- The paper’s main contribution is the introduction of RTT, a framework that assigns fine-grained token-level rewards to better align LLMs with rubric-based instructions.
- It employs a token-level relevance discriminator and intra-sample group normalization to overcome reward sparsity and ambiguity in reinforcement learning training.
- Empirical results demonstrate enhanced instruction-following accuracy and training stability across multiple datasets and LLM architectures.
Rubrics to Tokens: Fine-Grained Credit Assignment in Rubric-Based RL for Instruction-Following LLMs
Motivation and Problem Definition
Rubric-based RL has become a central approach for aligning LLMs with multi-constraint, open-domain instruction following tasks, pointing beyond simple preference optimization and RL from verifiable outcomes. However, state-of-the-art methods overwhelmingly depend on response-level (outcome-level) reward aggregation—either using strict conjunction (“all-or-nothing”) or scalarized satisfaction rates—propagating two fundamental problems: (1) reward sparsity, where the RL agent receives almost no signal unless all constraints are satisfied, and (2) reward ambiguity, where disparate constraint profiles are collapsed into identical scalar rewards. These artifacts lead to ineffective or unstable policy improvement in RL, especially when the policy is suboptimal relative to the complexity of the evaluation rubric.
To address the coarse granularity and limited expressiveness of conventional reward aggregation, the paper introduces the Rubrics to Tokens (RTT) framework, explicitly targeting fine-grained, token-level credit assignment derived from structured rubric signals. RTT is predicated on the hypothesis that only subsets of tokens contribute to satisfaction or violation of specific constraints, and that precise reward assignment at the token level can circumvent the inefficiencies and pathologies of response-level feedback.
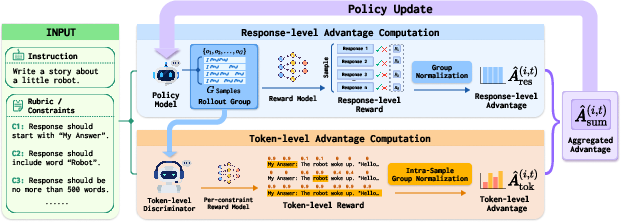
Figure 1: Architecture of RTT: response group generation, response-level advantage computation, token-level relevance discrimination and normalization, and joint advantage aggregation for policy updates.
Methodology
Token-Level Relevance Discriminator
Central to RTT is the training of a Token-Level Relevance Discriminator, which models the mapping from (prompt,constraint,response) triplets to per-token relevance scores in [0,1] that indicate, for each token, its responsibility for a given constraint’s satisfaction (or violation). The discriminator is trained on a corpus augmented with minimally-edited negative samples and LLM-annotated token-level labels, partitioned according to a taxonomy of local/global constraint scope and polarity.
The loss is standard binary cross-entropy over the discrimination output for each relevant token.
Rubric-to-Token Group Relative Policy Optimization (RTT-GRPO)
The RL stage adapts Group Relative Policy Optimization (GRPO) to the token-level regime. At every update, response groups are sampled per instruction, and both response-level and token-level advantages are computed:
- Response-level advantage (A^res): Relative normalization over scalar response scores across the group, as in original GRPO.
- Token-level advantage (A^tok): For each constraint, the discriminator output provides graded token-level reward, which is projected and normalized per response.
Crucially, the intra-sample normalization computes token-level group normalization within each response, rather than across the batch, to obviate length-based bias.
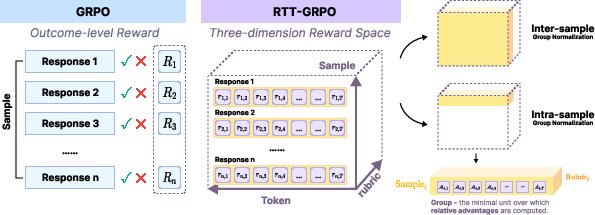
Figure 2: Comparison of reward normalization structures for GRPO (left) and RTT-GRPO (right), motivating inter- vs intra-sample group normalization strategies.
The final joint advantage at each token position is a weighted sum:
A^sum(i,t)=αA^res(i,t)+βA^tok(i,t)
where α,β govern reward composition.
Addressing the Group Partitioning Problem
The transition from scalar to three-dimensional (sample, token, criterion) reward landscapes raises the group partitioning problem: choosing normalization boundaries across axes to ensure unbiased and faithful relative advantages. While “inter-sample” normalization is straightforward but entangles length-based variance, “intra-sample” group normalization ensures that tokens in each response are standardized independently, maximizing fidelity of credit assignment.
Empirical Evaluation
Experimental Setup
The framework is benchmarked on HiR-16K and leading instruction-following datasets (IFEval, IFBench, MulDimIF, AdvancedIF) and OOD datasets (MATH-500, GPQA, MMLU-Pro), with policy and discriminator models drawn from recent Qwen and Llama3 series. Baselines comprise SFT, DPO, and canonical RL-AON/RL-CSR pipelines.
Superiority in Instruction Following
RTT both in CSR and AON variants consistently outperforms all baselines—SFT, DPO, and classic RL—with mean improvements of 2.50% in instruction-level and 1.64% in rubric-level accuracy relative to the best baselines.
