- The paper presents TIR-Judge, a framework that integrates code execution with reinforcement learning to improve LLM evaluation.
- It leverages diverse domain training and flexible judgment formats to enhance accuracy in both computational and interpretative tasks.
- Experimental results reveal significant improvements, achieving up to 7.7% gain in pairwise judgment tasks over text-only models.
The paper introduces a novel framework called TIR-Judge for training LLM-based judges with integrated tool capabilities using reinforcement learning. The approach seeks to enhance the reasoning capabilities of LLMs by incorporating precise evaluative tools, such as code executors, into their reasoning processes.
Introduction
LLMs functioning as judges evaluate model-generated outputs and guide the training of LLMs by aligning their predictions with human preferences. These judges traditionally rely on text-based reasoning, which limits their effectiveness in tasks requiring precise computation or symbolic verification. The paper proposes TIR-Judge to address these limitations by integrating a code execution environment into the judgment processes, thereby enhancing the accuracy and versatility of LLM evaluations.
Framework Overview
TIR-Judge is built on three core principles: diverse domain training, flexible judgment formats, and iterative reinforcement learning without distillation. These principles are realized through an end-to-end reinforcement learning framework that integrates a code executor for improved evaluative precision.
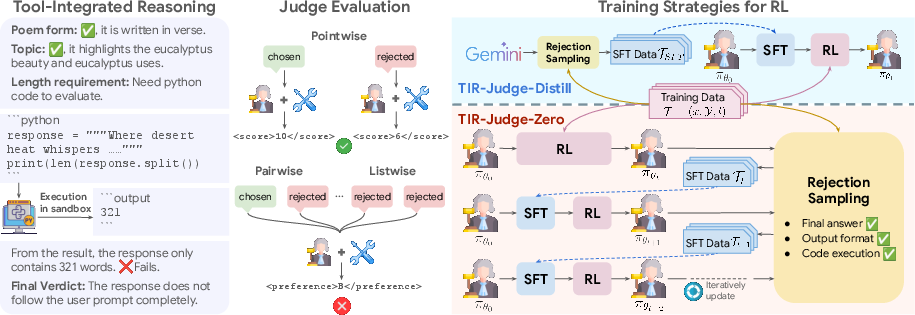
Figure 1: Overall framework of TIR-Judge variants. TIR-Judge natively supports tool use during judgment and is designed to handle diverse input formats.
Key Components
- Task Diversity: TIR-Judge incorporates training data from both verifiable (e.g., math, programming) and non-verifiable (e.g., dialogue) domains. This diversity enables the model to discern when to apply tooling and when intrinsic reasoning suffices.
- Judgment Flexibility: The framework supports multiple judgment formats—pointwise, pairwise, and listwise—ensuring its applicability to various practical scenarios.
- Iterative RL Process: Unlike prior methods relying on distillation, TIR-Judge employs iterative reinforcement learning directly from a baseline model, leveraging rollouts to reinforce tool use and improve reasoning capabilities.
Training Methodology
The training of TIR-Judge is performed in several stages, starting from data collection to iterative refinement using RL. High-quality data pairs are compiled from both human judgments and synthetic examples, ensuring coverage across different domains. The RL setup optimizes the model's ability to alternate between generating code, executing tasks, and refining judgments based on execution results.

Figure 2: The effect of different data mixture used in RL training of TIR-Judge-Zero.
Comparative Analysis
The performance of TIR-Judge was evaluated against various benchmarks, demonstrating substantial improvements over traditional text-only judges. It achieves notable performance gains, with improvements of up to 6.4% in pointwise and 7.7% in pairwise tasks compared to strong reasoning-based judges. The method shows that tool-augmented judges can evolve through self-driven learning without external distilled trajectories.
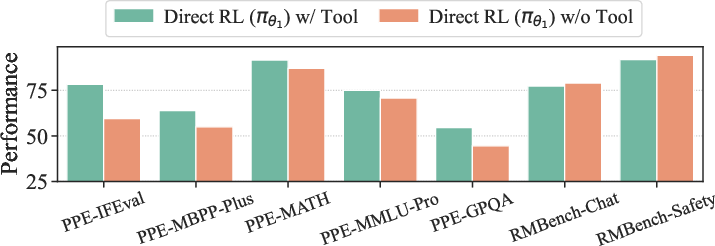
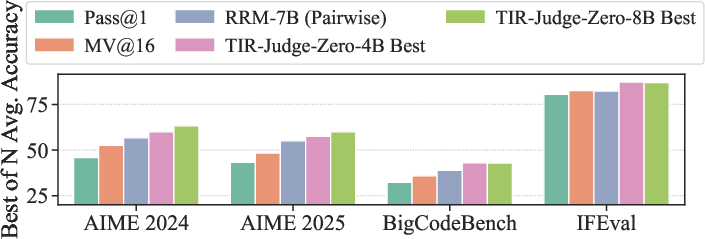
Figure 3: Experimental results comparing tool-augmented judges against text-only judges under the same training data and settings, as well as the best-of-N inference performance.
Iterative Improvement
TIR-Judge can bootstrap its learning using an iterative reinforcement learning process, refining its tool-use ability through self-supervised trajectories. The training methodology introduces data efficiency by circumventing the need for distillation, achieving high performance with fewer parameters.
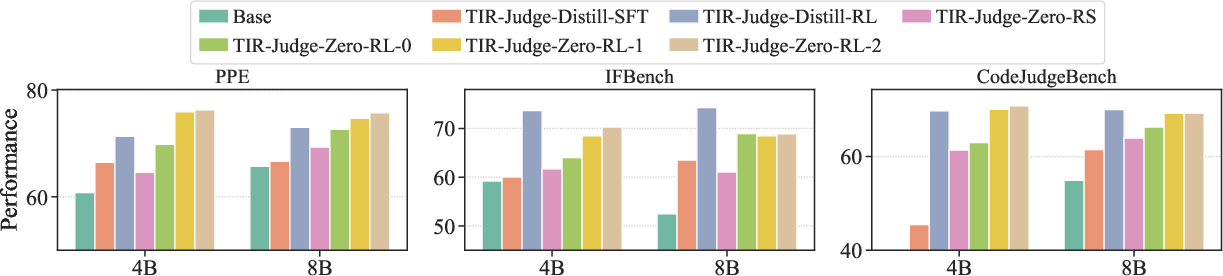
Figure 4: Accuracy of TIR-Judge across different training stages. Base denotes the backbone model without additional training. TIR-Judge-Zero-RS is a variant used in~\cite{zelikman2022star}.
Practical and Theoretical Implications
The introduction of TIR-Judge represents a significant advancement in the LLM evaluation domain by integrating executable tools into the reasoning process. The framework’s success indicates a broader application for integrating various auxiliary functions to bolster interpretative and evaluative tasks in LLMs. Practically, TIR-Judge's approach of reinforcement learning without reliance on distillation charts a scalable path for future AI systems capable of self-improvement.
Conclusion
TIR-Judge demonstrates that integrating tooling directly into LLM training can significantly enhance judgment capabilities, especially for tasks with a computational nature. Future research could expand the scope of integrated tools and explore other domains where precise computation is crucial, further honing the ability of AI to autonomously improve across diverse reasoning tasks.

