SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
Abstract: Software development is iterative, yet agentic coding benchmarks overwhelmingly evaluate single-shot solutions against complete specifications. Code can pass the test suite but become progressively harder to extend. Recent iterative benchmarks attempt to close this gap, but constrain the agent's design decisions too tightly to faithfully measure how code quality shapes future extensions. We introduce SlopCodeBench, a language-agnostic benchmark comprising 20 problems and 93 checkpoints, in which agents repeatedly extend their own prior solutions under evolving specifications that force architectural decisions without prescribing internal structure. We track two trajectory-level quality signals: verbosity, the fraction of redundant or duplicated code, and structural erosion, the share of complexity mass concentrated in high-complexity functions. No agent solves any problem end-to-end across 11 models; the highest checkpoint solve rate is 17.2%. Quality degrades steadily: erosion rises in 80% of trajectories and verbosity in 89.8%. Against 48 open-source Python repositories, agent code is 2.2x more verbose and markedly more eroded. Tracking 20 of those repositories over time shows that human code stays flat, while agent code deteriorates with each iteration. A prompt-intervention study shows that initial quality can be improved, but it does not halt degradation. These results demonstrate that pass-rate benchmarks systematically undermeasure extension robustness, and that current agents lack the design discipline iterative software development demands.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SlopCodeBench, a new way to test AI coding tools over time, not just once. The idea is simple: in real life, software changes again and again. When AI agents write code, it might work today but become a messy, hard-to-extend “slop” tomorrow. SlopCodeBench checks whether AI-written code stays clean and easy to build on as requirements keep changing.
What questions were the researchers asking?
- Can today’s AI coding agents keep their code clean and easy to update when they must extend their own earlier work?
- How does code quality change over many rounds of edits?
- Do simple “pass the tests” scores miss important problems, like growing messiness?
- How do AI agents compare to human programmers on code quality over time?
- Can better prompts (like “plan first” or “avoid messy code”) prevent code from getting worse?
How did they study it?
Think of building a Lego project where the instructions keep changing. You start with a car, then you’re told to turn it into a truck, then add a crane, then make it fly. If your first design was rigid, every new feature becomes a struggle.
That’s what SlopCodeBench does for code:
- It includes 20 problems split into 93 “checkpoints.” At each checkpoint, the AI gets a new requirement and must extend its own old code—not start fresh.
- The tests are “black-box.” The AI sees the instructions and examples, but not the hidden tests. This prevents the AI from gaming the test suite and forces real design choices.
- The tasks are language-agnostic (you could write the solution in different programming languages), though the paper focuses on Python for the experiments.
- They evaluated 11 different AI coding agents using their official tools.
To measure “slop,” they tracked two simple ideas:
- Verbosity: extra or repeated code that doesn’t add new value. Think of writing the same sentence three different ways—it’s longer, not better.
- Structural erosion: cramming more and more decision-making into a few giant functions. Imagine one huge “God function” that tries to do everything—this makes future changes painful.
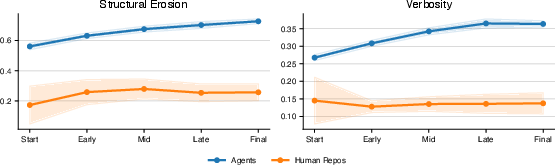
They also compared agent code to 48 real, maintained human Python projects and watched how those human projects changed over time. Finally, they tried prompt tricks like “plan first” or “avoid bloat” to see if that stops the slide into slop.
A quick example
One task starts as a simple search tool, then later asks for:
- Multiple programming languages,
- Smarter pattern matching using syntax trees,
- Auto-fixes, and
- Even more languages.
If the AI hardcodes early choices to handle just one language, it has to hack and patch later. If it designs a clean, flexible structure early on, adding features is smoother. SlopCodeBench rewards the latter—but the agents have to figure that out themselves.
What did they find?
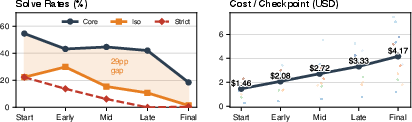
- No AI solved a full problem from start to finish across all checkpoints.
