unknown whether continuous CoT RL scales and remains stable for 14–70B+ models, multilingual vocabularies, and larger embedding sizes.
- CoT length sensitivity: Training capped at 128–512 CoT tokens with early stopping; the impact of CoT length limits and stopping criteria on accuracy, diversity, and stability (including very long chains) is not analyzed.
- Reward design and credit assignment: Only outcome-based rewards on final answers are used. Step-wise, intermediate, or structure-aware rewards (e.g., verifying intermediate derivations) and their effect on stability/diversity are not explored.
- RL algorithm choice: The approach uses RLOO (REINFORCE with group baseline). Comparative studies with PPO/GRPO/Advantage Actor-Critic, off-policy methods, or variance-reduction techniques (e.g., learned baselines, control variates) are absent.
- Exploration mechanism: Gaussian noise on input embeddings is fixed (σ ≈ 0.33·RMS). Schedules (annealing, curriculum), learned or structured noise (e.g., per-dimension, per-layer, adaptive), and alternative perturbations (dropout, stochastic layers, entropy regularization) remain untested.
- Noise placement: Only limited ablations on where to inject noise (input embeddings vs logits). Systematic evaluation across attention keys/values, residual streams, layer norms, or decoder layers could reveal more effective or robust placements.
- Temperature regime coverage: Temperature robustness is reported only for τ ∈ [1e−4, 0.1]; the behavior at moderate/typical sampling ranges (τ ≈ 0.3–1.0) and dynamic schedules during CoT remains unclear.
- Diversity measurement: Pass@32 improvements are attributed to diversity, but diversity is not directly quantified (e.g., distinct CoT paths, token-level/semantic diversity, tree-structure similarity, mutual information across samples). Establishing causality between entropy profiles and true reasoning-path diversity is still open.
- Answer decoding policy: Answers are always decoded greedily at τ=0. This deviates from standard pass@k practices and may confound conclusions about diversity and performance. Evaluating pass@k with answer sampling and comparing policies is needed.
- Generalization beyond math: Out-of-domain evaluation covers HellaSwag, ARC, and MMLU only. Broader domains (code, scientific QA, commonsense multi-hop, knowledge-intensive tasks) and multilingual settings are not assessed.
- Superposition claims in practice: While theory suggests continuous superposition can parallelize search (e.g., graph reachability), the paper does not test tasks explicitly requiring parallel frontier exploration to verify that learned soft CoTs realize such behavior.
- Mechanistic interpretability: No analyses probe whether continuous CoTs encode multiple reasoning paths simultaneously (e.g., path probes, linear concept decomposition, SAE activations, causal interventions, attention-head role analysis).
- Prompt/format sensitivity: Baseline discrepancies (e.g., Qwen 3B zero-shot/format issues) indicate strong sensitivity to prompt formats. Robustness across templates, instructions, and formatting conventions should be measured and controlled.
- Catastrophic forgetting analysis: The “softer touch” claim is based on NLL improvements; there is no deeper analysis (e.g., task-wise Fisher information, forgetting curves, layer-level changes, calibration shifts) to explain why soft/fuzzy training is less destructive.
- Safety/alignment effects: Injecting noise and continuous CoTs may alter safety behavior (e.g., harmful outputs, jailbreak susceptibility, hallucinations). No safety or alignment evaluations are provided.
- Practical deployment of soft inference: Soft/fuzzy inference underperforms hard inference. It remains open how to design inference-time continuous methods (e.g., learned projections, concept-token sparsification, dynamic τ/σ schedules, top-k embedding mixtures) that actually outperform hard decoding.
- Hard vs soft training benefits: Given best deployment uses hard inference on soft-trained models, the benefit may stem from training-time regularization rather than continuous reasoning per se. Controlled studies to disentangle regularization effects from genuine continuous reasoning advantages are needed.
- Comparison to alternative continuous approaches: No head-to-head comparisons with Coconut-style BPTT, CoCoMix, looped/recurrent-depth transformers, compressed CoT, or concept-token sparse mappings on standardized tasks were provided.
