TIDE: Every Layer Knows the Token Beneath the Context
Abstract: We revisit a universally accepted but under-examined design choice in every modern LLM: a token index is looked up once at the input embedding layer and then permanently discarded. This single-injection assumption induces two structural failures: (i) the Rare Token Problem, where a Zipf-type distribution of vocabulary causes rare-token embeddings are chronically under-trained due to receiving a fraction of the cumulative gradient signal compared to common tokens; and (ii) the Contextual Collapse Problem, where limited parameters models map distributionally similar tokens to indistinguishable hidden states. As an attempt to address both, we propose TIDE, which augments the standard transformer with EmbeddingMemory: an ensemble of K independent MemoryBlocks that map token indices to context-free semantic vectors, computed once and injected into every layer through a depth-conditioned softmax router with a learnable null bank. We theoretically and empirically establish the benefits of TIDE in addressing the issues associated with single-token identity injection as well as improve performance across multiple language modeling and downstream tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
LLMs break text into tiny pieces called “tokens” (often parts of words). Today’s models look up each token’s ID once at the very start to get an initial vector (its “embedding”), then throw away the token’s ID and rely only on context for the rest of the network. This paper argues that this common design causes two problems, and proposes a fix called TIDE (Token Identity Delivered Everywhere) that keeps a little “who-am-I” signal for each token available at every layer of the model.
What questions the researchers asked
- Why do LLMs struggle more with rare words or names?
- Why do different tokens that appear in very similar sentences sometimes end up with nearly the same internal representation, making the model confuse them?
- Can we change the model so each layer “remembers” which exact token it’s processing, not just its context, and does that help?
How their method works (in simple terms)
Think of a deep model as a tall building with many floors (layers). A token enters the building wearing a name badge (its token ID). In today’s models, the badge is read at the ground floor and then removed, so upper floors only know the token by the conversations happening around it (context).
TIDE gives every floor a way to peek at a copy of the token’s name badge:
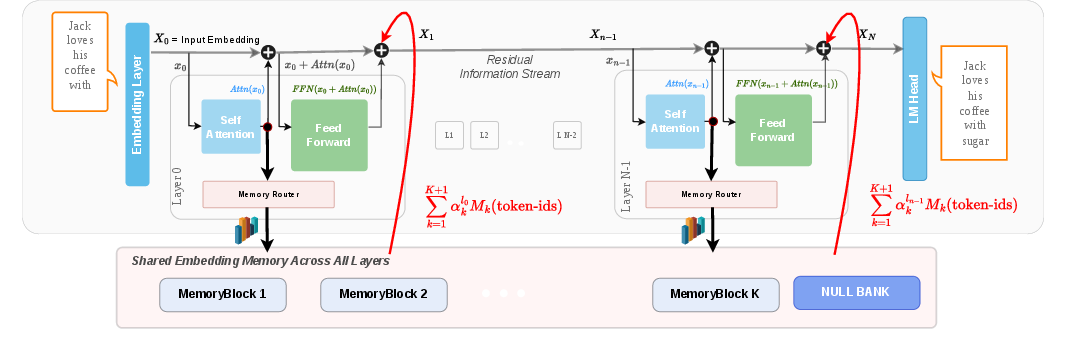
- EmbeddingMemory (many lockers): The model adds K small “memory blocks.” Each memory block is like a locker room that stores a short description for every token, based only on the token’s identity (not on context).
- Router (the chooser on each floor): On every floor (layer), a tiny “router” looks at the current state and decides how much to read from each memory block for that token. There’s also a “null bank” (an off switch) so the router can ignore the memory if it isn’t useful.
- Add the memory to the flow: The chosen memory signal for that token is added to the layer’s computation, alongside the usual context-based processing. That way, every layer has both “who this token is” and “what’s happening around it.”
