- The paper presents TimeMachine-bench, a repository-level migration benchmark that automates task identification and evaluation with date-based environment control.
- It details a five-step pipeline to create dual testing environments (pre- and post-dependency updates) and uses pass@1 and prec@1 metrics for performance measurement.
- Experimental results show high success rates for routine migrations by both proprietary and open-weight models, though challenges remain for complex, multi-step tasks.
Repository-Level Migration Benchmarking with TimeMachine-bench
Motivation and Contributions
TimeMachine-bench introduces a repository-level migration benchmark targeting real-world Python projects, specifically designed to evaluate LLMs and autonomous agents in code migration tasks induced by dependency evolution. Unlike prior benchmarks that treat software engineering within static environments, TimeMachine-bench operationalizes the inherently dynamic nature of code maintenance, where breaking changes in dependencies trigger build/runtime failures post-update. The primary contribution is a fully automated pipeline that identifies, curates, and verifies migration tasks from public repositories, along with a scalable framework for benchmarking solutions, including agent architectures leveraging large-scale models.
Framework and Dataset Construction
A core innovation is the use of date-based environment control. This bypasses the impracticality of manual library version tracking by employing a PyPI reverse-proxy that restricts package resolution to releases before a user-specified cutoff date. This mechanism enables strict reproduction of two temporally distinct environments for each migration instance: one prior to dependency update and one following it.
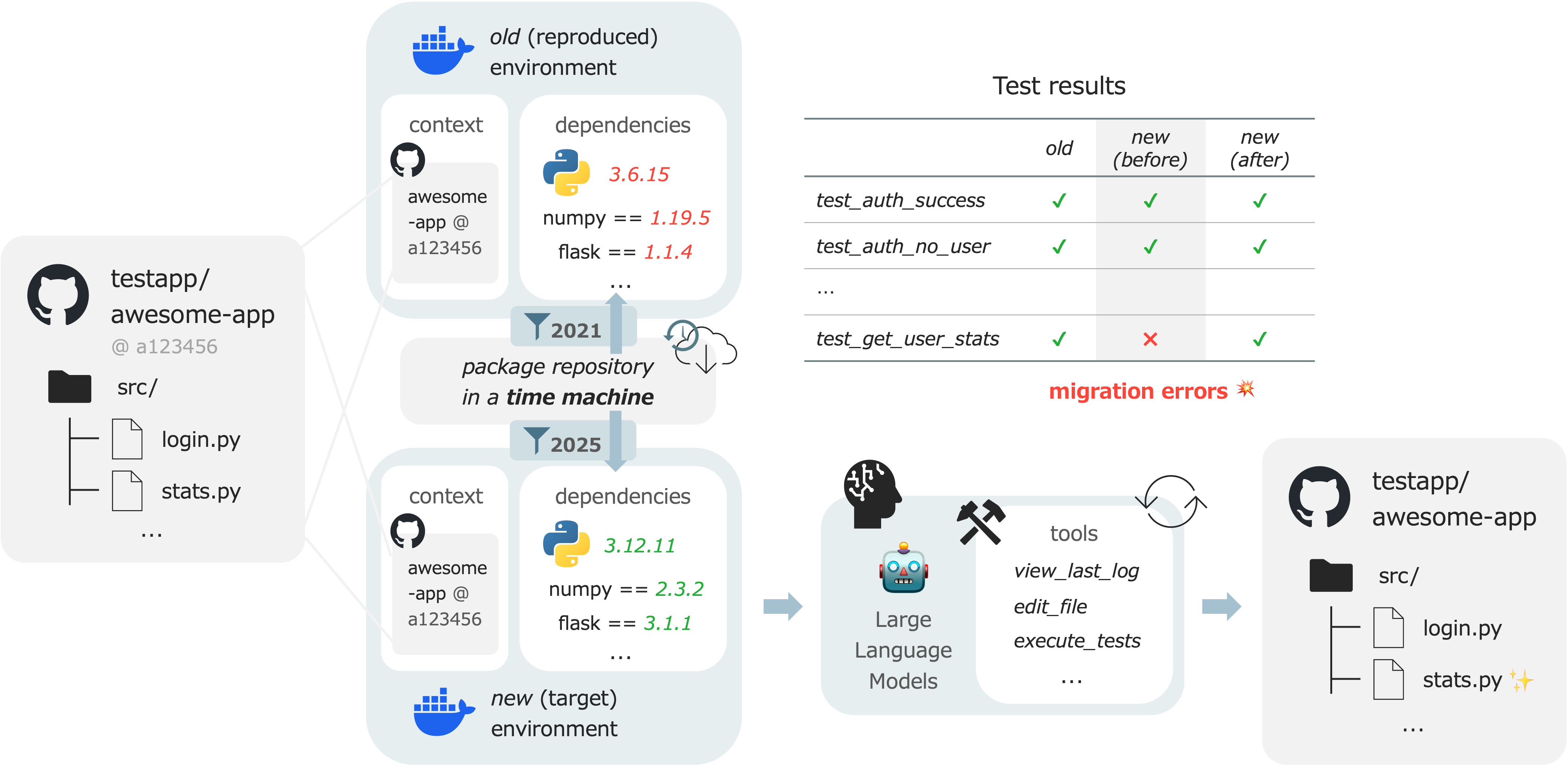
Figure 1: Environment control in TimeMachine-bench via pip index date masking enables reproducible, temporally-bounded migration scenarios.
