- The paper introduces a hierarchical benchmark (Vision2Web) that assesses coding agents from static UI reproduction to full-stack web development using multimodal tasks.
- It employs a dual-verification approach combining GUI agent interrogation and VLM-based visual checks to ensure reproducible and detailed performance evaluation.
- Experimental results reveal performance decay and integration challenges, highlighting current limitations in multimodal planning, state management, and cross-module reasoning.
Vision2Web: A Hierarchical Benchmark for Visual Website Development with Agent Verification
Motivation and Benchmark Design
Prevailing benchmarks for autonomous coding agents assess software engineering competence predominantly through isolated, issue-driven tasks or text-only protocols that insufficiently capture the complexities of holistic web development. They fail to provide comprehensive, multimodal, and realistic scenarios required for true end-to-end measurement of agentic capabilities, especially in visually rich, interaction-heavy domains. Vision2Web addresses these deficiencies by introducing a hierarchically structured benchmark aimed at rigorously evaluating coding agents on static single-page UI reproduction, multi-page interactive frontend assembly, and full-stack website development based on both visual prototypes and textual specifications.
This hierarchy enables systematic disentanglement of agent skills—ranging from device-adaptive visual rendering, logical navigation, to long-horizon, stateful backend integration—by escalating task complexity and explicit multimodal requirements. Each task draws from real-world websites, ensuring diversity in functional coverage, layout, and domain characteristics, and adheres to a multi-stage curation and annotation pipeline that leverages both expert review and model-assisted design to maintain data quality and contamination resistance.
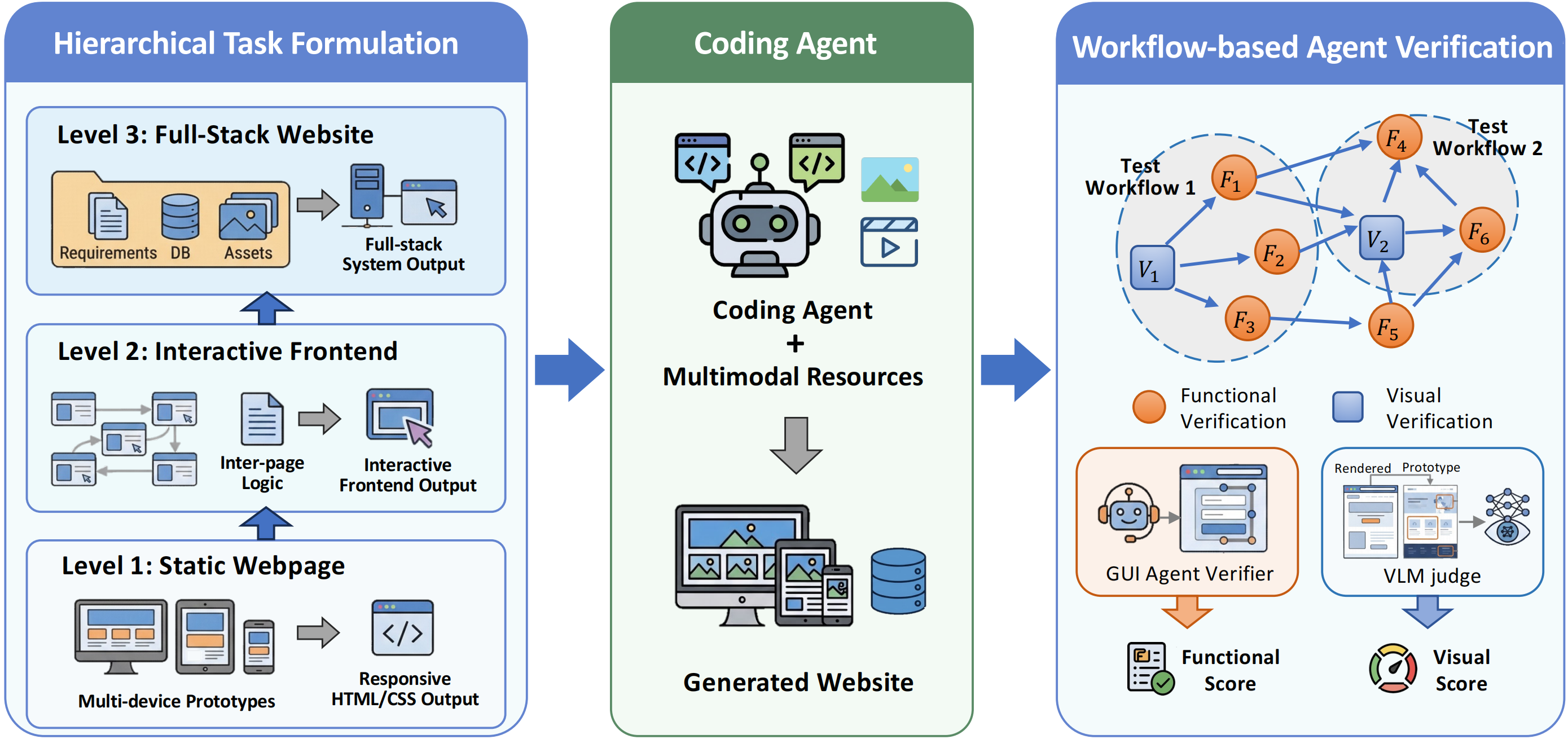
Figure 1: Vision2Web’s hierarchical organization, encompassing static webpages, interactive frontends, and full-stack website development tasks; evaluation is performed by workflow-based agent verification capturing both functional and visual adherence.
Dataset Taxonomy and Statistics
The Vision2Web dataset comprises 193 development tasks across 16 subcategories subsumed under four top-level website classes (Content, Transaction, SaaS Platforms, Public Services), accounting for 918 prototype images and 1255 rigorously crafted test cases. Each class presents unique challenges: Content and Transaction websites include intricate layouts and semi-structured interactions, SaaS platforms impose demanding cross-page state management, while Public Service tasks emphasize system reliability over extended usage.
Tasks are distributed by complexity: 100 static webpage, 66 interactive frontend, and 27 full-stack website cases. Prototype images for devices (desktop, tablet, mobile) illustrate the diversity introduced by adaptive layouts and responsive design.
