STEM: Scaling Transformers with Embedding Modules
Abstract: Fine-grained sparsity promises higher parametric capacity without proportional per-token compute, but often suffers from training instability, load balancing, and communication overhead. We introduce STEM (Scaling Transformers with Embedding Modules), a static, token-indexed approach that replaces the FFN up-projection with a layer-local embedding lookup while keeping the gate and down-projection dense. This removes runtime routing, enables CPU offload with asynchronous prefetch, and decouples capacity from both per-token FLOPs and cross-device communication. Empirically, STEM trains stably despite extreme sparsity. It improves downstream performance over dense baselines while reducing per-token FLOPs and parameter accesses (eliminating roughly one-third of FFN parameters). STEM learns embedding spaces with large angular spread which enhances its knowledge storage capacity. More interestingly, this enhanced knowledge capacity comes with better interpretability. The token-indexed nature of STEM embeddings allows simple ways to perform knowledge editing and knowledge injection in an interpretable manner without any intervention in the input text or additional computation. In addition, STEM strengthens long-context performance: as sequence length grows, more distinct parameters are activated, yielding practical test-time capacity scaling. Across 350M and 1B model scales, STEM delivers up to ~3--4% accuracy improvements overall, with notable gains on knowledge and reasoning-heavy benchmarks (ARC-Challenge, OpenBookQA, GSM8K, MMLU). Overall, STEM is an effective way of scaling parametric memory while providing better interpretability, better training stability and improved efficiency.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to make LLMs (like ChatGPT) smarter without making them much slower. The authors call it STEM, which stands for “Scaling Transformers with Embedding Modules.” STEM changes one part inside the model so it can store more knowledge, work more efficiently, stay stable during training, and be easier to edit and understand.
What questions are the researchers asking?
They focus on five simple questions:
- Can we give a model more “memory” (knowledge) without making it do a lot more work per word?
- Can we avoid the training problems that happen in other “sparse” models (like Mixture-of-Experts, or MoE)?
- Can we make the system faster and use less GPU memory and network communication?
- Can we make the model’s knowledge more interpretable and easy to edit (e.g., change a fact without changing the input text)?
- Can we make the model use more useful parameters when the input is very long, so it performs better on long documents?
How does STEM work? (In everyday language)
First, a quick crash course on terms (with analogies):
- Transformer: The general kind of model used in many chatbots. It reads text and predicts the next word.
- FFN (Feed-Forward Network): A sub-part inside each layer of a Transformer. Think of it like a mini processing unit that transforms information.
- Up-projection / Down-projection: Two large “matrix multiplications” in the FFN. You can imagine them as “expand then compress” steps.
- Embedding: A list (vector) of numbers that represents a specific word/token.
- Sparse: Not everything is used every time—only what’s needed.
- FLOPs: The number of basic calculations the computer does.
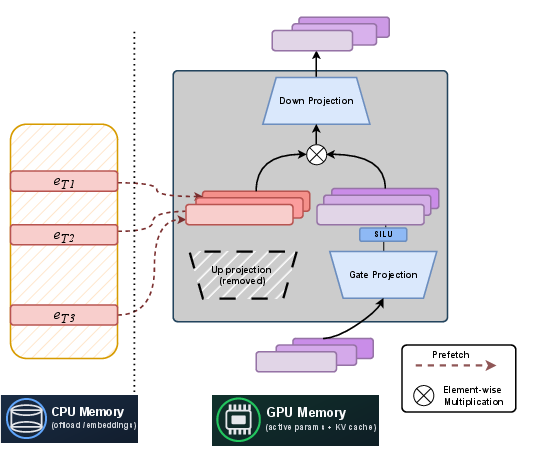
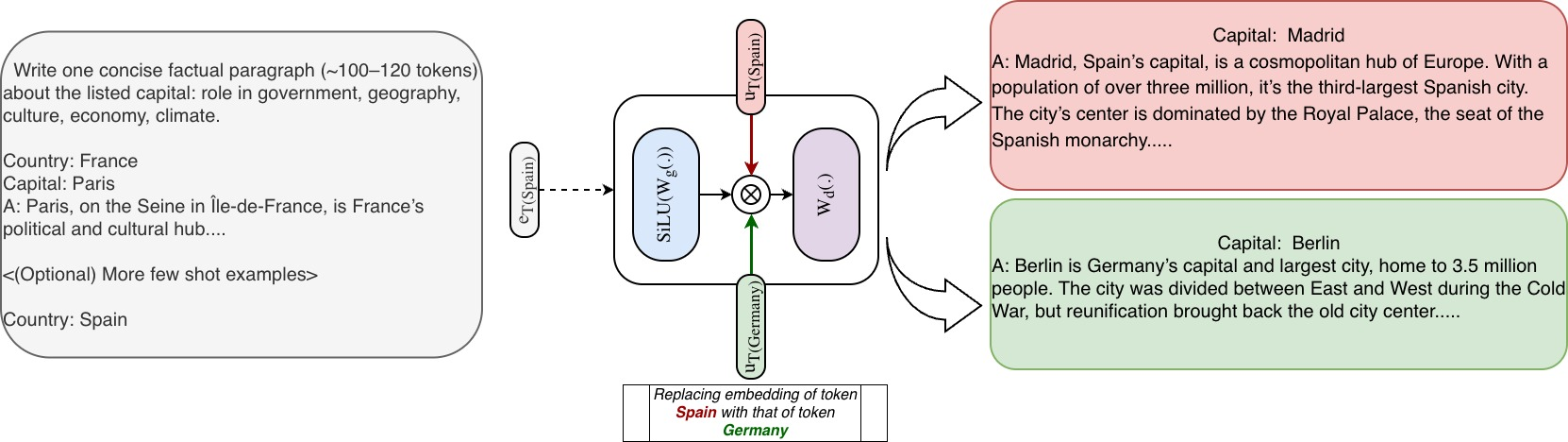
What’s the change? In a standard Transformer, the FFN has three main steps: a gate, an up-projection (expand), and a down-projection (compress). STEM replaces the up-projection with a simple “lookup” based on the current word (token). Instead of doing a big calculation to create an internal vector, the model just grabs a pre-learned vector for that specific token at that specific layer.
