- The paper introduces a 68-metric framework assessing AI-driven web app generators as virtual software agencies across planning, engineering, and operations.
- It highlights significant specification bottlenecks and frontend-backend decoupling that mask critical production and security failures.
- The results reveal high post-generation human effort and iterative modification challenges, emphasizing the gap between demo outputs and production readiness.
Framework Overview and Methodology
SWE-WebDev Bench introduces a multidimensional, 68-metric evaluation protocol for AI platforms that generate complete web applications from natural language, targeting the so-called “vibe coding” paradigm where users act as product owners, not developers. Unlike earlier code-centric benchmarks, SWE-WebDev Bench appraises platforms as integrated “virtual software agencies.” It captures the entire delivery lifecycle—requirement inference (PM), code generation (Engineering), infrastructure/deployment (Ops), and iterative modification—with explicit metrics and diagnostic traceability (Figure 1).
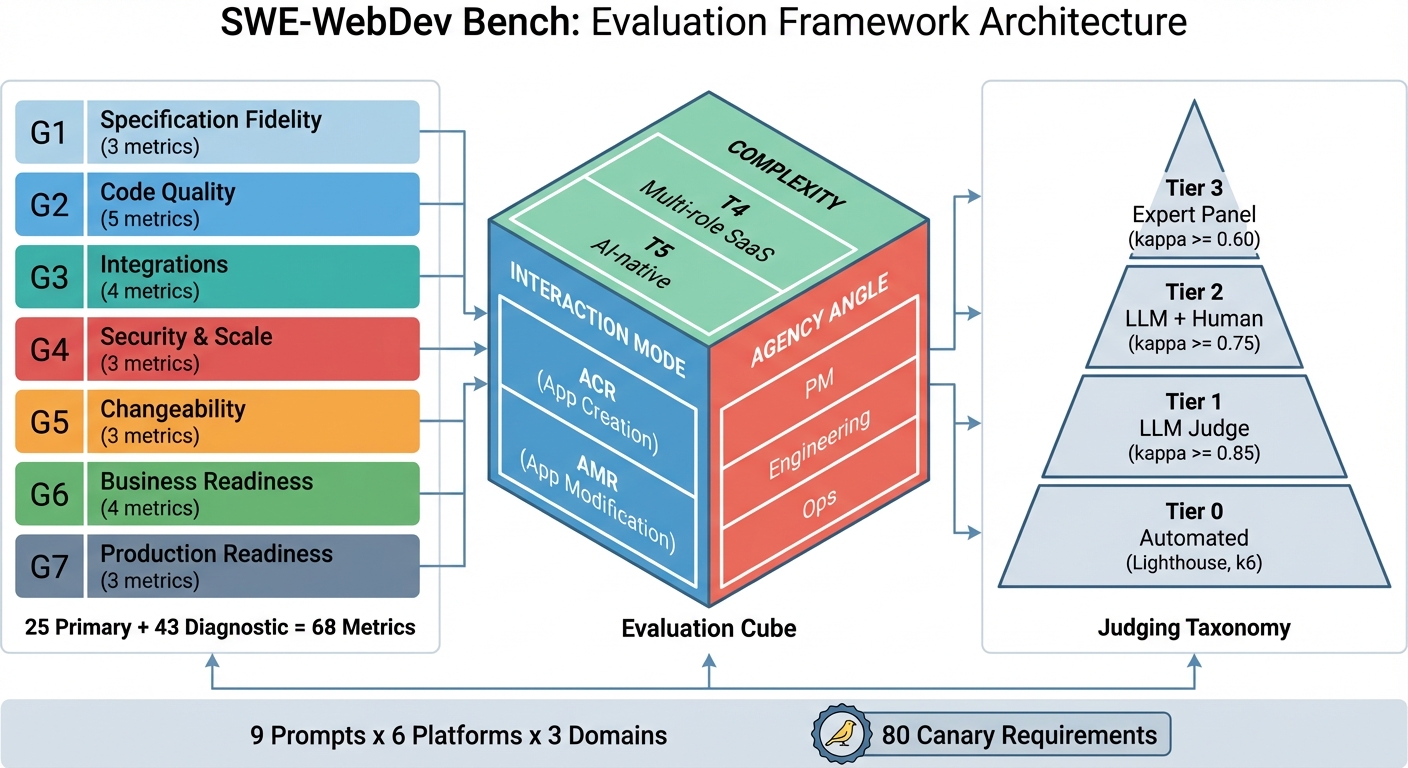
Figure 1: SWE-WebDev Bench framework—metrics span 7 groups, evaluated along three dimensions: Interaction Mode (ACR/AMR), Agency Angle (PM/Engineering/Ops), and Complexity Tier (T4/T5); incorporates a four-tier judging taxonomy and 80 canary requirements across six platforms and three domains.