The construction pipeline comprises five automated steps:
- Repository selection from The Stack v2, filtered for Python and permissive license.
- Identification of build/test configuration and viable test suites.
- Dual environment creation (past/future) with containerized dependency installation constrained by date.
- Automated test execution and log parsing to extract migration-induced failures.
- Human verification for the creation of a high-quality subset (TimeMachine-bench-Verified), ensuring that problems are solvable with code edits alone (excluding dependency downgrades or system-level fixes).
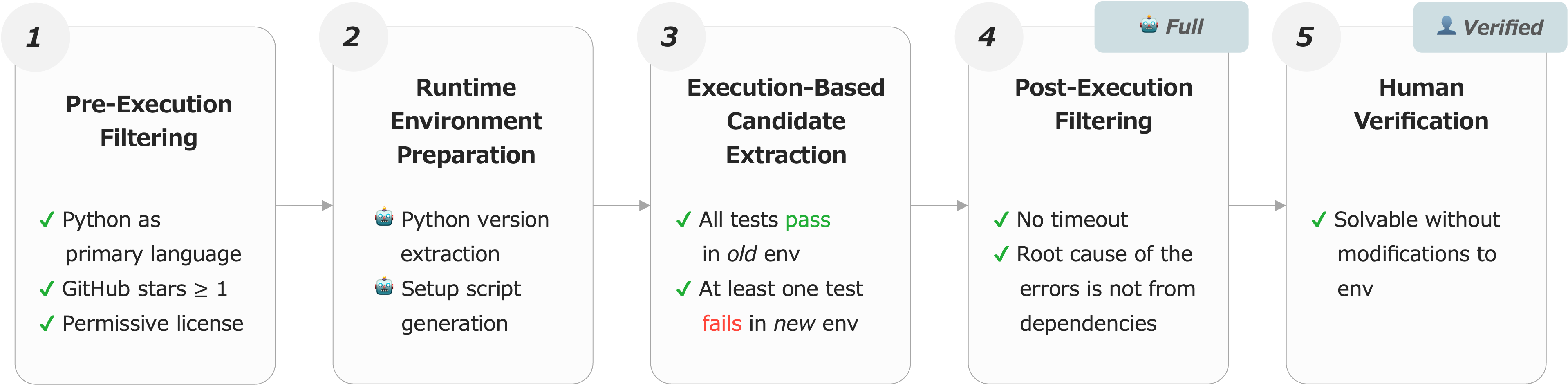
Figure 2: Automated pipeline ensures scalability, resulting in the Full dataset (1,145 repos); manual curation produces the 100-instance Verified subset.
Task Design and Diversity
Tasks consist of real-world migration errors triggered by library and Python version updates. Each task presents the agent with both the specification of dependency versions and the original repository code, and requires modifying only the source files (test-case edits are disallowed) to achieve test suite success in the updated environment.
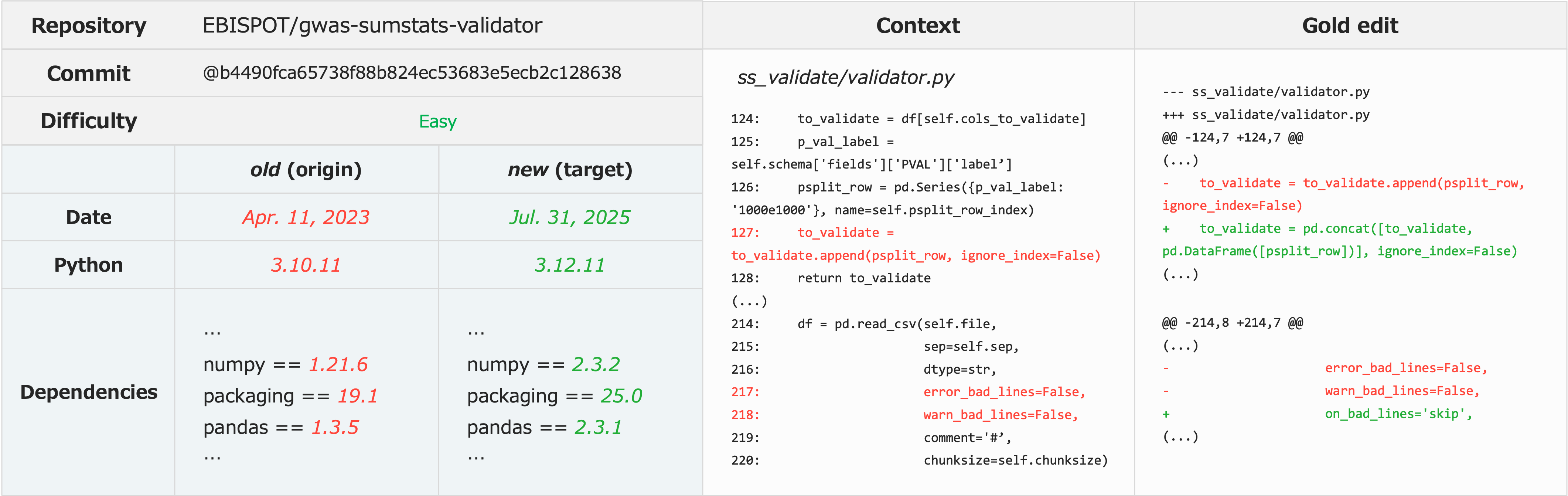
Figure 3: Example Verified task—handling pandas version update, requiring staged correction of multiple runtime errors.
