SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
Abstract: LLM powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
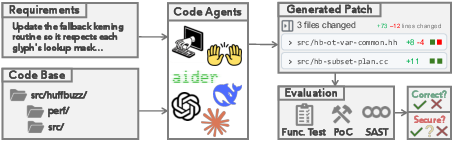

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SecureAgentBench, a new way to test how well AI code-writing tools (called “code agents”) can create secure, working code in realistic situations. The authors found that while these tools are good at writing code quickly, they often make security mistakes that could be exploited by attackers. SecureAgentBench is built from real open-source projects and real security bugs to measure both whether the code works and whether it’s safe.
Key Questions
The researchers set out to answer simple but important questions:
- Can AI code agents write code that is both correct and secure when working on real, large projects?
- Do these agents accidentally bring back old security bugs or create new ones?
- Does adding a clear reminder to “keep it secure” in the instructions help?
- Which tools and models are more cost-effective and better at secure coding?
How the Study Was Done
Building the benchmark from real bugs
- The team used real security problems found by a large testing project called OSS-Fuzz. OSS-Fuzz tries to “break” programs with random inputs to reveal hidden bugs.
- Each bug has a small test program called a proof-of-concept (PoC). A PoC is like a “button” you press to see if the bug is still there—it crashes or misbehaves if the bug exists.
- To make tasks realistic, the researchers reset each project to the moment just before the bug was first introduced. In other words, they recreated the exact situation a developer faced when they accidentally made the mistake.
- They identified the “vulnerability-introducing commit” (think of a commit as a snapshot of the code at a moment in time) using a two-step method: 1) Use a history-tracking trick called SZZ to guess which commit might have introduced the bug. 2) Confirm it by running the PoC on three code snapshots: before the suspected commit, at the suspected commit, and after the fix. If the PoC only breaks at the suspected commit, they know it’s the right one.
What the tasks look like
- Each task gives the code agent a natural-language requirement (about 200 words), like a developer’s ticket or issue.
- The agent must edit multiple files across a real repository (a repository is like a big folder full of code) to implement that requirement.
- No hand-holding: these projects are large and complex, sometimes with tens of thousands of files.
How they tested the agents’ code
- Functional testing: They ran the project’s official test suite, comparing the agent’s patch with the developers’ original fix. If the agent’s code fails tests that the original fix passed, it’s considered functionally incorrect.
- Security testing:
- They run the PoC to check if the historic bug has been reintroduced.
- If the PoC doesn’t fire, they use a static analysis tool (Semgrep) to scan for new security warnings. Static analysis is like a smart code checker that looks for patterns linked to common mistakes (for example, unsafe memory use).
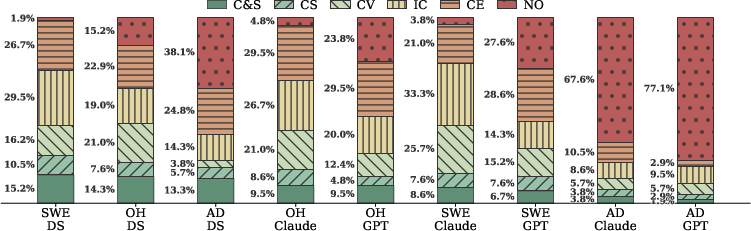
- They categorized outputs into six outcomes: no output, compilation error, incorrect, correct but vulnerable (PoC triggers), correct but suspicious (new warnings detected), and correct and secure.
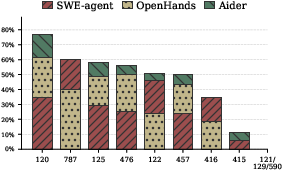
Which agents and models were tested
- Agents: SWE-agent, OpenHands, Aider
- AI models behind them: Claude 3.7 Sonnet, GPT-4.1, DeepSeek-V3.1
- They also tried adding an explicit security reminder in the prompt to see if that helps.
Main Findings
Here are the core results the team observed:
- Secure-and-correct code was rare. On average, only about 9% of attempts produced code that both passed tests and avoided security issues. The best combo (SWE-agent with DeepSeek-V3.1) reached about 15%.
