Rethinking Token Prediction: Tree-Structured Diffusion Language Model
Abstract: Discrete diffusion LLMs have emerged as a competitive alternative to auto-regressive LLMs, but training them efficiently under limited parameter and memory budgets remains challenging. Modern architectures are predominantly based on a full-vocabulary token prediction layer, which accounts for a substantial fraction of model parameters (e.g., more than 20% in small scale DiT-style designs) and often dominates peak GPU memory usage. This leads to inefficient use of both parameters and memory under constrained training resources. To address this issue, we revisit the necessity of explicit full-vocabulary prediction, and instead exploit the inherent structure among tokens to build a tree-structured diffusion LLM. Specifically, we model the diffusion process with intermediate latent states corresponding to a token's ancestor nodes in a pre-constructed vocabulary tree. This tree-structured factorization exponentially reduces the classification dimensionality, makes the prediction head negligible in size, and enables reallocation of parameters to deepen the attention blocks. Empirically, under the same parameter budget, our method reduces peak GPU memory usage by half while matching the perplexity performance of state-of-the-art discrete diffusion LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to build and train LLMs called a Tree-Structured Diffusion LLM (TDLM). Instead of guessing the next word or piece of a word from the entire dictionary all at once, it organizes the vocabulary into a tree and makes a series of small, simple choices—like moving down a family tree from broad groups to a specific item. This makes the model much more memory‑friendly and faster to train while keeping its text quality strong.
What questions are the researchers trying to answer?
They focus on two big questions:
- Do LLMs really need to choose from every token (word piece) in the whole vocabulary at once?
- Can we use the natural structure and similarities among tokens to make training far more efficient without hurting performance?
How does their method work?
Think of the vocabulary (all the tokens the model can output) as a big tree:
- The root is the “everything” category.
- Each level splits the vocabulary into smaller, more specific groups.
- The leaves at the bottom are the actual tokens (like “play”, “##ing”, or punctuation).
Instead of one huge “pick the right token from 50,000 options” step, the model:
- Starts near the top of the tree and repeatedly asks a simpler question: “Which child of this node is correct next?”
- Moves down the tree level by level until it lands on a single token.
Here’s the idea in everyday terms:
- It’s like playing “20 Questions.” Rather than guessing the exact answer immediately, you narrow down the possibilities with a few small questions.
They use a “diffusion” approach:
- Diffusion models create things step by step, gradually cleaning up noise into a clear result. For language, that means refining rough guesses into precise tokens over several steps.
- TDLM aligns each diffusion step with a level of the tree: it makes a coarse choice first, then finer choices later.
How the tree is built:
- The authors group similar tokens together (using a clustering method) and arrange them into a balanced tree so every token is at the same depth. That keeps the steps organized and predictable.
Why this helps:
- The final “prediction head” (the part that picks the next item) shrinks dramatically. Instead of a giant layer that scores every token, it only scores a small set of children at each step.
- This cuts memory use and frees up room to make the core of the model deeper and smarter.
What did they find, and why does it matter?
Main findings:
- Much smaller output layer: In one example, the output layer shrank by about 100×.
- Big memory savings: Training needed about half the peak GPU memory compared to popular diffusion-based baselines.
- Strong quality: Despite being more efficient, the model’s perplexity (a “how confused is the model?” score—lower is better) matched or beat state‑of‑the‑art diffusion LLMs at similar sizes.
- Better use of parameters: Because the output layer is smaller, they could add more attention blocks (the “thinking” parts) without increasing the total size too much, improving overall performance.
Why it matters:
- Training becomes feasible on smaller or cheaper hardware (like consumer GPUs or edge devices).
- Faster training and better throughput mean researchers and developers can iterate more quickly.
- Efficiency gains don’t come at the cost of worse text quality.
What could this change in the future?
- More accessible AI: Easier training on limited hardware could open language modeling to more labs, schools, and startups.
