Universal Transformers Need Memory: Depth-State Trade-offs in Adaptive Recursive Reasoning
Abstract: We study learned memory tokens as computational scratchpad for a single-block Universal Transformer (UT) with Adaptive Computation Time (ACT) on Sudoku-Extreme, a combinatorial reasoning benchmark. We find that memory tokens are empirically necessary: across all configurations tested -- 3 seeds, multiple token counts, two initialization schemes, ACT and fixed-depth processing -- no configuration without memory tokens achieves non-trivial performance. The optimal count exhibits a sharp lower threshold (T=0 always fails, T=4 is borderline, T=8 reliably succeeds for 81-cell puzzles) followed by a stable plateau (T=8-32, 57.4% +/- 0.7% exact-match) and collapse from attention dilution at T=64. During experimentation, we identify a router initialization trap that causes >70% of training runs to fail: both default zero-bias initialization (p ~ 0.5) and Graves' recommended positive bias (p ~ 0.73) cause tokens to halt after ~2 steps at initialization, settling into a shallow equilibrium (halt ~ 5-7) that the model cannot escape. Inverting the bias to -3 ("deep start," p ~ 0.05) eliminates this failure mode. We confirm through ablation that the trap is inherent to ACT initialization, not an artifact of our architecture choices. With reliable training established, we show that (1) ACT provides more consistent results than fixed-depth processing (56.9% +/- 0.7% vs 53.4% +/- 9.3% across 3 seeds); (2) ACT with lambda warmup achieves matching accuracy (57.0% +/- 1.1%) using 34% fewer ponder steps; and (3) attention heads specialize into memory readers, constraint propagators, and integrators across recursive depth. Code is available at https://github.com/che-shr-cat/utm-jax.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores how a certain kind of AI model, called a Universal Transformer, can learn to solve very hard Sudoku puzzles. The key idea is that the model needs “memory tokens” — think of them like sticky notes the model can write on while it thinks — to keep track of important information as it reasons step by step.
The big idea in plain words
Imagine solving a Sudoku without writing anything down. You’d probably get stuck. Now imagine you’re allowed a few sticky notes to keep track of possibilities and deductions. This paper shows that a Universal Transformer (a model that reuses the same “thinking step” over and over) really needs those sticky notes (memory tokens) to solve tough puzzles. It also shows how to set up the model so it thinks for long enough before deciding it’s done.
What questions did the researchers ask?
They focused on four simple questions:
- Do memory tokens (the model’s “sticky notes”) actually help this kind of model reason through hard problems like Sudoku?
- How many memory tokens are enough, and can too many hurt?
- How should the model be started so it doesn’t stop thinking too soon? (They found a “trap” that makes the model quit early.)
- Is it better to let the model decide how many thinking steps it needs (Adaptive Computation Time, or ACT) rather than forcing a fixed number of steps? And can we make this efficient?
How did they test their ideas?
They trained a compact Universal Transformer on a big set of extremely difficult 9×9 Sudoku puzzles (very few starting numbers). Here’s how the main pieces work in everyday language:
- Universal Transformer: Instead of stacking many layers, this model applies the same “thinking block” again and again, like repeating a step of thought multiple times.
- Memory tokens: Extra learned slots added to the input that the model can read from and write to while it thinks — like sticky notes it keeps between steps.
- ACT (Adaptive Computation Time): A built-in “stopwatch” that lets each token decide when to stop thinking. At each step, a tiny “router” guesses, “Should we halt now?” If yes, the model blends the steps it took into a final answer. If not, it keeps going.
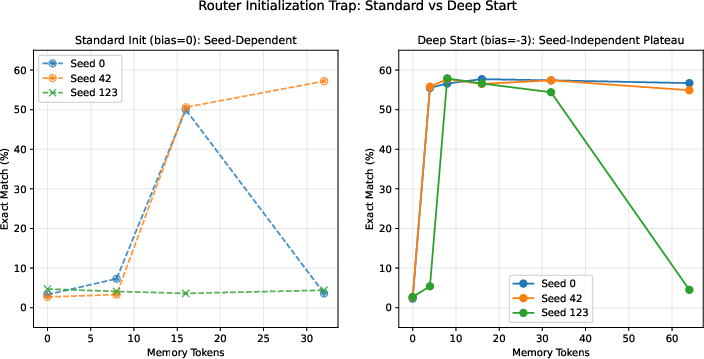
- The “router initialization trap”: If the router starts with the wrong settings, it makes the model stop after only a couple of steps — too shallow to solve tough puzzles. The authors fix this by starting with a strong “keep thinking” bias (called a “deep start”), then letting the model learn to stop earlier when it’s ready.
They compared:
- With vs. without memory tokens
- Different numbers of memory tokens
- ACT (model chooses when to stop) vs. fixed depth (forced number of steps)
- Different router starting settings
- Training for both accuracy and efficiency
What did they find?