A helpful analogy:
- Imagine a toolbox with drawers labeled by word IDs (tokens). In a usual model, to get the right tool (vector), you run a complex machine each time. In STEM, you skip the machine and open the drawer labeled with the current word to pull out the right tool instantly. Then:
- A “gate” (which still depends on the sentence’s context) decides how much to use that tool.
- A shared “down-projection” shapes the result and sends it onward.
Why does this help?
- No routing delays: Unlike MoE (Mixture-of-Experts), there’s no need to pick experts on the fly, so the path is predictable and fast.
- Efficiency: Looking up a vector is cheaper than doing a big matrix multiplication every time. This cuts a large chunk of work and memory use in the FFN (roughly one-third of FFN parameters are removed).
- CPU offloading: These token-specific vectors can be stored in CPU memory and fetched just-in-time to the GPU. The authors also use tricks like deduplicating repeated tokens and caching frequent ones to reduce data movement.
- More capacity in long texts: As a document gets longer and uses more unique words, the model touches more unique token vectors. That means it effectively “activates” more knowledge without adding more per-word compute.
What did they test and how?
They tested STEM on medium-sized models (about 350 million and 1 billion parameters) and compared it to:
- A regular “dense” model (the standard setup).
- Hash-based MoE variants with similar total parameter counts.
They evaluated:
- General knowledge and reasoning benchmarks (like ARC-Challenge and OpenBookQA).
- Math and advanced knowledge benchmarks (like GSM8K and MMLU).
- Long-context tasks (like “Needle-in-a-Haystack,” where the model must find information hidden in long text).
They also looked at:
- Training stability (Does the loss spike?).
- Efficiency (Fewer calculations and less parameter loading).
- Interpretability (Can we edit knowledge by editing the STEM vectors?).
What did they find, and why is it important?
- Better accuracy with less compute:
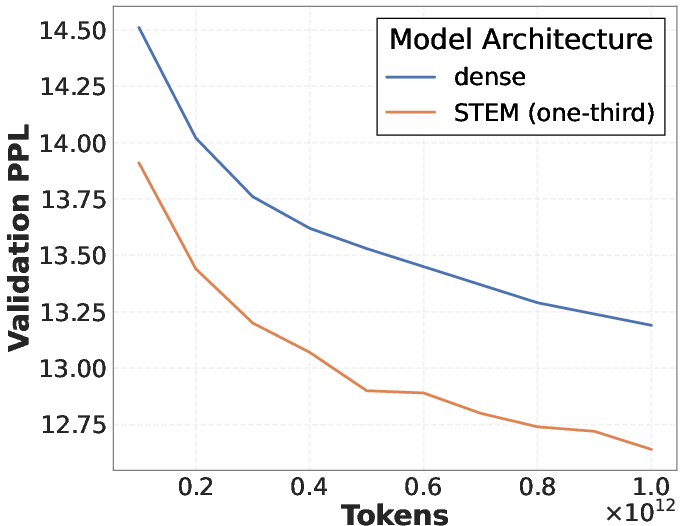
- STEM improved overall accuracy by around 3–4% compared to standard models at similar scales.
- It especially helped on knowledge-heavy and reasoning tasks (like ARC-Challenge, OpenBookQA, GSM8K, and MMLU).
- It reduced the number of calculations and parameter reads per token by removing about one-third of the FFN parameters.