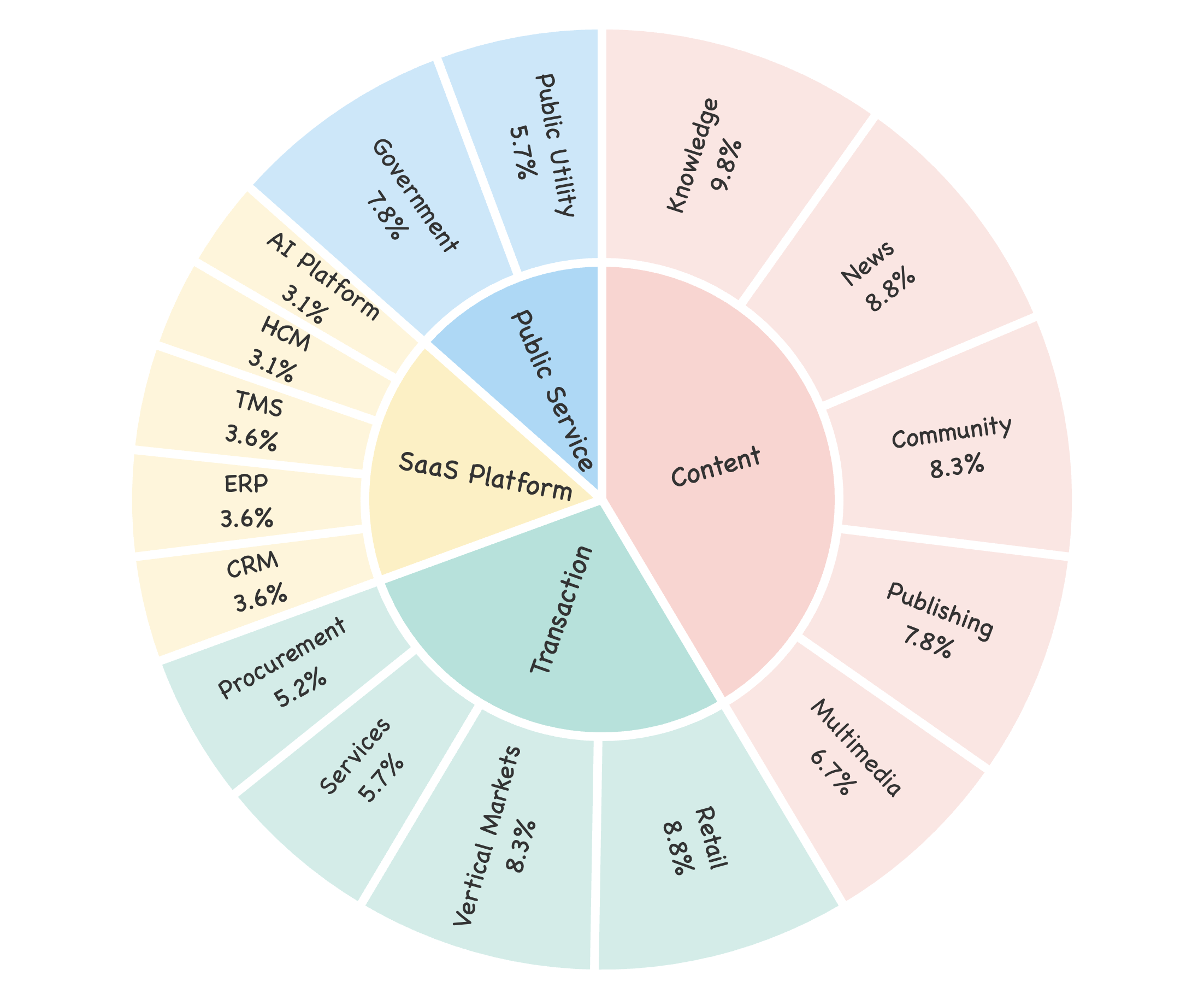
Figure 2: Task distribution across website categories and 16 subcategories, illustrating scenario coverage.
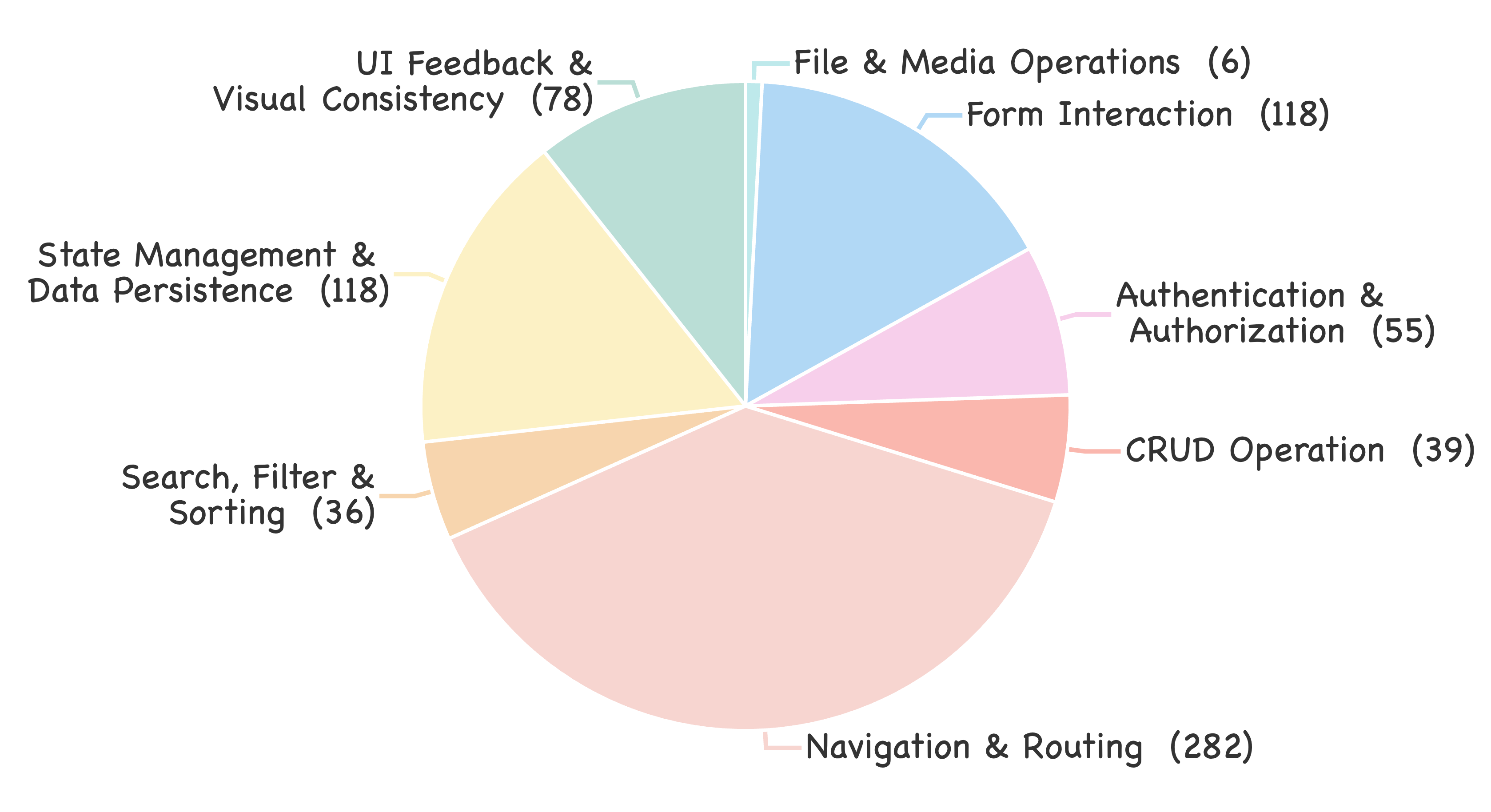
Figure 3: Test case density and diversity at the website level, confirming extensive scenario coverage for realistic agent evaluation.
