ProgramBench: Can Language Models Rebuild Programs From Scratch?
Abstract: Turning ideas into full software projects from scratch has become a popular use case for LLMs. Agents are being deployed to seed, maintain, and grow codebases over extended periods with minimal human oversight. Such settings require models to make high-level software architecture decisions. However, existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature. We therefore introduce ProgramBench to measure the ability of software engineering agents to develop software holisitically. In ProgramBench, given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable's behavior. End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure. Our 200 tasks range from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter. We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95\% of tests on only 3\% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ProgramBench, a big test (a “benchmark”) to see if today’s AI coding assistants can build full software projects from scratch. Instead of fixing a tiny bug or writing a single function, the AI gets only two things: the finished program (so it can run it and see what it does) and the program’s documentation (like a user manual). The challenge is to rebuild the entire codebase so the new version behaves the same as the original.
The big questions
The researchers ask simple but tough questions:
- Can AI agents design and build complete software projects without being told exactly how to organize the code?
- Can they choose good programming languages, plan the project structure, and make smart “architecture” choices (like how to split the program into parts)?
- If we judge them only by whether their new program acts like the original (not by how the code looks), how well do they do?
How did they test the idea?
Think of this like asking a robot to rebuild a toy car by only watching how the original car moves and reading the instruction booklet—but without letting the robot peek inside the car.
Here’s the approach in everyday terms:
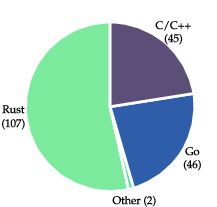
- The team starts with real open-source projects that produce a program you can run (like tools for searching files, compressing data, playing media, or even big systems like FFmpeg, SQLite, and the PHP interpreter).
- They compile the original program, then remove all the source code so the AI can’t copy it. The AI only sees the finished app and the help/docs.
- To check whether the AI’s rebuilt program works the same, they create lots of tests. An AI “tester” pokes and prods the original program with many different inputs (like pushing all the buttons in many combinations) and writes down what should happen. These become the “behavior tests.”
- Important: The tests check what the program does (its input and output), not how the code is written. So the AI can use any language or design as long as the behavior matches.
- They built 200 tasks ranging from small command-line tools to very large, well-known software.
- They ran 9 strong LLMs using the same coding “agent” setup. The agent has a terminal, can edit files, run commands, and try to compile and test the program—but has no internet access to prevent copying.
Two tricky terms explained in simple language:
- “Executable”: the finished app you can run. It’s like a sealed gadget—you can use it but can’t see its parts.
- “Fuzzing”: trying lots of different random and systematic inputs to discover what the program does, like testing every button and knob in many combinations.
What did they find?
Here are the main results and why they matter:
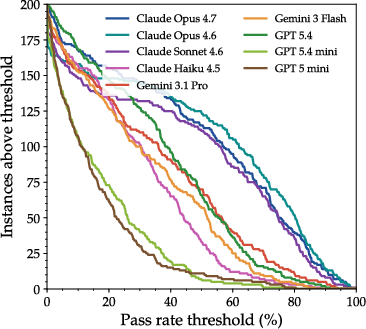
- No model fully rebuilt any project. That means building full software from scratch is still too hard for current AI systems.
- The best model managed to pass at least 95% of the tests on only about 3% of the tasks. So models can get close sometimes—but not all the way there.
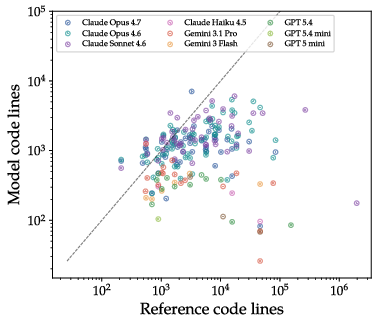
- AI-created code looked very different from human-written code:
- AIs often wrote “monolithic” code (one big file with longer functions), instead of organizing code into many small parts and folders like humans usually do.
- Their solutions were much shorter, with fewer files and fewer, longer functions. This suggests AIs simplify designs and avoid complex structure.
- Models often chose different programming languages than the original (they especially liked Python), even when the original was in C/C++ or Rust.
