- The paper presents SWE-Bench Pro, a contamination-resistant benchmark for long-horizon software engineering tasks that require multi-file, large-scale code modifications.
- It details a rigorous human-in-the-loop process and diverse dataset construction, emphasizing task complexity with concrete metrics like average 107.4 LOC changes per task.
- The evaluation shows frontier models achieve below 25% Pass@1, highlighting major challenges in aligning AI agent capabilities with real-world software development demands.
SWE-Bench Pro: A Rigorous Benchmark for Long-Horizon Software Engineering Agents
Motivation and Context
SWE-Bench Pro addresses critical gaps in the evaluation of LLM-based software engineering agents by introducing a benchmark that is both contamination-resistant and representative of real-world, enterprise-level software development. Existing benchmarks, such as SWE-Bench and SWE-Bench Verified, have become saturated, with top models achieving over 70% Pass@1. However, these benchmarks are limited by contamination risks due to permissive licensing and by the prevalence of trivial, single-file tasks that do not reflect the complexity of professional software engineering. SWE-Bench Pro is designed to overcome these limitations by curating a diverse set of challenging, long-horizon tasks from both public GPL-licensed and proprietary commercial repositories, emphasizing multi-file, large-scale code modifications.
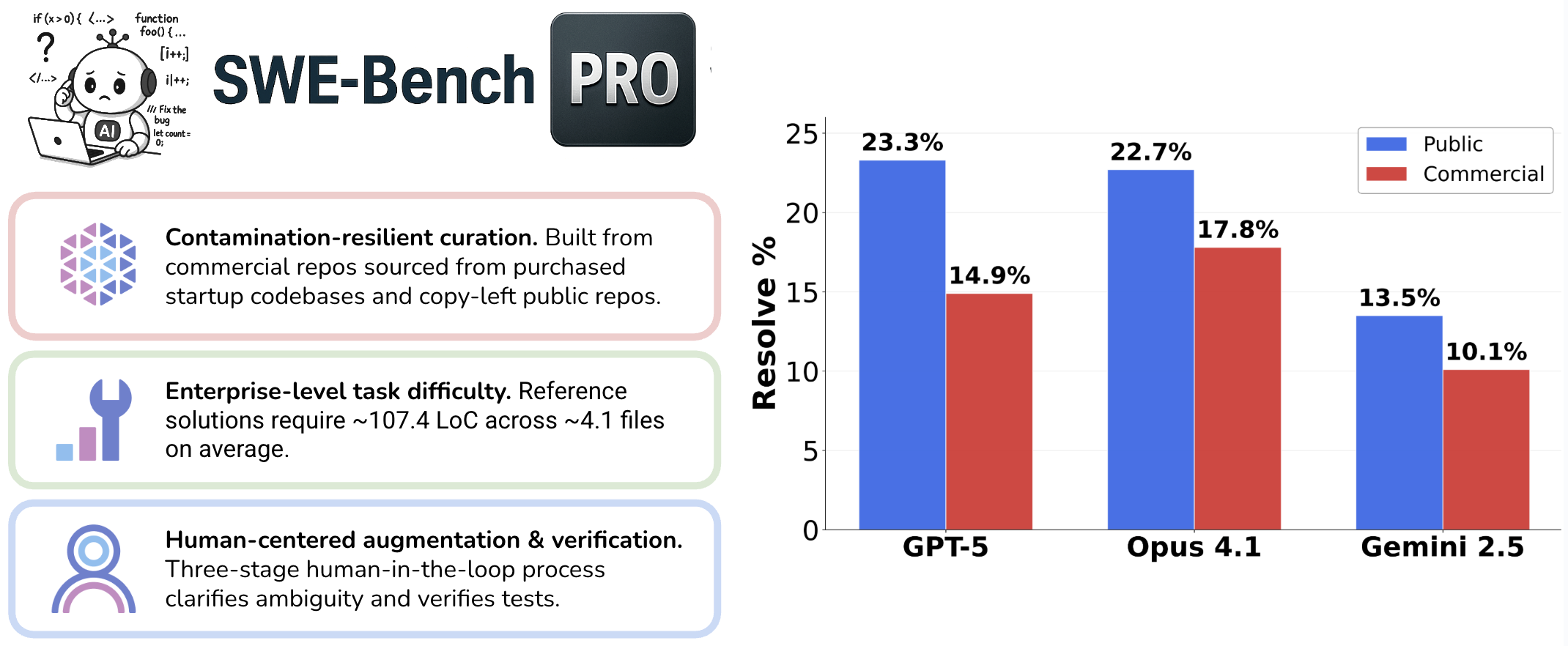
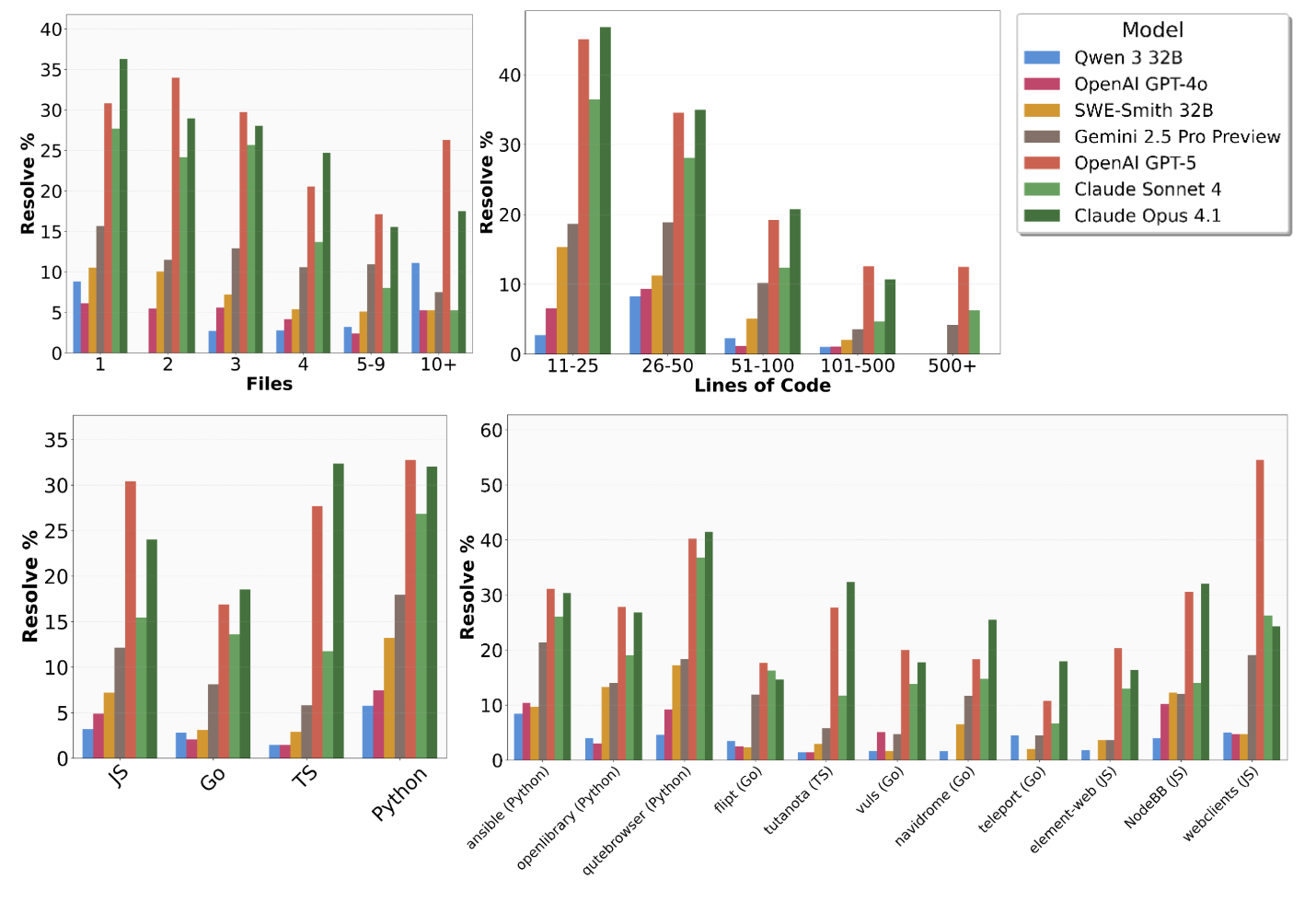
Figure 1: SWE-Bench Pro is a dataset with challenging, enterprise-level, long-horizon software engineering tasks. Frontier models, such as GPT-5 and Claude Opus 4.1, score less than 25% on SWE-Bench Pro with the SWE-Agent scaffold.