- Better architecture choices: Saved memory and parameters can be moved into parts of the model that matter more, like deeper reasoning layers.
- New modeling ideas: Predicting “children” instead of entire tokens could enable advanced strategies like joint predictions over multiple positions or larger, more expressive vocabularies without increasing sequence length.
- Practical deployments: Memory‑efficient models are attractive for on-device applications where hardware is tight.
In short, this work shows that by turning “guess one from everything” into “step-by-step choices in a tree,” we can make LLMs lighter, faster, and still smart—an important step toward powerful models that are easier to train and deploy.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete gaps that future research could address.
Theory and Modeling Formulation
- Non-CTMC cross-level dynamics: The overall process is not a CTMC (singularities at level thresholds), but no theoretical analysis is provided on the implications for consistency, stability, or convergence of sampling across levels; error accumulation at level boundaries remains unquantified.
- Training signal sparsity and weighting: The in-level ELBO contributes nonzero terms only under specific events (e.g., when the state has not transitioned yet), but there is no analysis of gradient variance, sample efficiency, or principled level-weighting schemes beyond limited heuristics.
- Schedule design: The choice and shape of in-level schedules α_th are not justified theoretically; there is no guidance or method to learn α_th per level or per context to optimize ELBO or generation quality.
- Reverse-process parameterization: The reverse kernel conditions on predicted children distributions; alternative parameterizations (e.g., hybrid parent-child targets, auxiliary consistency losses, or denoising score matching in discrete spaces) are not explored.
- Error propagation across levels: Misclassification at higher (coarser) levels may irreversibly constrain lower-level predictions; no formal analysis or mitigation (e.g., soft branching, uncertainty-aware branching, or corrective refinement) is provided.
Vocabulary Tree Construction and Representation
- Static, pre-constructed tree: The tree is built offline (recursive K-means), but there is no method to learn or adapt the hierarchy jointly with the model (e.g., differentiable tree learning, bilevel optimization, RL-based structure search).
- Embedding source and criteria: The embedding space and criteria used for clustering (semantic, syntactic, frequency, morphology) are not systematically compared; the effect of different embedding sources (e.g., contextual vs static embeddings) on tree quality is unknown.
- Non-uniform branching and depth: Only fixed branching factor K and padded uniform depth are used; the impact of variable branching per node, depth regularization, or adaptive mixed-arity trees on performance and efficiency is unexplored.
- Padding artifacts: Repeating terminal tokens to enforce uniform depth could bias training or distort level-wise ELBO; no ablation quantifies its effect or proposes alternatives (e.g., virtual nodes, skip transitions, or learned padding).
- Tokenizer dependence: Interactions with different tokenizers (BPE vs SentencePiece vs unigram), vocabulary sizes, and token distributions—especially for agglutinative or morphologically rich languages—are not studied.