Here are the main results, in clear terms:
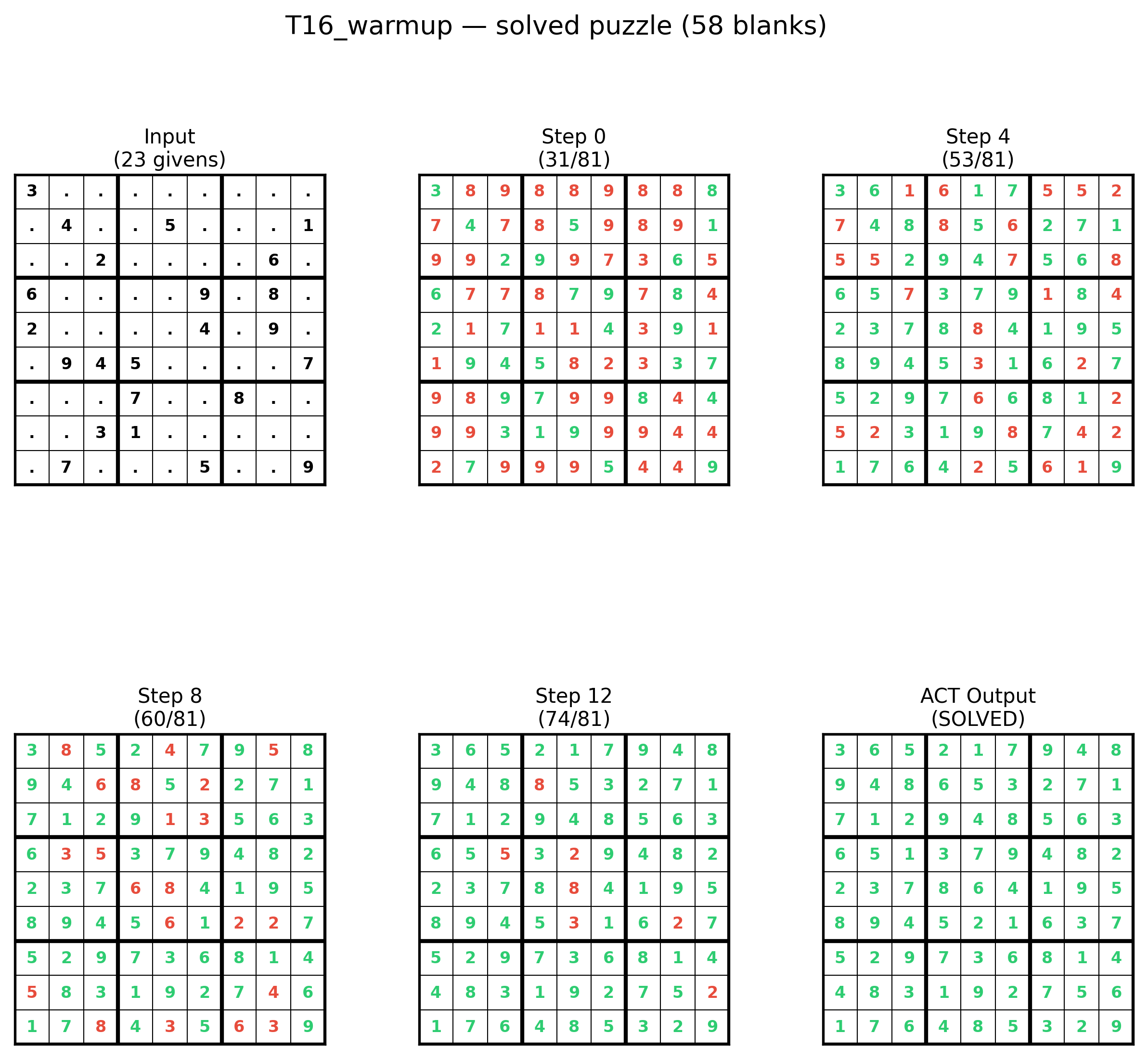
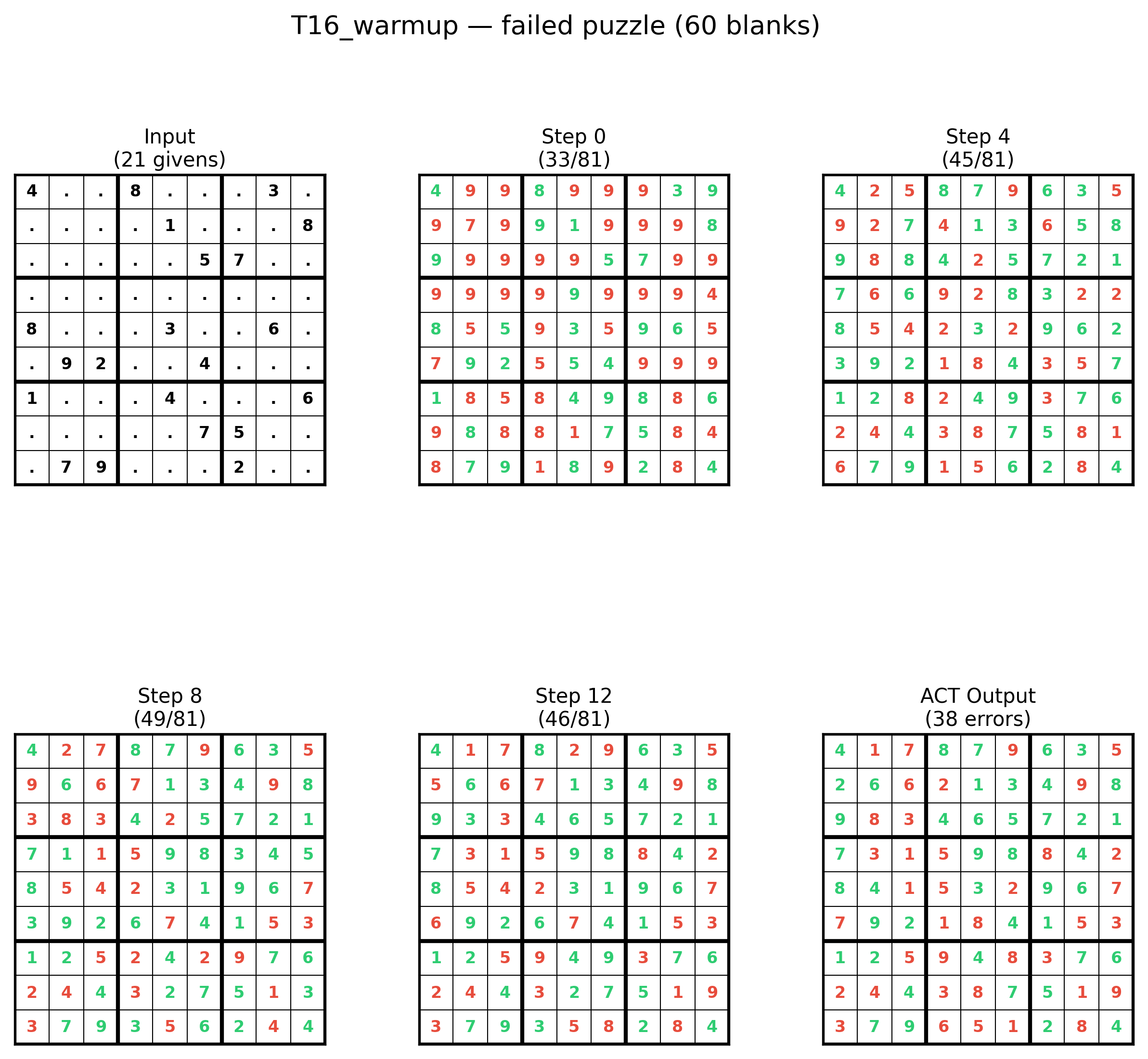
- Memory tokens are necessary for this model on very hard Sudoku
- Without memory tokens, the model never really learns to solve the puzzles.