Autonomous Agent Verification: Methodology
Evaluation combines two core modules: (1) a GUI agent verifier for functional interrogation and (2) a VLM-based judge assessing visual fidelity. End-to-end testing is formalized as a dependency-graph-based workflow, in which each node corresponds to a functional or visual verification sub-procedure and enforces well-defined objectives, interaction scripts, and validation criteria. This approach constrains agent execution, yields reproducible results, and supports implementation agnosticism—accommodating the diversity of plausible web system realizations.
Functional testing leverages a GUI agent instance (WebVoyager-based) executing structured workflows, interacting through click, type, and navigation primitives, and validating discrete application states. Visual verification—critical for UI-centric development—uses a fine-grained rubric for component-level comparison, operating at multiple device resolutions across prototype heights and blocks.
This dual-verification modal paradigm delivers high human agreement: 87.2% node-level accuracy for the GUI agent and a Spearman correlation of 0.66–0.80 for visual judgments, compared to an inter-annotator agreement of 0.78. The framework demonstrates practical reliability for large-scale, reproducible evaluation in multimodal development scenarios.
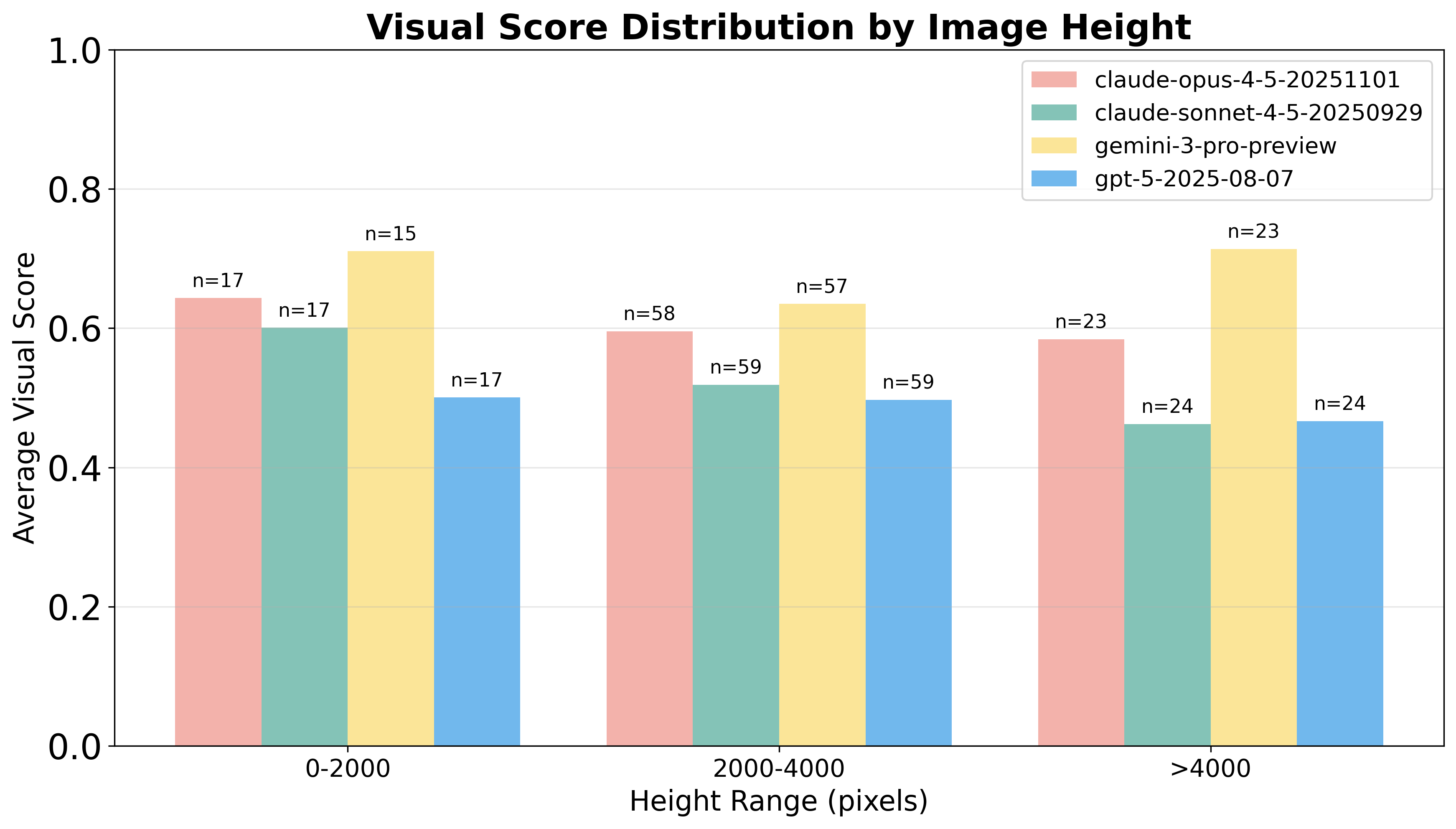
Figure 4: Distribution of visual scores as a function of prototype heights, emphasizing the challenge posed by visually dense, vertically extended UI layouts for leading models.
