- The paper presents SWE-Bench 5G, a benchmark that evaluates AI coding agents on real-world bugs in 5G core networks using dual testing strategies.
- It employs multi-turn iterative patch refinement across four LLMs, demonstrating that iterative feedback significantly boosts bug resolution rates.
- The study shows that injecting domain-specific protocol excerpts enhances patch accuracy for complex, specification-driven bugs while highlighting current AI limitations.
Motivation and Benchmark Scope
SWE-Bench 5G introduces a comprehensive benchmark for evaluating the efficacy of AI coding agents in resolving real-world bugs within 5G core network software. Unlike prior benchmarks that focus on general-purpose Python repositories, SWE-Bench 5G targets protocol-intensive codebases characterized by stringent correctness constraints dictated by 3GPP Technical Specifications and distributed Network Function (NF) architectures. These unique challenges—3GPP-driven logic, cross-NF signaling, and runtime dependency complexity—reflect pivotal gaps in existing agent benchmarks and position SWE-Bench 5G as a critical resource for advancing agentic code intelligence in telecommunications.
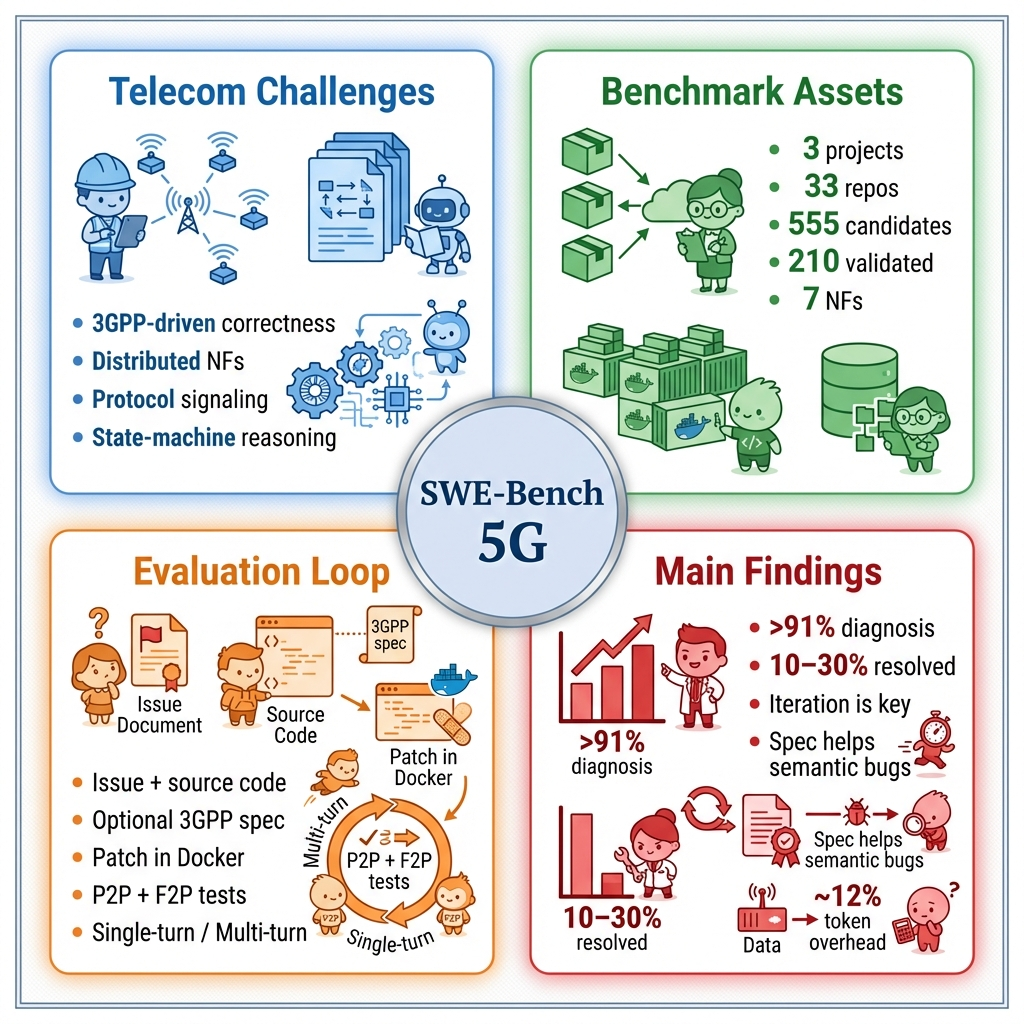
Figure 1: SWE-Bench 5G overview including telecom-specific challenges, benchmark assets, evaluation flow, and summary of empirical model performance.
Dataset Construction and Evaluation Pipeline
The benchmark aggregates 210 validated tasks spanning seven NFs extracted from three open-source 5G core projects: free5GC (Go), Open5GS (C), and Magma (Go/Python). Each task instance—defined by an input tuple (I,O,E)—pairs a bug description (potentially referencing 3GPP specifications) and source code with the expected patch and automated fail-to-pass/pass-to-pass test suites.
Due to the intricate runtime dependencies common to NF functions (e.g., SCTP sessions, MongoDB contexts, inter-NF signaling), the evaluation pipeline leverages two distinct test strategies:
- Direct Call Testing: Invokes the buggy function with crash-triggering inputs, capturing panic events via Go's defer/recover mechanism.
- Diff-Based Intent Testing: Validates patch correctness by inspecting code structure for explicit fix patterns, minimizing the requirement for complex runtime environments.
Instances undergo rigorous triage: Docker environments must pass all existing tests, fail the validated bug-triggering tests at the parent commit, and pass all after applying the ground-truth patch. This automated pipeline ensures reproducibility and strict validation criteria.