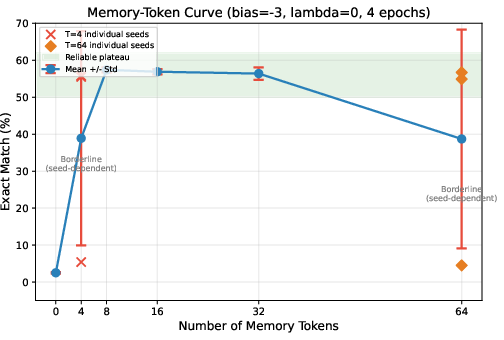
- With at least 8 memory tokens, the model succeeds reliably and reaches solid accuracy (around 57% of puzzles exactly right).
- Too many memory tokens (like 64) can hurt because the model’s attention gets “spread too thin” — like having so many sticky notes that you can’t focus on any of them.
- There’s a sharp threshold for how many memory tokens you need
- 0 tokens: fails.
- 4 tokens: sometimes works, sometimes fails (unstable).
- 8–32 tokens: consistently good (a stable “sweet spot”).
- The “router initialization trap” is real — and easy to fix
- If the halting unit (router) starts out neutral or slightly positive, it makes the model stop after only 1–2 steps at the beginning of training and then get stuck stopping early.
- Flipping the starting bias to encourage deep thinking first (a “deep start”) avoids this trap. The model then learns when to stop on its own.
- Letting the model choose its own number of thinking steps (ACT) is more reliable than forcing a fixed number