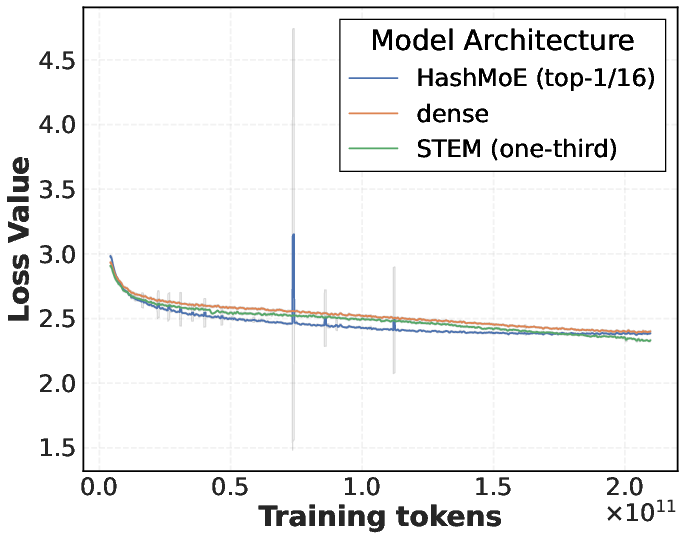
- Stable training:
- Unlike many MoE models, STEM did not show sudden training instability (no loss spikes). This is a big deal because stability is a common problem in sparse models.
- More interpretable and editable knowledge:
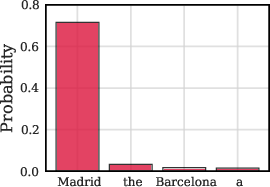
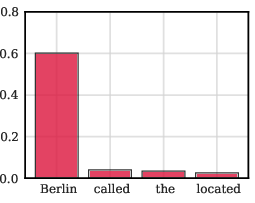
- Because the vectors are tied to specific tokens, you can “edit” behavior by swapping which token’s STEM vector is used—without changing the input text.
- For example, you can make the model behave as if the country were “Germany” even if the prompt says “Spain,” just by swapping the internal token vectors. This shows where knowledge lives in the model and how to change it in a targeted way.
- Stronger performance on long texts:
- As the sequence gets longer and includes more unique words, the model uses more distinct token-specific vectors, effectively increasing its active capacity at test time.
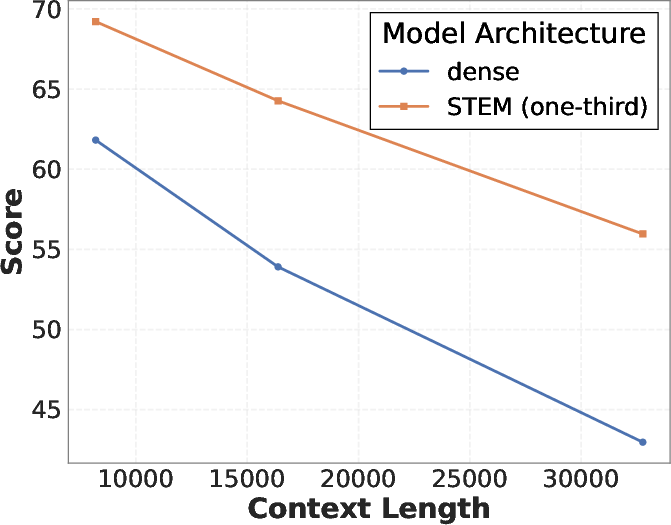
- On the Needle-in-a-Haystack test, STEM’s advantage grew as context length increased (e.g., the performance gap over the dense baseline increased from about 8.4% to 13%).
- System and memory benefits:
- By offloading embedding tables to CPU and prefetching them, STEM avoids heavy cross-device communication (a common MoE bottleneck).
- It uses less GPU memory for FFN parameters and avoids costly all-to-all routing.
- Why replace the “up-projection,” not the gate?
- The authors explain the FFN as a kind of “memory” that uses “keys” (from the up-projection) and “values” (from the down-projection).
- Replacing the up-projection with token-specific vectors works well because those vectors act like clear “addresses” for the memory.
- Keeping the gate as a learned, context-aware part helps the model adapt to the sentence—replacing the gate with a static embedding hurt performance in tests.
What does this mean for the future?
- Cheaper scaling: STEM shows a promising way to grow a model’s knowledge without paying a high cost in speed or memory. That could make future models smarter and more affordable to run.
- Better control and understanding: Because each token has its own vectors, developers can better understand what the model knows and edit it in a focused way. That’s a step toward more transparent and controllable AI.
- Stronger long-context abilities: As we push models to handle longer documents (like books, multi-article research, or long conversations), STEM’s “activate more when needed” behavior is especially valuable.
- Plays well with others: STEM is compatible with other ideas (like MoE). You could build “Mixtures of STEM experts,” combining their strengths.
In short: STEM is a simple but powerful change—swap one big calculation for a token-specific lookup—that makes LLMs more accurate, more efficient, more stable, and more interpretable, especially on knowledge-heavy and long-context tasks.
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that remain unresolved and could guide future work.
- Scaling behavior beyond 1B parameters: no evidence that STEM’s gains, stability, and efficiency persist at 7B–70B+ scales or under multi-trillion-token pretraining.
- Wall-clock and throughput measurements: efficiency claims are given in FLOPs/parameter-access terms, but lack end-to-end timing on varied interconnects (PCIe, NVLink, Infiniband) and diverse GPU generations.