Training and Inference Procedures
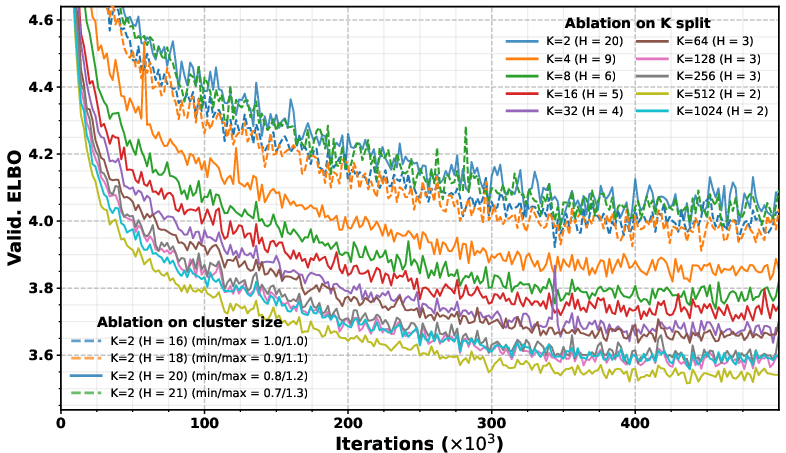
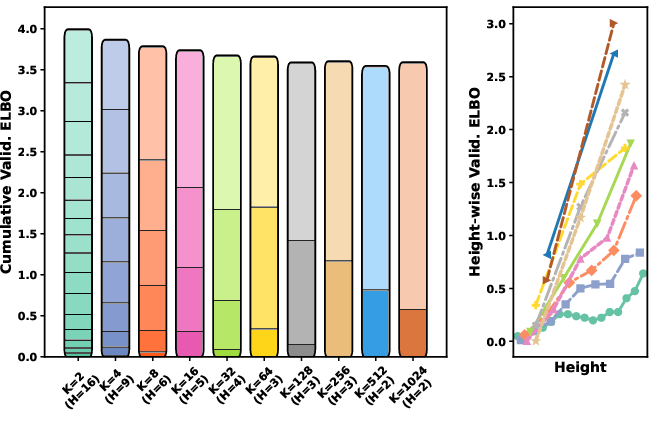
- Step allocation policy: Only two-level (H=2) step allocation is examined, showing balanced steps perform best; no general policy, adaptive scheduling (e.g., uncertainty- or entropy-based), or per-example step allocation is developed for deeper trees.
- Discretization and numerical issues: The continuous-time derivation is trained with sampled t; discretization error, step-size sensitivity, and numerical stability across levels are not analyzed.
- Loss alternatives: Beyond cross-entropy-like child prediction, no alternative objectives (e.g., margin-based losses, mutual information maximization, consistency regularizers between adjacent levels) are evaluated to balance level-wise learning.
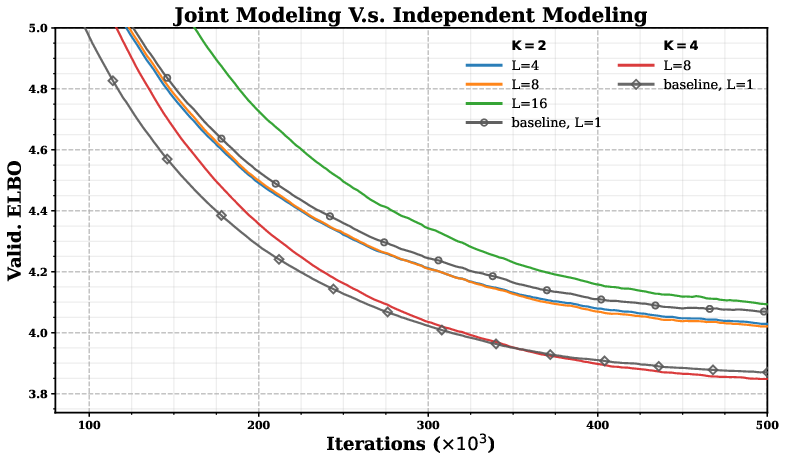
- Joint modeling: The paper hints at tractable joint modeling due to reduced output space but does not present a concrete method or empirical evaluation for joint multi-token or structured outputs.
- Curriculum or progress-aware training: No exploration of curricula (e.g., start from coarse levels and progressively unfreeze deeper levels) to stabilize training or improve sample efficiency.
Empirical Scope, Evaluation, and Scalability
- Limited datasets and tasks: Results are restricted to OpenWebText; generalization to larger corpora (e.g., C4, The Pile), downstream tasks, multilingual corpora, or code/data-to-text is untested.
- Scale limits: Only small/base-scale models are reported; behavior at larger parameter counts and with larger vocabularies (e.g., 200k–1M tokens) is unknown.
- Inference efficiency vs AR baselines: While training memory is improved, wall-clock inference latency and throughput (vs autoregressive models or other DLMs) are not compared for matched quality and sampling steps.
- Fairness of comparisons: Parameter savings are reallocated to deepen the backbone; causal attribution (head reduction vs deeper network) is not fully disentangled via controlled studies (same backbone, varying head design only).