Why this helps:
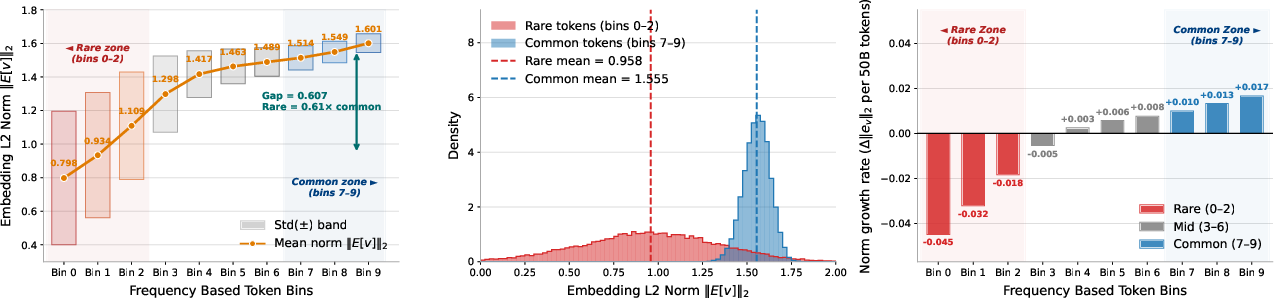
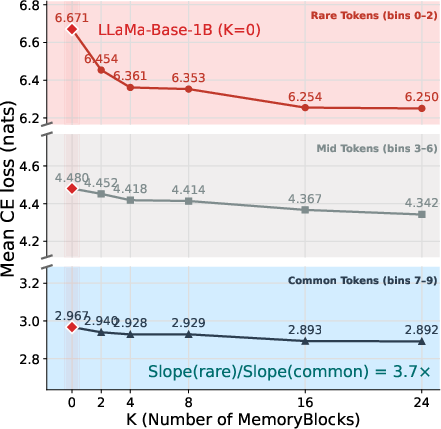
- Rare Token Problem: In normal training, common tokens get lots of updates, while rare ones get very few. With K memory blocks, each rare token gets K pathways to learn, boosting the learning signal it receives.
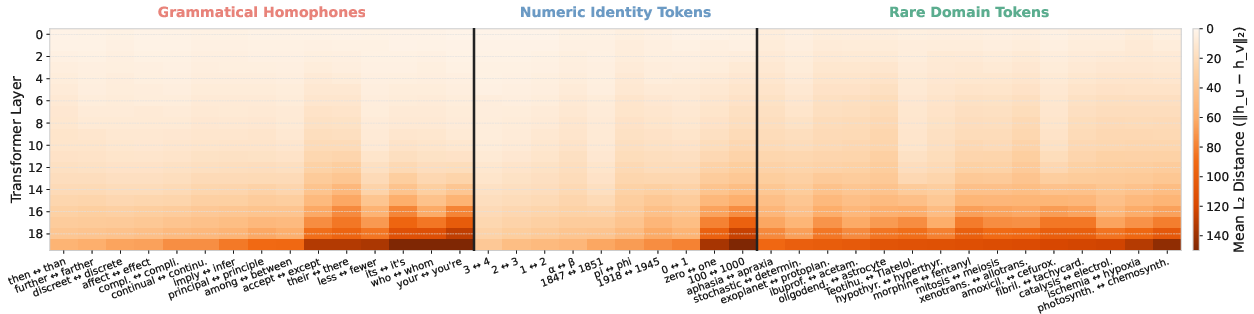
- Contextual Collapse: Sometimes two different tokens in nearly identical sentences look almost the same to the model, making it hard to tell them apart. The memory signal is tied directly to the token’s identity, so it can keep those tokens distinct even when their contexts are the same.
What they found and why it matters
Here are the main results, stated simply:
- Better on rare tokens: TIDE reduces mistakes on rare tokens more than on common ones. That’s important because rare names, dates, and technical terms are where models often fail.
- Less confusion between similar-looking cases: When two different tokens appear in nearly the same context (like “their” vs. “there” or similar numbers), TIDE helps the model keep their internal representations apart, reducing mix-ups.
- Overall performance improves: Across several datasets and tasks (like HellaSwag, ARC, PIQA, BoolQ, and LAMBADA), TIDE consistently beats the standard transformer at similar sizes (from ~750M to 3B parameters).