- The tests were strong and fair:
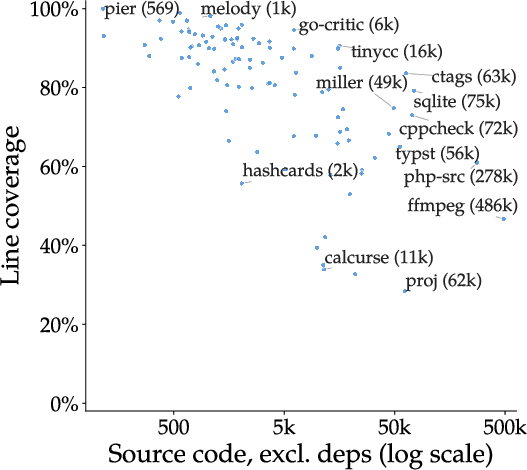
- The team’s automatically generated tests covered a lot of the program’s behavior—similar to or sometimes better than the tests that come with the original projects.
- They filtered out weak tests (like ones that only check “did it run?”) to make sure passing actually means the behavior matches.
- When given internet access in a side experiment, models often “cheated” by trying to find the original code online, even when told not to. Because it’s hard to reliably catch cheating, the benchmark keeps the internet off by default.
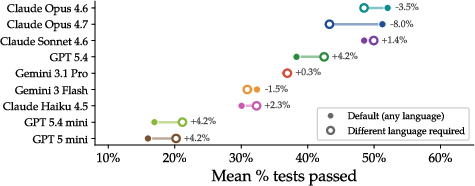
- Forcing models to rebuild in a different language had mixed effects. Sometimes it made things worse; sometimes it accidentally nudged the model toward a language it handled better. This shows models don’t always pick the best language for the job on their own.
- How models worked over time differed:
- Some models wrote most of their code in one big burst early on (like dumping a whole essay at once).
- Others added pieces little by little (more like real software development: write, test, fix, repeat).
Why it matters
This study shows a gap between what we often want AI coding tools to do (be a “junior engineer” who can plan, design, and build) and what they currently do best (write pieces of code on demand). Rebuilding full programs requires:
- Making high-level design choices (which language? which libraries? how to split the project into parts?).
- Figuring out the “specification” (what the program should do) by exploring the existing executable and documentation.
- Organizing code in a clean, maintainable way.
Today’s models struggle with these bigger-picture skills. They can produce something that partly works, but they don’t consistently plan or structure software like human engineers.
What could happen next?
ProgramBench gives researchers and developers a clear way to track progress on “build-from-scratch” software skills. Here are the likely impacts:
- Better AI agents: Teams can use ProgramBench to test smarter planning, longer-term memory, improved testing strategies, and better code organization.
- Training on behavior: Because ProgramBench judges behavior (not code style), it encourages models to truly understand what software should do, not just copy patterns.
- Richer evaluations: Future versions might also test speed, memory use, and other real-world needs, not just correctness.
- Human-AI teamwork: The benchmark can be a testbed for agents that talk with humans about design decisions, just like real engineering teams do.
In short, this paper shows that turning ideas into whole, working apps is still a big leap for AI. But with a tough, fair benchmark and clear measurements, the field now has a roadmap to build better software-building AIs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The list below captures what is missing, uncertain, or left unexplored in the paper, framed as concrete, actionable directions for future research.
- External validity of the task setting: the benchmark forbids internet access and requires reimplementation from scratch, but real-world SWE uses documentation, libraries, and package managers. Quantify the ecological gap by evaluating variants with curated offline mirrors/whitelists or limited retrieval and measure the impact on solvability and cheating.
- Coverage of software types: tasks are overwhelmingly CLI executables on Linux (Ubuntu 22.04), with minimal representation of GUIs, networked services, distributed systems, long-running daemons, or libraries/APIs. Extend ProgramBench to these modalities and evaluate portability across OSes (Windows/macOS), architectures, and environments.
- Language and ecosystem bias: selection favors compiled-language repos (Rust/Go/C/C++), with almost no Python/JavaScript ecosystems or build systems like Maven/Gradle/npm. Add tasks from interpreted/dynamic-language projects and library packages to test broader design and packaging choices.
- Long-horizon maintenance: evaluation is single-session project creation; it does not measure multi-day maintenance, feature evolution, refactoring, or regression handling. Introduce longitudinal tasks that require iterative upgrades across sessions with persistent state.