- Calibration and uncertainty: No evaluation of probability calibration, confidence estimation, or uncertainty propagation across levels; effects on downstream risk-sensitive tasks are unknown.
- Generation quality beyond perplexity: Human evaluations, factuality, coherence, and diversity assessments are absent; reliance on (generative) perplexity may miss qualitative differences introduced by hierarchical decoding.
Robustness, Safety, and Practical Considerations
- Robustness to tree quality: Sensitivity to poor or misaligned trees (e.g., noisy embeddings, domain shift) is not quantified; no strategies for tree repair, pruning, or online refinement are provided.
- Bias and harm propagation: Hierarchical clustering may group sensitive terms or dialects in ways that amplify bias; there is no analysis of fairness, bias mitigation, or the impact of tree structure on representational equity.
- Compatibility with efficiency tricks: Interactions with activation checkpointing, mixed precision, parameter-efficient finetuning (e.g., LoRA), and activation compression are not systematically benchmarked.
- Engineering overhead: The runtime and memory overhead of managing Γ↑/Γ↓ mappings, variable sibling set sizes, and dynamic batching across levels is not reported; guidelines for efficient implementation are missing.
- Deployment on edge devices: Although memory savings are highlighted, quantitative end-to-end deployment studies (latency, energy, model size on-device) are not provided.
Extensions and Alternatives
- Context-dependent subtrees: The method uses a global, static tree; dynamically selecting context-relevant subtrees (e.g., via retrieval or gating) to further shrink the output space is not explored.
- Hybrid heads: Combining tree-based heads with a small fallback flat head for rare tokens or uncertainty cases is not considered; might mitigate hard errors at high levels.
- Learnable schedules and branching: No exploration of learning K per node, adaptive α_th, or level transition times t_h to optimize a compute–quality trade-off.
- Constrained/grammar decoding: The hierarchical structure could enable grammar- or schema-constrained decoding; this integration and its benefits are not investigated.
- Tokenizer expansion: The paper suggests reallocating saved parameters to expand the vocabulary, but provides no methodology or experiments showing benefits or trade-offs (sequence length, sparsity, rare-token modeling).
Reproducibility and Clarity
- Tree-building details: Precise sources of token embeddings, normalization, clustering initialization, and seeding for the recursive K-means are not specified, hindering replication.
- ELBO constants and implementation: Practical computation of constant terms, variance reduction techniques, and batching strategies for the in-level ELBO are not detailed.
- Equation and notation errors: Several typographical inconsistencies (e.g., missing brackets/superscripts) in key equations may impede faithful reimplementation; a corrected mathematical appendix would improve reproducibility.
Practical Applications
Overview
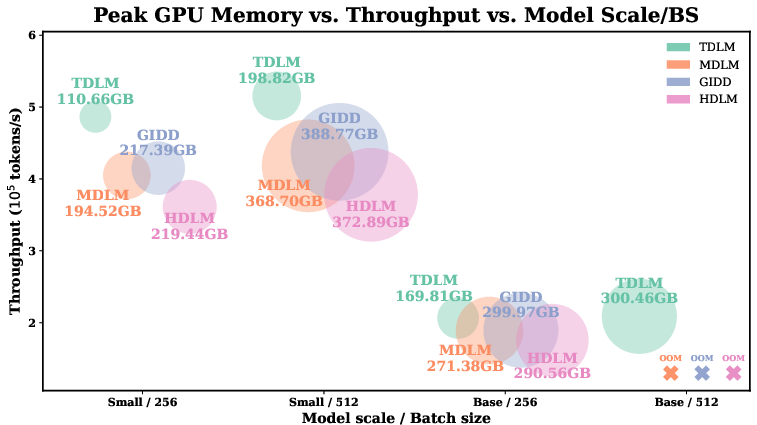