The benchmark covers diverse, ecosystem-wide issues, not restricting itself to popular libraries. Analysis reveals that migration failures occur across dozens of disparate libraries as well as Python builtins:
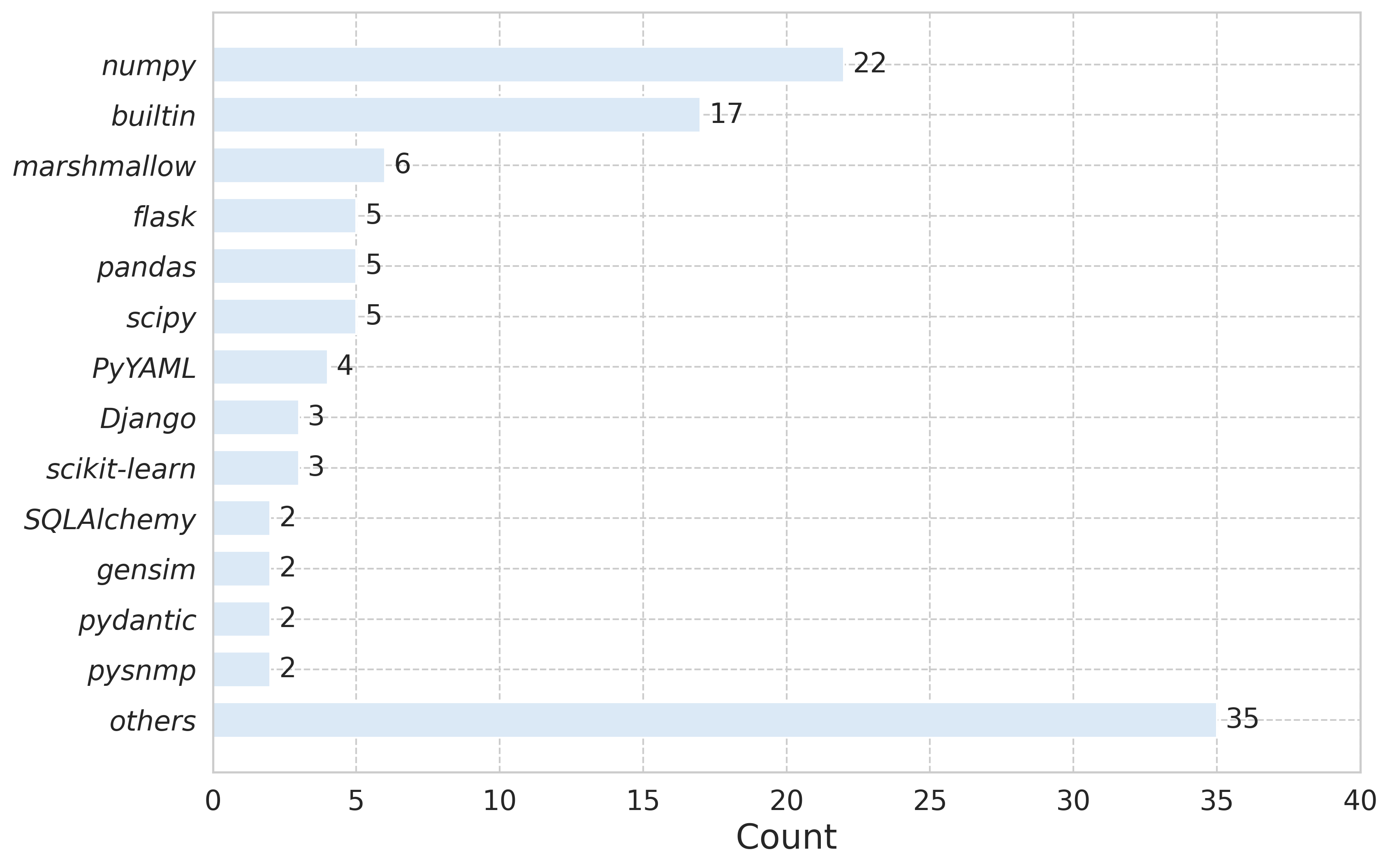
Figure 4: Distribution of error-triggering libraries in Verified; migration problems span the Python ecosystem, not concentrated in a few packages.