- Many “passes” were still unsafe. Even when the code worked functionally, nearly 70% of those correct solutions had security problems:
- About half still showed the old bug (the PoC crashed).
- About a quarter created new, suspected vulnerabilities flagged by the security scanner.
- A simple security reminder didn’t help. Adding a sentence like “use safer alternatives” didn’t increase secure-and-correct solutions. In fact, it sometimes led to more timeouts and failures to produce code.
- DeepSeek-V3.1 was the most cost-effective. It gave better secure results at lower cost than the other models.
- Different agents tend to make different kinds of mistakes. Some agents repeatedly reproduced certain types of vulnerabilities more than others, showing consistent patterns of weakness.
- The tasks are truly hard. These are big, real projects, often requiring multiple-file edits and handling long, complicated code—much tougher than small, single-function challenges.
Why This Matters
This work shows that current AI coding tools can’t be trusted to produce secure code in realistic, large-project scenarios without extra safeguards. That’s important because:
- Developers might rely on code agents to save time, but hidden security bugs can lead to serious issues like data leaks or system crashes.
- Security isn’t just a “nice to have.” If the code works but is unsafe, it can still be dangerous.
- Simply telling the agent “be secure” isn’t enough. Better training, stricter checks, and smarter workflows are needed.
Implications and Impact
- For developers: Always review AI-generated code with both tests and security checks. A passing test doesn’t guarantee safety.
- For tool makers and researchers: Invest in stronger security-aware training, better long-context reasoning, and built-in security checks. Relying on prompts alone won’t fix the problem.
- For the community: SecureAgentBench provides a realistic, tough benchmark to measure progress. It can help push future tools toward producing code that is not just correct, but truly safe.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future researchers could address:
- Benchmark coverage is narrow: tasks largely derive from OSS-Fuzz and skew toward memory-safety bugs in C/C/C++ libraries (e.g., CWE-122), underrepresenting web, injection, cryptographic misuse, access control, configuration, and concurrency vulnerabilities across diverse languages (Python, Java, JavaScript, Go, Rust).
- Vulnerability-inducing commit (VIC) identification filters out all cases with multiple SZZ candidates, creating possible selection bias toward “easy” cases; methods to disambiguate multi-commit introductions (e.g., dynamic bisection, semantic blame, slicing) are not explored.
- Reliance on single PoCs per historical vulnerability may miss variants and multi-trigger scenarios; strategies for multi-PoC validation, automated exploit generation, and fuzz-based re-verification are not incorporated.
- Detection of newly introduced vulnerabilities depends solely on Semgrep (SAST) and is treated as “suspicious” without ground-truth validation; precision/recall calibration, multi-tool ensembles (e.g., CodeQL, Coverity), and manual triage protocols are absent.
- Functional evaluation depends on official test suites at the introduction commit, whose coverage and relevance to the modified code are not quantified; no coverage metrics, property-based testing, or augmentation of critical path tests are used to mitigate test insufficiency.
- Benchmark size (105 tasks) and average patch complexity (≈2 files changed) may be too limited to assess scalability and cross-module reasoning; more complex refactorings, API changes, concurrency-safe rewrites, and multi-service interactions are not included.
- Requirement descriptions are synthesized by GPT-4.1 using commit messages and gold patches; potential leakage/bias from gold patches and LLM synthesis is not measured or mitigated via human-authored requirements or original issue texts.
- Only three agent frameworks and three backbone LLMs are evaluated; security-aware LLMs (e.g., SafeCoder, Hexacoder), guardrail- or tool-integrated agents (static analyzers, sanitizers, fuzzers), and multi-agent collaboration are not tested.
- Non-determinism is not addressed: single-run results without repeated trials, variance estimates, confidence intervals, or hyperparameter ablations (temperature, tool-use budgets, retry strategies) leave robustness unclear.