Three axes of evaluation form a cube: Interaction Mode (App Creation Requests vs. App Modification Requests), Agency Angle (Product Manager, Engineering, Operations), and Complexity Tier (multi-role SaaS, AI-native applications). The metric system pairs 25 primary with 43 diagnostic metrics to localize failure modalities, including feature completeness, canary retention, schema/architecture, security, integration, business readiness, and real-world operability. Judging relies on a tiered protocol, moving from fully automated tests (Tier 0) to LLM judges and expert evaluation (Tier 3), emphasizing reproducibility and mitigation of scaling bias.
A major methodological innovation is the “canary requirement” protocol: 80 embedded, subtle requirements (culture/locale-sensitive or contradictory domain rules) that probe whether agents perform genuine comprehension over template matching.
Experimental Setup and Prompt Suite
Six platforms (including Base44, Emergent, Lovable, QwikBuild, Replit, and Vercel v0-Max) are evaluated across three meticulously constructed business domains: EdTech (inference from ambiguous founder narrative), Field Service (complex RFP with explicit contradictions), and FinTech-AI (AI-native, multi-stage trust-critical pipeline). Each domain is represented by prompts of varied ambiguity, imposing orthogonal diagnostic pressures—requirement extraction, execution fidelity, or AI feature integrity.
Prompt styles deliberately stress varied capabilities: domain-specific deduction (vague, rambling input), transactional precision (structured, detailed input), and trust/security management (AI-centric flows). Canary requirements—classified as original, new, surviving, or contradiction—map the fidelity of information propagation and transformation, especially under iterative modifications.
Evaluation proceeds through a seven-phase pipeline, from initial prompt submission through deployment, security and load audit, and aggregation of human/automated/LLM judgments (Figure 2).
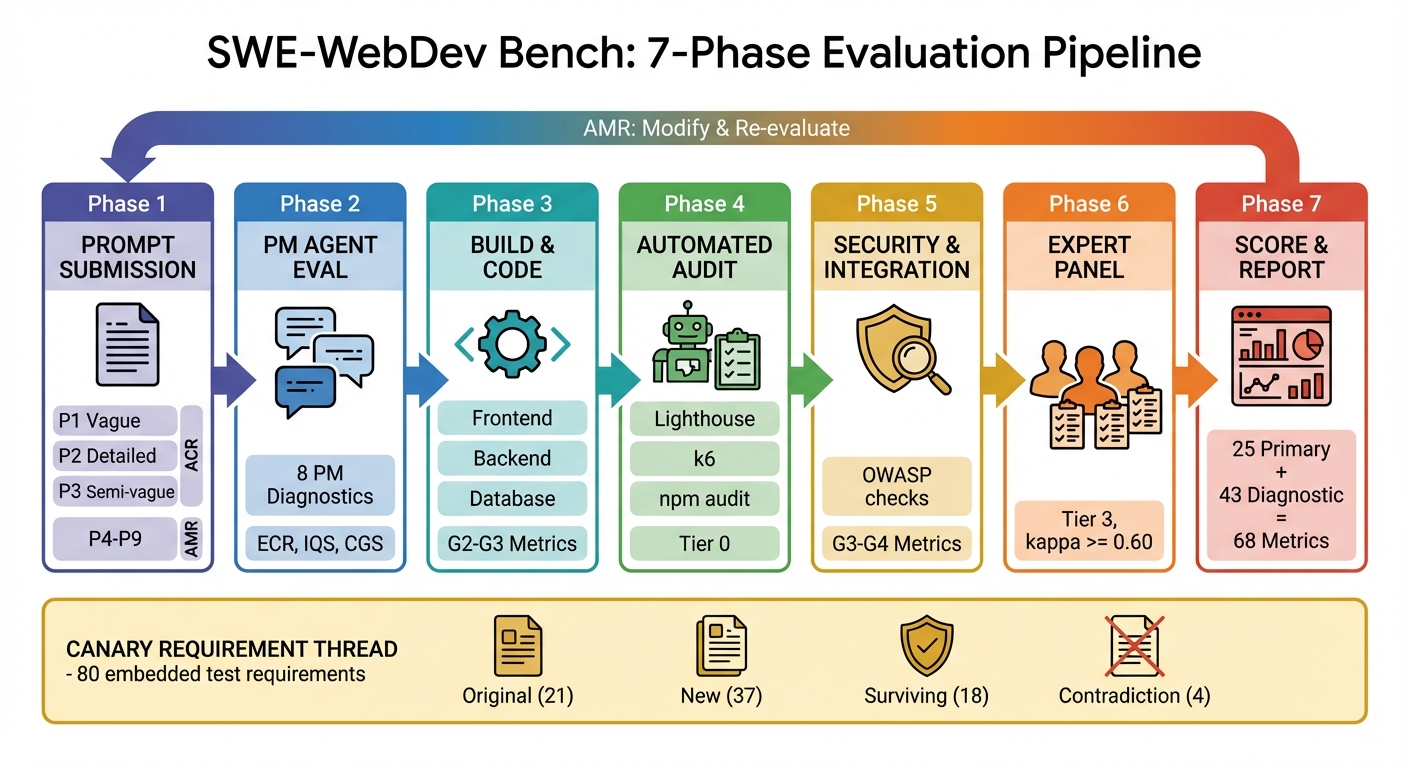
Figure 2: Seven-phase evaluation pipeline integrating prompt submission, multi-angle evaluation, automated and human audit, and iterative diagnostic feedback—with a canary requirement thread across all stages.