- ACT gave more consistent results across different random starts.
- With a simple “warmup” trick (start training without penalizing long thinking, then gradually add a penalty), the model used about 34% fewer thinking steps while keeping the same accuracy.
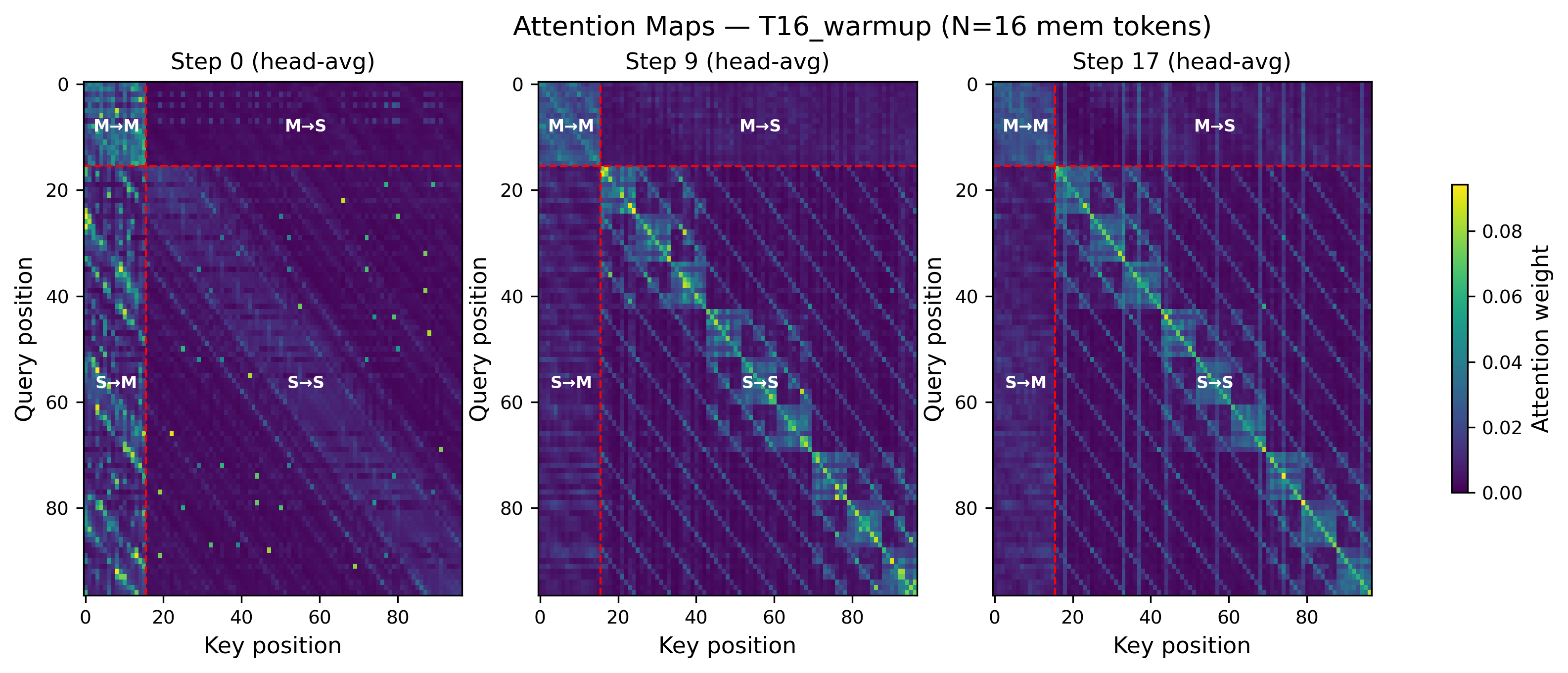
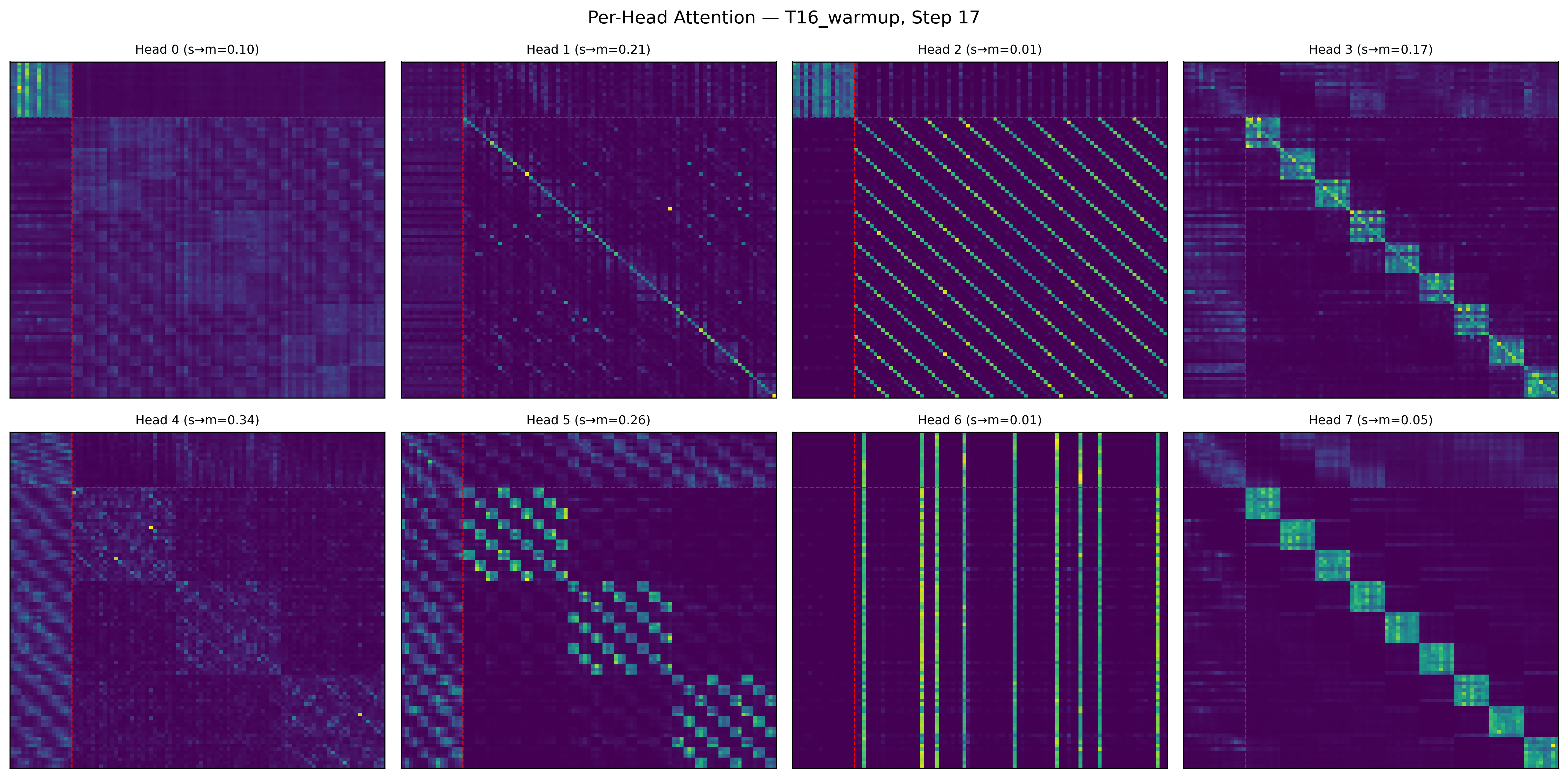
- The model’s attention heads specialize as it reasons
- Some heads mostly read memory (gathering information), some write to it (broadcasting findings), and some focus on Sudoku rules (rows, columns, and boxes).
- This is like a team where some members keep notes, others share conclusions, and others enforce the rules — all across multiple steps of thought.
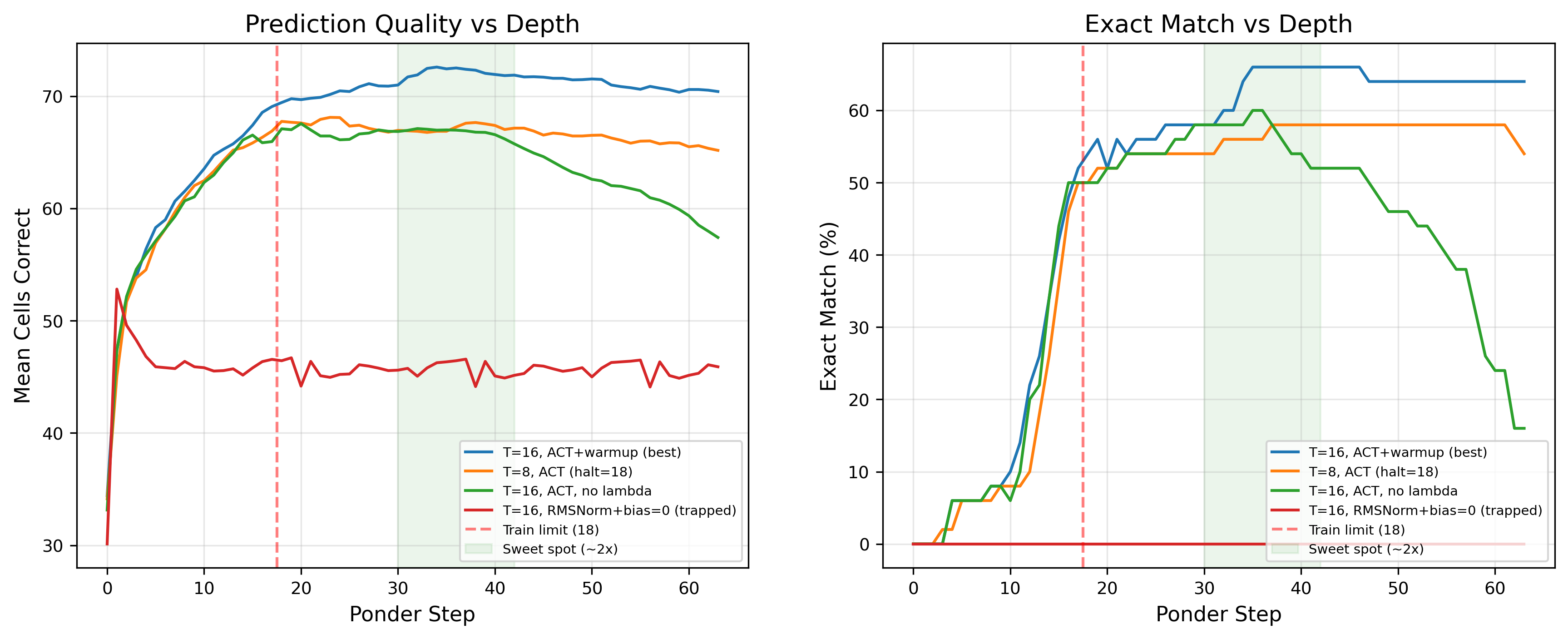
- Extra thinking at test time can help
- Even if the model was trained to think up to 18 steps, letting it think longer (e.g., ~36 steps) during testing improved accuracy more, then gradually leveled off.