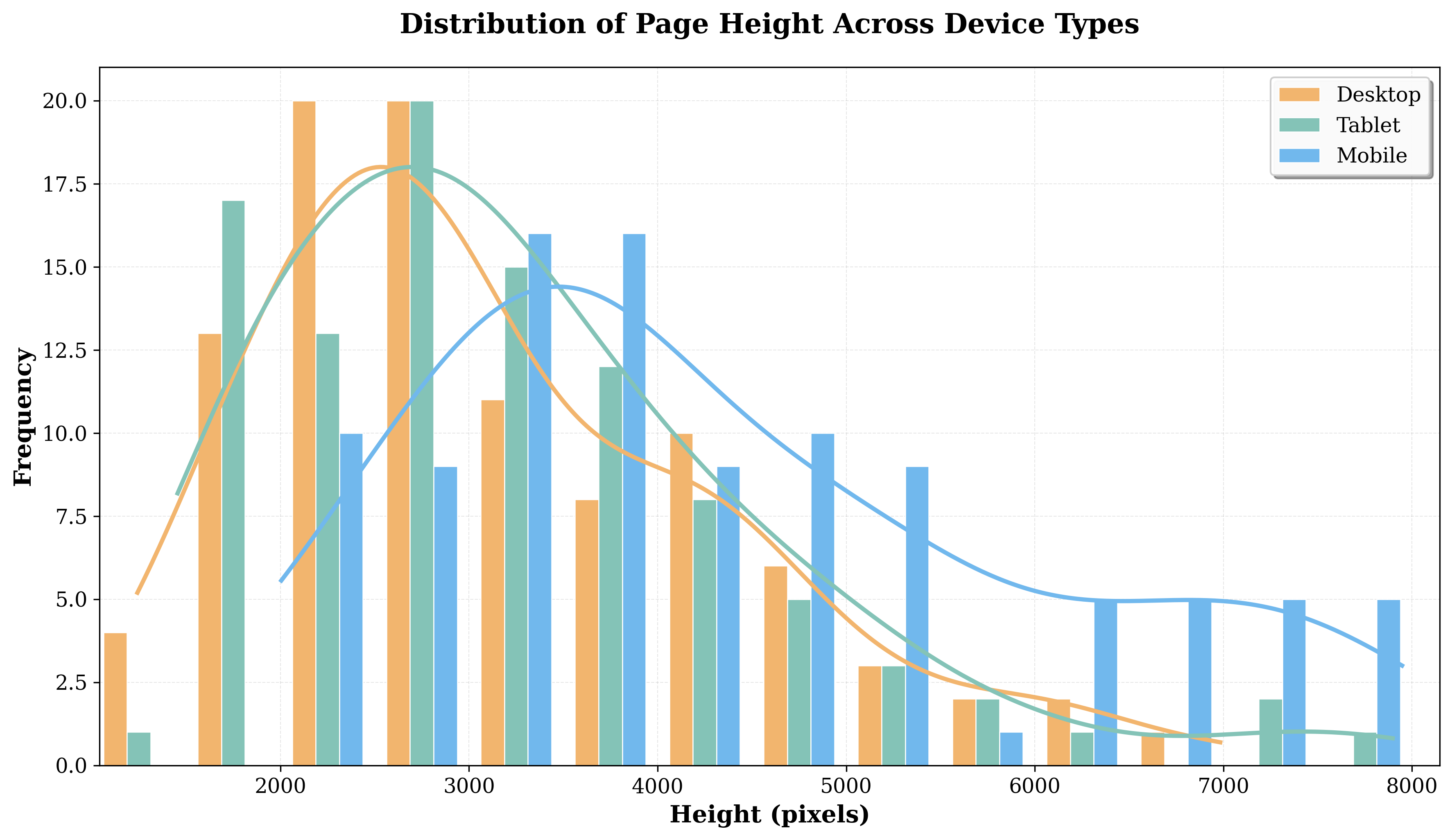
Figure 5: Prototype image size distribution across device types, highlighting the range of complexity encountered in responsive web tasks.
Experimental Results and Failure Analysis
Vision2Web enables unified, fine-grained comparison of eight leading large multimodal models integrated under two agentic programming frameworks (OpenHands, Claude Code). Empirical findings are summarized below:
- Monotonic performance decay across hierarchy: All models show substantial score decreases moving from static UIs to interactive frontends and full-stack websites. For example, Gemini-3-Pro-Preview achieves 63.3 average desktop VS on static tasks but plunges to 11.7 on full-stack tasks within OpenHands.
- Framework/model interactions: Claude-Opus-4.5 consistently outperforms, attaining peak VS/FS of 38.4/57.6 on the most complex settings. OpenHands generally yields higher device- and task-level results than Claude Code, except for Claude-specific deployments.
- Category-wise heterogeneity: Coding agents achieve best results on Public Service sites (median VS/FS ≈ 56.9/60.0) and manifest severe limitations on SaaS platforms, with both visual and functional alignment compromised in the presence of multi-module logic and persistent state.
Systematic analysis of failure modalities reveals three recurrent themes:
- Low-level visual misalignment: Incorrect positioning, color infidelity, and typography lapses dominate even on static webpages, escalating with asset ambiguity or occlusion.
- Cross-module integration breakdowns: Incomplete or inconsistent reproduction of navigation, interactivity, or component linkage are commonplace in frontend and full-stack contexts.
- Long-horizon planning failures: Inability to internalize and reason over extended requirements leads to missing, broken, or logically inconsistent backends, datastores, and authentication modules.
Implications and Research Directions
Vision2Web demonstrates that current multimodal agents lack the requisite compositional, cross-modal, and planning competence to succeed on realistic software development tasks. The gap between isolated UI generation and robust end-to-end full-stack system synthesis persists across architectures, model scales, and agentic frameworks. Performance variance by device form factor and visual complexity underscores deficits in spatial reasoning and prompt grounding. Consistent weaknesses in CRUD, file/media, and state management scenarios highlight unsolved problems in persistent state tracking, temporal dependency management, and tool integration.
These observations affirm the practical need for:
- End-to-end, workflow-grounded benchmarks for rigorous system-level evaluation.
- Improved architectures capable of hierarchical task decomposition, explicit state management, and multimodal grounding.
- Joint optimization of model-agent design for robust, deployment-grade coding agents in complex, real-world settings.