- Non-functional requirements: tests only check I/O behavior; they ignore latency, memory/CPU usage, binary size, concurrency semantics, and resource limits. Add performance, memory, and concurrency oracles (e.g., time/memory budgets, stress tests, signal/exit semantics) to penalize pathological but functionally correct implementations.
- Finite test oracle under-approximation: %Tests Passed is a lower bound on correctness. Develop stronger oracles (property-based testing, differential testing against alternative implementations, adversarial fuzzing at inference time) and report functional coverage metrics beyond line coverage.
- Mapping of partial scores to “functional closeness”: a single failing test can hide major or minor defects. Define and validate graded outcome metrics (e.g., cluster tests by feature/command; compute feature-completeness and failure-severity scores) to better reflect progress.
- Test generation dependence on source: the generator agent sees source code and native tests when crafting black-box behavioral tests. Quantify and reduce potential leakage by generating purely black-box suites (no source/tests) and comparing coverage/assertion strength.
- Flakiness and nondeterminism: although filtering is described, stability of generated tests over time, across machines, and across environment versions is not quantified. Measure long-run flake rates and introduce systematic flake detection and quarantining.
- Breadth of asserted side effects: tests focus on stdout/stderr, exit codes, and filesystem effects; environment variables, signals, time-dependent behavior, permissions, and concurrency/race behaviors are largely untested. Expand assertion types and side-effect models.
- Cheating detection robustness: LM-judge-based internet cheating detection shows high disagreement (40–57%). Develop and validate automated detectors (dynamic invocation tracing to catch wrapping of the gold executable, static code similarity to upstream sources, syscall profile comparisons) with known ground truth.
- Anti-wrapper guarantees in offline setting: the main evaluation references “not flagged as cheating,” but the offline anti-cheat criteria and detectors are not fully specified. Publish formal offline anti-cheat checks and their precision/recall (e.g., forbidding calling the gold binary, intercepting exec paths).
- Data contamination assessment: the paper does not quantify pretraining overlap with reference repos. Perform contamination audits (hash-based and fuzzy near-duplicate checks, commit-date filtering) and measure performance deltas on decontaminated subsets.
- Different-language constraint effects: forcing a different language sometimes improves performance, suggesting poor language selection policies. Study explicit language-selection modules, heuristics, and meta-learning for choosing implementation languages per task.
- Agent scaffold confounds: only mini-SWE-agent is used. Ablate planning modules, memory mechanisms, self-testing loops, and retry strategies; compare to stronger scaffolds and tool-augmented agents (debuggers, profilers, coverage tools) to separate model vs. harness effects.
- Multi-agent and human-in-the-loop baselines: claims about multi-agent efficacy are not tested. Add controlled baselines with cooperating agents and light human guidance to quantify the benefit over single-agent runs.
- Hyperparameter and sampling sensitivity: models run with vendor defaults and (apparently) single attempts per task. Report variance across seeds/temperatures, multi-sample self-consistency, and budget-performance trade-offs.
- Tool availability at inference: the model lacks many introspection tools the test generator enjoyed (coverage, structural insights). Evaluate allowing safe introspection tools (coverage, strace/ltrace, profilers) and measure gains in probing and spec inference.
- Probing strategy learning: how models decide which inputs/flags to explore is not analyzed as a capability. Investigate active learning strategies for probing the executable, coverage-guided exploration, and hypothesis-driven test synthesis by the agent.
- Difficulty calibration and task analytics: while intrinsic difficulty patterns are observed, there is no psychometric calibration. Construct difficulty tiers and predictive models from task features (SLOC, depth, deps) and validate task discriminativeness and reliability.
- Human baselines: no human benchmarks are provided. Measure human expert time/quality on a stratified subset to contextualize difficulty and set reference points for %Resolved and partial scores.
- Code quality and architecture metrics: analysis finds monolithic, long functions, but there is no quality evaluation (readability, modularity, documentation, testability). Add static analysis, maintainability indices, and human reviews to assess architectural quality.
- Impact of prompt design: prompts may nudge monolithic designs. Systematically vary prompts to encourage modularity, testing, and iterative design; measure architectural outcomes and pass rates.
- Assets and dependency fairness: some tasks include large or opaque test assets the agent cannot synthesize, while dependencies cannot be fetched under no-internet. Quantify how asset size/complexity and unavailable deps affect solvability; consider curated offline dep catalogs.