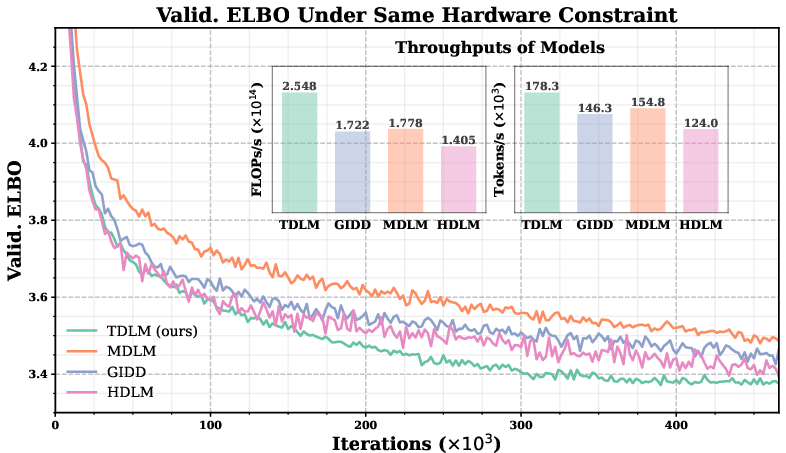
The paper introduces a Tree-Structured Diffusion LLM (TDLM) that replaces full-vocabulary token prediction with hierarchical child prediction over a pre-constructed vocabulary tree. This reduces the classification head size from O(d×V) to O(d×K), substantially lowering parameters and training activation memory while maintaining competitive perplexity. The method includes a continuous-time Markov chain (CTMC) formulation, closed-form in-level ELBOs, and practical tree construction via recursive K-means. Empirically, TDLM halves peak GPU memory and improves throughput by ~25% in small models, enabling deeper backbones under the same budget.
Below are practical applications derived from the paper’s findings and methods, grouped by deployment timeline.
Immediate Applications
The following items can be deployed now with reasonable engineering effort and are directly supported by the paper’s demonstrated efficiency gains and implementation details.
- Software/AI Engineering: Cost-efficient training of diffusion LMs
- Use case: Train base-scale diffusion LMs on limited hardware (e.g., 4×24GB GPUs) by swapping full-vocabulary heads for TDLM’s child-prediction head.
- Tools/products/workflows: PyTorch or JAX implementation, a HuggingFace-compatible module, and the paper’s recursive K-means tree builder; reallocate saved parameters to deepen attention blocks for performance.
- Dependencies/assumptions: Quality of the vocabulary tree (branching factor K, height H, cluster balance); task fit for diffusion LMs; stable training schedules (αt) per level.
- Edge & Mobile AI: On-device inference and fine-tuning for text tasks
- Use case: Run smaller-memory LMs for keyboards, offline translation, note-taking, and smart assistants on smartphones, wearables, and AR devices.
- Tools/products/workflows: Deploy TDLM heads in CoreML/NNAPI/TensorRT runtimes; store compact tree metadata; balance inference steps across levels for latency/quality.
- Dependencies/assumptions: Diffusion inference requires multiple steps; latency constraints may necessitate step scheduling and pruning; device-optimized kernels for small-K softmax.
- Healthcare (on-prem/private): Privacy-preserving clinical text modeling
- Use case: Summarize/structure clinical notes and generate discharge summaries on hospital GPUs without cloud data transfer.
- Tools/products/workflows: Domain-specific token tree (medical terminology clustering), local TDLM training with memory savings, compliance logging.
- Dependencies/assumptions: Domain tree construction aligned with medical vocabularies; clinical evaluation and regulatory approvals; integration with EHR systems.
- Finance and Compliance: Lexicon-constrained generation via branch gating
- Use case: Enforce terminology and prevent disallowed outputs by pruning branches in the token tree during generation.
- Tools/products/workflows: Decoder-side “policy gate” that masks disallowed children sets contextually; audit trails for gating decisions.
- Dependencies/assumptions: Reliable mapping from tokens to compliance categories; careful maintenance of tree-taxonomy alignment over updates.