- Verification and reward coverage: Reliance on exact-answer verification (Math Verify) excludes tasks with ambiguous or non-extractable intermediate steps or open-ended reasoning. Developing reward models (e.g., learned verifiers, step-level checkers) and testing them is an open direction.
- Entropy–performance linkage: The observed preservation of entropy profiles is suggestive but not sufficient; rigorous studies linking entropy changes to calibration, uncertainty quantification, and pass@k outcomes (including per-step calibration metrics) are missing.
- Vocabulary-size and embedding-mixture distribution shift: Mixing token embeddings via pE may create inputs far from pretraining distribution. The model’s tolerance and adaptation mechanisms (e.g., layer-norm statistics, positional encoding interactions) require investigation.
- Compute/sample efficiency vs discrete RL: The training uses B=2 prompts × G=32 rollouts, 4k steps. Comparative analyses of sample efficiency and compute cost versus discrete-token RL or SFT baselines are absent.
- Soft/fuzzy training collapse cases: Llama-8B hard training collapses on MATH OOD; why soft/fuzzy avoid this is not explained. Identifying root causes (e.g., overconfidence, entropy suppression, gradient pathologies) through controlled ablations is an open problem.
- Early stopping criteria: The CoT early stopping mechanism (Appendix) may bias training/inference. Its impact on accuracy, diversity, and failure modes is not isolated or quantified.
- Reproducibility and release: Code, seeds, and exact training configs are not provided for external replication; sensitivity analyses (random seeds, datasets, hyperparameters) are limited.
These gaps point to concrete follow-up experiments (compute profiling, broader benchmarks, alternative RL and exploration designs, mechanistic probes) and methodological extensions (reward shaping, step-wise verification, improved inference-time soft methods) to validate, strengthen, and generalize the claims of continuous CoT RL.
Practical Applications
Immediate Applications
Below are concrete applications that can be deployed now by leveraging the paper’s key finding: train with continuous (soft/fuzzy) Chain-of-Thought via RL with low-overhead Gaussian exploration in the embedding space, but deploy with standard discrete (hard) inference. This yields pass@1 parity, improved pass@32 diversity, and better preservation of out-of-domain behavior.
- Enterprise domain reasoning fine-tuning (software, finance, legal)
- What: Post-train 3B–8B LLMs on in-house reasoning tasks (e.g., policy compliance Q&A, financial reconciliation, legal clause analysis) without needing labeled discrete CoTs.
- Why: Continuous CoT RL preserves base model generality (improved OOD NLL), avoids overconfidence, and increases sampling diversity for reranking workflows.
- Tools/workflows:
- Fine-tuner that adds “soft/fuzzy CoT RL” into TRL/RL4LMs pipelines (Gaussian noise at input embedding, RLOO baseline, verifier-based rewards).
- Inference stays standard (hard, greedy/sampled decoding) to simplify deployment.
- Optional pass@k sampling with rerankers/verifiers.
- Assumptions/dependencies:
- Availability of automatic or heuristic verifiers (or robust scoring functions) for rewards.
- Compute to sample G≈32 trajectories per prompt during RL.
- Hyperparameter tuning (noise scale, temperature, max CoT tokens) in the reported robust ranges.
- Math tutoring and grading systems (education)
- What: Train small LLM tutors and graders on GSM8K/MATH-like tasks using continuous CoT RL to generate multiple solution paths and robust final answers.
- Why: Pass@32 diversity enables better self-consistency; training does not require CoT annotations; preserves general knowledge (less catastrophic forgetting).
- Tools/workflows:
- Tutor product using “sample-then-verify” or “vote-and-verify” inference, while keeping decoding hard.
- Automated grading via domain verifiers (MathVerify-like pipelines).
- Assumptions/dependencies:
- Reliable answer verification (e.g., expression normalization, unit checks).
- Guardrails for pedagogical safety and age-appropriate content.
- Test-time diverse sampling for decision support (finance, operations)
- What: Use pass@32 sampling from soft-trained models to surface multiple plausible options (portfolio adjustments, scenario analyses, troubleshooting trees).
- Why: The approach increases CoT diversity without sacrificing top-1; enables “what-if” exploration with downstream filtering/constraints.