- The best “strict” success rate at a checkpoint was only 17.2% (strict means passing all tests, including ones from earlier checkpoints).
- Code quality steadily got worse as agents iterated:
- Structural erosion went up in 80% of runs.
- Verbosity went up in 89.8% of runs.
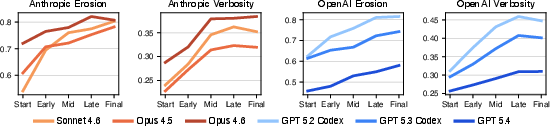
- Compared to human projects, agent code was much messier:
- Agent code was about 2.2× more verbose on average.
- Agent code had far more “big, complicated” functions than human code.
- Over time, human projects tended to stay steady, but agent code consistently got worse with each iteration.
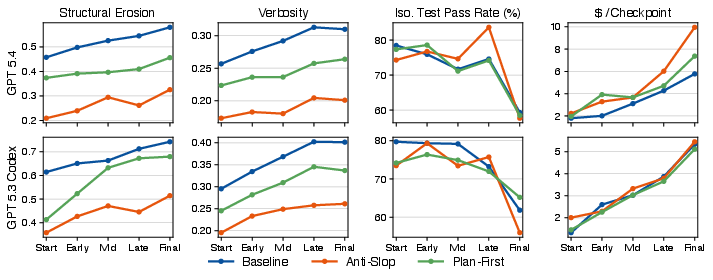
- Prompts that said “avoid slop” or “plan first” helped the very first version look cleaner, but they did not stop the steady decline later on.
- These “quality-aware” prompts often cost more money and time—and still didn’t improve test pass rates.
Why is this important?
Most coding benchmarks today focus on whether the code passes tests right now. But in real software, you live with your code. You need to be able to add features, fix bugs, and grow the system. This paper shows that:
- Test pass rates alone can hide serious long-term problems. Code can pass tests and still be turning into a tangled mess.
- Current AI coding agents don’t reliably make future-friendly designs on their own. They tend to pile on patches, repeat code, and bloat a few giant functions as tasks evolve.
- We need better ways to train and guide AI agents—tools, feedback, or training methods that teach them to keep code clean across many changes, not just solve the current step.
In short
SlopCodeBench is a new “long-term” test that shows how AI-written code gets messy when requirements change over time. It finds that today’s agents often create code that becomes harder to extend, even if it passes tests. Human projects stay more stable. Simple prompt fixes help at the start but don’t stop the decline. The takeaway: to build reliable AI coding assistants, we must measure and improve how well they handle long, evolving projects—not just single tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future research.
- External validity across languages is untested: although SlopCodeBench is designed to be language-agnostic, all experiments target only the Python track; it remains unknown whether the degradation dynamics and metrics (verbosity, erosion) hold for Java, C/C++, Rust, Go, etc., and whether tooling/metrics remain comparable across languages.
- Benchmark scale and task diversity may be insufficient: 20 problems and 93 checkpoints might not cover the breadth of real-world architectural pressures (e.g., large multi-module repos, services, GUIs, build systems, package management), limiting generalizability.
- Realism of “no tests visible” constraint is unvalidated: hiding test suites and prohibiting fail-to-pass feedback may not reflect common developer workflows where tests, CI, and linters are present; it is unknown how results change when agents can see tests or write/maintain their own tests.
- Memoryless iteration between checkpoints may mask potential improvements: the benchmark resets agent session state and prior conversation context each turn; whether memoryful agents (with persistent plans, summaries, or design docs) slow degradation is not assessed.
- Harness confounds are not disentangled from model ability: evaluating via heterogeneous, provider-specific CLI harnesses (with different versions and behaviors) risks conflating harness policy with model capability; a controlled ablation using a standardized loop is needed.
- Sensitivity to harness versions is only lightly probed: the main results pick one version per model; a systematic sensitivity study across harness versions, settings, and toolchains is missing.
- Validity of structural erosion as a maintainability proxy is unverified: the chosen mass formula (CC × sqrt(SLOC)) and CC>10 cutoff are heuristic; there is no user study or empirical validation linking this metric to developer effort, defect rates, or extension time.