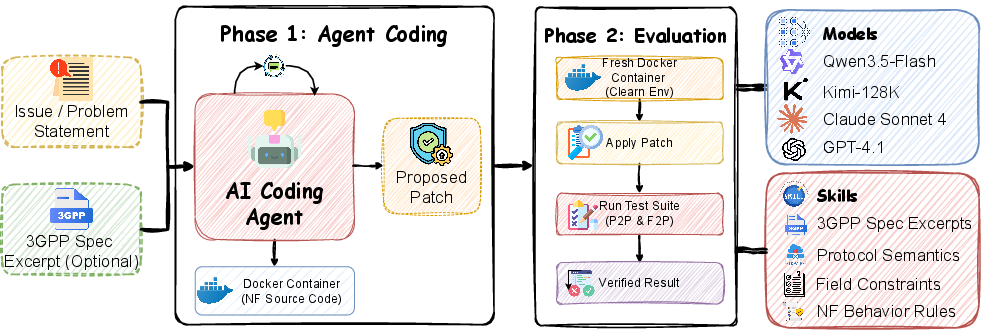
Figure 2: SWE-Bench 5G evaluation pipeline encompassing issue ingestion, optional specification injection, patch generation, and dual-strategy test validation.
Experimental Paradigms and Model Analysis
Agents are evaluated under single-turn (prompt-to-patch) and multi-turn (up to K=5 iterative patching with feedback) paradigms using four diverse LLMs: Qwen3.5-Flash, Kimi-128k, Claude Sonnet 4, and GPT-4.1. The multi-turn feedback loop is critical in facilitating iterative patch refinement, particularly for complex NF bugs.
Resolve rates across models show pronounced variance:
- Claude Sonnet 4 leads with 30.0%, followed by GPT-4.1 at 20.0%, while Qwen3.5-Flash and Kimi-128k plateau at 10.0%.
- Single-turn agents fail to resolve any instances despite high diagnostic accuracy, underscoring the necessity of agentic iteration.
- Concurrency-related and logic error bugs pose substantial challenges, with resolution rates consistently lower than those for nil pointer or missing validation bugs.
Patch application rates (i.e., valid code edits irrespective of test success) reveal significant friction between correct diagnosis and precise patch generation, attributed partly to type system strictness and exact-match requirements inherent to search/replace operations.
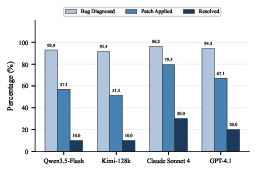
Figure 3: Multi-turn evaluation results (K=5) illustrate the diagnostic and patching funnel, revealing substantial gaps between comprehension and successful resolution.
The dominant failure mode across all models is incomplete fix, typically involving partial resolution of the bug while missing edge cases or ancillary dereference points. Format errors—incorrectly structured patch blocks—are especially problematic for weaker models and highlight potential improvements via fuzzy matching augmentation.
Specification-as-Skill Experimentation
SWE-Bench 5G evaluates the impact of injecting concise 3GPP specification excerpts (“skill documents”) into agent context on a subset of tasks. Specification injection follows a controlled A/B design, comparing resolve rates with and without appended protocol guidance.
Results confirm conditional utility:
- Specification injection yields notable gains (+16.7–25.0%) for spec-dependent bug classes (e.g., policy authorization, session management), demonstrating the effectiveness of domain-matched protocol knowledge.
- Generic bug classes (e.g., nil pointers, defensive checks) experience negligible improvement, with utility deltas consistently at zero.
- The context token overhead averages at 12%, illustrating the efficiency of curated specification summaries.
These findings reinforce prior skill injection literature: the benefit of domain knowledge is highly contingent on bug category, abstraction level, and actionable relevance.
Practical and Theoretical Implications
SWE-Bench 5G draws attention to core research challenges for AI code agents in telecom systems:
- Current LLMs exhibit pronounced limitations in reliably generating patches for distributed, protocol-driven codebases, particularly when precise logic and specification compliance are required.
- Multi-turn agentic paradigms materially outperform single-turn setups, suggesting that future agent designs should prioritize iterative refinement and environment interaction for complex engineering domains.
- Domain knowledge injection confers substantial benefit primarily for specification-driven bugs, motivating research into dynamic skill/context augmentation mechanisms based on bug semantics.
- The dual-strategy evaluation design effectively mitigates the runtime dependency bottleneck, but overall agent performance remains far below general-purpose benchmarks, evidencing the inadequacy of current LLMs for advanced telecom engineering workflows.
SWE-Bench 5G also exposes structural deficiencies in open-source telecom codebases (e.g., sparse test coverage, ambiguous commit histories), highlighting additional research opportunities around dataset curation, cross-NF coordination tasks, and agentic tool integration.
Future Directions
Opportunities for follow-up research and benchmark extension include:
- Inclusion of cross-NF coordination and distributed signaling bugs, expanding agent evaluation to inter-function and protocol-state reasoning.
- Integration of native file-editing and advanced tool capabilities to support sophisticated patch generation, beyond static diff-based paradigms.
- Systematic analysis of agent generalization in additional 5G/6G implementations, targeting broader architectural and language diversity.
Conclusion
SWE-Bench 5G provides a rigorous benchmark for AI coding agents in telecom network engineering applications, introducing domain-specific tasks, reproducible evaluation, and integrated specification injection protocols. Experimental results demonstrate that both agentic iteration and selective domain knowledge are critical for effective bug resolution in distributed, protocol-governed network functions. The benchmark surfaces persistent agentic limitations, informs future research priorities, and sets a foundation for advancing code intelligence in complex engineering domains.
(2604.26278)