Key Findings
1. Specification Bottleneck
Requirement capture is the most differentiating—and deficient—capability. Inference Quality Score (IQS) varies by 3.5× (20–70) across platforms. Many agents compress rich business intent into oversimplified plans, often skipping requirement elicitation. As a result, Canary Retention Rate varies from 17.7% to 97.7%, directly reflecting whether detailed domain requirements survive the generation pipeline.

Figure 3: Four recurring findings—(1) inference/spec bottleneck, (2) frontend-backend decoupling, (3) readiness cliff, (4) pervasive security failures—are visualized, each exposing core limitations.
2. Frontend–Backend Decoupling
Frontend quality is a poor predictor of production viability. Across the field, multiple platforms deliver visually polished UIs (FES 68–74%) while the corresponding background infrastructure is either absent or non-functional (CBS as low as 0%; Figure 4). Strategies cluster as: Infrastructure-Integrated (highest backend pass-through), Ecosystem-Leveraged (makes use of platform-native libraries/tooling), or Frontend-Prioritized (optimizes for polished UX at the expense of backend fidelity). Polished presentation masks critical architectural or integration defects.
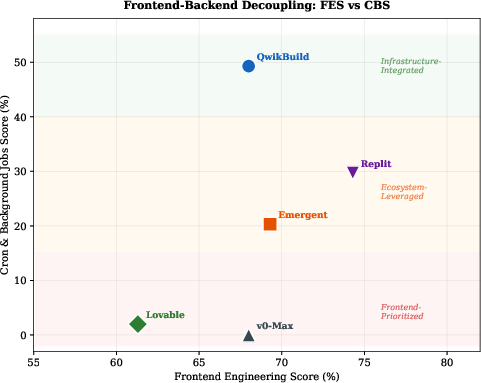
Figure 4: FES vs. CBS scatter showing wide spread in backend job support for highly similar frontend scores, indicating significant decoupling between visual and functional readiness.
3. Production Readiness Cliff
All platforms require substantial post-generation human engineering—Effort-to-Fix (ETF) spans 14.7 to 65.7 developer-hours even for the highest-performing configurations. No platform exceeds 60% on the core engineering composite. The Total Cost of Correctness and Feature Gap Delta remain high, revealing an order-of-magnitude cliff in what’s needed to move from demo to deployment (Figures 7 and 8). Furthermore, high Claim Drift Index values (up to 35.7%) demonstrate a chronic mismatch between platform-reported status and actual delivered capabilities.
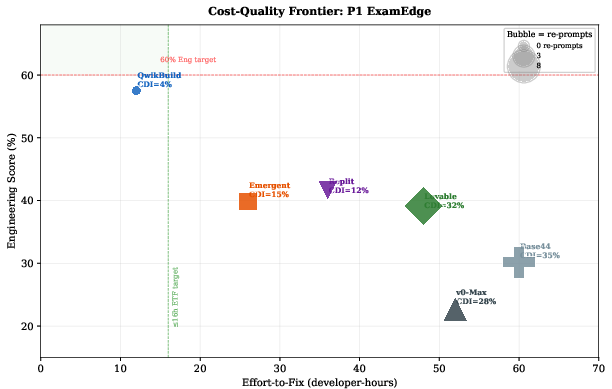
Figure 5: Cost-quality frontier for six platforms; ideal “top-right” (high-quality, low-fix) remains unpopulated—quality correlates with developer effort, and trustworthiness (CDI) is uneven.