- Limits: small-data generalization
- When trained on very few examples, this model memorized those puzzles but didn’t generalize well to new ones. Other models with different strategies did better in that small-data setting.
Why does this matter?
- For certain kinds of reasoning models (like a single-block Universal Transformer), “memory tokens” aren’t just a bonus — they’re essential. Giving the model a scratchpad dramatically improves its ability to keep track of partial deductions and solve complex problems.
- How you start the model’s “when to stop thinking” decision matters a lot. A simple change (deep-starting the halting unit) can make training far more reliable.
- ACT can make models both steadier and more efficient, and with a warmup you can save compute without losing accuracy.
- These insights could help researchers and engineers build smaller, smarter reasoning systems that think just enough, use memory wisely, and avoid subtle training traps.
- While the results here are for Sudoku, the broader lesson — that structured memory and careful halting behavior can enable deeper reasoning — could apply to other logic tasks, puzzles, or step-by-step problem solving.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The following list summarizes concrete gaps and open questions left by the paper that future work can address:
- Generality of memory-token necessity: Verify whether learned memory tokens are required beyond Sudoku-Extreme and the single-block UT+ACT setup by testing across tasks (ARC-AGI, mazes, formal logic) and alternative looped architectures (e.g., multi-block UTs, URM variants).
- Scaling law for memory size: Characterize how the minimum effective number of memory tokens T scales with sequence length L and required depth K (e.g., vary board sizes 4×4, 9×9, 16×16; longer sequences in other domains) to test or refine the “~1 per 10 cells” heuristic.
- Model-size interactions: Determine whether the deep-start fix rescues wider/deeper UTs (e.g., hidden=768, ~7M params) and whether memory-token thresholds shift with capacity; produce parameter-scaling curves for EM vs parameters, T, and K.
- Attention dilution at high T: Diagnose and mitigate the collapse at T=64 (e.g., sparse attention, memory gating, learned memory compression, token clustering, top-k memory reads) and quantify when increased T helps vs harms.
- Theory of the ACT initialization trap: Provide a formal analysis of gradient dynamics and fixed points under ACT’s cumulative halting to explain the shallow-halt equilibrium; derive principled initialization and router designs that guarantee escape.
- Halting mechanisms beyond vanilla ACT: Compare PonderNet-style geometric halting, multi-layer routers, temperature-scaled logits, or RL-based halting to assess stability, compute, and accuracy relative to deep-started ACT.
- Normalization effects on ACT: Systematically ablate LayerNorm, RMSNorm, ScaleNorm, DerfNorm (and parameterizations) to quantify their impact on halting dynamics and trap frequency across seeds and tasks.
- Optimal halting-bias strategy: Sweep halting-bias values, schedules (e.g., cosine, linear), per-token/per-layer biases, and meta-learned initial biases to find robust, architecture-agnostic defaults instead of a single b_h = −3 setting.
- Output aggregation across steps: Evaluate alternatives to ACT’s weighted blend (e.g., learned attention over steps, last non-halted only, step-wise gating/skip connections, learned step pooling) to reduce seed variance without ACT.
- Sample efficiency under ACT: Quantify whether ACT improves data efficiency or primarily stabilizes training; control for matched compute and steps to separate stability from efficiency gains.
- Early-run diagnostics and mitigation: Develop predictive signals (e.g., router gradient norms, halting histograms, entropy of step weights) to detect trap runs within few thousand steps and auto-apply corrective actions (bias inversion, router LR boosts, restarts).
- Small-data generalization failure: Isolate causal factors by introducing iterative answer refinement within UT (e.g., multi-pass decoding, self-correction heads), curriculum learning, stronger regularization, or TRM-style training within the UT framework.
- Cross-task universality of head roles: Test whether the observed head specializations (memory readers/writers, constraint propagators) reproducibly emerge across seeds, sizes, and tasks; quantify necessity via causal ablations (mask/prune/rewire specific heads).
- Safe over-pondering limits: Map performance vs inference steps beyond training depth under different step-embedding schemes (non-wrapping, relative, learned monotonic embeddings) to avoid aliasing and to determine safe 2×–5× over-ponder regimes.
- Adaptive memory allocation: Explore dynamic activation of memory (e.g., sparsely-used or per-instance memory tokens, k-select memory access, learned memory count) to trade off compute and accuracy.
- Memory index semantics: Ablate fixed vs learned memory positions (with/without RoPE), randomized indexing, and shared vs per-step positional encodings to test whether “numbered registers” are essential for scratchpad utility.
- Optimizer dependence: Benchmark Muon, Adafactor, Shampoo, Lion, and momentum schedules against AdamW for convergence speed, trap incidence, and final EM under deep-start and lambda warmup.
- Training duration and curricula: Assess whether more epochs, staged difficulty, or synthetic constraint curricula improve EM and generalization (vs the current 4-epoch regime).
- Halting penalty design: Compare penalty forms (linear vs quadratic, per-token vs per-sequence, adaptive λ), staged ceilings/floors on steps, and tokenwise compute budgets to sharpen the compute–accuracy frontier.
- Instance-level compute control: Design inference-time early-exit policies (e.g., thresholds on residual halting mass, stability of predictions over steps) to automatically allocate extra steps only when they help.
- Parameter-matched baselines: Run controlled comparisons against TRM/HRM/URM at matched parameter counts and training budgets to disentangle architectural choices from capacity and data effects.