- Tools/workflows:
- “Generate–Evaluate–Select” loops with business rules and risk constraints.
- Assumptions/dependencies:
- Strong downstream evaluators or constraints to avoid spurious variants.
- Code reasoning with unit-test rewards (software engineering)
- What: Train small code assistants on problem–test-pairs (unit tests as verifiers) using continuous CoT RL; deploy with hard inference.
- Why: Mirrors math-verifier setup; improves diversity of candidate patches/fixes, boosts pass@k with test-based reranking.
- Tools/workflows:
- IDE plugins that trigger k-sample code generations and run unit tests to pick the best.
- Assumptions/dependencies:
- High-quality test suites; sandboxed execution.
- Safer post-training for general-purpose assistants (MLOps, safety)
- What: Replace standard RLHF/fine-tuning on reasoning datasets with soft/fuzzy CoT RL to preserve out-of-domain performance and reduce overconfidence.
- Why: Paper shows better NLL on OOD benchmarks; entropy profiles remain closer to base model’s.
- Tools/workflows:
- “Entropy Inspector” dashboard to track CoT entropy across steps, detect overconfidence shifts, and gate releases.
- OOD NLL or perplexity regression checks in CI/CD for models.
- Assumptions/dependencies:
- Consistent prompt formats; dataset-specific entropy baselines.
- Cost-effective training without CoT annotations (industry and academia)
- What: Avoid expensive CoT collection by training continuous CoTs directly with RL.
- Why: Removes dependence on ground-truth CoT traces; scales to hundreds of CoT tokens with minimal overhead.
- Tools/workflows:
- A “Soft-CoT Trainer” that takes plain problem–answer pairs plus a verifier and returns a soft-trained checkpoint.
- Assumptions/dependencies:
- Verifier availability; compute budget for multi-sample RL.
- Policy and evaluation guidance (policy, governance)
- What: Update model procurement and evaluation checklists to include OOD NLL and entropy-profile deltas after fine-tuning.
- Why: Continuous CoT RL provides a “softer touch” on base models; measurable, auditable preservation of general capabilities.
- Tools/workflows:
- Reporting OOD NLL and entropy trajectory in model cards; threshold-based deployment gates.
- Assumptions/dependencies:
- Access to standardized OOD benchmark suites and procedures.
- Personal study and daily problem-solving assistants (daily life, education)
- What: Homework helpers, puzzle/contest assistants, or planning aids that sample multiple solution paths before finalizing an answer.
- Why: Pass@32 improvements translate to higher self-consistency and better final outcomes when re-ranked.
- Tools/workflows:
- Mobile apps generating multiple candidate plans/solutions with “explain-then-decide” UI.
- Assumptions/dependencies:
- Lightweight verifiers or heuristics to rank candidates; user controls and transparency.
Long-Term Applications
These build on the paper’s methods but require additional research, tooling, verifiers, or scaling.
- Domain-verifier ecosystems for RL at scale (healthcare, law, engineering)
- What: Develop precise automated verifiers (conformance to clinical guidelines, statutory logic checks, engineering spec satisfiability) to unlock continuous CoT RL beyond math/code.
- Why: RL success hinges on reward quality; these verifiers generalize the approach across high-stakes domains.
- Tools/products:
- Verifier SDKs, benchmark suites, and shared registries for domain rewards.
- Assumptions/dependencies:
- Quality, coverage, and legal acceptance of verifiers; governance frameworks.
- Planning and control via superposition reasoning (robotics, logistics)
- What: Combine continuous CoT RL with simulators to train models that explore multiple plan frontiers in parallel and then execute discretely.
- Why: Theoretical results (reasoning-by-superposition) suggest efficiency gains for breadth-first exploration; paper’s training recipe makes this practical.
- Tools/products:
- “Plan-k and verify” controllers; simulation-verifier loops.
- Assumptions/dependencies:
- High-fidelity simulators; safe deployment layers; bridging from language plans to action primitives.
- Multimodal continuous reasoning (vision-language, geospatial, energy)
- What: Extend soft-token RL to multimodal inputs (images, time series); use verifiers such as physical constraints or conservation laws for rewards.