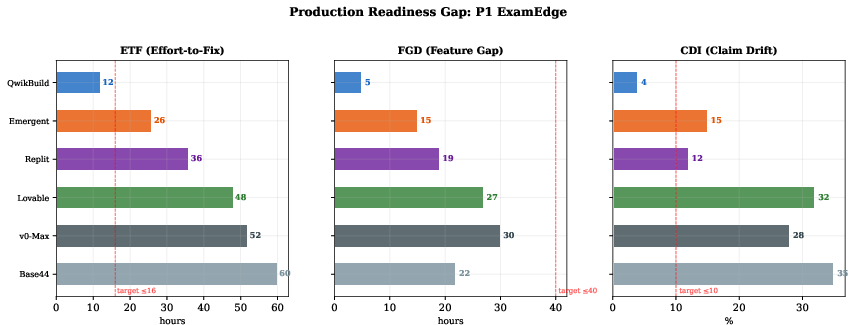
Figure 6: Decomposition of readiness gap—ETF, FGD, and CDI highlight fix, missing features, and trust as primary post-generation burdens.
4. Security and Infrastructure Failures
Security and concurrency scores are universally deficient: no platform exceeds 65% Security Score (target 90%), concurrency handling is as low as 6% (target 70%). Common lapses include hardcoded credentials, missing CSRF mitigations, lack of rate limiting, and incomplete access controls. This vulnerability spans all architectural classes and is corroborated by failed OWASP and load testing audits (Figure 7).
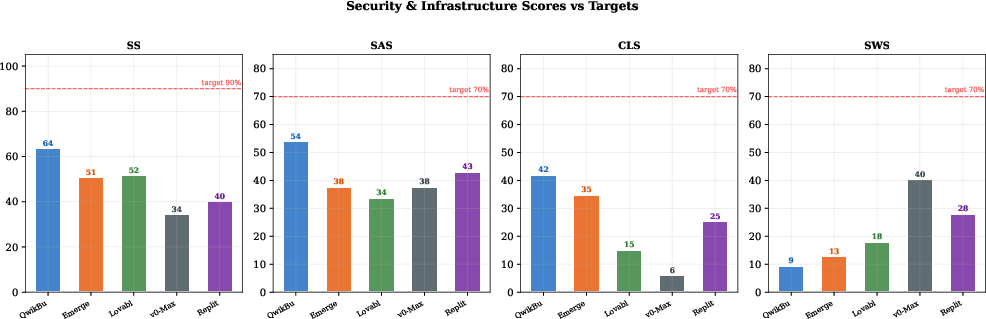
Figure 7: Security and infrastructure deficits visualized—every platform falls short of minimum deployment targets, with concurrency support especially critical.
5. AMR/Iterative Modification Weaknesses
Modification (AMR) is consistently harder than first-pass creation: post-creation metrics typically decline by 1–24 percentage points. Canary survival rates sharply degrade during structural AMRs, with surviving constraints three times likelier to be lost than new ones (Figure 8). Although coherent multi-agent planning reduces regression rates (in QwikBuild's AMR runs: 0% regressions), “change correct” and composite coherence scores still decline, indicating information loss and incomplete constraint propagation during iterative edits.
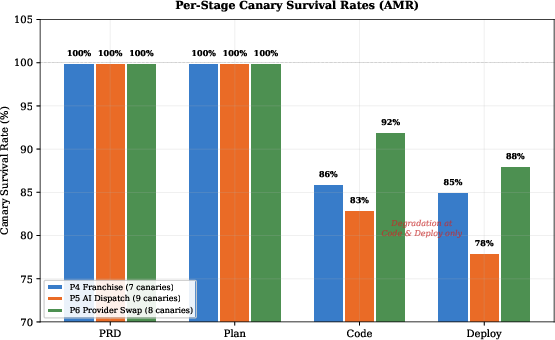
Figure 8: Canary requirement survival per stage under AMR—failures accumulate during code/deployment phases, with inherited requirements especially fragile.