- Neuro-symbolic decoding: Test constraint-aware post-processing (e.g., Sudoku solvers, SAT-based repair, differentiable constraint layers) to see if memory requirements and EM improve without changing UT internals.
- Seed sensitivity at boundaries: Develop regularizers (e.g., memory dropout, stochastic depth over steps, router noise) to reduce seed sensitivity in borderline regimes (T=4, T=64) and verify robustness across >3 seeds.
- Head-count and width of attention: Study how the number of heads and head dimension affect memory specialization, dilution, and final EM; identify minimal head configurations that retain specialized roles.
- Statistical robustness: Report full-test-set EM, more seeds, and confidence intervals; release per-run halting distributions and attention metrics for reproducibility and meta-analysis.
- Generalization to larger combinatorial spaces: Extend experiments to 16×16 Sudoku and Latin squares to test whether T scales sublinearly/linearly with L and whether the memory–depth trade-off persists.
- Alternative routers and gating: Evaluate deeper routers (MLPs), shared vs token-specific routers, and temperature annealing to control halting sharpness and reduce trap likelihood.
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s findings on Universal Transformers with Memory (UTM) and Adaptive Computation Time (ACT). Items are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further R&D, scaling, or validation). Each item highlights relevant sectors, potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Adopt “deep-start” ACT initialization to avoid halting traps (Software/AI infrastructure)
- What: Initialize the ACT router with a strongly negative bias (e.g., −3) so tokens start deep and learn to halt earlier.
- Tools/workflows: Update UT/ACT training recipes, framework defaults, or library utilities; add a one-line change to halting head initialization in PyTorch/JAX/TF repos; include as a config flag in open-source UT baselines (e.g., the provided JAX repo).
- Assumptions/dependencies: Applicable when using ACT-style halting with per-token probabilities; most relevant for weight-shared/looped architectures; may need retuning for other tasks.
- Add learned memory tokens as a computational scratchpad for single-block UTs (Software/AI research; Operations Research prototypes)
- What: Include ≥8 memory tokens for 81-token inputs (rule-of-thumb ≈1 memory per 10 inputs) to enable recursive reasoning.
- Tools/workflows: Architecture templates with memory token banks and type embeddings; hyperparameter sweeps over memory-token count (8–32) to hit the plateau; integration into UT-based solvers for constraint satisfaction (e.g., Sudoku-like prototyping).
- Assumptions/dependencies: Necessity is architecture-specific to single-block UTs; other architectures (e.g., TRM/HRM) may not need memory tokens.
- Use ACT with weighted blend for more reliable training than fixed-depth (Software/AI infrastructure)
- What: Prefer ACT’s weighted output over fixed-depth last-step output to reduce seed variance and stabilize training outcomes.
- Tools/workflows: Training configs that enable ACT by default; dashboards to monitor per-step weights (w_k) and halting distributions.
- Assumptions/dependencies: ACT implementation quality and router stability are critical; ensure deep-start initialization is applied.
- Apply lambda warmup to cut compute without hurting accuracy (Software/ML Ops; Cloud cost control)
- What: Start training with λ=0, then gradually apply ponder cost (λ>0) to reduce average steps by ~34% at matched quality.
- Tools/workflows: Scheduler for λ warmup; training-time compute budgeters; automated early-stopping on halting equilibrium.
- Assumptions/dependencies: Needs a warmup phase long enough to establish deep processing; overly aggressive λ without warmup collapses halting.
- Exploit “compute knob” at inference by running deeper than training depth when accuracy matters (Software/Analytics; Offline batch processing)
- What: Increase ponder steps at inference (e.g., 2× training depth) to gain accuracy on difficult instances without retraining.
- Tools/workflows: Runtime parameter that scales max ponder steps; policy-based routing where high-uncertainty cases get extra steps.
- Assumptions/dependencies: Step embeddings must generalize; latency/compute budget must tolerate deeper loops; gains observed on Sudoku-Extreme may vary by task.
- Integrate ACT diagnostics to detect failure modes early (Software/DevOps; Research tooling)
- What: Log per-step halting probabilities, router gradient norms, and attention-mass quadrants to identify shallow-halt traps or lack of head specialization.
- Tools/workflows: Training dashboards and alerts when router gradients stay low or halting equilibria are too shallow; automated recovery by switching to deep-start bias or adjusting λ warmup.
- Assumptions/dependencies: Requires instrumentation hooks in the training loop; adds negligible overhead.
- Design-time budgeting using the memory–depth trade-off (Software/AI systems)
- What: Choose memory-token count versus max ponder steps to hit latency/quality targets (e.g., more memory, fewer steps; fewer memory tokens, deeper pondering).
- Tools/workflows: Profilers that co-optimize memory tokens and ponder limits to maintain throughput SLAs.
- Assumptions/dependencies: Trade-off curve is task- and architecture-specific; validate on target workloads.
- Curriculum and teaching aids for iterative reasoning (Education)
- What: Use the provided attention visualizations to teach constraint propagation, memory “registers,” and iterative refinement.
- Tools/workflows: Classroom labs using the open-source repo; step-by-step puzzle-solving demos.
- Assumptions/dependencies: Pedagogical use is robust even if absolute accuracy is modest.
- Default-setting updates in UT/ACT repos and internal templates (Software engineering policy)
- What: Promote deep-start halting bias, ACT-by-default, and λ warmup as first-class defaults in internal model templates.
- Tools/workflows: PRs to open-source repos; internal coding standards; model cards documenting halting initialization.
- Assumptions/dependencies: Organizational willingness to change defaults; regression tests on existing projects.
Long-Term Applications
- General-purpose reasoning modules with memory tokens (Software; Foundation models)
- What: Scale UTM with memory to broader reasoning tasks (e.g., theorem proving, formal logic, code synthesis) once generalized performance improves.
- Tools/products: Reasoning-centric model families that expose a “scratchpad register” interface; APIs to allocate memory slots per task.
- Assumptions/dependencies: Requires validation on multi-task suites and algorithmic generalization beyond Sudoku; potential integration with TRM-style iterative refinement.
- Dynamic-depth inference policies in production systems (Cloud/Edge AI; Finance; Healthcare; Robotics)
- What: Allocate more compute (ponder steps) to uncertain or safety-critical cases while keeping others shallow to save cost/latency.