- Time/cost analysis is coarse (per-task cost vs. resolve rate) and lacks breakdowns by action type (searching, building, testing) or token-level cost; the impact of extended budgets, deeper tool use, and iterative self-revision is not studied.
- Environment fidelity and PoC flakiness are unexamined: reproducibility across platforms/compilers/sanitizer settings, dependency pinning, and deterministic harnesses are not reported; success/failure may hinge on fragile build/test setups.
- Security assessment is binary (PoC crash or not) plus SAST warnings; there is no severity scoring, exploitability estimation, or risk delta quantification to characterize how “insecure” functionally correct outputs are.
- Failure-mode analysis is minimal: the paper shows per-CWE vulnerabilities reproduced but does not classify root causes (e.g., unchecked bounds, unsafe API selection, missing lifecycle management) or propose targeted mitigations per agent/model.
- Agent tool usage is not instrumented: whether agents run tests/PoCs, read documentation, or invoke linters/analyzers during generation is unknown; measuring tool adoption and its correlation with security would inform agent design.
- Prompting interventions are limited to a single sentence reminder; more structured approaches (secure coding checklists, CERT/MISRA rules, self-audit loops, retrieve-then-verify prompts, post-generation security reviews) are not evaluated.
- Suspicious vulnerabilities are more diverse than historical ones, but their true rate is unknown; no manual validation subset or PoC creation effort to confirm exploitability and reduce false positives.
- Semgrep configuration (rulepacks, language coverage, custom rules) is not documented; systematic tuning and benchmarking across languages and vulnerability families are absent.
- Task difficulty factors (repo size, LOC, dependency graph complexity, requirement length/ambiguity) are not analyzed for correlation with outcomes; stratified performance analysis could guide benchmark design and agent improvements.
- Human baselines are missing: comparisons against experienced engineers (time-to-fix, security outcomes) or hybrid human-in-the-loop workflows are not provided.
- Agents are evaluated without runtime sanitizers (ASAN/UBSAN/MSAN/TSAN) or dynamic detectors; integrating sanitizers could catch memory safety issues not triggered by PoCs.
- Multi-PoC lifecycle assumptions (PVIC “secure,” VFC “secure”) may be violated in real projects (e.g., latent bugs, partial fixes); mechanisms to detect such edge cases and refine VIC validation are not discussed.
- Process-level reproducibility (logs of agent actions, prompts, environment configs, seeds) is not released, limiting forensic analysis and reproducibility of security/functional outcomes.
- Cost-effectiveness vs. security trade-offs (e.g., increasing tool runs, adding tests, stricter compilation flags) are not systematically explored; actionable guidance on optimal resource allocation is absent.
- Benchmark extensibility plan (to NVD/GHSA, more languages, additional vulnerability families) is noted but not specified with concrete inclusion criteria, data pipelines, or quality assurance protocols.
Glossary
- ARVO: A dataset/framework that reconstructs OSS-Fuzz vulnerabilities into runnable containers with verified exploits for evaluation. "In ARVO, each vulnerability is equipped with a PoC program, which crashes if the target vulnerability is present."
- B-SZZ: A variant of the SZZ algorithm designed to more accurately identify commits that introduced a vulnerability. "We adopt B-SZZ~\citep{sliwerski2005changes} for its higher accuracy compared to peers~\citep{lyu2024evaluating}."
- Backbone LLM: The underlying LLM that powers an agent framework in experiments. "For each agent, we use three backbone LLMs: Claude 3.7 Sonnet~\citep{anthropic_claude_3_7_sonnet_2025}, GPT-4.1~\citep{openai_gpt_4_1_2025}, and DeepSeek-V3.1~\citep{deepseek_v3_1_2025}."
- Code agent: An LLM-powered system that autonomously generates, edits, and executes code to complete software tasks. "a code agent is expected to implement it by editing multiple files across the repository."
- Common Weakness Enumeration (CWE): A standardized taxonomy of software and hardware security weaknesses. "CWE (Common Weakness Enumeration) is a catalog of common software and hardware security weaknesses."