- Software Engineering: Grammar-constrained code generation
- Use case: Improve syntactic correctness by limiting predictions to grammar-valid children (e.g., integrating SynCode-like grammar augmentation).
- Tools/products/workflows: Combine TDLM child prediction with language grammars; IDE plugins for code completion with constrained decoding.
- Dependencies/assumptions: Accurate grammar-to-tree alignment; robust handling of long-tail tokens and domain-specific libraries.
- Education & Academia: Democratized LM training for coursework and research
- Use case: Allow students and small labs to train competitive base-scale diffusion LMs using modest hardware.
- Tools/products/workflows: Teaching materials on tree construction, CTMC ELBO derivations, and ablation procedures; reproducible TDLM baseline.
- Dependencies/assumptions: Open-source TDLM implementations; datasets with permissive licenses; instruction-tuning resources if needed.
- Energy & Sustainability Reporting: Lower training footprint
- Use case: Track and reduce energy-per-token metrics by halving peak memory and boosting throughput.
- Tools/products/workflows: MLOps dashboard integrating GPU memory and FLOPs/s metrics; ESG reporting for model training pipelines.
- Dependencies/assumptions: Organizational measurement frameworks; consistent benchmarking for fair comparisons across architectures.
- Enterprise MLOps: Throughput and capacity gains in existing pipelines
- Use case: Train deeper backbones within fixed compute budgets; run more experiments or larger batches.
- Tools/products/workflows: CI/CD integration of TDLM layers; hyperparameter templates for per-level schedules and step allocation.
- Dependencies/assumptions: Stable TDLM training under diverse corpora; predictable behavior under scaling and distributed training.
- Domain Tokenization & Vocabulary Design: Better subword structure
- Use case: Build domain-optimized trees (legal, technical, biomedical) to improve modeling efficiency and perplexity.
- Tools/products/workflows: Library to construct balanced trees via recursive K-means over domain embeddings; uniform leaf-depth padding utilities.
- Dependencies/assumptions: High-quality domain embeddings; careful choices of K/H and min/max node-size ratio to avoid degenerate clusters.
Long-Term Applications
These items likely require further research, scaling, validation, or co-design efforts to reach production maturity.
- Safety and Controllable Generation: Policy-constrained hierarchical decoding
- Use case: Dynamic branch pruning to enforce safety policies (toxicity, privacy) at generation time.
- Tools/products/workflows: Safety taxonomies mapped onto tree nodes; learned policy controllers that modulate allowed children sets.
- Dependencies/assumptions: Reliable safety classification at subword-level; robust handling of context-dependent semantics; evaluation against adversarial prompts.
- Hardware Co-Design: Accelerators for small-K output layers
- Use case: Specialized kernels for low-dimension softmax and hierarchical decoding to further cut latency and energy.
- Tools/products/workflows: GPU/ASIC kernels tuned for TDLM-style heads; memory hierarchy optimizations for tree traversal.
- Dependencies/assumptions: Broad adoption of hierarchical heads; standardization of tree formats; vendor support.
- Joint Modeling and Multi-Task LMs
- Use case: Exploit reduced output space to jointly model multiple tasks/languages/modalities (text+code, multilingual) without exploding head sizes.
- Tools/products/workflows: Unified vocabulary trees with cross-domain branches; shared TDLM backbones with per-task schedules.
- Dependencies/assumptions: Effective joint ELBO design across tasks; avoidance of interference via tree structure; large-scale validation.
- Retrieval-Augmented Diffusion (RAG) with Subtree Selection
- Use case: Context-aware narrowing to relevant subtrees, reducing search space and improving faithfulness.
- Tools/products/workflows: RAG pipelines that pre-select subtree candidates from retrieved context; per-level guidance during denoising.
- Dependencies/assumptions: Reliable context-to-subtree mapping; latency budgets for retrieval; evaluation of factuality improvements.