- Tools/workflows: Confidence-based routing; SLAs aware of per-request compute; guardrails that enforce minimum halting depths on critical categories.
- Assumptions/dependencies: Calibrated uncertainty estimates; fairness and latency policies; hardware/runtime support for variable-length loops.
- Operations research and planning with looped reasoning (Logistics; Manufacturing; Energy)
- What: Apply looped UTs with memory tokens to approximate constraint satisfaction and scheduling (e.g., timetabling, vehicle routing) as learned heuristics.
- Tools/products: Hybrid solvers that couple classical optimization with learned recursive modules; warm-starts or feasibility checks via deeper pondering.
- Assumptions/dependencies: Must demonstrate competitive solution quality and reliability; domain-specific tuning and larger models likely required.
- ACT-aware cluster schedulers and billing (Cloud/AI infrastructure policy)
- What: Price and schedule jobs by effective ponder steps; reward λ warmup and dynamic-depth policies that cut energy usage.
- Tools/workflows: Telemetry capturing halting distributions; billing models tied to actual token-steps; autoscaling tuned to dynamic compute.
- Assumptions/dependencies: Cloud support for fine-grained metering; organizational buy-in to new billing semantics.
- Memory-scaling heuristics and “register planning” for model design (AI systems)
- What: Develop rules-of-thumb (e.g., memory ≈ 1 per 10 inputs) and autotuners that jointly select memory slots and depth for a given task size.
- Tools/workflows: AutoML that searches memory/depth budgets under latency constraints; visualization tools that verify head specialization emerges.
- Assumptions/dependencies: Heuristics likely task-dependent; needs broader benchmarking.
- Explainability via attention specialization analysis (Regulated sectors: Healthcare, Finance)
- What: Use head-role decomposition (memory readers/writers, constraint propagators) to audit decision pathways in recursive models.
- Tools/workflows: Compliance dashboards showing per-head quadrant masses across depth; alerts when expected specialization fails to emerge.
- Assumptions/dependencies: Causality of attention patterns is debated; requires careful interpretation and sector-specific validation.
- Safer defaults and standards for dynamic-compute models (Policy/Standards bodies)
- What: Recommend deep-start initialization and halting diagnostics as best practices to avoid underthinking in ACT-enabled systems.
- Tools/workflows: Standards documents; conformance tests checking halting distributions and recovery from shallow equilibria.
- Assumptions/dependencies: Consensus across research and industry; extensions for non-UT architectures.
- Training efficiency via new optimizers (Software/AI research)
- What: Combine Muon or other second-order-ish optimizers with deep-start + λ warmup for faster convergence in weight-shared models.
- Tools/workflows: Optimizer plug-ins; evaluation harnesses measuring compute per accuracy under ACT.
- Assumptions/dependencies: Unproven synergy; may require hyperparameter sweeps and stability checks.
- Cross-architecture synthesis with TRM/HRM (Software/AI research)
- What: Hybridize memory-token scratchpads with autoregressive answer-improvement loops to improve small-data generalization.
- Tools/workflows: Training curricula that alternate UT pondering and iterative refinement; memory slots seeded by previous iteration summaries.
- Assumptions/dependencies: Non-trivial engineering; careful ablations needed to isolate gains.
- Hardware-aware kernels for looped blocks with persistent memory (Semiconductors; Systems)
- What: Optimize kernels for repeated application of a single shared block with persistent memory tokens to improve cache locality and throughput.
- Tools/products: Compiler passes that fuse ponder steps; buffer pinning for memory tokens; accelerator runtime support for dynamic halting.
- Assumptions/dependencies: Requires hardware/runtime co-design; benefits increase with longer ponder loops.
- Curriculum learning and tutoring systems that demonstrate iterative reasoning (Education tech)
- What: Interactive tutors that visualize how deeper “pondering” refines answers, teaching meta-cognition strategies.
- Tools/products: “Solve with more steps” toggles; step-by-step constraint propagation demos for math/logic curricula.
- Assumptions/dependencies: Must ensure pedagogical validity; content adaptation beyond Sudoku.
- Governance of compute–accuracy trade-offs (Policy; Sustainability)
- What: Encourage reporting of halting distributions, compute per token, and dynamic-depth policies in model cards to support energy transparency.
- Tools/workflows: Reporting templates; audits tying λ warmup and deep-start usage to energy and performance metrics.
- Assumptions/dependencies: Policy adoption by stakeholders; standardized metrics across vendors.
- Domain transfer to structured biomedical or legal reasoning (Healthcare; Legal tech)
- What: Explore recursive UTs with memory for structured constraint problems (e.g., trial scheduling, protocol eligibility checks).
- Tools/products: Prototypes that use deeper inference on ambiguous cases; human-in-the-loop workflows leveraging interpretability tools.
- Assumptions/dependencies: Requires rigorous validation and high accuracy; current Sudoku-level performance indicates more R&D is needed.
Glossary
- Adaptive Computation Time (ACT): A mechanism that learns how many iterative processing steps each token should receive, allowing variable per-token depth. "Universal Transformers apply a single transformer block iteratively, with Adaptive Computation Time determining per-token processing depth."
- AdamW: An optimizer that decouples weight decay from gradient-based updates for better generalization in deep learning. "AdamW (lr=, cosine decay)"
- attention artifacts: Undesirable attention patterns that can arise in transformer models without specialized tokens to stabilize computation. "\citet{darcet2024vision} show Vision Transformers need register tokens to prevent attention artifacts; we demonstrate an analogous necessity for recursive reasoning."
- attention dilution: Degradation of attention effectiveness when too many tokens compete for attention, reducing signal quality. "collapse from attention dilution at ."
- attention-mass logging: Instrumentation that tracks how attention weights are distributed, used to analyze model behavior across steps. "attention-mass logging that reveals head specialization and computation dynamics across recursive depth."
- autoregressive answer improvement: A training/inference approach where predictions are refined iteratively in an autoregressive loop. "solve Sudoku without memory tokens via autoregressive answer improvement"
- bidirectional attention: An attention scheme where tokens can attend to both previous and subsequent tokens in the sequence. "with bidirectional attention."