- CPU offload limits and bandwidth sensitivity: no stress tests quantifying how prefetch traffic scales with batch size, context length, and unique-token rates under constrained host-bandwidth or noisy neighbors.
- Training with CPU-offloaded embeddings: the training implementation is incomplete; missing measurements for gradient write-back, optimizer-state offload, contention, and stability at scale.
- Memory footprint trade-offs: replacing an up-projection of size d_ff×d with per-layer tables of size V×d_ff may greatly inflate total parameters in CPU RAM; no quantified memory budgets (per layer, per model) for realistic vocab and d_ff.
- Multilingual and CJK tokenizers: unclear whether very large vocabularies (e.g., 200k–500k) and script diversity degrade STEM’s CPU memory, bandwidth, and accuracy trade-offs.
- Rare-token undertraining: STEM embeddings for low-frequency tokens may receive few updates; no techniques (e.g., sharing, tying, smoothing, prior regularizers) are proposed or evaluated to mitigate tail underfitting.
- Polysemy and context sensitivity: static token-indexed up-projection may struggle with polysemous tokens; no targeted evaluation on word-sense disambiguation or controlled ambiguity tests to quantify failures.
- Robustness across tokenizers: sensitivity to tokenization changes (BPE vs Unigram, merges, domain-specific tokenizers) is untested; no study of how re-tokenization affects learned STEM tables or knowledge editing.
- Domain transfer and OOD generalization: no experiments on cross-domain shifts (biomedical, legal, code-heavy corpora) to assess whether token-tied address vectors overfit domain-specific statistics.
- Long-context worst cases: while capacity scales with unique tokens, no analysis of worst-case prefetch load when L_uniq≈L (e.g., deduplicated or highly diverse contexts) and its latency impact.
- Cache policies: LFU cache efficacy is reported qualitatively; no ablation of cache size, eviction policies, or hit-rate vs latency curves under different workloads and vocab distributions.
- Quantitative interpretability: the “angular spread” observation lacks rigorous metrics (e.g., mutual coherence, subspace overlap) and correlation with downstream retrieval/knowledge attribution fidelity.
- Knowledge editing evaluation: edits are shown qualitatively; missing quantitative success rates, side-effect footprint on unrelated behaviors, layer-wise sensitivity, and persistence across prompts and tasks.
- Safety and misuse of editing: no discussion of guardrails against malicious knowledge injection/swapping or of auditing mechanisms to detect/edit provenance across layers.
- Compositional and synonym generalization: token-localized knowledge may impair synonym/paraphrase transfer; no tests on lexical substitution or paraphrase benchmarks to check compositionality.
- Instruction tuning and alignment: unknown interaction with SFT/RLHF—do STEM tables help or hinder alignment, refusal behavior, or controllability post-tuning?
- Code and math specificity: evidence on GSM8K is promising but sparse; no fine-grained analysis on code generation, unit tests, and structured reasoning tasks to pinpoint where STEM helps or hurts.
- Combination with MoE: authors note orthogonality but provide no experiments; open design/efficiency questions for “Mixture of STEM Experts” and communication patterns under expert parallelism.
- Quantization and compression: no study of quantizing STEM tables (per-layer V×d_ff), mixed-precision training, or compression schemes compatible with frequent CPU–GPU transfers.
- Curriculum and sampling: no strategies to rebalance exposure to tail tokens (e.g., adaptive sampling, frequency-aware regularization) to improve rare-token STEM quality.
- Placement and fraction of STEM layers: placement is called “critical,” but systematic search over which layers to convert, scaling the number of STEM layers, and per-layer d_ff sensitivity is incomplete.
- Ablations on gating/down projections: while replacing gate hurts, deeper analysis of gate capacity bottlenecks, alternative gating nonlinearities, or low-rank/shared gate variants is missing.
- Theoretical capacity analysis: no formal model linking angular spread, addressability, and interference to generalization or sample complexity; absence of scaling-law comparisons vs dense/MoE.
- Catastrophic interference across layers: unclear how token-level edits or updates in one layer propagate across layers and whether they induce unintended interference in other capabilities.
- Robustness to adversarial and noisy inputs: no robustness tests (typos, homoglyphs, adversarial perturbations) to see if token-tied addresses exacerbate brittleness.
- Data privacy and memorization risk: token-localized memory may increase susceptibility to membership inference or verbatim recall; no privacy audits or mitigation strategies.
- Cross-device replication costs: replicating V×d_ff tables on every serving node is asserted but not costed for multi-tenant, multi-model serving; missing analyses of amortization and operational overhead.
- KV-cache interaction: long-context benefits are claimed, but there is no analysis of trade-offs with KV-cache size, paging, and end-to-end memory pressure under real workloads.
- Continual learning and updates: how to add/merge tokens or revise knowledge post-deployment (e.g., new entities, spelling variants) without retraining is not addressed.
- Failure analysis: no breakdown of where STEM underperforms dense (task subsets, categories), nor error taxonomies to guide targeted improvements.
- Statistical significance and variance: limited reporting on run-to-run variance, confidence intervals, and sensitivity to hyperparameters (LR, warmup, weight decay) for fair comparison.