Evaluation Metrics and Protocols
TimeMachine-bench introduces dual metrics:
- Sufficiency: pass@1(n,m)—the proportion of solved tasks within n LLM calls and m test executions.
- Necessity: prec@1(n,m)—the precision of model-generated edits against human-annotated minimal changes, computed as the proportion of code edits intersecting the gold patch.
These metrics are used in agent-based evaluation, with agents operating via ReAct-style prompting and a suite of file/log manipulation tools adapted for repository-level migration.
Experimental Results
Strong numerical results were observed in TimeMachine-bench-Verified, especially by proprietary models. Claude Sonnet 4 achieved a pass@1(100, 10) of 99% and prec@1 of 78%, setting an indicative upper bound for automated migration in routine cases.
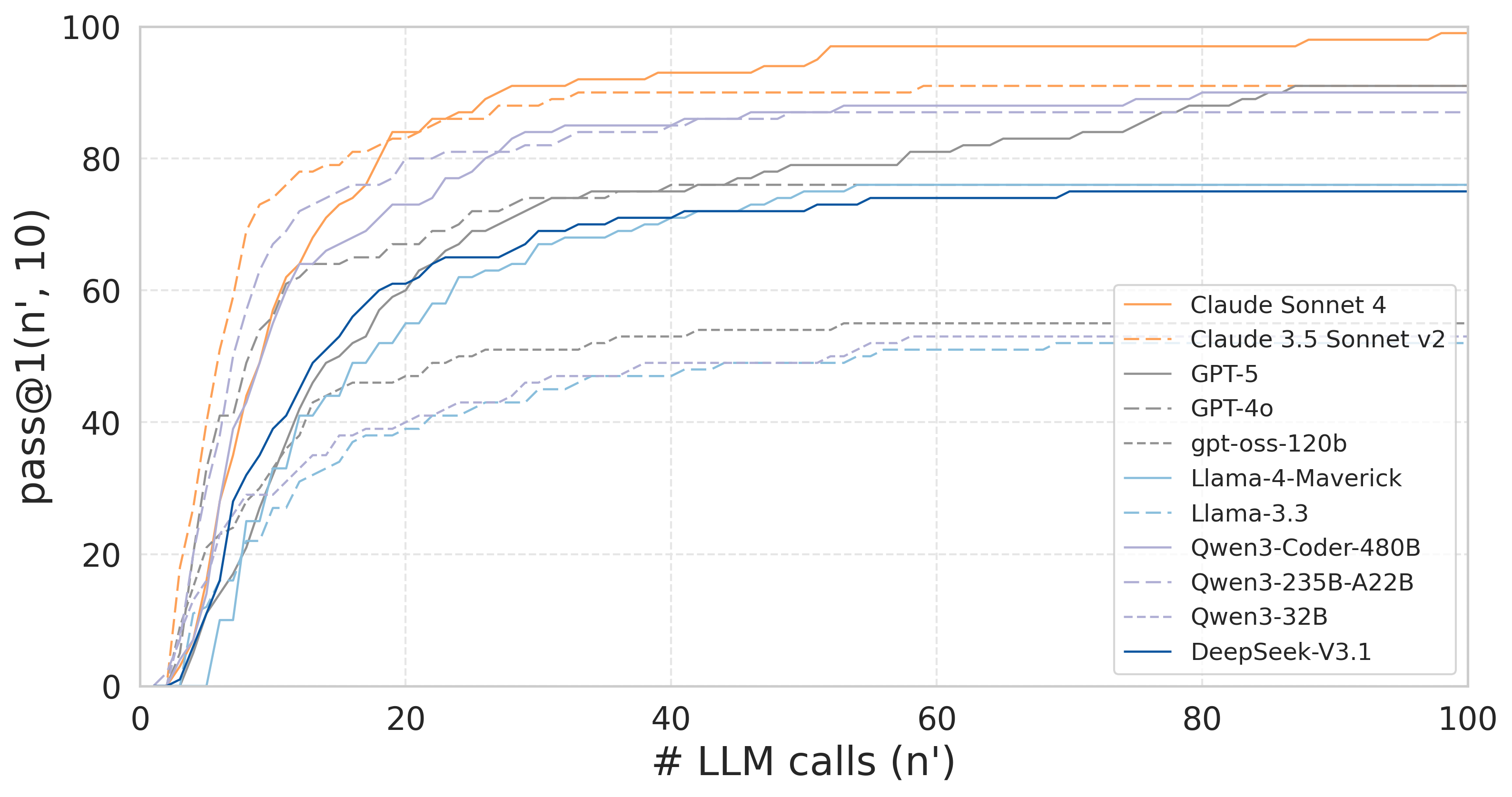
Figure 5: pass@1(n′,10) curve plateauing as the number of agent steps increases, suggesting n=100 suffices for model convergence.