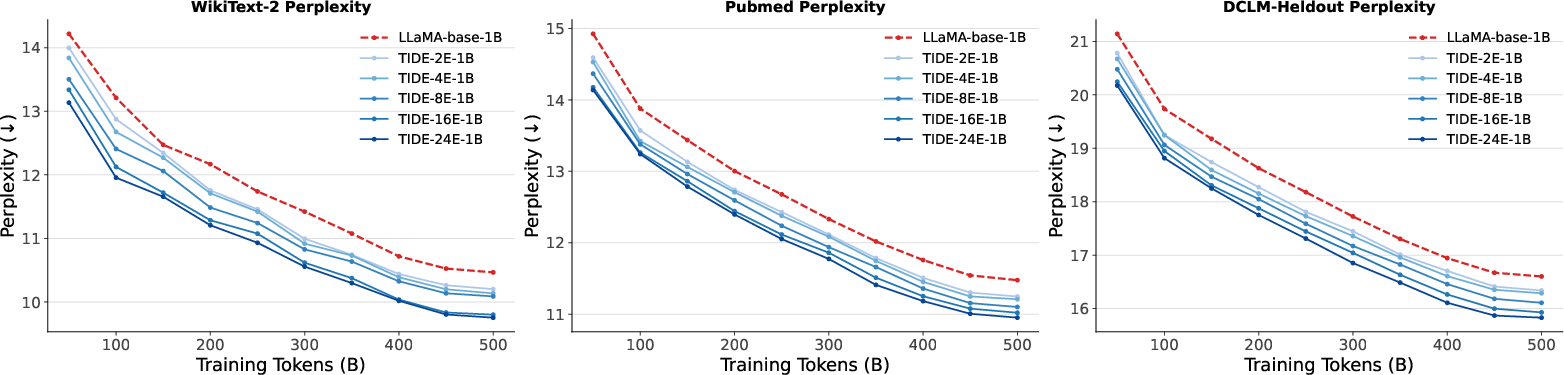
- Benefits show up early and scale with K: Even with just 2–4 memory blocks, TIDE matches or beats the baseline that trained much longer. More blocks (larger K) usually help more, but even small K gives a big chunk of the improvement.
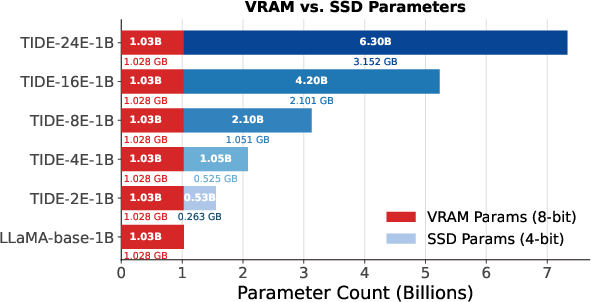
- Small overhead: The memory lookups are cheap, and the extra tables can be heavily compressed and even stored on disk with smart caching, so the GPU memory cost stays close to normal models.
Why this work matters (impact and implications)
- Stronger handling of rare and specific knowledge: By keeping token identity available throughout the model, TIDE helps LLMs remember and use facts about uncommon words, names, and numbers—key for accuracy in real-world texts.
- Fewer “look-alike” mistakes: TIDE makes models less likely to confuse different tokens that appear in similar contexts, improving reliability in tasks that depend on fine distinctions.
- Practical and scalable: The method slots into standard transformers with low cost and can improve models without massive extra compute.
- A design rethink: Just like models repeatedly use position information (so they know order), TIDE shows there’s value in repeatedly giving layers direct access to token identity too—not just context.
In short, the paper proposes a simple architectural tweak—keep a little token-identity memory and let each layer use it—that makes LLMs learn rare tokens better, separate look-alike cases more reliably, and perform better on both language modeling and downstream tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research:
- Scalability to much larger models: Does TIDE’s benefit persist or change at ≥7B–70B+ scales, and how do throughput, convergence, and training stability behave at those scales?
- Fairness of comparisons vs. parameter count: How do TIDE gains compare to baselines that spend the same parameter budget on larger FFNs, wider embeddings, or other standard components rather than MemoryBlocks?
- Inference-time overhead with SSD offloading: What are the real latency/throughput impacts of offloading EmbeddingMemory to SSD under realistic batch sizes, sequence lengths, and cache hit/miss dynamics (including prefetch failures)?
- End-to-end compute and energy costs: What is the net FLOPs, wall-clock time, and energy footprint (training and inference) for TIDE vs. baselines under identical hardware and software stacks?
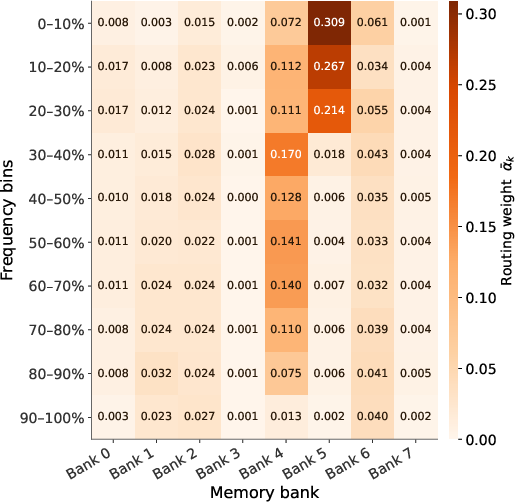
- Router dynamics and stability: Under what conditions does the depth-conditioned router collapse to the null bank or to a single MemoryBlock, and are regularizers (e.g., entropy or diversity penalties) needed to ensure robust multi-block utilization?