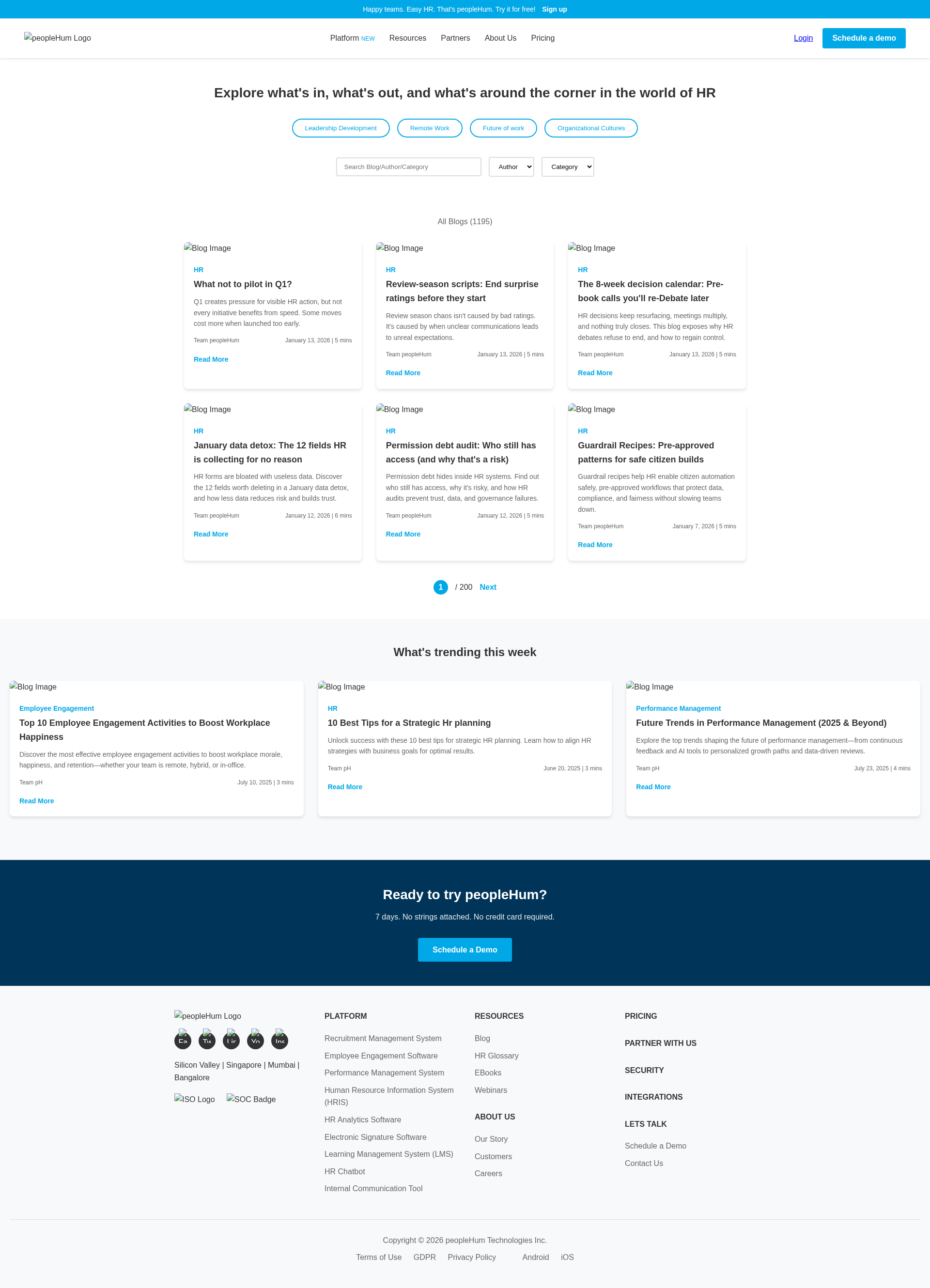
Figure 6: Example of a prototype web UI evaluated in the benchmark, illustrating task complexity and the challenge for