Dataset Construction and Design Principles
SWE-Bench Pro comprises 1,865 human-verified and augmented problems sourced from 41 actively maintained repositories, partitioned into public, held-out, and commercial subsets. The public set (731 instances) is derived from GPL-licensed repositories, the commercial set (276 instances) from proprietary startup codebases, and the held-out set (858 instances) is reserved for future overfitting checks. The benchmark enforces several key design principles:
- Contamination Resistance: By selecting only GPL-licensed public repositories and private commercial codebases, SWE-Bench Pro minimizes the risk of benchmark leakage into LLM training corpora.
- Task Complexity: All tasks require at least 10 lines of code changes, with an average of 107.4 LOC across 4.1 files per task. Over 100 tasks require more than 100 LOC modifications, and trivial edits are explicitly excluded.
- Human Augmentation and Verification: Each problem undergoes a three-stage human-in-the-loop process to clarify ambiguity, augment requirements, and ensure robust test-based validation. This process guarantees that tasks are both challenging and resolvable.
- Diversity: The benchmark spans multiple domains (consumer, B2B, developer tools) and languages (Python, Go, JavaScript, TypeScript), with each repository contributing a capped number of instances to prevent overfitting.
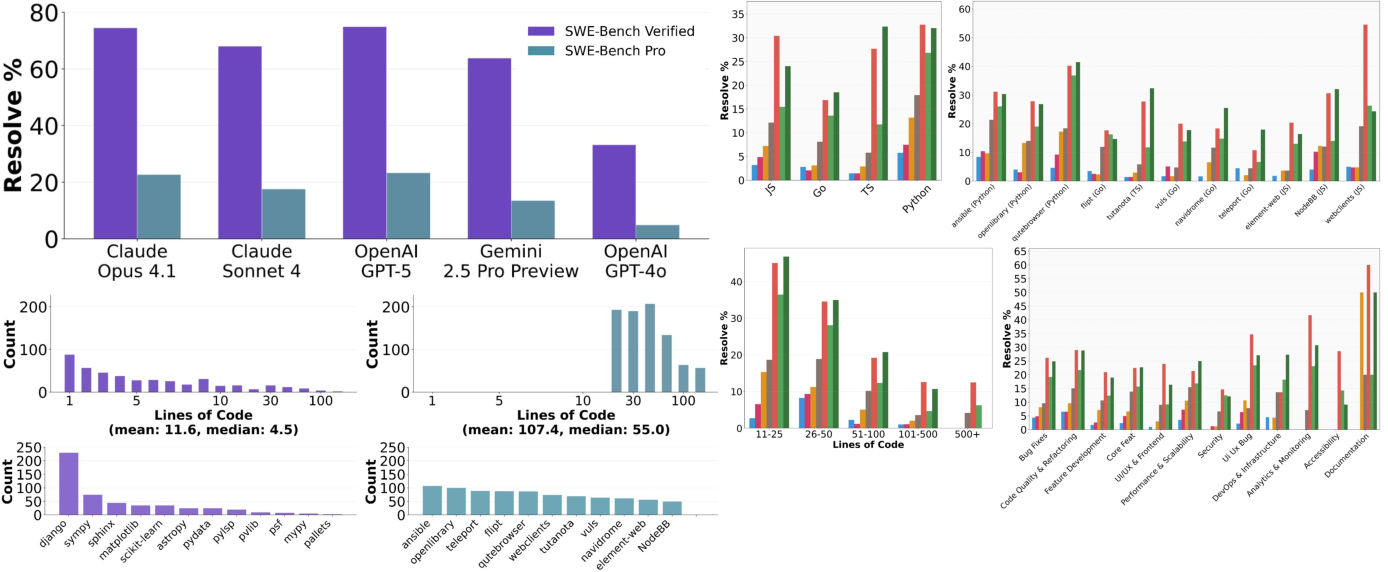
Figure 2: SWE-Bench Pro mimics real, challenging software engineering tasks with larger, multi-file changes. Frontier models score >70% on SWE-Bench Verified but less than 25% on SWE-Bench Pro.