- Formalization of K-fold gradient amplification: Theoretical bounds currently assume strictly positive router weights; how do the guarantees change when router mass is small or often allocated to the null bank, and what lower bounds hold on per-block gradients in practice?
- Risk of over-memorization and privacy leakage: Does re-injecting token-identity at every layer increase memorization of rare or sensitive tokens (e.g., PII), and how does TIDE perform on membership inference and extraction tests compared to baselines?
- Polysemy and sense disambiguation: Since MemoryBlocks are context-free, do they bias predictions toward a dominant sense for polysemous tokens? Evaluate on word-sense disambiguation and context-sensitive ambiguity benchmarks.
- Tokenization dependence: How does TIDE’s effectiveness vary with different tokenizers (BPE, Unigram, byte-level, WordPiece) and in morphologically rich languages where subwords are highly ambiguous?
- Multilingual and code domains: The paper focuses on English datasets; does TIDE improve long-tail tokens in multilingual corpora and programming languages with very different token distributions?
- Long-context behavior: How does token-identity re-injection interact with long-context attention (e.g., 32k–128k tokens) and position encodings (RoPE, ALiBi)? Evaluate on retrieval-heavy and long-context benchmarks.
- Broader evaluation coverage: Assess TIDE on reasoning- and math-intensive tasks (e.g., GSM8K, MMLU, BBH), factuality/hallucination benchmarks, and knowledge-heavy QA to test whether identity signals improve or hurt deeper reasoning and factual calibration.
- Error bars and statistical significance: Provide multi-seed runs with confidence intervals to establish the robustness of reported gains across datasets and tasks.
- Ablations of simpler identity-injection baselines: Compare TIDE to cheaper alternatives such as re-adding input embeddings at each layer, learned per-layer token biases, or shallow adapters that carry token identity forward.
- Interaction with MoE and retrieval: How does TIDE interact with mixture-of-experts layers, kNN-LM, and retrieval-augmented generation? Are gains complementary or redundant?
- Post-hoc retrofitting: Can TIDE be added to already pretrained models via fine-tuning (e.g., with LoRA/PEFT) and still yield most of the benefits without full retraining?
- Hyperparameter sensitivity: Systematic study of K (number of MemoryBlocks), d_b (block dimension), router architecture (linear vs. nonlinear), and per-layer placement to determine optimal configurations and diminishing returns.
- Layer-wise injection analysis: Which layers benefit most from identity injection (early vs. mid vs. late), and does restricting injection to certain layers preserve gains while reducing overhead?
- Quantization/compression rigor: Empirically evaluate 4-bit (and lower) quantization of MemoryBlocks across tasks and domains, including potential training-time quantization or mixed-precision schemes.
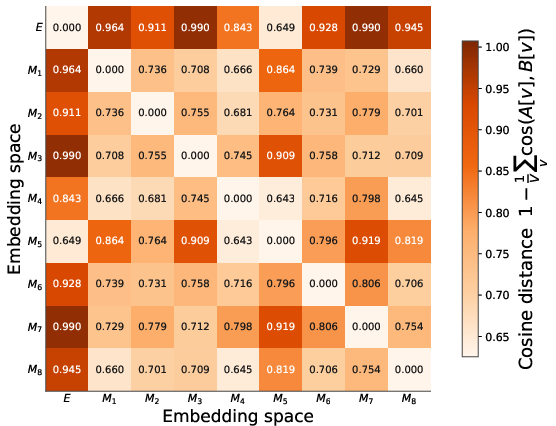
- Content stored in MemoryBlocks: Beyond cosine distances, conduct interpretability analyses to characterize what semantic/factual information MemoryBlocks capture and how it differs from base embeddings and FFN “memories.”
- Impact on common-token performance: While rare tokens benefit most, quantify any trade-offs for common tokens and investigate mechanisms to avoid over-privileging identity over context.
- Numerical reasoning and token identity: TIDE increases separability of numeric tokens, but does this translate into better arithmetic or numeric reasoning performance?
- Data distribution interventions vs. TIDE: Compare TIDE to data-level fixes (e.g., upsampling rare tokens, frequency-aware curriculum) to isolate architectural vs. corpus-intervention gains.
- Regularization for memory overfitting: Explore weight decay/dropout and sparsity constraints on MemoryBlocks to curb overfitting and promote generalizable semantic signals.