agent code generation.
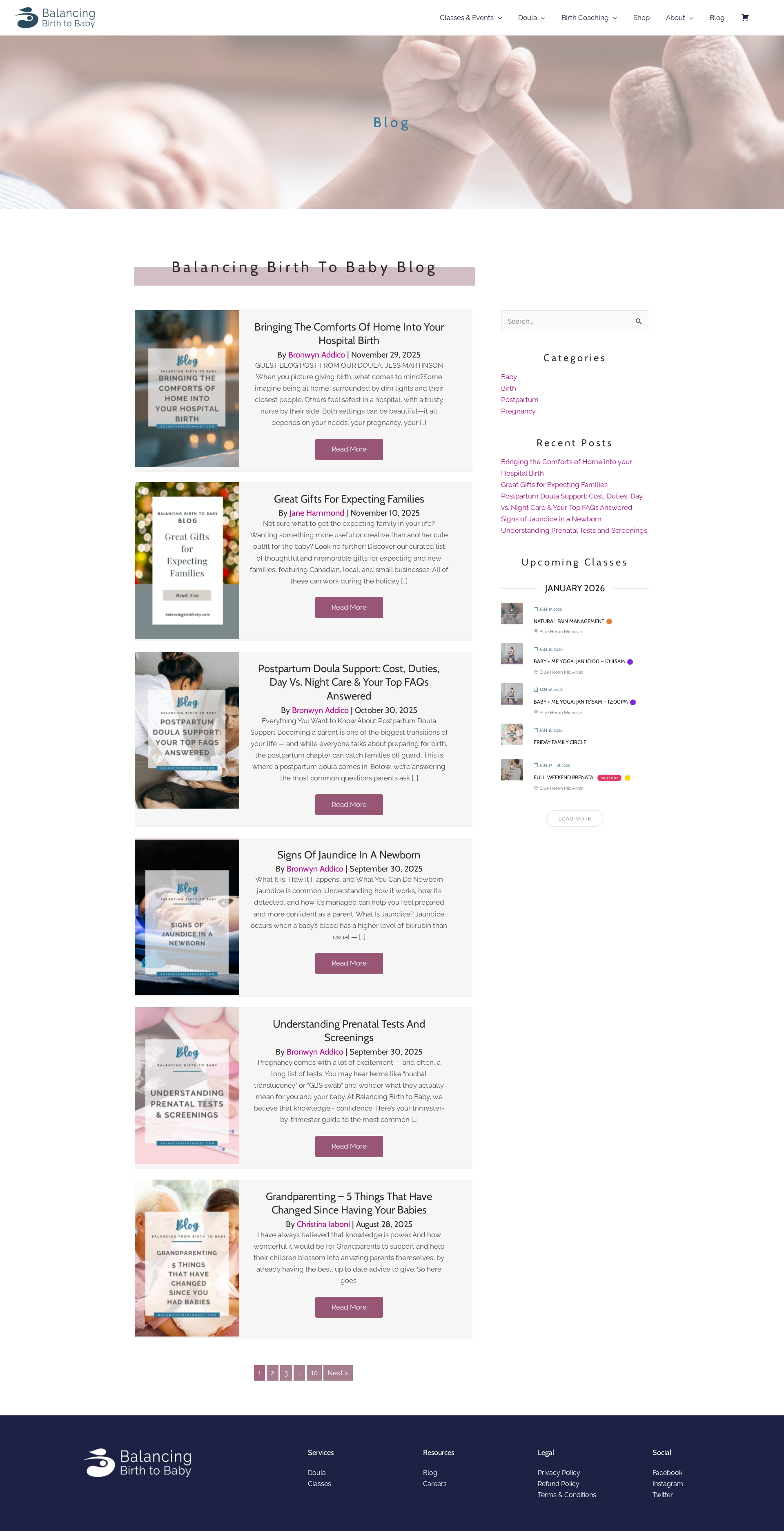
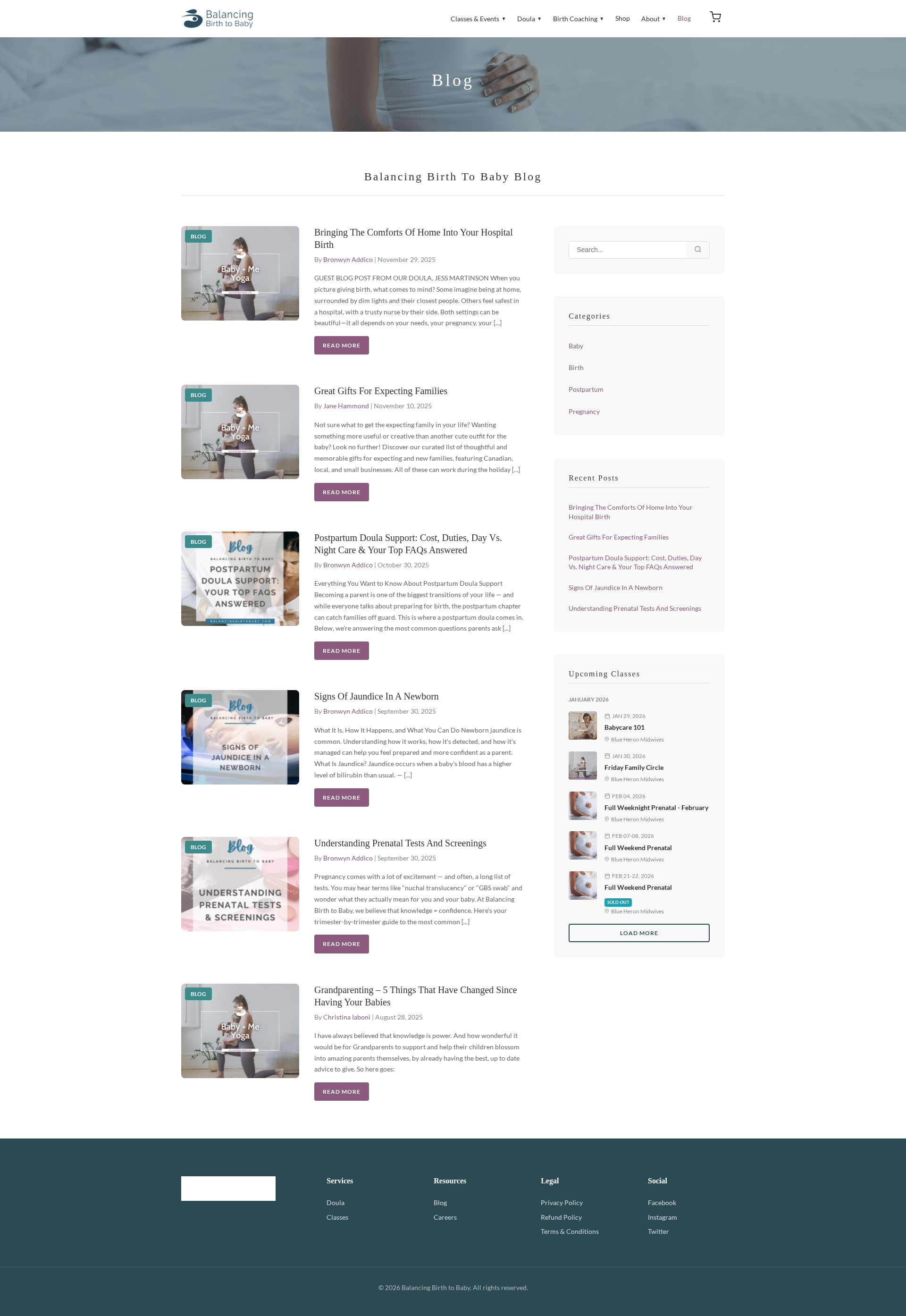
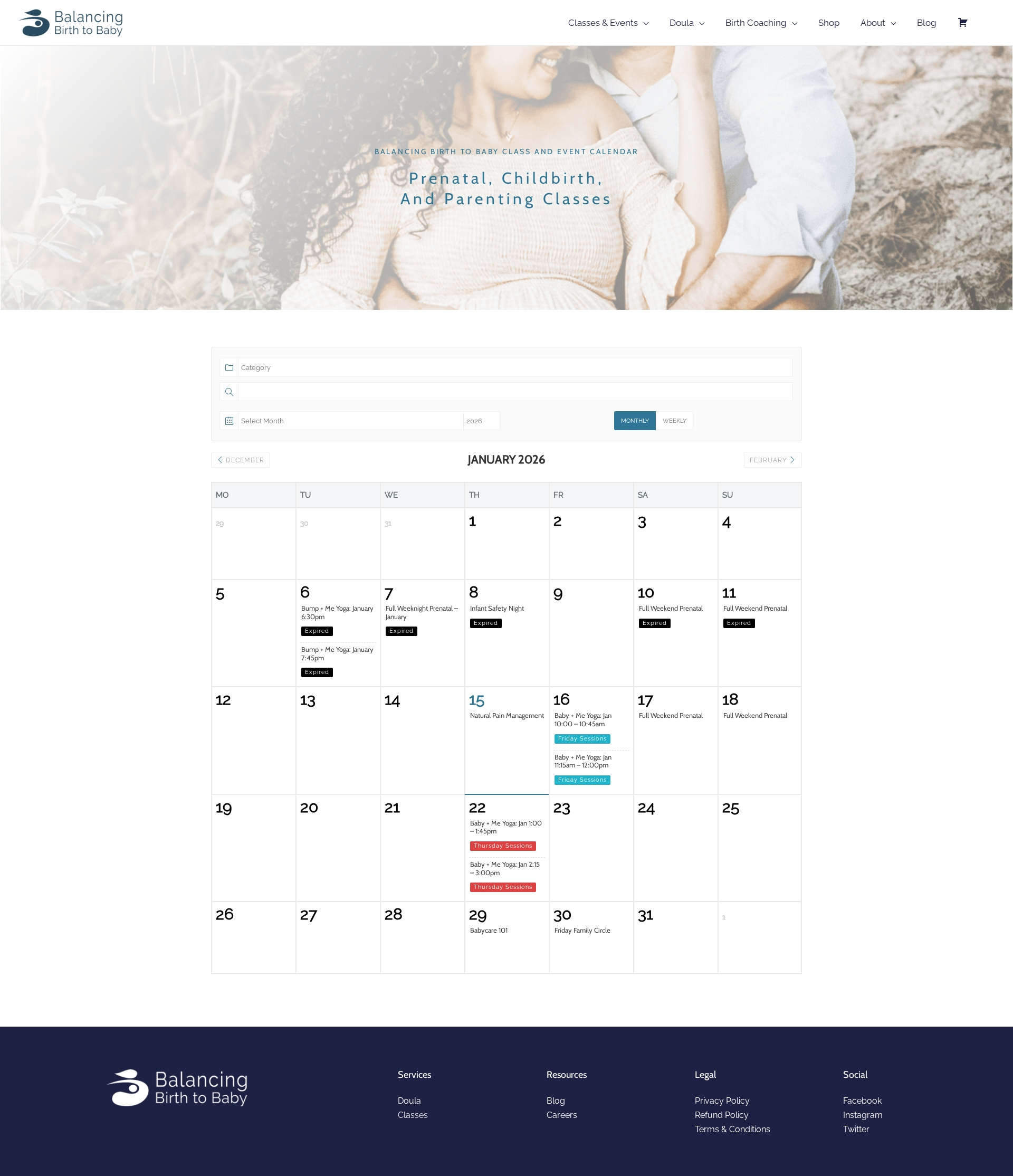