- Cross-language comparability of complexity metrics is unclear: cyclomatic complexity thresholds and mass aggregation may not transfer directly across languages and idioms; per-language calibration and thresholds are not evaluated.
- Verbosity metric relies on 137 hand-authored AST-Grep rules without uncertainty estimates: coverage, false positives/negatives, and portability of these rules to other languages and coding styles are not measured; rule-set ablations and cross-language rule design remain open.
- Clone detection details and robustness are under-specified: the clone detection tool, thresholds, and configuration are not fully detailed; sensitivity to clone type (Type-1/2/3/4), normalization choices, and repository size is unknown.
- Other key quality dimensions are not measured: coupling, cohesion, modularity, dependency management, dead code, documentation quality, type hints, test coverage/quality, and API stability are omitted; the relationship between these dimensions and extension robustness is open.
- Runtime and resource efficiency are untested: performance, memory use, latency, and scalability across checkpoints are not assessed; whether verbosity/erosion correlate with runtime regressions is unknown.
- Human calibration is unmatched and potentially confounded: comparing agent outputs to unrelated open-source repos (stratified by stars) does not control for domain, size, maturity, or process; a matched human baseline solving the same SCBench tasks is needed.
- Contamination risk is not formally audited: although specifications are synthetic, there is no formal contamination check against model pretraining data or harness exemplars; the impact of any overlap is unknown.
- Error-handling is identified as a major failure mode but not targeted: error tests drive pass-rate declines, yet the paper does not evaluate targeted interventions (e.g., exception policies, fuzzing, negative-test planning) to improve error robustness over iterations.
- Prompt-only interventions are limited; structural/tooling levers remain untested: the paper shows anti-slop and plan-first prompts reduce initial slop but not slope; effects of continuous code-quality feedback (e.g., gating on CC, clone ratio, linting/formatting, automated refactoring) are unstudied.
- Multi-agent and human-in-the-loop strategies are not evaluated: planner–implementer–reviewer roles, code review cycles, or periodic human refactoring might arrest degradation; their effectiveness on slope reduction is unknown.
- Refactoring allowances and rewrite strategies are not manipulated: the benchmark encourages incremental extension of prior code; studies that explicitly permit/require periodic refactors or modular rewrites to test whether slope decreases are missing.
- Task-level analysis of degradation triggers is shallow: the paper cites a few exemplars (e.g., code, circuit_eval, dag_execution) but does not systematically identify task characteristics (e.g., cross-language expansion, complex dispatch, stateful APIs) that predict erosion/verbosity growth.
- Patch dynamics are not quantified: the size, locality (append vs refactor), and distribution of changes across functions/modules over time are not analyzed; understanding when/where duplication and CC spikes are introduced is an open area.
- Relationship between current quality metrics and future extensibility is uncalibrated: while verbosity/erosion increase, their predictive power for future checkpoint pass rates, time-to-implement, or defect introduction is not modeled.
- Cost–quality tradeoffs are underexplored: analysis beyond average dollars/minutes per checkpoint (e.g., token budgets, “thinking” vs “acting” time, diminishing returns curves) is missing; it’s unclear which spending patterns, if any, slow degradation.
- Effect of development tooling is unknown: formatting (e.g., black), linting (flake8/ruff), static typing (mypy/pyright), and test scaffolding may alter verbosity/erosion; these were not systematically varied.
- Impact of conversation history and architectural artifacts is untested: providing agents with persistent designs, ADRs, diagrams, or code maps across checkpoints might change trajectories; this remains unexplored.
- Security and defect trends are not measured: growth of vulnerabilities, unsafe patterns, or bug-introducing changes across iterations (and their correlation with verbosity/erosion) is unaddressed.
- Long-horizon limits are modest: problems span 3–8 checkpoints; whether degradation accelerates, plateaus, or can be arrested beyond 10–20 turns remains unknown.
- Benchmark reproducibility details need expansion: randomness control, OS/toolchain variability, and determinism of metrics/tests across machines are not fully detailed; reproducible runs across environments should be validated.
- Generalizability to proprietary vs open models is uncertain: only 11 frontier configurations via Claude Code/Codex are tested; open-source models, smaller models, and fine-tuned agents are not assessed under identical conditions.