- Distributed and multi-GPU deployment: How do MemoryBlocks and router computations scale under tensor/pipeline parallelism, and what are the synchronization and bandwidth costs for the shared memory pathway?
- Reproducibility and release: Clarify training data composition, deduplication, token-frequency statistics, code, and checkpoints to enable independent replication of the reported effects.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s TIDE architecture can be applied today, leveraging its two core benefits: (1) better learning for rare tokens via K-pathway gradient amplification and (2) persistent token-identity signals that reduce contextual collapse across layers.
- Software/AI Infrastructure: Faster, cheaper pretraining and domain-adaptive pretraining (DAPT)
- What: Use TIDE (with K≈2–8) to reach baseline perplexity with fewer tokens and better rare-token coverage, lowering compute cost and time for new or domain-specific LLMs.
- Tools/workflows: Add TIDE blocks to LLaMA-style stacks; enable 4-bit quantized MemoryBlocks and SSD offload with async prefetch; monitor rare-token loss deciles and router weights.
- Assumptions/dependencies: Requires training or continued pretraining; benefits empirically confirmed for 350M–3B models; engineering for SSD prefetch/caching is needed; tokenizer compatibility must be validated.
- Healthcare/Clinical NLP: Improved handling of rare entities (drug names, genes, rare diseases)
- What: Better recognition and generation for medical terminology that follows long-tail distributions; improves clinical summarization, Q&A, and NER on EHRs and biomedical literature.
- Tools/products: Clinical assistants and coders that robustly handle obscure drug/condition names; TIDE-enhanced biomedical LMs.
- Assumptions/dependencies: Needs retraining or DAPT on clinical corpora; strict privacy/security controls for MemoryBlocks if deployed on-device or in hospitals.
- Legal/Compliance: Accurate handling of rare citations, case law, and statutes
- What: Reduce errors on niche legal references and case IDs by maintaining token identity across depth.
- Tools/products: Legal drafting/review assistants; compliance scanners that don’t “collapse” distinct statutes with similar contexts.
- Assumptions/dependencies: Domain corpora availability; legal risk and auditability requirements remain.
- Finance: Long-tail entity coverage and numeracy-sensitive tasks
- What: Enhanced treatment of tickers, CUSIPs, ISINs, and rare corporate names; improved differentiation among numeric tokens that commonly collapse.
- Tools/products: Analyst copilots, compliance/chat tools, and KYC/AML systems that better handle obscure instruments and numeric identifiers.
- Assumptions/dependencies: Gains on numeric reasoning are suggested by reduced collapse for number tokens; full arithmetic improvements may require task-specific fine-tuning.
- E-commerce/Search: Long-tail product SKUs and catalog entities
- What: More reliable query understanding and product matching for rare SKUs/options; improved personalization for niche brands and models.
- Tools/products: Catalog ingestion, product Q&A, and search rerankers that avoid conflating similar items; TIDE-based entity linkers.
- Assumptions/dependencies: Requires integration into existing retrieval/reranking stacks; tokenization for alphanumeric SKUs must be appropriate.
- Software Engineering/Code LMs: Better handling of rare identifiers and APIs
- What: Improve code completion and doc generation for infrequent libraries and project-specific symbols (class/function names, package versions).
- Tools/products: IDE assistants that preserve identity across layers to avoid mixing similar symbol names; repository-aware fine-tunes.
- Assumptions/dependencies: Train/evaluate on code corpora; ensure tokenization captures identifiers effectively.
- Low-Resource and Specialized Languages: Fairer long-tail token treatment
- What: Reduce frequency-induced bias by amplifying gradient pathways for rare vocabulary; improves multilingual/localized assistants and public-service chatbots.
- Tools/products: Government and NGO services in minority languages; localization QA tools.
- Assumptions/dependencies: Data availability; tokenizer coverage for the target language; careful evaluation for fairness and safety.
- Customer Support/CRM: Proper-noun robustness (names, products, locations)
- What: More accurate handling of customer-specific names and niche product references in tickets/chats; fewer mix-ups due to contextual collapse.
- Tools/products: Support copilots integrated with CRM fields; entity-aware summarizers.
- Assumptions/dependencies: Privacy/security of user-specific tokens; fine-tuning with enterprise data.
- Model Ops & Evaluation: Rare-token and collapse-aware diagnostics
- What: Add dashboards tracking decile-wise loss, embedding norms, and layer-wise separation for token pairs; detect and mitigate collapse early.