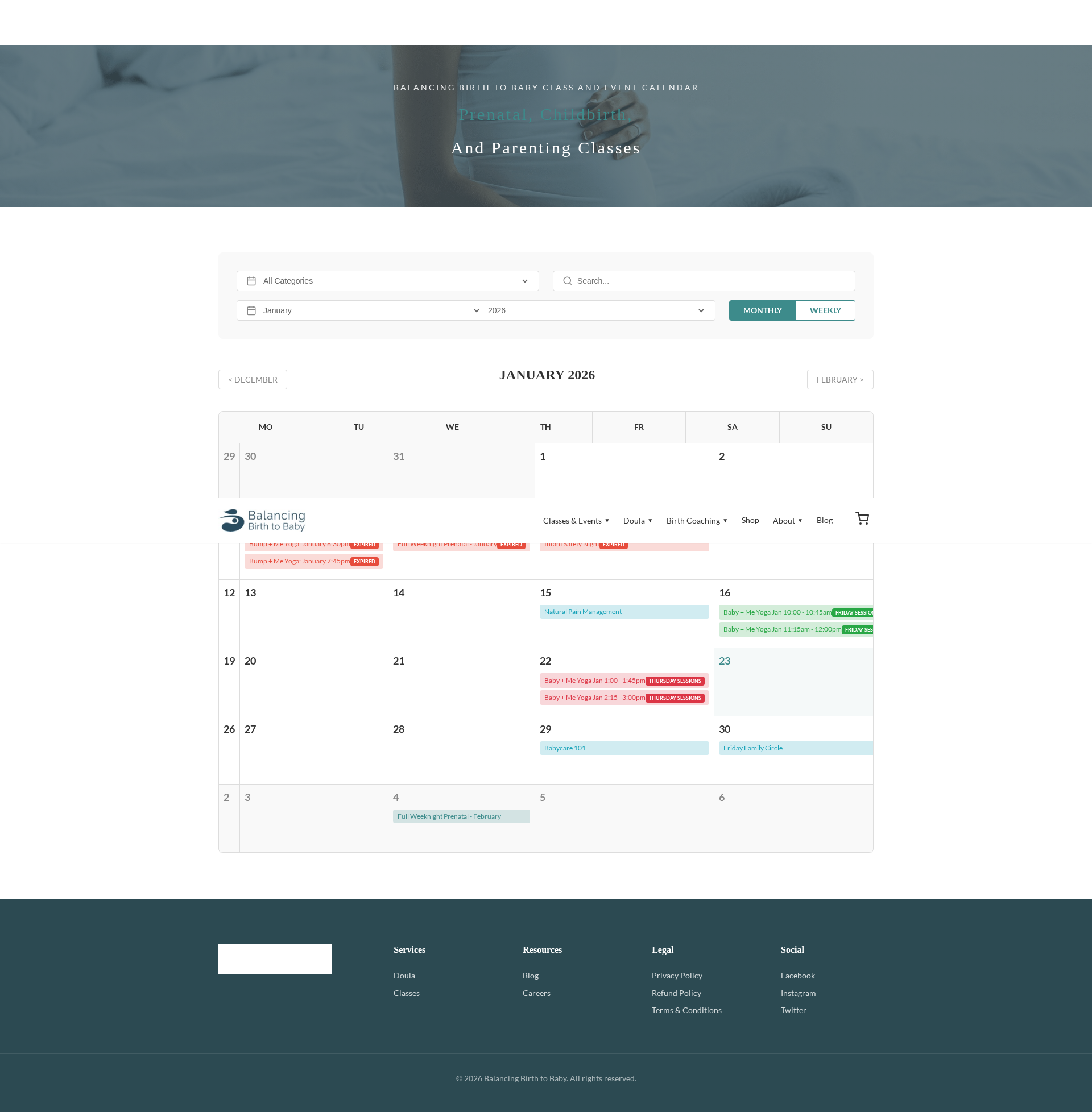
Figure 7: Example of a blog prototype image as part of frontend or full-stack scenario, emphasizing multimodal content alignment.