- ConvSwiGLU: A variant of the SwiGLU feed-forward layer augmented with convolution, used in some transformer architectures. "URM applies UT+ACT to Sudoku and ARC without memory tokens, reaching 77.6\% on Sudoku using ConvSwiGLU and truncated backpropagation"
- constraint propagators: Attention heads or mechanisms that enforce and spread problem constraints across tokens. "attention heads specialize into memory readers, constraint propagators, and integrators across recursive depth."
- cosine decay: A learning rate schedule that decreases the learning rate following a cosine curve. "AdamW (lr=, cosine decay)"
- cumulative halting probability: In ACT, the running total of halting probabilities used to decide when to stop processing a token. "each token maintains cumulative halting probability."
- Deep-start initialization: An ACT router bias initialization with a strongly negative bias to encourage deep processing initially. "Deep start: bias , giving ."
- Derf: A normalization-free transformation using an error-function-based nonlinearity with learned parameters to stabilize activations. "DerfNorm (our term for the normalization-free design using Derf), where standard normalization layers are replaced by with learned per-feature "
- DerfNorm: A normalization-free design replacing standard norms with a parametric erf-based transform (Derf) to stabilize training. "DerfNorm (our term for the normalization-free design using Derf), where standard normalization layers are replaced by with learned per-feature "
- exact-match (EM): An accuracy metric that requires all outputs (e.g., all Sudoku cells) to be predicted exactly correctly. "Eval exact-match (\%)"
- Exponential Moving Average (EMA): A technique that tracks a smoothed running average of model parameters to improve evaluation stability. "EMA (0.999)"
- fixed-depth processing: A setup where the model runs a predetermined number of steps for all tokens rather than using ACT to adapt per token. "Fixed-depth processing with memory tokens achieves EM"
- halting bias: The bias term in the ACT router that influences the initial halting probabilities and thus early training dynamics. "initializing the halting bias to a positive value (, giving )"
- halting probability: The per-step probability produced by the ACT router indicating whether a token should stop being processed. "The ACT router outputs halting probability per token at each step"
- head specialization: The emergence of distinct roles across different attention heads (e.g., memory readers or constraint propagators). "attention heads specialize into memory readers, constraint propagators, and integrators across recursive depth."
- HRM (Hierarchical Reasoning Model): A model class that structures reasoning in a hierarchy of latent computations. "HRM uses hierarchical latent reasoning."
- indexed RoPE positions (numbered registers): Assigning fixed rotary positional indices to learned memory tokens to give them stable, register-like identities. " learned memory vectors with indexed RoPE positions (numbered registers)."
- lambda warmup: A training policy that delays applying the ACT ponder penalty (λ) to allow the model to first learn deep computation. "Lambda warmup achieves matching accuracy () using 34\% fewer ponder steps."
- memory tokens: Learnable vectors prepended to the sequence that act as a global scratchpad across iterative steps. "We study learned memory tokens as computational scratchpad"
- Muon optimizer: An optimizer introduced for training deep networks, particularly promising for weight-shared architectures. "(2) Muon optimizer: Newton-Schulz-based optimizers \citep{jordan2024muon} have shown promise for weight-shared architectures"
- Newton–Schulz-based optimizers: Optimizers that use matrix inverse approximation techniques (Newton–Schulz iterations) to precondition updates. "Newton-Schulz-based optimizers \citep{jordan2024muon} have shown promise for weight-shared architectures"
- Ponder cost: The ACT cost term that penalizes longer computation, often combining the number of steps and a remainder term. "Ponder cost is minimized with coefficient ."
- ponder penalty: The regularization term applied to the ponder cost to discourage excessive computation depth. "Direct application of the ponder penalty collapses halting even with deep start."
- ponder steps: The iterative processing steps the model uses to refine representations under ACT. "using 34\% fewer ponder steps"
- pre-norm attention: An architecture where normalization (or its replacement) is applied before the attention sublayer. "pre-norm attention + SwiGLU FFN"
- QK-normalization: A technique that normalizes query and key vectors to stabilize attention computations. "multi-head attention with RoPE and QK-normalization"
- RMSNorm: A normalization method based on root-mean-square statistics used as an alternative to LayerNorm. "replacing it with RMSNorm"
- Rotary Positional Embeddings (RoPE): A method to encode positions by rotating query/key vectors, enabling better extrapolation of attention. "multi-head attention with RoPE and QK-normalization"
- router (ACT router): The module that outputs halting probabilities and governs per-token stopping decisions in ACT. "The ACT router outputs halting probability per token at each step"
- router initialization trap: A failure mode where default or positively biased ACT halting initialization induces shallow halting that training cannot escape. "we identify a router initialization trap that causes 70\% of training runs to fail"
- step embedding: A learned embedding that encodes the current iteration/ponder step to the model. "per-step learned positional embedding"
- step-weight distribution: The distribution of ACT blending weights across steps that determines how much each step contributes to the final output. "step-weight distribution"
- SwiGLU: A gated feed-forward activation variant that improves transformer expressivity and stability. "SwiGLU FFN with expansion"
- TRM: A compact recursive reasoning model that achieves strong results via iterative answer refinement. "TRM (7M params) achieves strong ARC-AGI results via recursive answer improvement."
- truncated backpropagation: Training that backpropagates gradients through a limited number of steps to save compute/memory. "using ConvSwiGLU and truncated backpropagation"
- type embedding: An embedding that encodes token types (e.g., memory vs. sequence) to help the model distinguish roles. "token + type embedding (memory vs sequence)"
- Universal Transformer (UT): A transformer that reuses a single block across multiple iterative steps, enabling depth via recurrence. "Universal Transformers apply a single transformer block iteratively"
- URM (Universal Reasoning Model): A UT+ACT-based system applied to reasoning tasks like Sudoku and ARC. "URM applies UT+ACT to Sudoku and ARC without memory tokens"
- weight-tied transformer: A transformer where the same block parameters are reused at each layer/step. "When ACT is disabled, the model outputs only the final representation (standard weight-tied transformer)."
- weighted blend: The ACT output aggregation that linearly combines step representations using the halting probabilities as weights. "The output is a weighted blend: "
Collections
Sign up for free to add this paper to one or more collections.