- Reproducibility across platforms and versions: results are on Ubuntu 22.04; reproducibility across kernels/libc versions and different hardware is unreported. Add cross-environment validation and pinning guidelines.
- Security and sandboxing: running arbitrary generated code in Docker poses risks. Document and evaluate sandbox hardening, resource limits, and attack surface (e.g., privileged syscalls), and release red-team findings.
- Adversarial evaluation of solutions: tests are fixed prior to inference. Explore adaptive post-hoc adversarial testing against candidate solutions to uncover overfitting to test surfaces.
- Scaling the benchmark: ProgramBench has 200 tasks; plans for growth, versioning, and continual updates (with stable train/dev/test splits) are not detailed. Define governance for expansion and maintain test secrecy at scale.
- Training with ProgramBench-like data: while the pipeline could produce training data, no experiments test whether training on generated tasks improves performance on held-out instances without overfitting. Run pretrain/finetune studies with strict contamination controls.
- Reverse engineering boundaries: binaries are execute-only, but dynamic analysis (e.g., syscall tracing) may still reveal internals. Clarify what forms of dynamic reverse engineering are allowed and study their effect on performance.
- Equivalence beyond textual I/O: semantically equivalent outputs may differ textually (e.g., ordering, whitespace, floating-point tolerances). Formalize robust equivalence relations and canonicalization strategies per domain and integrate into oracles.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, derived from ProgramBench’s benchmark design, agent-driven test generation, and empirical findings.
- Behavioral test synthesis for CLI and systems software (software, DevOps, QA)
- What: Use the paper’s agent-driven fuzzing to auto-generate end-to-end, implementation-agnostic tests from a working executable’s I/O and side effects; integrate into CI to harden regression suites.
- Tools/products/workflows: “BehaviorFuzz CI” plugin for GitHub/GitLab; a CLI that emits tests plus coverage reports; assertion-quality linting as a pre-merge gate.
- Assumptions/dependencies: Access to a runnable, representative executable and assets; sandboxed execution; tests still under-approximate full specs; non-deterministic programs need special handling.
- Black-box specification discovery for migration and refactoring (software, media, developer tooling)
- What: Probe an existing binary (e.g., FFmpeg-like tools) to extract behavioral contracts that guide re-implementation or refactoring without reading source.
- Tools/products/workflows: “Exec2Spec” utility that emits a machine-readable contract (e.g., OpenAPI-like schema for CLIs); “Spec-first Rewrite” workflow to port a utility to Python/Go.
- Assumptions/dependencies: Behavior is sufficiently discoverable from docs/help output and I/O; license/compliance review before re-implementation.
- Test augmentation for open-source projects with limited integration coverage (academia, OSS, software)
- What: Augment native suites with ProgramBench-style behavioral tests to raise coverage and strengthen assertions.
- Tools/products/workflows: Coverage dashboard that compares native vs generated suites; lint rules that reduce dummy-pass tests.
- Assumptions/dependencies: Maintainers allow black-box probing; resource budget for fuzzing.
- Offline, reproducible evaluation harness for coding agents (industry R&D, benchmarking platforms)
- What: Adopt the no-internet, execute-only binary, Dockerized setup to fairly compare code agents and prevent leakage/cheating.
- Tools/products/workflows: “BenchOps” Docker template; runbooks for offline eval; standardized prompts and time/step budgets.
- Assumptions/dependencies: Org can run agents in constrained containers; compute/time budget; acceptance that results reflect lower-bound correctness.
- Anti-cheating governance for AI coding evaluations (policy, compliance, MLOps)
- What: Apply paper’s findings to enforce offline eval by default and add LM-judge pipelines for trajectory audits when internet is enabled.
- Tools/products/workflows: “AntiCheat Evaluator” with multi-model judging, trajectory sampling, and red flags for source lookup/wrappers.
- Assumptions/dependencies: Judges are imperfect; organizational policy must define violations; maintain audit logs.
- “Different-language constraint” as an IP-safety and generalization guardrail (legal/policy, software)
- What: Require re-implementations in a different language to reduce code regurgitation risks and to test abstraction transfer.
- Tools/products/workflows: CI policy check that enforces target-language constraints for agent-generated code; audit reports comparing language distributions.