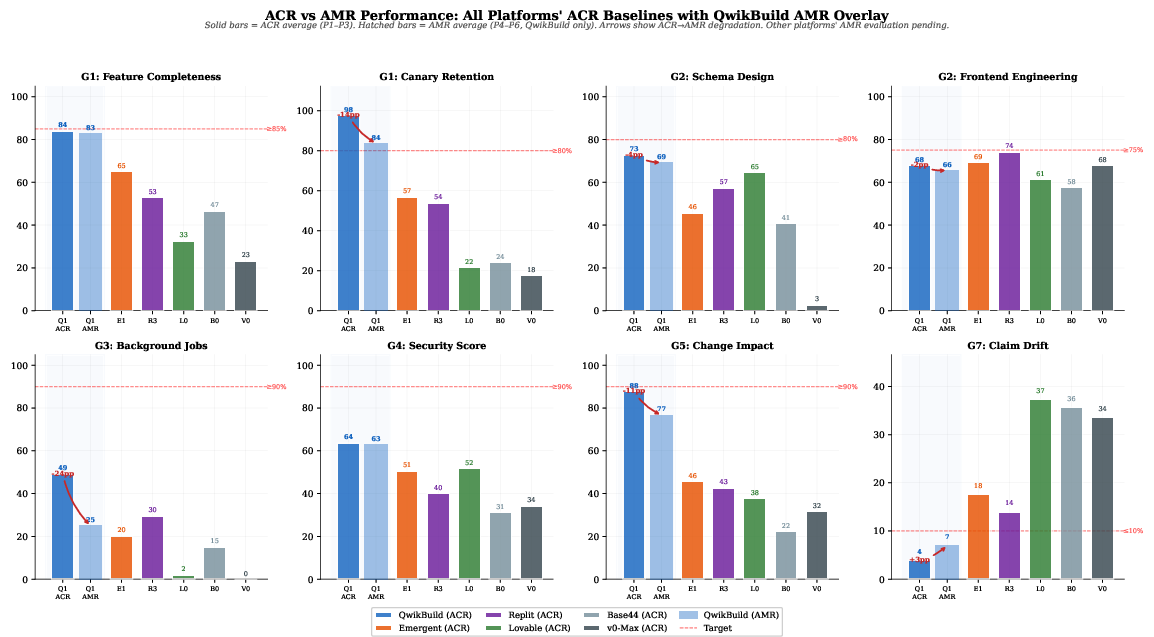
Figure 9: ACR (App Creation) vs AMR (App Modification) performance—modification typically downgrades all metric groups, and platforms near viability marginals risk catastrophic declines.
Diagnostic and Architectural Insights
- Single-pass plans predict poor coverage for vague business prompts; robust Q&A-style PM agents—with planning/clarification—are essential for correct domain mapping and contradiction resolution.
- Closed-loop code generation and proactive inter-agent feedback appear correlated with higher specification fidelity and lower Claim Drift Index, but these architectures are uncommon.
- Backend and infrastructure provision remains the deepest unsolved challenge—suggesting architectural investment should focus here, not just on UX generation or frontend polish.
- Iterative editable pipelines (AMR) introduce additional complexity—constraint-tracking, robust change management, and cross-agent state propagation remain fragile.
- Metrics like Canary Retention, Claim Drift Index, and Effort-to-Fix uniquely detect invisible but critical risks endemic to non-expert-driven workflows; these would not be surfaced by granular code-level or user-preference-driven benchmarks.
Implications and Future Directions
Practically, SWE-WebDev Bench provides a rigorous methodology for platform vendors to diagnose—and not just rank—deficiencies. For engineering teams deploying these systems, the consistently high post-generation human effort highlights the danger of deploying unvalidated outputs, especially in security-sensitive domains. Theoretically, the work signals a shift in evaluation: from developer-oriented, patch-level accuracy to system-level behavioral competence, multi-role agency, and iterative business alignment.
Most notably, the evidence suggests key research priorities:
- Advancing robust, dialog-style requirement elicitation agents with explicit contradiction/ambiguous requirement detection,
- Developing closed-loop, feedback-centric planning-to-execution architectures,
- Elevating backend/infrastructure module synthesis to parity with frontend-generation capabilities,
- Improving code modification consistency, especially for complex, stateful, or cross-cutting refactors,
- Promoting standardized, blind, and independent multi-angle evaluations to prevent metric gaming or evaluator bias.
SWE-WebDev Bench, as an open, extensible community benchmark, provides the groundwork for future large-scale, statistically robust replications, model-driven ablations, and architectural innovation in agentic software delivery.
Conclusion
SWE-WebDev Bench reveals that, despite substantial progress in full-stack code generation, current coding agent platforms universally fall short of replacing a professional software agency for end-to-end, production-grade, business-ready delivery. The primary limiting factors are inadequate requirement capture, backend-infrastructure fragility, high remedial effort, and security/infrastructure deficits. The framework’s comprehensive, diagnosis-driven methodology establishes a new baseline for benchmarking agentic web development systems—enabling granular, actionable analysis aligned with real-world production needs.
(2605.04637)