- Alignment between correctness and quality is weak but unexplained: large reductions in verbosity/erosion did not improve pass rates; mechanisms (e.g., missing features, under-engineering side-effects) need analysis to design interventions that boost both.
- Extensions to more realistic ecosystems are pending: tasks with external services, databases, networks, build/packaging, and multi-language repos are needed to test architectural discipline under richer constraints.
- Metric release and cross-language tooling readiness need confirmation: for non-Python tracks, availability of parsers, CC analyzers, clone detectors, and AST-Grep equivalents (or alternatives) is unresolved.
Practical Applications
Immediate Applications
The following applications can be deployed now using SlopCodeBench’s artifacts (benchmark, metrics, harness setup) and the paper’s findings on degradation, verbosity, and structural erosion.
- Industry — Procurement “bake-off” for coding agents
- Sector(s): Software/DevTools, Enterprise IT
- What to do: Evaluate candidate AI coding tools using SlopCodeBench before purchase. Compare strict/isolated/core pass rates, cost per checkpoint, and trajectory slopes for erosion and verbosity.
- Tools/products/workflows: Internal evaluation harness; dashboard for per-model solve-rate vs. degradation; acceptance criteria (e.g., maximum erosion/verbosity slope).
- Assumptions/dependencies: Access to vendor harnesses; compute/time budget to run the benchmark; internal thresholds calibrated to team norms; acknowledgment that results are Python-track unless extended.
- Industry — CI/CD “slop gates” to block maintainability regressions
- Sector(s): Software/DevTools, FinTech, HealthTech (regulated environments)
- What to do: Add automated checks for erosion and verbosity on each PR (especially for AI-generated changes). Fail builds if metrics exceed a budget or slope threshold.
- Tools/products/workflows: CI plugin (“SlopGuard”) integrating cyclomatic complexity (e.g., Radon-like), clone detection, and AST-Grep rules; PR annotations with diffs of quality metrics; “slop budgets” per service or repo.
- Assumptions/dependencies: Reliable parsing for your language(s); baseline established per codebase to avoid false positives; developer training to interpret metrics; risk of metric gaming mitigated by periodic audits.
- Industry — Code review assistants that flag and fix “slop”
- Sector(s): Software/DevTools
- What to do: Deploy a bot that comments on high-mass functions and verbosity patterns (copy-paste blocks, unnecessary branches), proposing targeted refactors.
- Tools/products/workflows: AST-Grep rule pack derived from the paper’s 137 rules; “mass concentration” detector; quick-fix snippets; reviewers’ checklist for erosion hotspots.
- Assumptions/dependencies: Review culture open to automated feedback; static analysis tuned to the project; refactor suggestions guarded by tests.
- Industry — Prompt strategy and workflow templates
- Sector(s): Software/DevTools, Consulting
- What to do: Use “anti-slop” and “plan-first” prompts to improve initial code quality when engaging agentic tools; pair with CI slop gates to sustain quality.
- Tools/products/workflows: Prompt libraries; internal playbooks combining plan-first → implement → refactor passes; cost tracking per checkpoint to catch diminishing returns.
- Assumptions/dependencies: The paper shows prompts lower intercepts but not degradation slopes; teams need guardrails (quality gates, refactor steps) beyond prompting.
- Industry — Cost/performance observability for agent workflows
- Sector(s): Platform Engineering, DevOps, FinOps
- What to do: Track cost per checkpoint, pass-rate subtype (core/functionality/error/regression), and quality metrics over time to identify “spend-more-for-less” phases.
- Tools/products/workflows: Cost dashboards; alerts when cost rises without correctness gains; escalation to human-led refactoring.
- Assumptions/dependencies: Access to usage/cost telemetry; tagging agent-sourced changes; consistent workload definitions.
- Academia — Research baselines and courseware for iterative software engineering
- Sector(s): Academia, Education
- What to do: Use SlopCodeBench to study long-horizon code aging, ablation of architectural choices, and interventions (e.g., modular scaffolds, planning tools). Turn checkpoints into semester projects testing maintainability.