- Licensing and data mixture effects: improvements may depend on OLMo-Mix and Nemotron mixtures; no study of data composition sensitivity or data-scaling on STEM’s relative gains.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with the methods and findings introduced in the paper.
- Efficient LLM serving with static sparsity
- Sectors: software infrastructure, cloud platforms, energy efficiency
- What to deploy: retrofit existing decoder-only models to replace FFN up-projection with per-layer token-indexed STEM embeddings; offload STEM tables to CPU; add asynchronous prefetch, token deduplication, and LFU caching in the inference stack
- Workflow: update model layer definitions; implement a CPU-resident embedding store; prefetch unique token embeddings per batch; overlap prefetch with compute; cache hot tokens
- Assumptions/dependencies: sufficient CPU RAM to hold per-layer tables; CPU–GPU bandwidth adequate for prefetch overlap; stable training recipes (validated at 350M–1B); vocab/tokenization unchanged after deployment
- Cost-optimized training and fine-tuning of sub-billion LLMs
- Sectors: startups, research labs, enterprise ML
- What to deploy: pretrain or mid-train insertion of STEM in 350M–1B models to reduce FLOPs and parameter loading while preserving or improving accuracy; use the provided training schedules and sharding of STEM tables
- Workflow: replace one-third to one-half of FFN layers with STEM; shard STEM tables across GPUs; optionally offload STEM to CPU even during training; enable deduplication and LFU cache on gradient/resident embeddings
- Assumptions/dependencies: token distribution is Zipfian to yield cache benefits; reliable gradient write-back when offloading; optimizer state management for offloaded parameters
- Long-context inference for multi-document tasks at near-constant per-token compute
- Sectors: legal (contract analysis), healthcare (long EHR summarization), finance (prospectus analysis), R&D (literature review)
- What to deploy: use STEM-enhanced models for contexts 8k–32k+ where test-time capacity scales with unique tokens; apply to NIAH-like retrieval and multi-document reasoning
- Workflow: fine-tune with extended context data; monitor distinct token activation and latency; employ STEM at a subset of layers to balance throughput vs. capacity
- Assumptions/dependencies: long-context training data and masking strategies available; CPU offload remains effective at large vocab coverage
- Fast, controllable knowledge editing without text changes
- Sectors: enterprise knowledge management, compliance, localization, content operations
- What to deploy: “knowledge editor” tool that swaps per-token STEM embeddings (e.g., replace token t_source embeddings with t_target embeddings across layers) to correct facts or localize content
- Workflow: build an API/UI over STEM tables to map, copy, pad, subset, or average target token embeddings; audit and roll back edits; evaluate downstream effects on specific domains
- Assumptions/dependencies: tokenization alignment between source and target concepts; robust QA/evaluation harnesses; governance to prevent unintended distribution shift or covert edits
- Auditable attribution via token-level micro-expert semantics
- Sectors: safety, policy/regulation, risk/compliance
- What to deploy: attribution dashboards that reveal which token-indexed embeddings were used per layer; link outputs to token-scope “micro-expert” roles
- Workflow: log per-layer token-indexed embedding activations; surface interpretability metrics (e.g., angular spread, similarity neighborhoods); attach provenance to outputs
- Assumptions/dependencies: stable token-to-embedding semantics within a model version; reproducible mapping across evaluation runs
- Simpler sparsity than MoE for production inference
- Sectors: cloud inference platforms, MLOps
- What to deploy: replace MoE layers that suffer from routing overhead with STEM; eliminate all-to-all traffic and reduce latency sensitivity to batch routing diversity
- Workflow: swap MoE FFNs for STEM-enhanced FFNs; prefetch embeddings locally; benchmark end-to-end latency/throughput
- Assumptions/dependencies: CPU memory replication of tables per node; model quality comparable or better on target workloads
- Edge and mobile model deployment with smaller compute/memory budgets
- Sectors: mobile apps, embedded robotics, consumer devices
- What to deploy: STEM in compact models (e.g., MobileLLM-350M) to cut decoding parameter traffic and FLOPs; leverage system RAM for tables where GPU memory is limited
- Workflow: on-device serving with RAM-based embedding tables; streamline prefetch and cache for frequent vocabulary
- Assumptions/dependencies: device interconnects (CPU–GPU or NPU–RAM) support low-latency embedding fetch; model quantization compatible with token-indexed tables
- Domain lexicon specialization without MoE complexity
- Sectors: scientific publishing, pharma, legal, code intelligence
- What to deploy: STEM tables tuned for domain-specific vocab to store and retrieve specialized facts more cleanly (large angular spread reduces interference)
- Workflow: targeted fine-tuning on domain corpora; evaluate gains on domain benchmarks (MMLU subsets, code tasks); monitor per-domain token embedding geometry
- Assumptions/dependencies: domain terms exist in the tokenizer or are added via controlled re-tokenization; careful evaluation to avoid catastrophic edits
- ROI-focused model portfolio management
- Sectors: enterprise AI strategy, finance of compute
- What to deploy: model selection and training policies that favor STEM variants due to improved accuracy-per-FLOP; integrate cost tracking (activated FLOPs, bandwidth)
- Workflow: track “Training ROI = accuracy / total training FLOPs” across models; prioritize budgets for STEM-enabled experiments; adopt CPU offload where cost-effective
- Assumptions/dependencies: standardized ROI metrics across tasks; accurate accounting of offload bandwidth and cache hit rates
- Safer hotfixes for live systems
- Sectors: customer support, e-commerce, media, public sector
- What to deploy: rapid corrections to known factual errors by swapping relevant token embeddings while avoiding full model re-training
- Workflow: identify faulty entity tokens; apply embedding replacement strategies; A/B test responses; log and audit all edits
- Assumptions/dependencies: reliable edit scoping to specific tokens; strong validation suites; rollback mechanisms in case of regressions
Long-Term Applications
Below are applications that likely require further research, scaling, tooling, or hardware advances before broad deployment.