- Tools/workflows: Router analytics, rare-token regression tests, and frequency-aware training curricula.
- Assumptions/dependencies: Requires logging/telemetry and testbed datasets; organizational processes to act on signals.
- Deployment Engineering: VRAM-efficient inference with SSD-offloaded memory
- What: Keep VRAM near baseline while scaling MemoryBlocks on SSD with 4-bit quantization; suitable for edge servers with ample NVMe.
- Tools/workflows: Async prefetch + cache policies; per-layer routing; quantization pipelines.
- Assumptions/dependencies: Storage bandwidth/latency must meet SLA; robust fallback when cache misses occur.
Long-Term Applications
The following opportunities build on the paper’s method but require further research, scaling experiments, or productization.
- Retrofitting Existing LLMs: Post-hoc addition of MemoryBlocks with minimal retraining
- What: Add TIDE to strong pretrained models and train memory banks/router while freezing most weights to cost-effectively boost rare-token performance.
- Dependencies: Method not evaluated in the paper; needs empirical validation at large scale and careful optimization to avoid catastrophic interference.
- Personalized/Contextual Memory Banks: User- or tenant-specific token memories
- What: Maintain private banks for contact names, internal SKUs, project jargon; dynamically load per session/account to personalize outputs without full fine-tunes.
- Dependencies: Secure isolation, privacy, and governance; on-device or encrypted server storage; router adaptation to per-user distributions.
- Multi-Modal TIDE: Extending token-identity delivery to speech, vision, and robotics
- What: Provide persistent identity signals for subword units in ASR, visual tokens in ViTs, or command tokens in robot policies to avoid collapse of similar-looking/sounding units.
- Dependencies: Redesign MemoryBlocks for non-text tokens; cross-modal router conditioning; multi-modal training regimes.
- Advanced Numeracy and Structured Reasoning
- What: Combine TIDE’s improved numeric token separation with program-of-thought or tool-use to yield stronger arithmetic/financial reasoning.
- Dependencies: Benchmarks show separation gains but not full reasoning; requires algorithmic prompting/tools and targeted training.
- Retrieval-Augmented Generation (RAG) Synergy
- What: Use MemoryBlocks to store long-tail lexical and entity priors while retrieval handles dynamic knowledge; routers can adaptively favor memory vs. context vs. retrieved facts.
- Dependencies: Joint training or scheduling strategies; evaluation to avoid redundancy or overreliance on static memory.
- Continual/Federated Learning: On-device memory updates
- What: Update MemoryBlocks with user/device data to improve rare-token coverage locally while keeping core model static.
- Dependencies: Federated optimization, privacy-preserving aggregation, drift detection, and rollback mechanisms.
- Tokenizer Co-Design: TIDE-aware vocabulary and segmentation
- What: Co-optimize BPE/SentencePiece with TIDE to ensure rare but meaningful entities are tokenized in ways MemoryBlocks can exploit.
- Dependencies: Automated pipelines for frequency-aware vocab selection; evaluation on downstream tasks and languages.
- Fairness/Governance Standards: Long-tail competence requirements
- What: Incorporate rare-token performance and collapse metrics into procurement/compliance checklists (e.g., for public services, healthcare).
- Dependencies: Community benchmarks and reporting standards; regulatory guidance on representational fairness.
- Hardware/Systems Support: Dedicated prefetch and memory pathways
- What: Accelerator/runtime features for low-latency MemoryBlock lookup and routing; compiler support for mixed VRAM/SSD execution plans.
- Dependencies: Collaboration with hardware vendors; profiling at 10B–70B+ parameter scales.
- Knowledge Editing and Safety
- What: Use separable MemoryBlocks to localize and update rare or sensitive facts with minimal collateral effects; facilitate safer “edits.”
- Dependencies: Robust editing algorithms for MemoryBlocks; safeguards against adversarial token-level manipulation; rigorous evaluation.
Notes on Assumptions and Dependencies (Cross-Cutting)
- Scaling and Generality: Reported gains are demonstrated up to 3B parameters; behavior at tens of billions of parameters and across diverse instruction-tuned/chat models remains to be validated.
- Training Access: Most benefits require training or continued pretraining with TIDE; drop-in improvements without training are unlikely.
- Tokenization: Effectiveness depends on how well entities of interest are tokenized; revising vocabularies may be necessary for maximum benefit.
- Systems Engineering: SSD offload and prefetch can reduce VRAM but introduce latency risks; productionization needs careful caching and monitoring.