- Why: Many real tasks are multimodal; continuous concepts can capture non-linguistic abstractions.
- Tools/products:
- Energy dispatch advisors, grid anomaly explainers, supply-chain planners with constraint verifiers.
- Assumptions/dependencies:
- Reliable constraints/solvers; data integration pipelines.
- Native pretraining with continuous concept tokens (foundation model training)
- What: Integrate continuous tokens during pretraining to natively support soft reasoning (synergies with looped transformers, latent-depth thinking).
- Why: Could amplify the gains seen in post-training; reduce brittleness of soft inputs.
- Tools/products:
- Pretraining recipes that interleave soft/hard tokens and curriculum schedules; sparse autoencoders to couple spaces.
- Assumptions/dependencies:
- Large-scale compute; evidence that benefits persist at scale and across domains.
- IDE-integrated program synthesis with verifier-guided search (software)
- What: End-to-end synthesis where continuous CoT RL explores diverse tool-call chains; static analyzers/unit tests provide reward signals.
- Why: Better pass@k diversity improves recall of correct pipelines; improves developer productivity.
- Tools/products:
- “Continuous-CoT Synthesis” mode in IDEs; multi-agent tool-use orchestrators.
- Assumptions/dependencies:
- Fast, comprehensive analyzers; robust tool APIs.
- On-device soft-trained small models (edge AI)
- What: Train 3B class models via soft CoT RL and deploy with hard inference on devices for private, low-latency reasoning (education, personal finance planning).
- Why: Minimal inference changes; better generalization preserved on small footprints.
- Tools/products:
- Quantized checkpoints; efficient pass@k sampling with on-device reranking.
- Assumptions/dependencies:
- Memory/compute optimizations; battery and privacy constraints.
- Standardized “entropy health” and OOD-preservation metrics (policy, safety)
- What: Regulators and standards bodies adopt entropy-profile and OOD NLL deltas as required disclosures for post-trained models.
- Why: Empirically aligns with reduced overconfidence and better generalization.
- Tools/products:
- Certification tests; monitoring libraries.
- Assumptions/dependencies:
- Community consensus on thresholds and protocols.
- Scientific assistants exploring multiple hypotheses (academia, R&D)
- What: Assistants that generate diverse chains-of-reasoning and experimental plans, scored by domain-specific plausibility checkers or simulators.
- Why: Pass@32 gains translate into richer hypothesis sets; soft training avoids narrowing of model behavior.
- Tools/products:
- Hypothesis generation platforms with structured verifiers (e.g., chemical property predictors).
- Assumptions/dependencies:
- High-quality scientific validators; careful safety and ethics review.
Cross-cutting assumptions and dependencies
- Reward design is pivotal: math/code benefit from strong verifiers; other domains need credible, automatable reward signals.
- Compute budget: RL uses multiple samples per prompt (e.g., G≈32) and up to hundreds of CoT tokens; still moderate compared to BPTT-based soft methods.
- Generalization beyond 8B and math: Paper shows results up to 8B and math-heavy tasks; replication is advised before critical or regulated deployments.
- Deployment simplicity: Best practice is soft/fuzzy training with standard hard-token inference; changes at inference are not required.
- Hyperparameters: Noise scales around 0.33× RMS embedding norm and CoT temperatures in [0.0001, 0.5] worked; retuning may be needed per domain/model.
- Licensing and safety: Apply domain-specific guardrails; avoid unverified medical/legal advice; ensure compliance for data and model usage.
Glossary
- ARC/AI2 Reasoning Challenge: A multiple-choice benchmark targeting grade-school science reasoning used to assess out-of-domain generalization. "HellaSwag, ARC and MMLU"
- Backpropagation Through Time (BPTT): A training method that backpropagates gradients through all time steps of a sequence model. "similarly to Backpropagation Through Time (BPTT)."
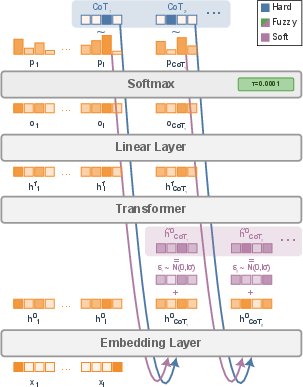
- Categorical sampling: Sampling discrete tokens according to their probability distribution rather than taking the argmax. "Hard tokens: Categorical sampling of ordinary hard CoT tokens with temperature ."