Open-weight models (e.g., Qwen3-Coder-480B) nearly matched proprietary performance, implying rapid progress in foundation model capabilities. Results stratified by task difficulty revealed sharp performance drops on “Hard” tasks, highlighting unresolved efficiency/reasoning gaps for complex multi-step migrations.
Token and cost analysis uncovered significant variation in resource utilization—the Qwen series delivered much higher success rates under constrained monetary budgets compared to proprietary models.
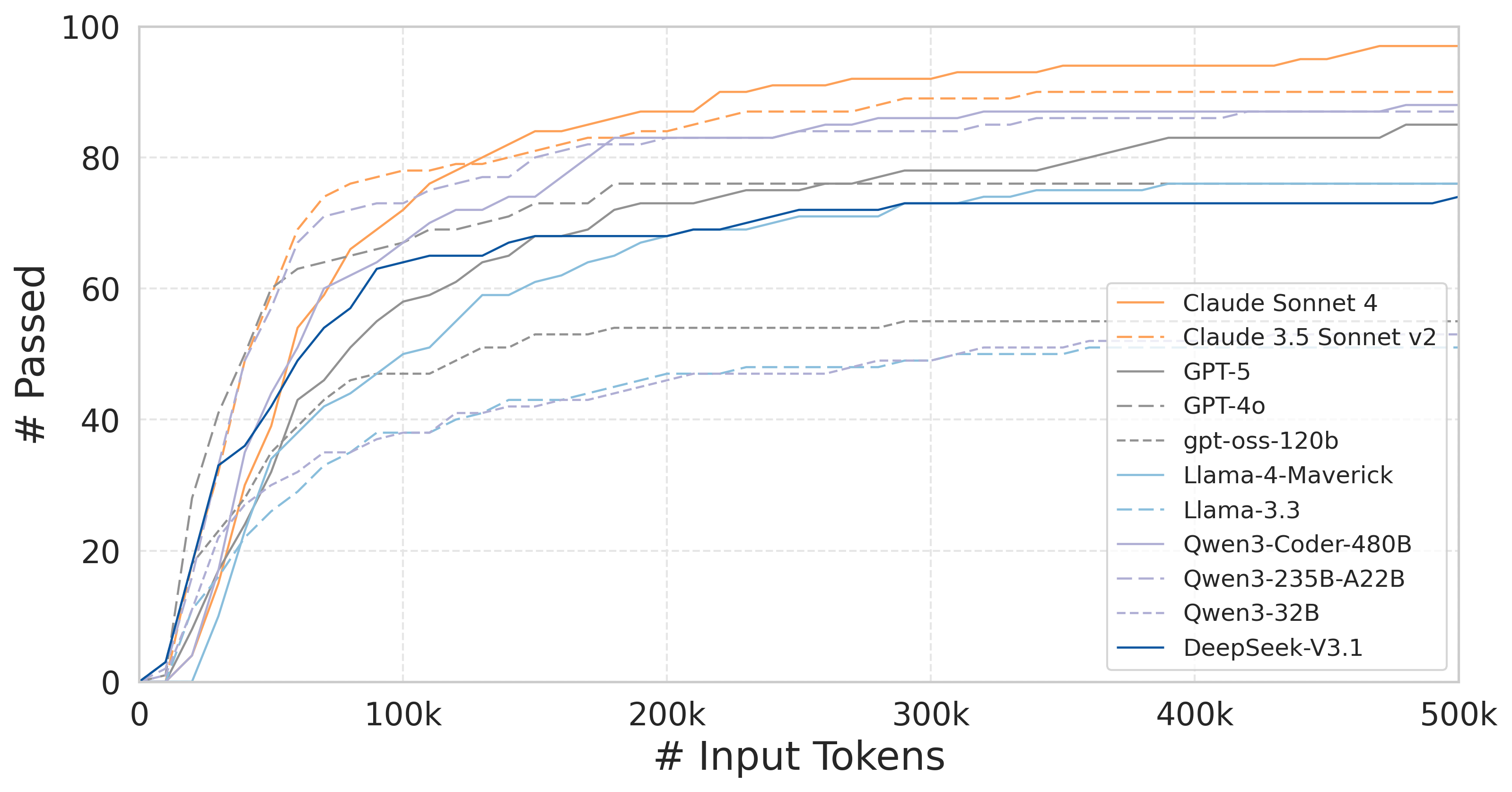
Figure 6: Migration success versus input token budget for Verified tasks—model efficiency is strongly context-dependent.