- Tools/products/workflows: Reproducible Docker setup; assignments that grade both correctness and erosion/verbosity trajectories; human vs. agent comparative labs.
- Assumptions/dependencies: Compute budget for runs; instructor guidance on interpreting metrics; ethical use policies for AI tools.
- Open-Source stewardship — PR triage for bot/agent contributions
- Sector(s): Open-Source, Community Maintainers
- What to do: Auto-label PRs with erosion/verbosity deltas; request modularization when single functions absorb most complexity mass; reject PRs that fail regression quality gates.
- Tools/products/workflows: GitHub Actions app; contributor docs explaining quality expectations; “slop debt” badges per directory.
- Assumptions/dependencies: Community buy-in; balanced thresholds that don’t block legitimate complexity; allowance for domain-specific exceptions.
- Model/agent selection inside enterprises
- Sector(s): Enterprise IT, MLOps
- What to do: Gate internal rollouts on long-horizon metrics (e.g., no adoption unless erosion slope < X and regression pass rate > Y across problem phases).
- Tools/products/workflows: Internal “agent bake-off” pipeline; periodic re-evaluation after model updates.
- Assumptions/dependencies: Stable benchmark snapshots to avoid training contamination; periodic recalibration as models change.
- Safety/compliance guidelines for AI-assisted coding
- Sector(s): Governance, Risk, Compliance (GRC)
- What to do: Update engineering policies to require extension-robustness checks (hidden-test philosophy, regression tests preserved) and quality budgets for AI-generated code.
- Tools/products/workflows: Policy addenda referencing trajectory-level metrics; audit trail capturing quality deltas; approval workflows for exceptions.
- Assumptions/dependencies: Mapping metrics to compliance frameworks (e.g., ISO/IEC 25010 maintainability), and to industry-specific standards.
- Individual developers and small teams — “Slop scan” before merging
- Sector(s): Daily practice, Indie devs, Startups
- What to do: Run a lightweight CLI to report top erosion hotspots and duplicate blocks; refactor high-mass functions before shipping.
- Tools/products/workflows: Simple local tool bundling CC, clone detection, and AST-Grep; pre-commit hook; short refactor checklists.
- Assumptions/dependencies: Willingness to budget a small amount of time for refactoring; tests to maintain behavior during cleanup.
Long-Term Applications
These applications need further research, scaling, standards, or productization to be broadly feasible.
- Industry/Research — Agent architectures with enforced structural discipline
- Sector(s): Software/DevTools, Agent Platforms
- Concept: New agent loops that plan modules, enforce boundaries, and redistribute complexity automatically after each turn (preventing “complexity mass” from collapsing into single functions).
- Potential products: Architect-in-the-loop agents; “trajectory refactoring” planners that run after every change; structure-preserving code generators.
- Dependencies: Advances in program synthesis, modularity constraints, and multi-turn planning; robust refactoring safety nets; integration with IDEs/CI.
- Academia/ML — Training and evaluation with trajectory-level rewards
- Sector(s): ML research, LLM training
- Concept: Use erosion/verbosity slope as part of the reward function for RL or DPO, or as reranking signals; generate synthetic iterative curricula that force architectural decisions.
- Potential products: Datasets of multi-checkpoint tasks; open-source reward models for “extension robustness.”
- Dependencies: Stable, non-gamable quality metrics; scalable generation of iterative tasks across domains and languages.
- Industry/Standards — Maintainability and “slop” metrics as part of quality standards
- Sector(s): Standards bodies, Regulated industries (healthcare, finance, automotive)
- Concept: Establish norms for extension robustness (e.g., maximum allowed increase in erosion per release), and require reporting for AI-generated code.
- Potential products: Industry guides; certification programs; procurement checklists mandating long-horizon benchmarks.
- Dependencies: Consensus on metrics, thresholds, and audits; mapping to ISO/IEC 25010 and domain standards (e.g., ISO 62304 for medical software).
- Cross-language and domain-specific SlopCodeBench suites
- Sector(s): Embedded systems, Robotics, Data/ETL, Cloud infra, Energy
- Concept: Black-box, language-agnostic benchmarks tailored to other ecosystems (C/C++ for embedded/robotics; JVM for enterprise; SQL/ETL for data pipelines) with evolving specs.