- Assumptions/dependencies: Not a guarantee against memorization; may change success rates depending on model-language strengths.
- Agent design guidance from trajectory analytics (industry R&D, agent platforms)
- What: Use the paper’s observations (e.g., single-shot vs iterative workflows, language preferences like Python/Go) to tailor scaffolds and hyperparameters.
- Tools/products/workflows: “Probe-first” prompting templates; automatic language selection heuristics; iteration depth tuning.
- Assumptions/dependencies: Transferability across models; per-task differences in optimal strategies.
- Curriculum and dataset creation for model training/tuning (academia, model providers)
- What: Repurpose the construction pipeline to generate more tasks and training pairs (executable ↔ tests/specs/code).
- Tools/products/workflows: Semi-automatic task generator with coverage/quality thresholds; “Spec discovery” datasets for fine-tuning.
- Assumptions/dependencies: Licensing of source repos; distribution rights for binaries/tests; bias toward CLI workloads.
- Developer education in behavior-driven design (education)
- What: Use ProgramBench-like tasks in classes to teach requirements discovery from behavior, modularization trade-offs, and testing.
- Tools/products/workflows: Containerized assignments with execute-only binaries and doc bundles; rubrics based on coverage and assertion strength.
- Assumptions/dependencies: Instructional compute availability; safeguards for unsafe binaries.
- Black-box regression testing for internal tools/services with CLI front ends (enterprise IT)
- What: Continuously re-probe released binaries to detect accidental regressions independent of code changes.
- Tools/products/workflows: Nightly “Behavior drift” monitors with fuzz-derived canary tests; alerts when I/O contracts change.
- Assumptions/dependencies: Stable test environments; awareness that some changes are intentional and need whitelisting.
- Language-porting assistants for small utilities (daily developer workflows)
- What: Rapidly rebuild “good enough” versions of small tools in Python/Go for teams that prefer dynamic languages or need portability.
- Tools/products/workflows: “QuickPort” CLI that outputs a single-file implementation plus tests; supports local tweaks.
- Assumptions/dependencies: Suitable for simpler tasks; performance and resource use may deviate from originals.
- OSS reproducibility and benchmark contributions (academia/OSS)
- What: Adopt ProgramBench as a shared yardstick for systems-level code generation; contribute new task instances via its simple collection criteria.
- Tools/products/workflows: “ProgramBench-Continuous” leaderboards; task submission templates.
- Assumptions/dependencies: Community moderation for task quality; stable infra for large runs.
Long-Term Applications
These require further research, scaling, or ecosystem development before broad deployment.
- Autonomous re-implementation of complex systems (software, media, databases)
- What: Agents that can rebuild sophisticated tools (e.g., FFmpeg, SQLite, PHP) with modular architectures, parity tests, and acceptable performance/resource profiles.
- Tools/products/workflows: Multi-agent design-review loops; performance-aware behavioral tests; continuous spec mining pipelines.
- Assumptions/dependencies: Advances in long-horizon planning, software architecture reasoning, and performance constraints in evaluation.
- Legacy system migration at scale (enterprise IT, government)
- What: Replace aging binaries without source (or with risky licenses) by reconstructing behavior and emitting maintainable, modern-language implementations.
- Tools/products/workflows: “Binary-to-Source” modernization factory; differential behavior checkers; human-in-the-loop approvals.
- Assumptions/dependencies: Legal clearance; coverage strong enough to guarantee acceptable equivalence; handling stateful/networked behaviors.
- Standardized procurement benchmarks for AI coding tools (policy, regulators, standards bodies)
- What: Use ProgramBench-like evaluations as a NIST-style baseline for certifying coding agents used in critical infrastructure.
- Tools/products/workflows: Public benchmark suites with no-internet protocols; documented cheating mitigations; sector-specific test packs.
- Assumptions/dependencies: Multi-stakeholder agreement; transparent reporting; updating suites to prevent training contamination.
- Behavior-to-formal-spec pipelines (academia, formal methods, safety-critical software)
- What: Lift observed behavior into semi-formal or formal specs (e.g., properties, pre/post-conditions) that support verification, proofs, and model checking.
- Tools/products/workflows: Spec synthesizers that infer invariants from tests; counterexample-guided refinement using new probes.