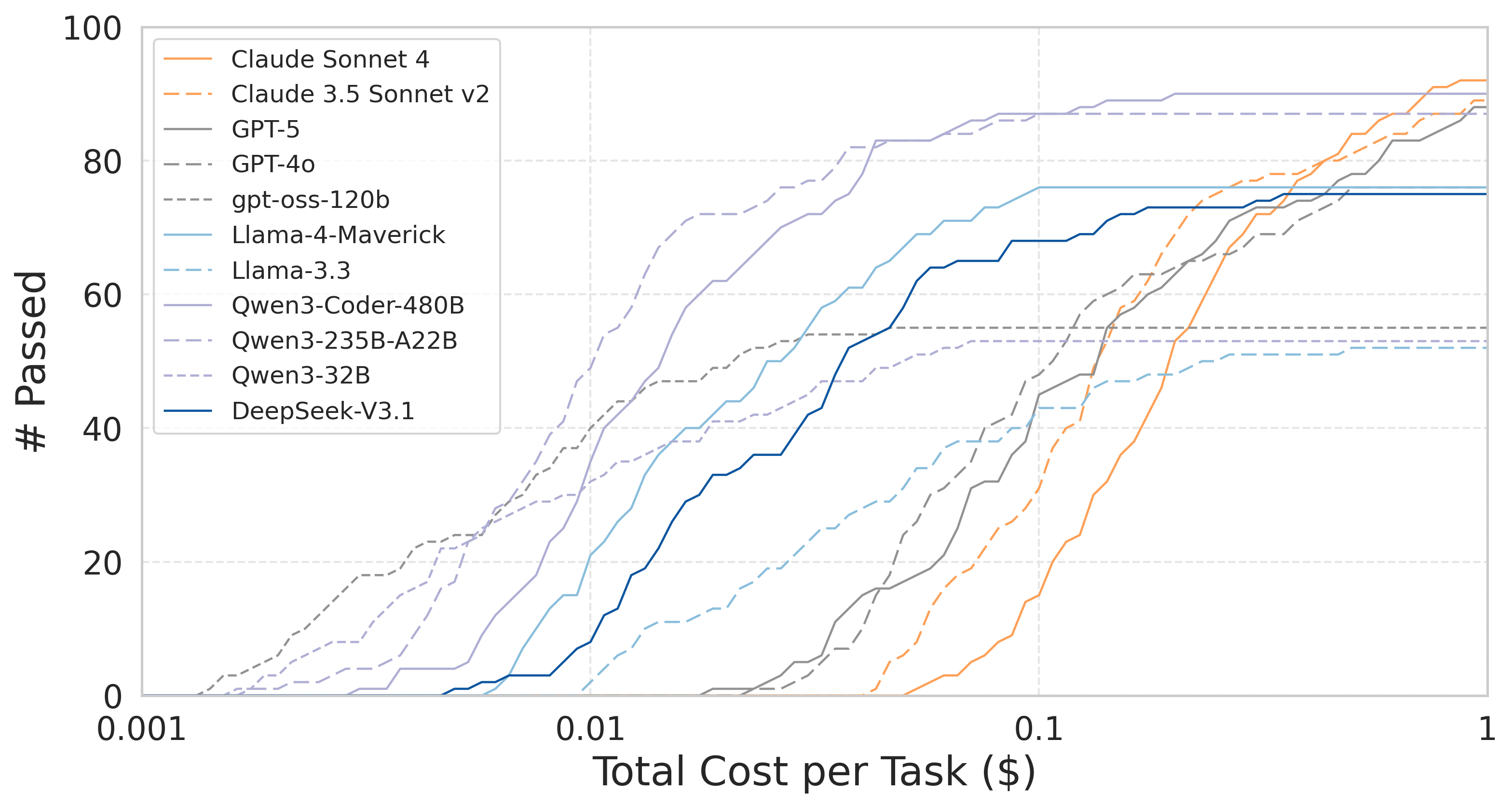
Figure 7: Success rate versus per-task monetary cost, showing open-weight model superiority in cost-effectiveness.
Qualitative Error Analysis and Behavioral Insights
Analysis of tool-use trajectories uncovered distinct strategies. For instance, Claude preferred rapid edit-test cycles, while GPT-5 often overused file inspection, resulting in slower iteration.