- Privacy/Security: If MemoryBlocks encode sensitive or user-specific tokens, access controls, encryption, and auditability become essential.
- Benchmarking: New diagnostics (e.g., collapse sets, rare-token deciles) should accompany deployment to ensure benefits persist under real workloads.
Glossary
- Additive fusion: An operation that injects additional signals into the model by adding vectors to the residual stream within each layer. "Depth-conditioned router and additive fusion:"
- Asymptotic Generalization: The property that TIDE can approximate the standard transformer arbitrarily well by routing to the null bank to suppress memory contributions. "Asymptotic Generalization to Standard Transformer."
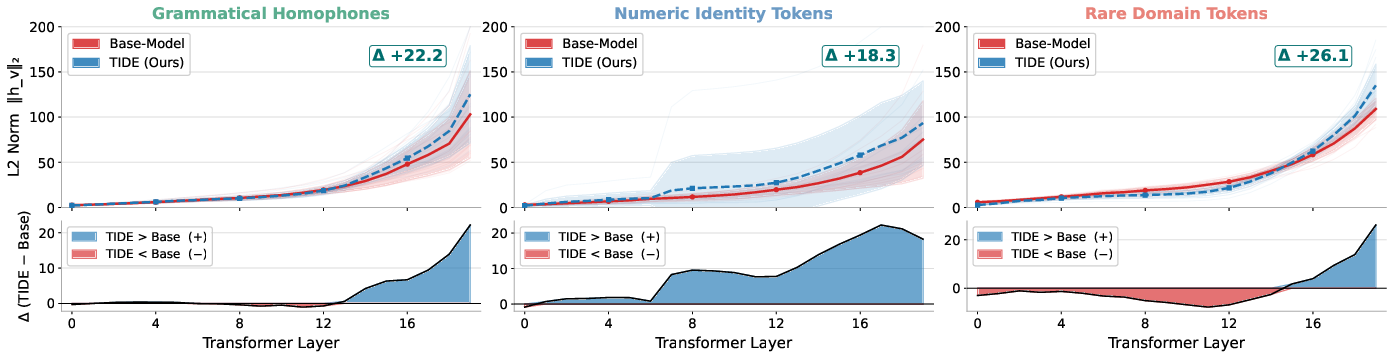
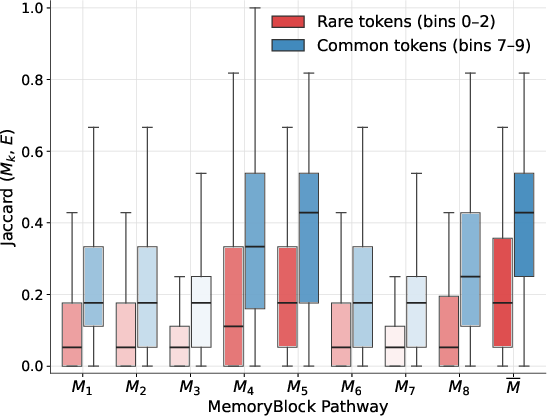
- Contextual Collapse: A failure mode where different tokens’ hidden states become nearly indistinguishable when their contexts are similar, making them hard to separate downstream. "Empirical Evidence of Contextual Collapse:"
- Contextual Collapse Set: The set of token pairs whose hidden states at a given layer are within a small distance across contexts. "Contextual Collapse Set"
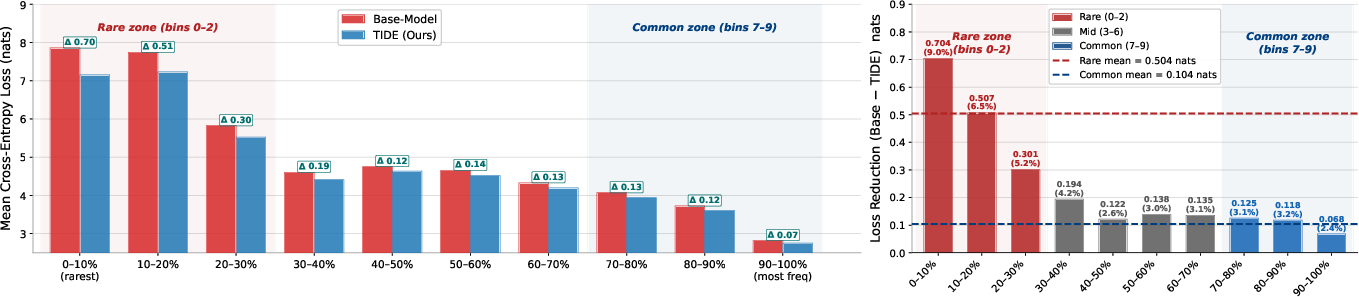
- Cross-entropy loss: A negative log-likelihood objective used to evaluate language modeling performance. "Mean validation cross-entropy loss per frequency decile of LLaMa-Base-1B and TIDE-8E-1B trained with $200$B tokens."