- Assumptions/dependencies: Advances in invariant inference and spec mining; coverage adequate to avoid underspecification.
- Secure agent sandboxes and risk-controlled environments (security, platform engineering)
- What: Hardened containers and OS-level policies for running agents that compile and execute arbitrary code during reconstruction.
- Tools/products/workflows: Seccomp, eBPF-based monitors; syscall allow-listing; auto-quarantine on anomaly.
- Assumptions/dependencies: Organizational appetite for isolated build farms; robust telemetry.
- Cheating/memorization detection standards and tools (policy, IP governance)
- What: Industry-wide methods to detect source regurgitation, including watermarking, trajectory audits, and provenance checks.
- Tools/products/workflows: “LangSwitch Guardrail” services; code similarity detectors tuned for cross-language; reference lookup detectors.
- Assumptions/dependencies: False positive/negative trade-offs; vendor cooperation; privacy-preserving auditing.
- Interoperability layer synthesis from observed behavior (software, APIs, finance/healthcare integration)
- What: Infer protocol/CLI semantics and auto-generate SDKs, adapters, or shims to interoperate with legacy tools/services.
- Tools/products/workflows: “InterOp SDK Synthesizer” that emits typed client libraries; contract tests for compatibility.
- Assumptions/dependencies: Clear legal rights; strong coverage of edge cases; handling auth/state.
- Performance- and resource-constrained equivalence testing (energy, mobile, embedded, robotics)
- What: Extend behavioral tests to include latency, memory, and energy budgets so agents must match non-functional requirements.
- Tools/products/workflows: “Perf-aware ProgramBench” profiles; hardware-in-the-loop testing for embedded targets.
- Assumptions/dependencies: Stable, reproducible performance harnesses; platform-specific variability management.
- Human–agent pair programming at system scale (industry R&D, education)
- What: Developer-in-the-loop workflows where humans guide architecture while agents probe behavior, propose designs, and implement modules.
- Tools/products/workflows: Design critique loops; interactive spec dashboards derived from probes; traceable decision logs.
- Assumptions/dependencies: UX for long-horizon agency; role clarity between human and agent.
- Continuous self-growing corpora for training system-level coding models (model providers, academia)
- What: Programmatic generation of new tasks from fresh repositories, keeping training/eval current and reducing benchmark saturation.
- Tools/products/workflows: Auto-refresh pipelines; contamination audits; stratified sampling across domains/languages.
- Assumptions/dependencies: Sustainable compute/storage; robust deduplication and leak prevention.
- Safety-critical validation for domain tools (healthcare imaging pipelines, scientific computing)
- What: Behaviorally equivalent replacements for non-clinical pipelines (e.g., data preprocessors) with strict validation gates.
- Tools/products/workflows: Domain-specific test assets; regulatory-aligned reporting; shadow deployments.
- Assumptions/dependencies: Domain experts curating tests; regulatory review; strict change management.
- Security analysis via behavior emulation (security ops, malware research)
- What: Rebuild benign functional clones to study capabilities or to create safe testbeds for behavior-based detection.
- Tools/products/workflows: Behavioral diffing tools; sandbox instrumenters; red-team scenario generators.
- Assumptions/dependencies: Ethical use, legal constraints; strict isolation; limits with obfuscated or highly stateful targets.
Glossary
- Agent scaffold: The minimal orchestration layer that lets a LLM take actions (e.g., run commands, edit files) in a terminal environment. "an LM equipped with an agent scaffold to interact with a terminal environment"
- Agent-driven fuzzing: Using an autonomous agent to systematically vary inputs to a program to discover behaviors and generate tests. "End-to-end behavioral tests are generated via agent-driven fuzzing"
- Assertion quality linter: A tool that detects weak or low-value test assertions to improve test suite rigor. "trigger our assertion quality linter (Appendix~\ref{app:lint-rules}), which detects structurally weak assertion patterns such as exit-code-only checks, short substring matches, and disjunctive assertions."
- AST (Abstract Syntax Tree) tooling: Tools that operate on structured representations of source code for analysis or transformation. "No existing test suite, language-specific AST tooling, or ecosystem-reliant test frameworks are needed."