- Expanded Vocabulary at Fixed Sequence Length
- Use case: Increase vocabulary granularity (morphology, domain terms) without growing sequence length, improving MT and legal drafting fidelity.
- Tools/products/workflows: Tree-aware tokenizers that support larger leaf sets; training recipes for expanded vocab under TDLM.
- Dependencies/assumptions: Careful trade-offs between vocab granularity and branch balance; retraining costs; downstream task evaluation.
- Edge Continual Learning and Personalization
- Use case: On-device updates to tree nodes and localized fine-tuning for personal assistants and note-taking apps.
- Tools/products/workflows: Lightweight on-device training loops; differential privacy mechanisms; periodic tree rebalancing.
- Dependencies/assumptions: Efficient step schedules for online learning; safe personalization under privacy constraints; model drift control.
- Robotics & IoT: On-board Language Reasoning
- Use case: Deploy low-memory language components for task planning, instruction following, and human-robot interaction on embedded compute.
- Tools/products/workflows: Real-time inference schedules optimized for latency; hierarchical constraints for safety-critical instructions.
- Dependencies/assumptions: Meeting hard real-time requirements; robust performance in noisy environments; integration with perception/planning stacks.
- Policy & Governance: Standards for Compute-Efficient NLP
- Use case: Establish procurement guidelines and reporting standards that incentivize hierarchical prediction and energy-efficient training.
- Tools/products/workflows: Benchmarks for energy-per-token and memory-per-parameter; certification programs for efficient models.
- Dependencies/assumptions: Multi-stakeholder agreement on metrics; transparent reporting; compatibility with existing governance frameworks.
- Industry Vertical Models (Law, Medicine, Finance)
- Use case: Build specialized trees with expert-curated structure to enhance domain accuracy and compliance.
- Tools/products/workflows: Domain experts collaborating with ML teams to codify hierarchical lexicons; productized TDLM models for verticals.
- Dependencies/assumptions: Sustained expert input; iterative refinement of tree taxonomy; rigorous task-specific evaluation.
Cross-Cutting Assumptions and Dependencies
- Quality of the vocabulary tree is pivotal: branching factor K, height H, and node-size ratio affect performance and training dynamics; uniform leaf depth may require padding.
- Diffusion LMs involve multi-step inference; balancing steps across levels impacts latency and quality (empirically, a balanced allocation often works best).
- Task fit and ecosystem readiness: many pipelines are tuned for autoregressive LMs; diffusion-based approaches may require integration and user acceptance.
- Safety, RLHF, and instruction-following capabilities for TDLMs need further maturity for broad consumer deployment.
- Open-source availability and standardized APIs will accelerate practical adoption across sectors.
Glossary
- Absorbing token: A special state that, once entered, the process remains in; used to represent complete corruption in diffusion. Example: "absorbing token [MASK]"
- Activation memory: GPU memory used to store intermediate activations during forward/backward passes. Example: "peak activation memory"
- Adaptive softmax: A tree-based approximation of the softmax for efficient large-vocabulary prediction. Example: "adaptive softmax"
- Ancestor function: A mapping that takes a node to its ancestor at a specified height in the tree. Example: "ancestor function"
- Attention blocks: Stacked self-attention layers in transformer-based architectures. Example: "deepen the attention blocks"
- Bayesian parameterization: Expressing reverse-time transition probabilities via Bayes’ rule using forward dynamics and predicted marginals. Example: "Bayesian parameterization"
- BF16: A 16-bit floating-point format (bfloat16) that reduces memory bandwidth and storage relative to FP32. Example: "Under BF16 with B=512"
- Branching factor: The number of children per internal node in a tree, controlling its fan-out. Example: "branching factor"
- Categorical distribution (Cat): A probability distribution over a finite set of discrete outcomes; used to parameterize discrete states. Example: "Cat(z_t|"