- EmbeddingMemory: A TIDE module that ensembles multiple MemoryBlocks mapping token indices to context-free vectors injected at every layer. "TIDE introduces EmbeddingMemory, an ensemble of independent MemoryBlocks"
- Feed-Forward Network (FFN): The position-wise MLP block in transformers that processes normalized hidden states after attention. "and is a SiLU-gated feed-forward network."
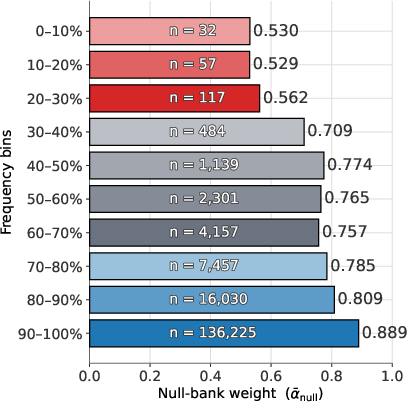
- Gradient Starvation: The under-training of rare-token embeddings due to infrequent appearances and thus fewer gradient updates. "Gradient Starvation Bottleneck:"
- Hapax: A token appearing only once in a corpus (hapax legomenon), representing the rarest frequency tier. "Hapax (rarest)"
- K-Pathway Gradient Amplification: TIDE’s mechanism where K independent MemoryBlocks provide parallel gradient routes, amplifying per-token signal. "Proposition [-Pathway Gradient Amplification]"
- Lipschitz continuity: A constraint bounding how much an FFN’s output can change for small input changes, limiting separation of collapsed tokens. "the Lipschitz continuity imposed on any FFN by its continuous domain."
- MemoryBlock: An independent embedding table in TIDE that maps discrete token indices to learned, context-free semantic vectors. "consisting of independent MemoryBlock, each mapping raw token indices to context-free token identity signal."
- NULL bank: A zero-vector option in the router that lets the model shut off memory injection at a layer. "via a depth-conditioned router with a NULL bank."
- Perplexity: A standard metric for LLMs measuring how well they predict a sequence; lower values are better. "the validation perplexity on three datasets"
- Power-law scaling: A heavy-tailed distribution pattern where a few tokens are very common and many are rare. "Natural language vocabularies obey power law scaling, specifically Zipf's law"
- Rare Token Problem: The issue that rare tokens receive insufficient training signal, leaving their embeddings under-trained. "The Rare Token Problem:"
- Residual stream: The main signal pathway in transformers that carries layer outputs forward via skip connections. "preserving the residual stream's role as a shared communication channel"
- RMSNorm: Root Mean Square Layer Normalization, a normalization method applied to vectors without centering. "a single embedding lookup followed by RMSNorm"
- RoPE (rotary position embeddings): A method for injecting positional information into attention that can be reapplied at every layer. "position, which is re-injected via RoPE at every attention layer"
- SGD (stochastic gradient descent): An optimization algorithm updating parameters using mini-batch estimates of the gradient. "Under minibatch SGD"
- SiLU: The Sigmoid Linear Unit activation used to gate the FFN in the transformer block. "and is a SiLU-gated feed-forward network."
- Single-injection assumption: The design choice to inject token identity only once at the input embedding layer and discard it thereafter. "This single-injection assumption creates two distinct failure modes:"
- Softmax router: A gating mechanism that assigns mixture weights over MemoryBlocks (and the null bank) using a softmax. "via a per-layer softmax routing mechanism"
- TIDE: The proposed architecture (Token Identity Delivered Everywhere) that reinjects token identity at every layer via EmbeddingMemory. "we propose TIDE (Token Identity Delivered Everywhere)"
- Token index: The discrete identifier of a token used to retrieve its embedding from an embedding table. "The token index is looked up once at the input embedding layer and then permanently discarded."
- Unigram probability: The probability that a randomly drawn token position contains a specific token, based on its frequency. "is the unigram probability of "
- Zipf's law: A specific power-law describing token frequency distributions in natural language where rank is inversely proportional to frequency. "Zipf's law"
Collections
Sign up for free to add this paper to one or more collections.