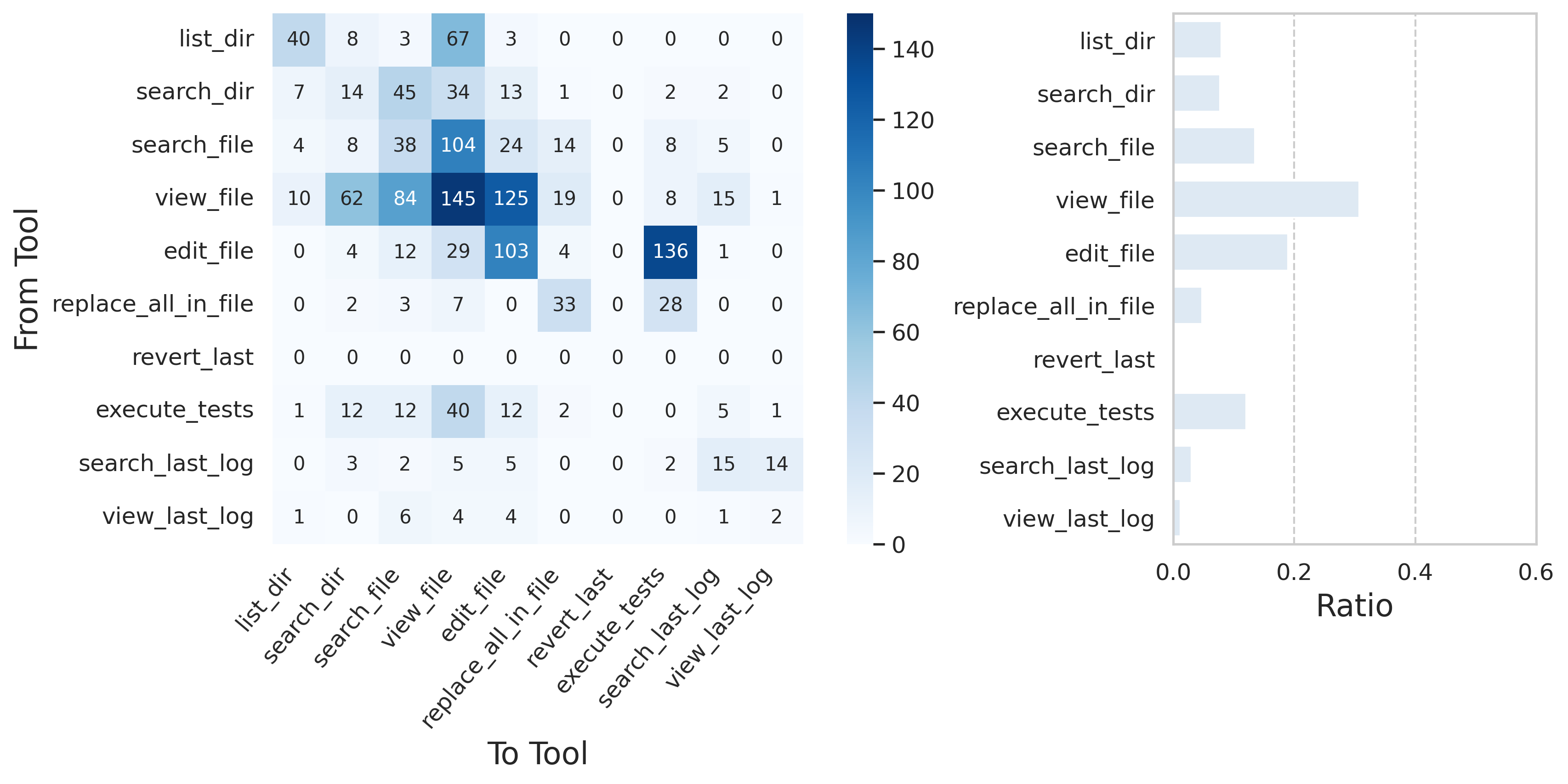
Figure 8: Claude Sonnet 4’s tool usage profile—edit-test alternation enables efficient error localization.
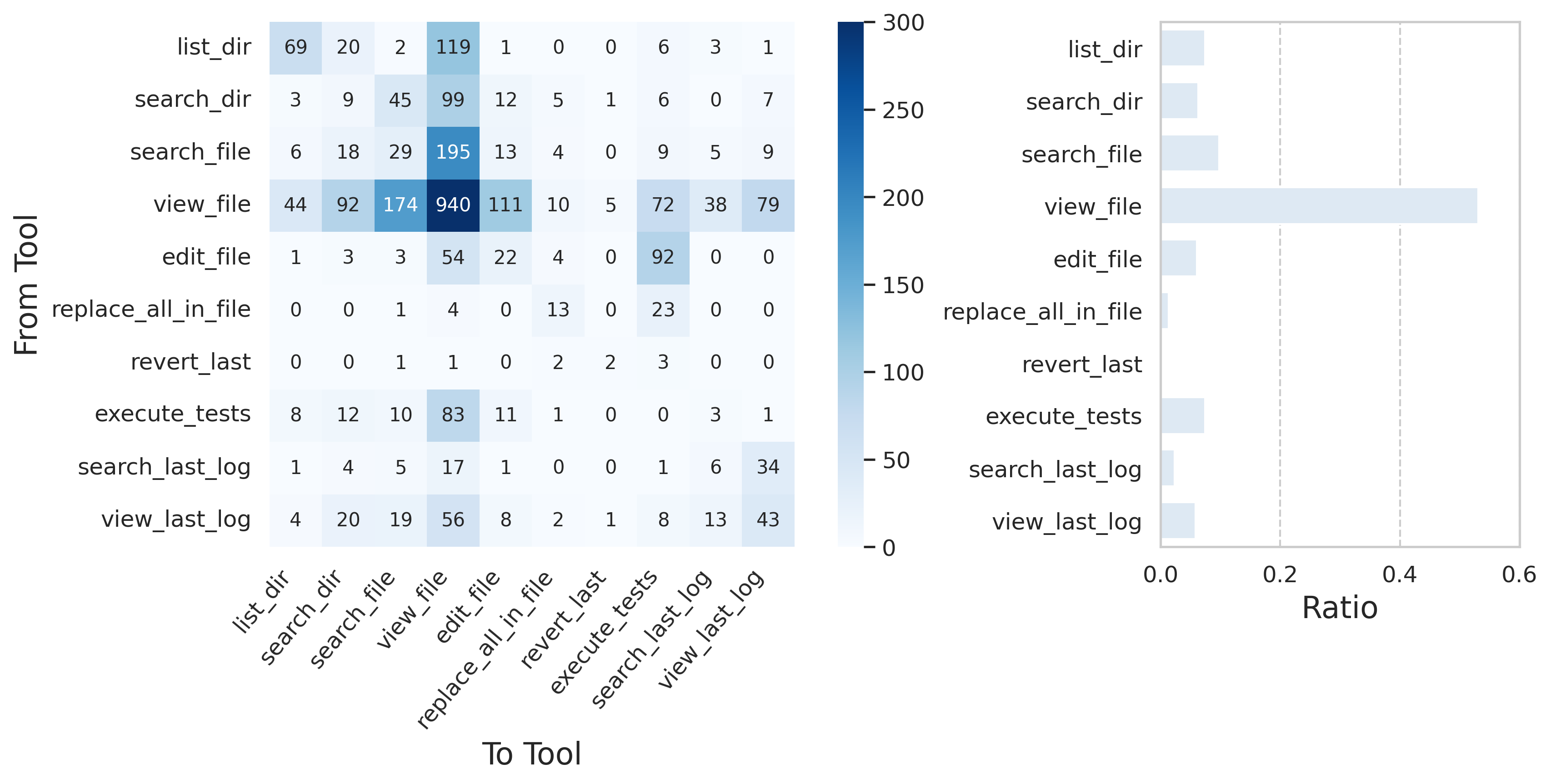
Figure 9: GPT-5 tool usage shows a bias toward context exploration, yielding slower migration.
Precision degradation was most pronounced in unnecessary or redundant edits (e.g., GPT-5’s boundary recognition errors), lack of introspective use of revert mechanisms, and degenerate strategies exploiting poor test coverage (e.g., dummy constant definition for import errors, violating intent but passing tests).
Additionally, models sometimes performed unasked large-scale refactoring beyond required migration scope, introducing semantic drift and review overhead.

Figure 10: Example of GPT-5 initiating far-reaching algorithmic changes, not strictly required for migration.
Benchmarks in Context and Limitations
TimeMachine-bench surpasses existing version-aware code intelligence benchmarks by offering true repository-level, arbitrary-library migration, and by controlling environments via global date filtering, rather than a fixed list of versions.
However, key limitations remain:
- Python-centric construction limits generalization; date-based PyPI proxying is theoretically language-agnostic but untested elsewhere.
- Reliance on extant repository test cases for correctness means latent bug fixes are uncredited, and degenerate solutions may pass.
- Human verification to ensure problem solvability is resource-intensive, introducing a bias toward simpler tasks.
- Data leakage risk exists from later commits in open repositories, though mitigated by the temporal snapshot paradigm.