- Frontier-scale STEM (10B–100B+ parameters)
- Sectors: foundation model providers, hyperscalers
- Potential product/workflow: STEM-aware training frameworks with distributed CPU memory pools (e.g., CXL-enabled), hierarchical caching, and adaptive sharding of embedding tables; end-to-end throughput gains at scale
- Assumptions/dependencies: high-bandwidth CPU–GPU interconnects; robust optimizer state offload; fault-tolerant embedding sharding across nodes
- Mixture-of-STEM experts (MoE + STEM)
- Sectors: advanced LLM research, high-end serving
- Potential product/workflow: experts that internally use STEM-enhanced FFNs to combine dynamic routing with static per-token memory; improved capacity without prohibitive communication
- Assumptions/dependencies: balanced routing to avoid skew; techniques to cap communication overhead; new kernels for small expert subnetworks
- Formal governance and audit trails for knowledge editing
- Sectors: regulation, compliance, safety engineering
- Potential product/workflow: versioned “knowledge packs” and audit logs of embedding-level edits; differential testing to detect collateral effects; policy templates for permissible edits
- Assumptions/dependencies: standardized interpretability metrics; legal frameworks for “knowledge attribution” in AI systems
- Hardware–software co-design for memory-tiered inference
- Sectors: semiconductors, systems research
- Potential product/workflow: co-designed caching hierarchies (HBM–CPU RAM–NVRAM) tailored to token Zipf distributions; near-memory compute primitives for embedding fetch
- Assumptions/dependencies: evolving interconnect standards (NVLink, PCIe Gen6, CXL); firmware/runtime support for asynchronous, deduplicated transfers
- Cross-lingual and multi-token semantic editing
- Sectors: global content, localization, multilingual AI
- Potential product/workflow: robust edit strategies across languages and tokenization schemes (BPE/Unigram), including alignment methods for length-mismatched entities and phrases
- Assumptions/dependencies: cross-lingual token alignment tooling; evaluation harnesses to detect subtle semantic drift
- Hot-swappable domain knowledge modules
- Sectors: enterprise software, vertical SaaS
- Potential product/workflow: packaged, versioned STEM embedding tables for domains (finance, medical, legal) that can be installed/uninstalled without retraining
- Assumptions/dependencies: interface standards for table import/export; regression testing pipelines; secure provenance metadata
- Formal robustness guarantees for embedding edits
- Sectors: safety, academia
- Potential product/workflow: theoretical and empirical bounds on the locality and collateral effects of per-token embedding swaps; safe-edit policies and constraints
- Assumptions/dependencies: mechanistic interpretability advances; counterfactual evaluation datasets; certification frameworks
- Privacy-preserving personalization via token-indexed embeddings
- Sectors: consumer AI, healthcare, finance
- Potential product/workflow: per-user or per-tenant token embeddings stored securely and auditable; differential privacy mechanisms; on-device caches for personalization tokens
- Assumptions/dependencies: secure key management for embedding tables; privacy guarantees; opt-in user consent and policy alignment
- Green AI and sustainability reporting
- Sectors: ESG reporting, policy
- Potential product/workflow: standardized metrics to quantify energy savings from STEM (FLOPs reduction, memory traffic); tools to report carbon impact improvements
- Assumptions/dependencies: reliable telemetry on power usage; alignment with emerging reporting standards
- Tooling for STEM-aware development
- Sectors: developer tooling, MLOps
- Potential product/workflow: “Embedding Editor” IDEs, diagnostics for angular spread and overlap, visualization of token neighborhoods, APIs for safe swap/average/pad/copy operations
- Assumptions/dependencies: integration with major ML frameworks; ergonomic APIs; education/training for practitioners on best practices and pitfalls
- Security hardening against malicious edits
- Sectors: security, trust & safety
- Potential product/workflow: watermarking or cryptographic signatures for embedding tables; anomaly detection for unauthorized edits; policy enforcement over sensitive tokens
- Assumptions/dependencies: secure storage and access control for CPU-offloaded tables; continuous monitoring and alerting; red-team evaluations
Glossary
- Activated FLOPs: The count of floating-point operations actually executed per token in a sparse model, often kept roughly constant even as parameters grow. "because they raise parametric capacity at roughly constant activated FLOPs by sparsely activating a small subset of experts per token."