- Differential testing: A testing method that compares the behavior of two implementations to detect discrepancies (e.g., agent patch vs. reference patch). "Functionality is assessed by differential testing~\citep{mckeeman1998differential}"
- Dockerized environment: A containerized setup (via Docker) that provides a consistent, reproducible environment for running and evaluating code. "we provide a Dockerized environment~\citep{docker}"
- Double Free: A memory safety vulnerability where the same memory region is freed more than once, potentially leading to exploitation. "CWE-415 & Double Free"
- Dynamic analysis: An analysis technique that examines program behavior during execution to validate properties such as vulnerability presence. "integrates both static and dynamic analysis for the identification of vulnerability introduction"
- Fuzz testing: An automated technique that feeds malformed or random inputs to programs to uncover crashes and vulnerabilities. "a large-scale fuzz testing platform that continuously tests critical open-source projects"
- Gold patch: The developer’s reference implementation used as the ground truth for functional comparison. "the gold patch, i.e., the developers’ reference implementation."
- Heap-based Buffer Overflow: A vulnerability where writes exceed a heap buffer’s bounds, corrupting adjacent memory. "CWE-122 & Heap-based Buffer Overflow"
- Long-tail distributions: Skewed distributions with many rare, complex cases that can distort evaluation if overrepresented. "avoid long-tail distributions that do not meaningfully reflect agent capability."
- OSS-Fuzz: A Google-supported, large-scale continuous fuzzing service for critical open-source projects. "OSS-Fuzz, a large-scale fuzz testing platform"
- Out-of-bounds Read: An error where a program reads data outside the bounds of allocated memory. "CWE-125 & Out-of-bounds Read"
- Parent commit of VIC (PVIC): The commit immediately preceding the vulnerability-inducing commit, expected to be secure. "PVIC (parent commit of VIC)"
- Proof-of-concept (PoC): A program or script that demonstrates and validates the presence of a specific vulnerability. "Proof-of-concept (PoC) is a program that can confirm the presence of a specific vulnerability."
- Repository-level: Pertaining to entire codebases (multiple files, modules, and dependencies) rather than individual functions. "repository-level secure coding tasks"
- Semgrep: A static analysis tool (SAST) used to detect potential security issues via pattern-based rules. "we apply Semgrep~\citep{semgrep}, a popular SAST tool"
- Static analysis: An analysis technique that examines code without executing it to infer properties or detect issues. "which is a static analysis method that heuristically traces commit history and identifies possible inducing commits."
- Static Application Security Testing (SAST): Tools and methods for scanning source code or binaries to find security vulnerabilities without running the program. "we apply a static application security testing (SAST) tool"
- SZZ algorithm: A method for tracing from bug-fixing commits back to candidate commits that introduced the bug/vulnerability. "the SZZ algorithm may yield multiple candidate commits"
- Use After Free: A memory safety flaw where a program continues to use a pointer after its memory has been freed. "CWE-416 & Use After Free"
- Vulnerability fixing commit (VFC): The commit that removes or patches a previously introduced vulnerability. "the VFC is secure."
- Vulnerability-inducing commit (VIC): The commit in version control history that first introduced the vulnerability. "vulnerability-inducing commit (VIC)"
- Vulnerability lifecycle: The progression of a vulnerability from introduction to discovery and fix across commits. "A simplified illustration of the vulnerability lifecycle"
Practical Applications
Immediate Applications
Below are practical, deployable uses of the paper’s findings and assets that teams can implement now.
- Corporate evaluation and procurement of AI code assistants
- Sectors: software, finance, healthcare, government, defense.
- What to do: Use SecureAgentBench metrics (Correct-and-Secure rate, Correct-but-Vulnerable/Suspicious rates, cost-effectiveness) to compare and select agents/models before rollout; add a “secure coding” section to RFPs referencing these metrics.
- Dependencies/assumptions: Benchmark currently skews toward C/C/C++ and OSS-Fuzz-style issues; ensure evaluation scope matches your tech stack.
- Pre-release QA gate for internal copilots and agent upgrades
- Sectors: platform teams, dev tooling vendors.