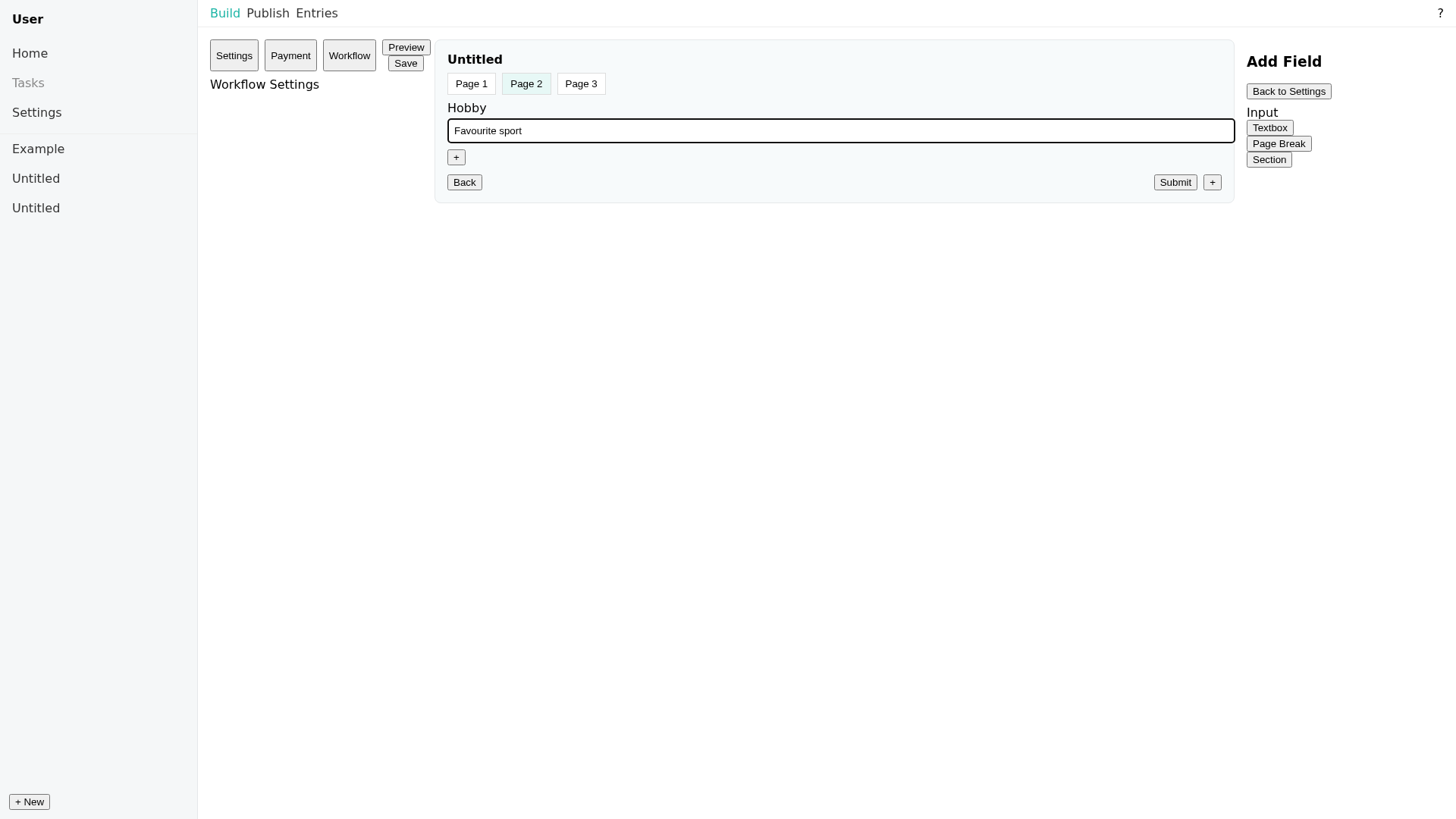
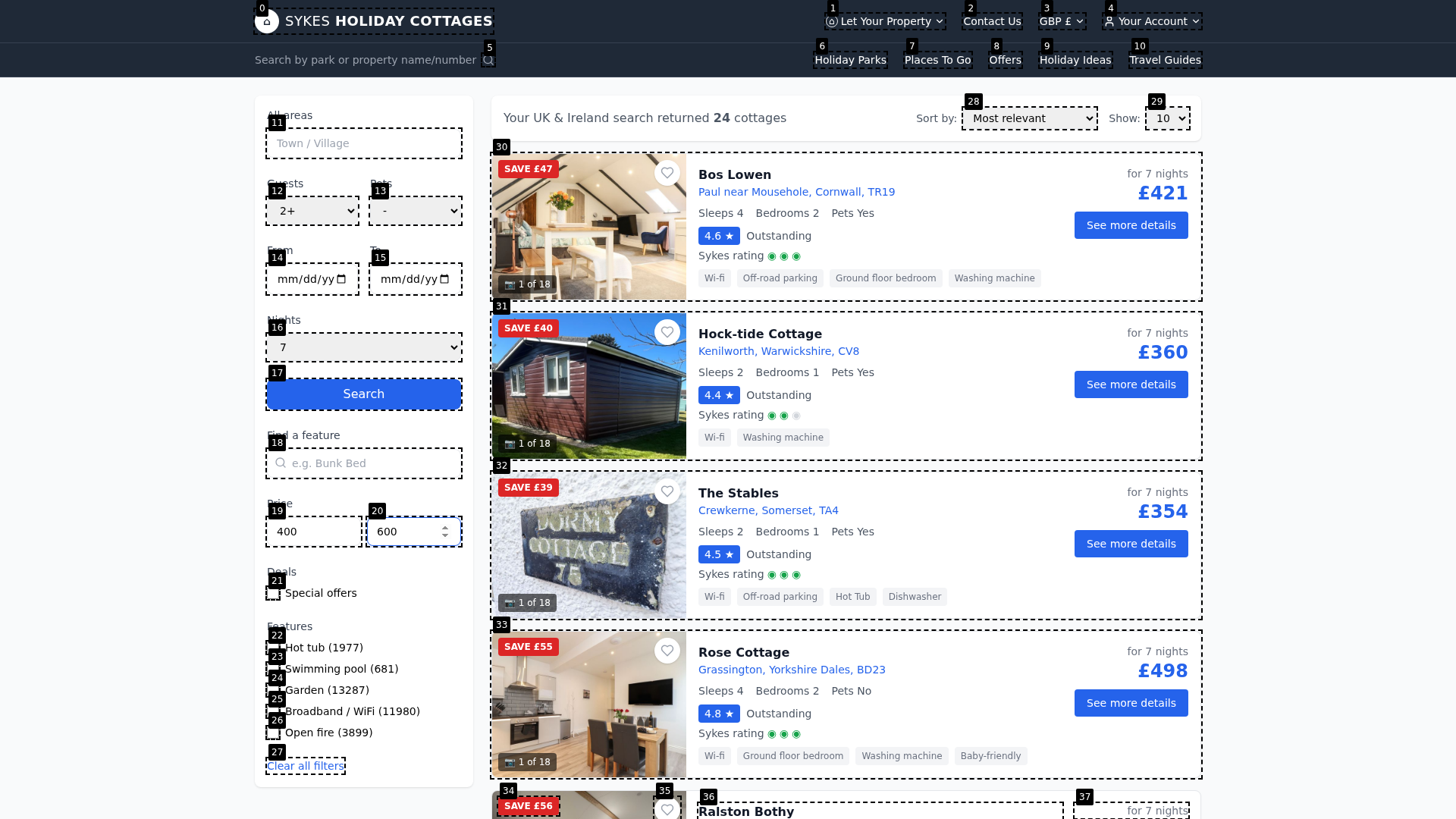
Figure 8: Example full-stack scenario (agendrix), representing the extensive cross-module and cross-page requirements present in Vision2Web.
Conclusion
Vision2Web establishes a comprehensive, hierarchically structured foundation for evaluating and advancing the state of multimodal coding agents for real-world, visually rich web development tasks. Its workflow-based agent verification paradigm, underpinned by large-scale, curated, and diversified tasks with reproducible evaluation, surfaces fundamental limitations of current architectures in hierarchical reasoning, visual fidelity, and system planning. This benchmark is poised to drive targeted model innovations, robust agent design, and reproducible evaluation in the next generation of agentic AI for software development (2603.26648).