- Potential products: “SlopCodeBench-Embedded,” “-Data,” “-Infra”; vendor-neutral challenge tracks.
- Dependencies: High-quality parsers/clone detectors per language; realistic domain checkpoints; cost-effective harnesses.
- Self-healing refactoring services
- Sector(s): DevTools, Platform Engineering
- Concept: Always-on services that observe CI results and proactively redistribute complexity, deduplicate code, and extract modules between sprints.
- Potential products: SaaS refactoring copilots; “budget-aware” maintainers that keep erosion/verbosity within SLOs.
- Dependencies: Safe automated refactoring at scale; semantic diffing; test generation to validate behavior; change management.
- Governance/Policy — Regulatory audits of AI-generated code longevity
- Sector(s): Government, Critical infrastructure, Defense
- Concept: Include long-horizon maintainability checks in audits (e.g., “simulate three requirement changes; demonstrate quality stability”).
- Potential products: Audit frameworks; guidance for public-sector AI procurement; risk scoring for code longevity.
- Dependencies: Auditor capacity; standardized test suites; confidentiality controls for black-box testing; avoiding training contamination.
- Insurance and risk pricing for AI-assisted software
- Sector(s): Insurance, FinTech
- Concept: Underwrite operational risk based on extension robustness metrics and trajectories; discounts for teams with strong slop gates and refactoring practices.
- Potential products: Code maintainability risk scores; premium adjustments tied to CI telemetry.
- Dependencies: Empirical linkage between metrics and incident rates; secure data sharing; defenses against metric gaming.
- IDEs with proactive “slop budgets” and architectural nudging
- Sector(s): IDEs, Developer experience
- Concept: Real-time feedback on mass concentration and duplication; “design-first” scaffolding; nudges to create extension points early.
- Potential products: Next-gen IDEs embedding erosion/verbosity HUDs; pattern-level code actions.
- Dependencies: Low-latency analysis; unobtrusive UX; accurate cross-project symbol analysis; developer acceptance.
- Beyond code — Extension-robustness benchmarks for other agentic domains
- Sector(s): Workflow automation, Data science/ML pipelines, Robotics
- Concept: Iterative benchmarks with evolving requirements for workflows, DAGs, and control policies; track “process slop” (redundant steps, brittle hubs).
- Potential products: “SlopFlowBench” for automation pipelines; long-horizon DAG quality metrics.
- Dependencies: Domain-specific observability; comparable quality measures; execution sandboxes.
- Enterprise SLOs for code health
- Sector(s): Enterprise IT
- Concept: Treat erosion/verbosity slope as SLOs, reviewed at release gates; tie OKRs and incentives to code longevity.
- Potential products: Health dashboards; executive reports; portfolio risk heatmaps.
- Dependencies: Organization-wide adoption; calibration by system complexity; guardrails to avoid perverse incentives.
Notes on Assumptions and Dependencies Across Applications
- Language coverage: The current results focus on Python; extending metrics to other languages requires high-quality ASTs, clone detectors, and threshold calibration.
- Metric validity and gaming: Erosion/verbosity correlate with maintainability but are partial views; combine with human review and additional metrics (cohesion/coupling, test quality). Watch for gaming (e.g., splitting functions without improving design).
- Cost and compute: Long-horizon runs are time- and cost-intensive; organizations should sample tasks representative of their workload.
- Hidden tests and black-box evaluation: Black-box practices reduce architectural leakage but require careful spec design and robust harness isolation (e.g., Dockerized runs).
- Data contamination: When benchmarking proprietary or open-source history, ensure models haven’t seen targets or commit trails.
- Culture and change management: Successful adoption hinges on developer buy-in, education, and measured thresholds that respect necessary complexity.
Glossary
- Agent harness: The command-line or tooling framework that runs and coordinates an AI coding agent. "We therefore evaluate agents in their native harnesses rather than frameworks such as MiniSWEAgent."
- Agentic coding benchmarks: Evaluations focused on autonomous coding agents, often measuring single-shot performance against complete specs. "agentic coding benchmarks overwhelmingly evaluate single-shot solutions against complete specifications."