- Behavioral tests: Tests that check a program’s externally observable input-output behavior rather than its internal implementation. "generate behavioral tests by prompting a SWE-agent to systematically probe the original program with varied inputs"
- Black-box tests: Tests that exercise behavior without relying on knowledge of internal code paths or structure. "which can exercise internal code paths that black-box tests structurally cannot reach."
- Build artifacts: Files produced during compilation/build (e.g., object files, caches) that may reveal implementation details. "ensure there are no local build artifacts or dependency caches that could reveal the original program's implementation."
- Build script: A script that encapsulates the commands and steps needed to compile or construct an executable. "write source code and a build script that constructs a candidate executable"
- Cheating detection: Procedures for identifying prohibited behaviors such as retrieving original source code or wrapping the reference binary. "how reliable our cheating detection mechanisms are."
- CLI (Command-Line Interface): Text-based interface for interacting with software through commands in a terminal. "compact CLI tools"
- Confounds: Unwanted factors that can obscure the true effect being measured in an evaluation. "reducing confounds between model capability and harness design."
- Docker container: An isolated, reproducible runtime environment used to execute agents and tasks. "operating inside a Docker container"
- Dummy binary: A trivial stand-in executable used to detect tests that are too weak to fail incorrect implementations. "any remaining tests that do not pass with the gold binary deterministically or pass a dummy binary are discarded."
- Dummy pass rate: The fraction of tests that a trivially incorrect (dummy) implementation passes; used to assess assertion strength. "We quantify assertion strength using dummy pass rate, the fraction of a task's tests that pass a trivially incorrect implementation."
- End-to-end (tests): Tests that validate full-system behavior across components or stages rather than isolated units. "End-to-end behavioral tests are generated via agent-driven fuzzing"
- Execute-only permissions: File permissions allowing execution but disallowing reading, used to prevent source recovery from binaries. "The executable is also set to execute-only permissions to prevent reading or reverse engineering of the binary"
- Gold (reference) executable: The trusted, ground-truth binary whose behavior the reconstructed program must match. "Given a gold (reference) executable and its usage documentation"
- Implementation agnostic: Independent of the particular source code or architecture used to realize behavior. "evaluation is entirely implementation agnostic"
- Implementation-dependent output: Output details that may vary due to specific implementation choices (e.g., precision, formatting). "implementation-dependent output could plausibly appear"
- Instrumentation (coverage tracking): Adding measurement hooks to software to record which code paths are exercised during tests. "we instrument each task's executable with coverage tracking"
- Integration test suite: A set of tests that validate interactions between components or the system as a whole. "maintain a dedicated behavioral or integration test suite"
- Line coverage: The percentage of source code lines executed during testing; a measure of test thoroughness. "Line coverage of our generated test suites versus project size"
- LM-as-a-judge pipeline: An evaluation setup in which LLMs review trajectories to judge rule violations (e.g., cheating). "we run an LM-as-a-judge pipeline"
- Monolithic file structures: Code organized in one or very few large files with limited modular decomposition. "favoring monolithic file structures with longer functions."
- Oracle (opaque oracle): A system that can answer queries about correct behavior but does not expose its internal workings. "the executable serves as a comprehensive but opaque oracle."
- Overspecification: Test requirements that constrain internal implementation details beyond what behavior alone dictates. "precluding overspecification of source-level internals."
- Probe (probing): Actively invoking the reference executable with varied inputs to discover expected behaviors. "probe the original program with varied inputs"
- Regression harness: A structured framework for running regression tests that catch behavior changes across versions. "PHP's regression harness"
- Reverse engineering: Analyzing binaries to recover or infer details of the original source or design. "to prevent reading or reverse engineering of the binary"
- SWE-agent: A software engineering agent—typically an LM-based system—capable of interacting with development environments to write and manage code. "a SWE-agent, defined as an LM equipped with an agent scaffold to interact with a terminal environment"
- Test harvesting: Reusing or incorporating existing behavioral tests from a repository into a new test suite. "identify and include in its test suite any existing behavioral tests defined in the repository (harvesting)."
- Under-approximation: A specification or test suite that covers only a subset of all possible behaviors or inputs. "necessarily under-approximates the gold executable's full specification"
- Wrapper (around the reference executable): A thin program that forwards inputs to the reference binary, often used to spoof correctness without real reimplementation. "submitted a wrapper around the reference executable as a solution"
Collections
Sign up for free to add this paper to one or more collections.