- Chain-of-Thought (CoT): A prompting and generation strategy where models produce intermediate reasoning steps (“thinking tokens”) before the final answer. "Chain-of-Thought (CoT) prompting, where models generate intermediate ``thinking tokens'' before producing final answers."
- CoCoMix: A pretraining approach that intersperses continuous tokens with hard tokens and couples them via a sparse autoencoder. "CoCoMix \citep{tack2025cocomixllmpretrainingcontinuousconcepts} intersperses continuous tokens with hard tokens at pretraining"
- Coconut: A method that distills ground-truth discrete chains of thought into continuous tokens for latent reasoning. "Coconut \citep{hao2024coconut}, in contrast, explicitly ventures into continuous-space reasoning by distilling ground-truth chains of thought into continuous tokens"
- Decoding matrix: The linear layer that maps transformer outputs to vocabulary logits for next-token prediction. "The output encodings are turned into logits by a decoding matrix "
- Directed graph reachability: A decision problem of whether there is a path from one node to another in a directed graph; used as a theoretical testbed for reasoning efficiency. "directed graph reachability far more efficiently than discrete CoT"
- Entropy blowup: A phenomenon where the uncertainty (entropy) of next-token predictions increases dramatically as generation progresses. "entropy blows up as the CoT progresses with hard sampling"
- Entropy profile: The pattern of entropy values of next-token distributions across positions in the generated chain of thought. "We present a detailed analysis of the entropy profiles of models"
- Exploration noise: Random perturbations introduced to enable exploration during reinforcement learning of continuous CoTs. "This noise produces the necessary exploration to apply RL fine-tuning."
- Filler tokens: Bland tokens inserted during pretraining to allow internal continuous computations while processing them. "``Filler tokens'' approaches ... introduce some bland tokens so that the model can use its continuous internal activations to reason while reading the bland tokens."
- Fuzzy tokens: Noisy embeddings of near-discrete tokens obtained by using a very low softmax temperature during the CoT phase. "we use the term \emph{fuzzy tokens} when the temperature used during the chain of thought tends to $0$"
- Gaussian noise: Noise drawn from a normal distribution added to embeddings to enable RL exploration in soft/fuzzy token generation. "add Gaussian noise to the embeddings."
- GRPO: A reinforcement-learning algorithm (a policy-optimization variant) cited as an advanced alternative to vanilla REINFORCE. "More advanced Reinforce-like methods such as RLOO, GRPO, PPO... are derived from Reinforce in the standard way."
- Greedy decoding: Decoding strategy that always selects the highest-probability token at each step. "answers always greedily decoded at temperature 0"
- GSM8K: A math word problem benchmark widely used to train and evaluate reasoning models. "on math reasoning datasets including GSM8K"
- Hard inference: Performing inference with discrete tokens even when the model was trained with continuous (soft/fuzzy) CoTs. "Hard inference on soft models."
- Hard tokens: Standard discrete tokens sampled during generation rather than continuous mixtures. "Hard tokens: Categorical sampling of ordinary hard CoT tokens"
- HellaSwag: A commonsense reasoning benchmark used to evaluate out-of-domain performance. "HellaSwag, ARC and MMLU"
- Latent-space reasoning: Performing reasoning in a continuous internal concept space rather than discrete token space. "see \citet{zhu2025surveylatentreasoning} for a survey on latent-space reasoning"
- Leave-One-Out (LOO) group baseline: A variance-reduction technique for REINFORCE where each sample’s reward is centered by the average reward of other samples from the same prompt. "RLOO, namely, Reinforce using a per-prompt leave-one-out (LOO) group baseline"
- Logits: The unnormalized scores over the vocabulary produced before softmax to obtain probabilities. "The output encodings are turned into logits"
- Looped transformers: Architectures that repeat internal blocks to create potentially infinite depth of continuous reasoning before each token. "``Looped transformers'' ... deploy internal, continuous CoTs in the depth direction of the transformer"
- MATH-500: A curated subset of the MATH benchmark used for evaluation. "MATH-500 \citep{math500_hf} subset of the MATH test set."