- Address vectors: Vectors that specify positions in a learned memory-like space to retrieve information, typically produced by the up-projection in FFNs. "the up-projection matrix maps each input hidden state to an address vector"
- All-to-all messages: Distributed communication pattern where each device communicates with every other, often used in expert parallelism and can become a bottleneck. "increasing the number of experts typically raises the number of all-to-all messages while shrinking message sizes"
- Autoregressivity: The property of generating the next token conditioned on all previous tokens, which constrains parallelism and prefetch timing. "because of autoregressivity."
- Auxiliary losses: Additional loss terms used to regularize or stabilize training (e.g., load balancing), beyond the primary objective. "To eliminate trainable routing and auxiliary losses, hash-layer MoE fixes a balanced, token-id–based mapping to experts"
- Content-addressable key–value (KV) memory: A memory interpretation of FFNs where inputs address keys to retrieve associated values. "A two-projection FFN can be read as a content-addressable key–value (KV) memory"
- Cross-device communication: Data transfer between different compute devices (e.g., GPUs), often a bottleneck in distributed training. "decouples capacity from both per-token FLOPs and cross-device communication."
- Cross-document attention masking: A masking strategy to prevent attention across document boundaries when packing multiple sequences. "pack sequences up to 32{,}768 tokens with cross-document attention masking."
- DDP: Distributed Data Parallel; a training strategy that replicates models across devices and synchronizes gradients. "Irrespective the parallelism technique (DDP, FSDP, or TP), we always shard the STEM embedding table across the available GPUs."
- Decoder-only transformer: A transformer architecture composed only of decoder blocks, typically used for autoregressive language modeling. "Consider a decoder-only transformer with layers, vocabulary size , model width , and feed-forward width $d_{\mathrm{ff}$."
- Down-projection: The second linear projection in an FFN that maps the intermediate hidden width back to the model width. "while keeping the gate and down-projection dense."
- Embedding table: A matrix storing learned vectors indexed by tokens (or other IDs), used to retrieve token-specific parameters. "let $\mathbf{U}_{\ell}\!\in\!\mathbb{R}^{V\times d_{\mathrm{ff}$ be the per layer embedding table."
- Expert parallelism: A distributed scheme that partitions experts across devices, requiring routing and communication among them. "Under expert parallelism, as the expert granularity increases, the peer-to-peer exchange becomes more fragmented"
- Expert subnetworks: Smaller specialized networks (experts) within a larger model, often activated sparsely per token. "Finer granularity can also reduce parameter-access locality and degrade kernel efficiency when expert subnetworks become too small"
- FFN: Feed-Forward Network; the MLP component within transformer layers that transforms hidden states with projections and nonlinearities. "the FFN output becomes"
- Fine-grained sparsity: A sparsity pattern with many small, specialized components (e.g., micro-experts), enabling high capacity with lower per-token compute. "Fine-grained sparsity promises higher parametric capacity without proportional per-token compute"
- FLOPs: Floating-point operations; a measure of computational cost used to compare efficiency across model designs. "reducing per-token FLOPs and parameter accesses"
- FSDP: Fully Sharded Data Parallel; a training approach that shards model parameters, gradients, and optimizer states across devices. "Irrespective the parallelism technique (DDP, FSDP, or TP), we always shard the STEM embedding table"
- Gate projection: The linear projection producing gating signals in GLU-based FFNs, modulating the content stream. "the SwiGLU feed-forward block uses a gate projection "
- Gated linear units (GLUs): FFN variants where a gate multiplicatively modulates content, sharpening retrieval and selectivity. "Gated linear units (GLUs) enrich this memory by factorizing the addressing into content and gate streams"
- GELU: Gaussian Error Linear Unit; a smooth activation function often used in transformers. "GELU for soft gating"
- Hash-layer MoE: A MoE variant with fixed, token-id–based expert assignment via hashing, removing trainable routing and auxiliary losses. "hash-layer MoE fixes a balanced, token-id–based mapping to experts"
- HBM capacity: High Bandwidth Memory capacity on accelerators (e.g., GPUs), a constraint for storing large parameter sets. "This additional memory footprint can easily grow beyond the available HBM capacity."
- Heaps-like: Refers to Heaps’ law; sublinear growth of unique tokens with sequence length in natural text. "In natural text typically grows sublinearly (Heaps-like)"
- Knowledge editing: Modifying model-internal representations to change specific factual outputs without altering the input text. "we study whether STEM embeddings allow us to edit factual knowledge by modifying only the STEM vectors"
- KV cache: Key–Value cache storing past attention projections during decoding to avoid recomputation. "decoding is primarily memory-bound: the dominant cost is loading parameters and KV cache rather than doing FLOPs."