- AST-based pattern matching: Matching code structures using abstract syntax trees rather than raw text. "AST-based pattern matching with metavariable capture."
- AST-Grep: A tree-based code query and linting tool used to detect syntactic patterns. "constructing 137 targeted AST-Grep rules."
- Black-box contract: A specification that constrains only observable behavior, not internal implementation details. "each task is a black-box contract that's implementable in any language."
- Black-box testing: Assessing software solely through its external interfaces without inspecting internals. "Black-box testing."
- CLI contract: The precise command-line interface (arguments and outputs) a tool must expose. "specifies the CLI contract: <root_dir> --rules <file> [--encoding <name>]"
- Clone lines: Lines identified as duplicated code fragments used to quantify redundancy. "clone lines normalized by LOC."
- Complexity mass: A per-function metric combining cyclomatic complexity and size to capture structural burden. "assign each callable a complexity mass"
- Cyclomatic complexity (CC): A measure of the number of independent paths through code, reflecting decision-point complexity. "where CC(f) is the cyclomatic complexity of callable f"
- Docker container: An isolated runtime environment packaging software and dependencies for reproducible execution. "Each checkpoint runs in a fresh Docker container under a non-root user."
- Fail-to-pass tests: An evaluation regime where failing tests guide development until they pass, often revealing specific target behaviors. "The dominant SWE evaluation paradigm provides fail-to-pass tests"
- Headless mode: Running an application without a graphical interface or interactive UI. "then invoke each in headless mode."
- High-complexity threshold: The cutoff beyond which functions are considered highly complex for erosion analysis. "functions exceeding a high-complexity threshold:"
- Isolation (ISO) correctness: Passing only the current checkpoint’s non-regression tests, ignoring past requirements. "we also report correct in isolation (ISO)"
- Language-agnostic: Designed to work across multiple programming languages without relying on language-specific internals. "a language-agnostic benchmark comprising 20 problems and 93 checkpoints"
- Metavariable capture: Binding placeholders in AST patterns to concrete subtrees or tokens during matching. "AST-based pattern matching with metavariable capture."
- Normalization guidance: Instructions that specify acceptable formatting or ordering to avoid false failures. "Specifications add normalization guidance only where arbitrary choices could cause false failures"
- Oracle-derived signals: Correctness feedback obtained from test oracles rather than from open-ended specifications. "test- or oracle-derived signals"
- Radon: A Python static analysis tool commonly used to compute cyclomatic complexity and related metrics. "the popular code analysis tool Radon."
- Reasoning effort: A configuration parameter controlling how much internal computation the model expends on a task. "we set the reasoning effort parameter to high."
- Regression tests: Previously introduced tests retained to ensure earlier behaviors continue to work. "Regression — All tests from prior checkpoints."
- Selector rules: Structured selection expressions over AST nodes used to target code patterns and transformations. "Selector rules and auto-fix functionality."
- Semantic source-file search: Searching code by structural or meaning-based patterns rather than raw text. "builds a CLI tool for semantic source-file search"
- SLOC: Source Lines of Code; a size metric for code artifacts. "and SLOC(f) is its source lines of code."
- Structural attractors: Recurring structural patterns that code tends to converge to under iterative edits. "Code converges toward structural attractors"
- Structural duplication: Repeated code fragments across the codebase indicating redundancy. "we measure structural duplication: clone lines normalized by LOC."
- Structural erosion: Increasing concentration of complexity in a small set of already complex functions over time. "structural erosion, the share of complexity mass concentrated in high-complexity functions."
- Thinking-token budget: A limit on tokens allocated to the model’s explicit reasoning process. "we configure the thinking-token budget via the environment variable"
- Trajectory-level quality signals: Metrics tracked across multiple iterations to assess how quality evolves. "two trajectory-level quality signals: verbosity, the fraction of redundant or duplicated code, and structural erosion, the share of complexity mass concentrated in high-complexity functions."
- Verbosity: The proportion of redundant or duplicated code and unnecessary scaffolding in a codebase. "verbosity, the fraction of redundant or duplicated code"
Collections
Sign up for free to add this paper to one or more collections.