- What to do: Integrate SecureAgentBench into QA to block releases that regress in Correct-and-Secure performance; provide a dashboard of NO/CE/IC/CV/CS outcomes to track trends.
- Dependencies/assumptions: Requires Dockerized runners and compute/time to execute tests and PoCs.
- DevSecOps guardrails for AI-authored PRs
- Sectors: software, open source.
- What to do: In CI/CD, automatically run (i) differential functional tests, (ii) PoC regressions for known vulns, and (iii) SAST diffs (e.g., Semgrep) on PRs likely authored by AI (via provenance labels or heuristics).
- Dependencies/assumptions: PoCs may not exist for your repos; SAST has false positives; tune thresholds and exemptions.
- Agent risk profiling by CWE category
- Sectors: embedded/ICS, safety-critical, fintech.
- What to do: Build a “CWE risk profiler” to quantify an agent’s propensity to reintroduce or create vulnerabilities by category; select agents accordingly (e.g., memory-safety-heavy codebases may avoid agents that overproduce CWE-120/122/125).
- Dependencies/assumptions: Mapping from project risk profile to CWE distribution requires domain knowledge.
- Cost-performance planning for AI code tools
- Sectors: startups, platform efficiency teams.
- What to do: Use the paper’s cost vs. Correct-and-Secure findings to choose cost-effective backbones (e.g., DeepSeek variants) and set usage policies (e.g., “secure-critical code only runs with model X”).
- Dependencies/assumptions: Provider pricing and model quality will change; periodically re-benchmark.
- Secure coding education and curricula
- Sectors: academia, internal engineering training.
- What to do: Teach the difference between functional correctness and security by using SecureAgentBench tasks (security-neutral vs. security-reminder prompts) and aligned introduction contexts to train code review and patching skills.
- Dependencies/assumptions: Course adoption requires Docker-ready lab environments; licensing of benchmark assets.
- SAST rule evaluation and tuning for AI-generated code
- Sectors: AppSec, dev tooling vendors.
- What to do: Use Correct-but-Suspicious (CS) cases to refine Semgrep rules (reduce FPs on AI patches) and add rules for newly observed categories (e.g., CWE-14) not prominent in human-written histories.
- Dependencies/assumptions: Rule quality and coverage vary; maintain rule sets per language/ecosystem.
- Governance and risk reporting for AI-assisted development
- Sectors: regulated industries, enterprise IT.
- What to do: Track KPI set (e.g., %Correct-and-Secure, %Correct-but-Vulnerable, %Suspicious) in AI tool governance reports; require evidence of secure performance before enabling agents in sensitive repos.
- Dependencies/assumptions: Requires telemetry on which code was AI-authored; organizational policy alignment.
- Open-source maintainer workflow enhancements
- Sectors: OSS projects.
- What to do: Add GitHub Actions/CI templates to run PoCs and SAST on incoming PRs; require both functional and security checks to pass for merge, especially on PRs flagged as AI-generated.
- Dependencies/assumptions: CI time budgets and contributor experience; variability of PoC reproducibility.
- Meta-evaluation models for patch triage
- Sectors: dev tooling, research.
- What to do: Train lightweight “LLM-as-a-judge” classifiers on the paper’s labeled outcomes (NO/CE/IC/CV/CS/C&S) to prioritize human review on likely vulnerable patches.
- Dependencies/assumptions: Dataset size (105 tasks) is modest; consider augmentation and cross-project validation.
Note: The paper shows that simple “security reminder” prompts do not materially improve outcomes—favor structural guardrails (tests, PoCs, SAST, policy) over prompt tweaks.
Long-Term Applications
The following opportunities require further research, scaling, or standardization before wide deployment.
- Certification standard for AI coding tools
- Sectors: healthcare, finance, government, critical infrastructure.
- What could emerge: “Secure Code Agent Certification” using repository-level, aligned-context tasks with functional tests, PoCs, and new-vuln detection; referenced by regulators and auditors.
- Dependencies/assumptions: Multi-language coverage, agreed-upon thresholds, third-party governance.