- Classification head: The final projection layer mapping hidden representations to class logits. Example: "classification head"
- Continuous-time ELBO: The evidence lower bound derived for continuous-time diffusion processes. Example: "continuous-time ELBO"
- Continuous-time Markov chain (CTMC): A Markov process evolving in continuous time with transitions governed by a rate (generator) matrix. Example: "continuous-time Markov chain (CTMC)"
- CT-ELBO: Abbreviation for continuous-time ELBO, the training objective in CTMC-based diffusion. Example: "CT-ELBO"
- CTMC interpretation: Viewing a discrete diffusion model as a CTMC under a continuous parameterization. Example: "admits a CTMC interpretation"
- Cumulative transition matrix: The matrix of transition probabilities from time s to t obtained by integrating the rate dynamics. Example: "cumulative transition matrix"
- Denoising: Iteratively reversing corruption to recover clean data from noise in diffusion models. Example: "iterative denoising steps"
- DiT-style architectures: Diffusion Transformer model designs that use transformer backbones for diffusion. Example: "DiT-style architectures"
- Discrete diffusion LLMs (DLMs): LLMs that apply diffusion in a discrete token space rather than continuous embeddings. Example: "discrete diffusion LLMs (DLMs)"
- ELBO (Evidence Lower Bound): A variational lower bound on log-likelihood used as a training objective. Example: "training ELBO"
- Flops/s: Floating-point operations per second, a metric for computational throughput. Example: "average Flops/s"
- Forward rate matrix: The time-dependent generator specifying instantaneous transition rates in a CTMC. Example: "forward rate matrix"
- Generator matrix: The matrix of transition rates defining the infinitesimal dynamics of a CTMC. Example: "generator (i.e., forward transition rate) matrix Q_t"
- GIDD (Generalized interpolating diffusion): A CTMC-based discrete diffusion framework that mixes data with a time-dependent distribution. Example: "Generalized interpolating diffusion (GIDD)"
- Hierarchical softmax: A tree-structured decomposition of softmax for efficient probability computation over large vocabularies. Example: "hierarchical softmax"
- In-level process: The portion of the diffusion confined between two adjacent tree levels over a specific time interval. Example: "in-level process"
- Kolmogorov forward/backward equations: Differential equations relating transition probabilities and the generator in CTMCs. Example: "Kolmogorov forward/backward equations"
- Kronecker delta function: A function δ that is 1 if its arguments are equal and 0 otherwise, used in discrete formulations. Example: "Kronecker delta function"
- Logits: Unnormalized scores output by a model before applying softmax. Example: "output logits"
- Markov property: The memoryless property where future states depend only on the present state. Example: "by the Markov property"
- MDLM (Masked diffusion LLM): A discrete diffusion model that interpolates between a token and an absorbing mask. Example: "Masked diffusion LLM (MDLM)"
- Mixing distribution: A time-dependent distribution with which data is interpolated during forward diffusion. Example: "time-dependent mixing distribution"
- One-hot encoding: A vector representation with a single 1 indicating the active category and 0s elsewhere. Example: "one-hot encoding vector"
- Offspring function: A mapping that returns the set of descendants (children at a given level) of a node in the tree. Example: "offspring function"
- Perplexity: An evaluation metric for LLMs measuring how well a probability model predicts a sample. Example: "generative perplexity"
- Power set: The set of all subsets of a given set; used to denote all possible descendant sets. Example: "power set"
- Reverse kernel: The conditional probability used to step backward in time during denoising, derived via Bayes’ rule. Example: "reverse kernel"
- Reverse process: The learned backward dynamics that reconstruct data from noise in diffusion models. Example: "reverse process"
- Time-inhomogeneous CTMC: A CTMC whose generator varies with time, leading to non-stationary dynamics. Example: "time-inhomogeneous continuous-time Markov chain (CTMC)"
- Vocabulary tree: A hierarchical organization of tokens enabling factorized, coarse-to-fine prediction. Example: "vocabulary tree"
Collections
Sign up for free to add this paper to one or more collections.