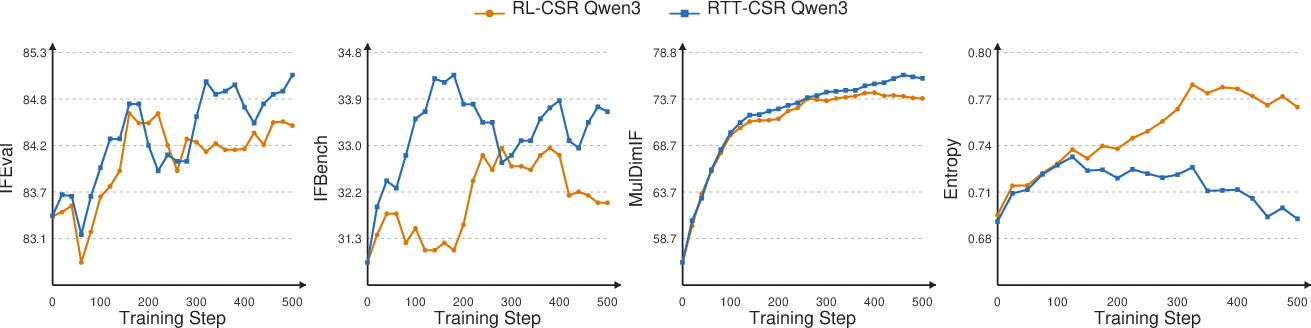
Figure 3: Training curves for RTT-CSR versus RL-CSR. RTT yields improved and more efficient learning curves and consistently lower response entropy, evidencing denser, less ambiguous guidance.
RTT also exhibits smoother, more stable training, as reflected in entropy, KL, and clipping metrics.
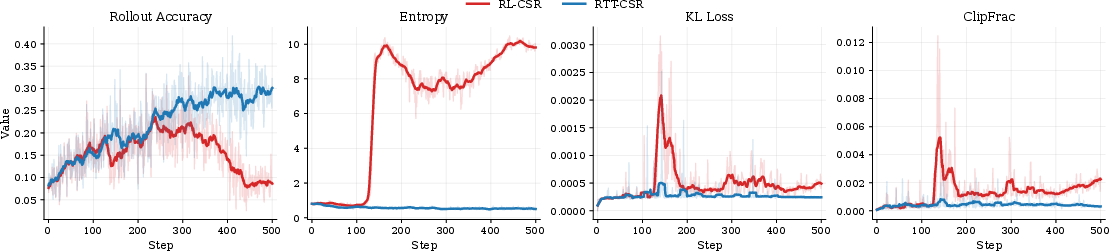
Figure 4: Stability analysis on Llama3.2-3B-Instruct: RTT-CSR remains robust throughout, while RL-CSR is prone to instability.
Robustness Analysis
- OOD Robustness: RTT-trained models generally maintain or marginally improve on OOD tasks (e.g., MATH-500), evidencing absence of catastrophic overfitting to constraint-heavy domains.
- Ablations: Intra-sample group normalization systematically outperforms inter-sample; full taxonomy-based annotation for discriminator training offers clear gains over greedy or random attributions.
- Hyperparameter sensitivity: RTT is robust across a moderate range of token-level weights β.
- Efficiency: Marginal additional GPU overhead (≈8%) for the token-level discriminator.
Token-Level Interpretability
RTT exposes explicit, human-readable token attributions for individual constraints, localizing credit assignment to the directly causative text. This supports interpretability and post-hoc diagnosis in multi-faceted alignment.
Theoretical and Practical Implications
By bridging the granularity gap between holistic rubric assessment and per-token optimization, RTT provides a general recipe for alleviating exploration bottlenecks, improving credit assignment, and fostering stability in deep RL for LLMs, even in the absence of verifiable or decomposable feedback. The introduction of the group partitioning problem frames future research in multi-dimensional reward normalization, connecting to recent findings on reward signal collapse in multi-reward RL (Liu et al., 8 Jan 2026).
Pragmatically, RTT increases the reliability of LLMs for safety-sensitive, rule-heavy, or compositional instruction-following applications and is expected to generalize to hierarchical agent contexts, structured code, and complex scientific/creative writing. Further, the explicit, fine-grained reward attributions produced by the discriminator may prove vital for human-in-the-loop inspection and downstream constraint debugging.
Future Directions
The paper outlines open questions in group partitioning for high-dimensional reward spaces, automated and domain-agnostic token-level supervision, and extension to agentic RL via turn-level discriminators. The formal connection to group normalization and multi-objective RL optimization remains an active area.
Conclusion
RTT provides a principled, empirically validated approach for bridging coarse rubric signals and fine-grained, token-level reward in instruction-following RL. Through token-level discrimination and intra-sample normalization, RTT resolves persistent sparsity and ambiguity issues, yielding stable and performant LLM fine-tuning for complex, rubric-defined objectives. This paradigm establishes a critical step toward more scalable and interpretable RL-based alignment approaches for future LLMs (2604.02795).