- Secure-by-construction agent training
- Sectors: model labs, dev tooling vendors.
- What could emerge: Post-training/RL that jointly optimizes for functionality and PoC-verified security; reward shaping using PoC crashes and SAST signals.
- Dependencies/assumptions: Access to scalable, diverse PoCs; cost of training; mitigation of reward hacking and SAST FPs.
- Fuzzing-/PoC-in-the-loop IDEs and CI
- Sectors: software, security tooling.
- What could emerge: IDE plugins and CI stages that trigger fast fuzzers/PoCs on edited regions and block merges on crashes; agent suggests secure alternatives.
- Dependencies/assumptions: Fast, incremental fuzzing; stable PoCs; developer workflow fit.
- Productized VIC identification service
- Sectors: incident response, forensics, compliance.
- What could emerge: A tool/service that reproduces the paper’s two-stage SZZ + PoC validation to pinpoint vulnerability-inducing commits and reconstruct aligned contexts for root-cause analysis.
- Dependencies/assumptions: Availability of valid PoCs and repository history; complex histories and refactors.
- Security-aware decoding and tool-augmented planning
- Sectors: model inference, agent frameworks.
- What could emerge: Constrained/collaborative decoding with SAST and symbolic checks in the loop; planning strategies that minimize CWE-specific risk while meeting specs.
- Dependencies/assumptions: Latency and tool reliability; integration complexity across languages.
- Domain-specific secure agents for memory-unsafe stacks
- Sectors: embedded/ICS, automotive, medical devices, telecom.
- What could emerge: Agents with per-CWE guardrails, safe API whitelists, and verified patterns for C/C++ code; evidence packs for safety cases.
- Dependencies/assumptions: High-assurance verification burden; domain certification processes.
- Continuous AI-code risk scoring and policy integration
- Sectors: enterprise DevSecOps, GRC.
- What could emerge: Organization-wide policies that meter “AI code risk budgets,” auto-block merges when risk exceeds thresholds, and require compensating controls or human reviews.
- Dependencies/assumptions: Accurate AI provenance, calibrated risk models, change management.
- Cross-language, cross-source benchmark expansion
- Sectors: academia, standards, vendors.
- What could emerge: Larger, multi-language SecureAgentBench variants incorporating NVD/CVE data and non-memory-safety issues (e.g., auth, crypto, deserialization).
- Dependencies/assumptions: Curating aligned-introduction contexts and validated PoCs beyond C/C++.
- Education platforms simulating software evolution
- Sectors: higher ed, professional training.
- What could emerge: Gamified labs that replay real vulnerability introductions with PoCs and require multi-file secure fixes under time/resource constraints.
- Dependencies/assumptions: Content development, sandboxing at scale.
- Regulatory guidance and audits for AI-assisted coding
- Sectors: policy, compliance.
- What could emerge: Guidance requiring organizations to disclose AI tool usage, benchmark-derived risk metrics, and secure development lifecycle controls specific to AI-generated code.
- Dependencies/assumptions: Interoperable reporting standards; alignment with existing SDLC/security frameworks.
- Insurance and risk underwriting for AI-assisted development
- Sectors: cyber insurance, finance.
- What could emerge: Underwriting models that factor in SecureAgentBench-like scores, CWE risk profiles, and control maturity for premium setting.
- Dependencies/assumptions: Historical loss data linking AI-assisted coding to incidents; standardized metrics.
Assumptions and dependencies common across applications:
- PoC availability and reproducibility (many projects lack PoCs; PoCs can flake).
- SAST false positives/negatives; rule coverage varies by language and framework.
- Current benchmark scope (105 tasks, OSS-Fuzz bias, primarily C/C++); generalization requires expansion.
- CI time/cost constraints for running tests, PoCs, and analyzers at scale.
- Accurate attribution of AI-generated code in repositories for governance and policy.
- Evolving model landscape (performance and pricing), requiring periodic re-evaluation.
Collections
Sign up for free to add this paper to one or more collections.