Implications and Future Directions
Practically, TimeMachine-bench demonstrates that LLMs are plausible assistants for repository migration, particularly in “routine” update scenarios. The narrowing gap between open-weight and closed models has significant implications for tooling cost and accessibility in industrial contexts.
Theoretically, the benchmark foregrounds deficiencies in agent reasoning capabilities for complex multi-step migration. These include overgeneralization of edit patterns, lack of introspection, failure to reason about historical library evolution, and the inability to distinguish migration from wholesale refactoring.
Future research directions include:
- Extending the benchmark to other languages/ecosystems with date-based proxying.
- Integrating automated unit test generation to improve coverage and correctness guarantee.
- Developing more sophisticated agent planning and introspection mechanisms.
- Scalable frameworks for human verification and patch annotation.
Conclusion
TimeMachine-bench sets a new standard for evaluating model and agent capabilities in real-world repository-level migration, uniquely addressing the challenges posed by dynamic software ecosystems. While LLMs demonstrate high baseline performance in common migration scenarios, significant reliability and efficiency challenges remain, especially for hard, multi-step tasks and environments with limited test coverage. The benchmark's extensible design paves the way for continuous, ecosystem-wide evaluation and rapid iteration in autonomous code intelligence research.
Reference: "TimeMachine-bench: A Benchmark for Evaluating Model Capabilities in Repository-Level Migration Tasks" (2601.22597)