- LFU caching: Least Frequently Used caching strategy to store frequently accessed embeddings and reduce CPU–GPU traffic. "we utilize the property that the input token ids follow a Zipfian distribution to implement a memory-efficient LFU cache"
- Load balancing: Training objective or mechanism that distributes routing traffic evenly across experts to avoid under-training and congestion. "While load-balancing objectives can address these issues, they may interfere with the primary objective"
- Long-context inference: Model inference on extended sequences, stressing memory, attention, and parameter activation patterns. "Improved Long-context Inference: During long-context inference, STEM activates more distinct parameters"
- Matmul weights: Weights used in matrix multiplications (linear layers), often stored on GPU; separating them can affect memory and communication. "These tables are separate from the matmul weights, so we can offload them to CPU memory."
- Mixture-of-Experts (MoE): Architectures that route tokens to a subset of expert FFNs, increasing capacity at similar per-token compute. "Mixture-of-Experts (MoE) models have been adopted in several frontier LLMs"
- Mixture of Word Embeddings (MoWE): An extreme MoE granularity approach where experts are instantiated per word/token to increase knowledge capacity. "Mixture of Word Embeddings (MoWE) pushes expert granularity to the word level"
- Needle-in-a-Haystack (NIAH): A benchmark evaluating retrieval performance in long contexts by hiding a target among distractors. "on Needle-in-a-Haystack (NIAH), the gap over the dense baseline increases from 8.4\% to 13\%."
- Optimizer states: Internal states (e.g., momentum, variance) maintained by optimizers like Adam, increasing memory use during training. "the additional footprint of optimizer states and gradients can be substantial."
- Parameter-access locality: The degree to which parameter accesses are contiguous and cache-friendly; low locality can slow kernels. "Finer granularity can also reduce parameter-access locality and degrade kernel efficiency"
- Parameter-scaling laws: Empirical laws predicting performance gains with increasing parameter counts. "Sparse computation is a key mechanism for realizing the benefits predicted by parameter-scaling laws"
- Per Layer Embedding (PLE): A design that adds per-layer token-indexed embeddings to complement FFNs, sharing gate and down projections. "Per Layer Embedding (PLE) share the gate projection and down projection of the FFN block across expert subnetworks."
- Prefetch: Fetching required data (e.g., embeddings) ahead of time to overlap communication with computation. "they can be prefetched asynchronously with layer computation."
- Prefilling: The initial, often compute-bound phase of inference that processes the entire input context before token-by-token decoding. "more efficient during both computation-intensive training and prefilling"
- Q/K/V/O: The four linear projections in attention: Query, Key, Value, and Output. "Aside from the shared projections in attention (Q/K/V/O)"
- Return on Investment (ROI): A metric relating accuracy to training compute, used to assess training efficiency. "We evaluate the Return on Investment (ROI)—defined here as the ratio of model accuracy to training FLOPs"
- Router: The component in MoE that selects which experts a token should activate, often using top-k selection. "a router that selects a small set of top- experts"
- SiLU: Sigmoid Linear Unit; an activation function used as the gate nonlinearity in SwiGLU. "SwiGLU replaces the gate nonlinearity with ."
- Sparse autoencoders: Models trained to learn sparse representations, used for interpretability and feature disentanglement. "Although recent works like sparse autoencoders have tried to interpret the FFN modules"
- Static sparsity: A sparsity pattern determined without runtime routing, enabling predictable compute paths and offloading. "We identify static sparsity as a potential solution to achieve these desired properties."
- Stragglers: Slow workers in distributed systems that delay synchronization and reduce throughput. "capacity padding/drops, stragglers), further amplifying effective communication and synchronization costs"
- Superposition: The phenomenon of encoding multiple concepts in overlapping directions within limited-dimensional spaces. "FFN layers rely on mechanisms such as superposition to encode a large number of concepts"
- SwiGLU: A gated FFN variant combining a linear unit with SiLU gating for improved expressivity. "Consider, for a given layer, the SwiGLU feed-forward block"
- Token deduplication: Removing duplicate token IDs in a batch to reduce repeated embedding transfers and communication. "Thus the batch token ids can deduplicated to reduce the CPU-GPU communication overhead"
- Token-indexed routing: Assigning experts or embeddings based on token IDs, avoiding dynamic routing decisions. "static sparsity via token-indexed routing has emerged as a promising direction"
- Top-r routing: Selecting the top r experts per token according to router scores. "Router (top-)"
- TP: Tensor Parallelism; a strategy to split tensor computations across devices to scale model size. "Irrespective the parallelism technique (DDP, FSDP, or TP)"
- Up-projection: The first linear projection in an FFN that expands the hidden dimension to the intermediate width. "replaces only the up-projection in gated FFNs with a token-specific vector"
- VRAM: Video RAM on GPUs; limited memory used to store model parameters, activations, and caches. "MoE models use a lot of VRAM."
- Zipfian: A heavy-tailed distribution of token frequencies where few items are very common and many are rare. "Word frequencies are Zipfian, so a larger number of experts sharpens load skew"
Collections
Sign up for free to add this paper to one or more collections.