- MMLU: A broad multi-task knowledge benchmark (Massive Multitask Language Understanding). "HellaSwag, ARC and MMLU"
- Negative Log-Likelihood (NLL): The average per-token negative log probability of the correct answer, used to assess model calibration/robustness. "negative log-likelihood per token (NLL) of the correct answer."
- OlympiadBench: A challenging benchmark of olympiad-level scientific problems used to test reasoning. "OlympiadBench test sets"
- One-hot vector: A sparse vector representation with a single 1 indicating the token index and 0s elsewhere. "each token can be seen as a one-hot vector "
- Out-of-domain: Tasks or datasets that differ from those used in fine-tuning, used to measure generalization robustness. "out-of-domain tasks"
- Pass@k: The fraction of problems solved when sampling up to k solution attempts; used to measure diversity/accuracy. "pass@$1$ and surpass them for pass@$32$"
- Pause Tokens: Dedicated placeholder tokens inserted to encourage deliberate internal reasoning during generation. "``Pause Tokens'', into rollouts to encourage more deliberate “thinking” in the internal layers."
- PPO: Proximal Policy Optimization, a reinforcement-learning algorithm used for training LLMs. "More advanced Reinforce-like methods such as RLOO, GRPO, PPO..."
- Probability mixture embedding: An input embedding computed as the probability-weighted mixture over token embeddings instead of a single token. "probability weighted mixture embedding, "
- Qwen 2.5 3b Instruct: A specific instruction-tuned LLM used as a base model in experiments. "Qwen 2.5 3b Instruct \citep{Yang2024Qwen25TR}"
- Reasoning by Superposition: A theoretical framework showing continuous thought vectors can encode multiple search frontiers in parallel. "Reasoning by Superposition ... shows that continuous thought vectors can act as superposition states"
- REINFORCE: A policy-gradient method for optimizing expected reward by weighting log probabilities with returns. "By the standard Reinforce theorem \cite{sutton1998}, this is equivalent to minimizing the loss"
- Reinforcement learning (RL): A training paradigm that optimizes model behavior via rewards, used here to learn continuous CoTs. "amenable to reinforcement learning (RL) training"
- RLOO: REINFORCE with Leave-One-Out group baseline; reduces variance by centering rewards per prompt. "RLOO, namely, Reinforce using a per-prompt leave-one-out (LOO) group baseline"
- Root-mean-square norm (RMS): A measure of vector magnitude computed as the square root of the mean of squared components. "0.33 times the root-mean-square norm of the token embeddings"
- Soft inference: Performing inference using soft (continuous) token mixtures rather than discrete tokens. "do \emph{not} confirm previously reported benefits of soft inference on hard (normal) training"
- Soft thinking: Using probability-weighted mixtures of token embeddings during the CoT phase instead of sampling discrete tokens. "In soft thinking \citep{zhang2025softthinkingunlockingreasoning,wu2025llmssinglethreadedreasonersdemystifying}, during the CoT phase, instead of sampling a next token ..."
- Soft tokens: Continuous mixtures of token embeddings (optionally with noise) used during CoT generation. "We call this model soft tokens"
- Softmax: A function converting logits into a probability distribution over tokens. "The next-token probabilities are obtained by applying a softmax"
- Softmax temperature: A scalar controlling the sharpness of the softmax distribution; lower values make distributions peakier. "applying a softmax at temperature "
- Sparse autoencoder: An autoencoder trained with sparsity constraints to learn interpretable latent features; used to couple hard and soft tokens. "uses a pretrained sparse autoencoder to couple the hard and soft tokens."
- Token embedding matrix: The learned matrix that maps one-hot tokens to dense input embeddings. "We denote by the token embedding matrix"
- Transformer stack: The sequence of transformer layers that map input embeddings to output representations. "We denote by the transformer stack"
- Vocabulary size: The number of distinct tokens in the model’s lexicon. "We denote by the vocabulary size."
Collections
Sign up for free to add this paper to one or more collections.