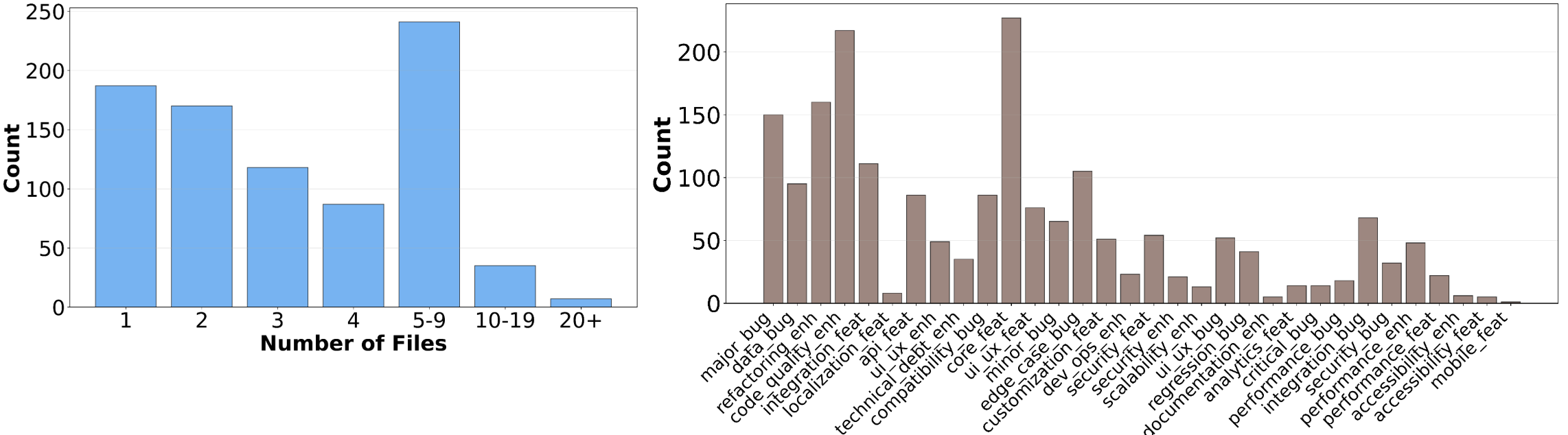
Figure 3: SWE-Bench Pro public set distributions show complex, long-horizon tasks across several files and diverse task types, including feature requests and bug fixes in optimization, security, UI/UX, and backend.
All models are evaluated using the SWE-Agent scaffold, which provides a unified agent-computer interface for code manipulation. The evaluation is performed in a setting with minimal ambiguity: agents receive the problem statement, requirements, and interface specification. Each task is validated using a suite of human-reviewed fail2pass and pass2pass tests in containerized, language-specific environments.
Key findings include:
Failure Mode Analysis
A detailed LLM-as-a-judge analysis, using GPT-5 as the judge, categorizes failure modes across models. The analysis reveals:
- Frontier Models: Opus 4.1 and GPT-5 primarily fail due to semantic errors (wrong solutions, 35.9–51.7%) and syntax errors (23.2–32.7%) in large, multi-file edits. These models demonstrate strong technical execution but struggle with complex reasoning and algorithmic correctness.
- Smaller Models: Models like Qwen-3 32B exhibit high tool error rates (42.0%) and frequent syntax/formatting issues, reflecting limitations in both code generation and tool integration.
- Context Management: Sonnet 4 and other models often fail due to context overflow and endless file reading, indicating that context window limitations and inefficient file navigation remain open challenges.
Limitations
SWE-Bench Pro, while a significant advance, has several limitations:
- Language Coverage: The benchmark underrepresents languages such as Java, C++, and Rust, limiting its generalizability across the full software engineering landscape.
- Task Scope: The focus is on issue resolution via code patches; broader engineering activities (e.g., system design, code review) are not captured.
- Test Suite Dependency: Reliance on test-based verification may not fully capture solution correctness, especially for tasks with multiple valid implementations.
- Ambiguity Reduction: Human augmentation may make tasks overly prescriptive, diverging from the inherent ambiguity of real-world engineering problems.
Implications and Future Directions
SWE-Bench Pro establishes a new, more realistic baseline for evaluating the capabilities of LLM-based software engineering agents. The substantial performance gap between SWE-Bench Verified and SWE-Bench Pro underscores the need for further advances in agent reasoning, context management, and tool integration. The benchmark's contamination resistance and task diversity make it a robust testbed for both academic and industrial research.
Future work should expand language and framework coverage, develop alternative evaluation metrics (e.g., code quality, maintainability), and introduce collaborative and multi-agent scenarios. There is also a need for evaluation protocols that go beyond test suites, incorporating human judgment and code review practices.
Conclusion
SWE-Bench Pro provides a rigorous, contamination-resistant, and industrially realistic benchmark for long-horizon software engineering tasks. The low Pass@1 rates of current frontier models highlight the significant gap between LLM agent capabilities and the demands of professional software development. SWE-Bench Pro will serve as a critical resource for measuring progress and guiding research toward the development of truly autonomous, high-performing software engineering agents.