MolmoAct2: Action Reasoning Models for Real-world Deployment
Abstract: Vision-Language-Action (VLA) models aim to provide a single generalist controller for robots, but today's systems fall short on the criteria that matter for real-world deployment. Frontier models are closed, open-weight alternatives are tied to expensive hardware, reasoning-augmented policies pay prohibitive latency for their grounding, and fine-tuned success rates remain below the threshold for dependable use. We present MolmoAct2, a fully open action reasoning model built for practical deployment, advancing its predecessor along five axes. We introduce MolmoER, a VLM backbone specialized for spatial and embodied reasoning, trained on a 3.3M-sample corpus with a specialize-then-rehearse recipe. We release three new datasets spanning low-to-medium cost platforms, including MolmoAct2-BimanualYAM, 720 hours of teleoperated bimanual trajectories that constitute the largest open bimanual dataset to date, together with quality-filtered Franka (DROID) and SO100/101 subsets. We provide OpenFAST, an open-weight, open-data action tokenizer trained on millions of trajectories across five embodiments. We redesign the architecture to graft a flow-matching continuous-action expert onto a discrete-token VLM via per-layer KV-cache conditioning. Finally, we propose MolmoThink, an adaptive-depth reasoning variant that re-predicts depth tokens only for scene regions that change between timesteps, retaining geometric grounding at a fraction of prior latency. In the most extensive empirical study of any open VLA to date, spanning 7 simulation and real-world benchmarks, MolmoAct2 outperforms strong baselines including Pi-05, while MolmoER surpasses GPT-5 and Gemini Robotics ER-1.5 across 13 embodied-reasoning benchmarks. We release model weights, training code, and complete training data. Project page: https://allenai.org/blog/molmoact2
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MolmoAct2 — A Simple Guide
What is this paper about?
This paper introduces MolmoAct2, a new kind of AI model that helps robots understand what they see and what we ask them to do, and then turns that into smooth, real-world actions. It’s built to be practical: fast enough to control robots in real time, strong at “spatial reasoning” (understanding where things are and how they move), and fully open-source so anyone can use, study, and improve it.
The Main Goal in Plain Words
Robots often need many separate programs to do different tasks. MolmoAct2 aims to be a single general “brain” that can learn from images, videos, and words, and then control different kinds of robots to do many tasks—like cleaning a table, folding laundry, or assembling parts—without starting from scratch each time.
What questions does the paper try to answer?
- How can we build a robot “brain” that’s open, reliable, and ready for real-world use?
- Can we make robots think more clearly about space (depth, distance, direction) so they act more safely and accurately?
- How do we keep the robot’s decisions fast so it can react in real time, not with long delays?
- Can a single model work across different robot bodies and cameras, not just expensive ones?
How did they build MolmoAct2? (Methods explained simply)
1) A stronger “visual-and-language brain” for robots
- They created Molmo2-ER, a vision-LLM specialized for “embodied reasoning.” That means it’s good at:
- Pointing to exact spots in images,
- Tracking objects across views,
- Understanding depth and geometry,
- Reasoning over time in videos.
- It was trained on about 3.3 million examples designed to teach spatial skills, using a two-step process:
- Specialize: first fine-tune on spatial/robot-focused tasks,
- Rehearse: then mix back in general vision-language data to keep overall skills balanced.
Think of this as giving the model strong “spatial common sense” before it learns robot control.
2) New, real robot datasets you can actually use
They released three curated datasets that work on lower-cost or common platforms:
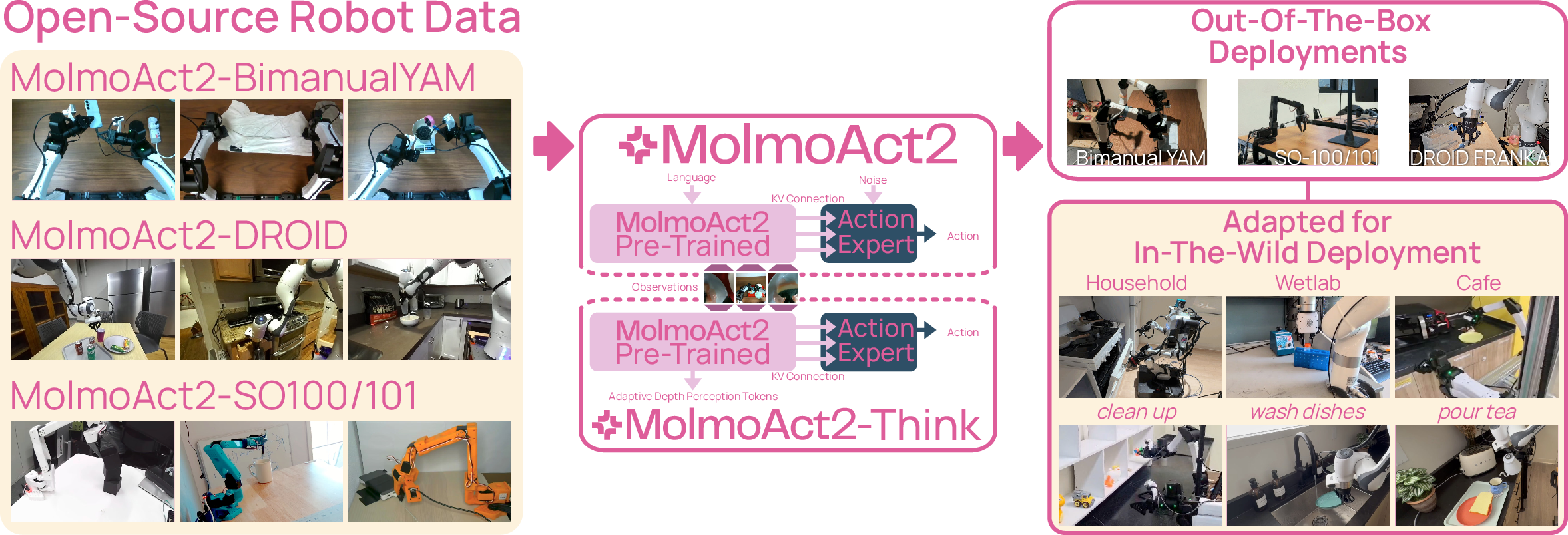
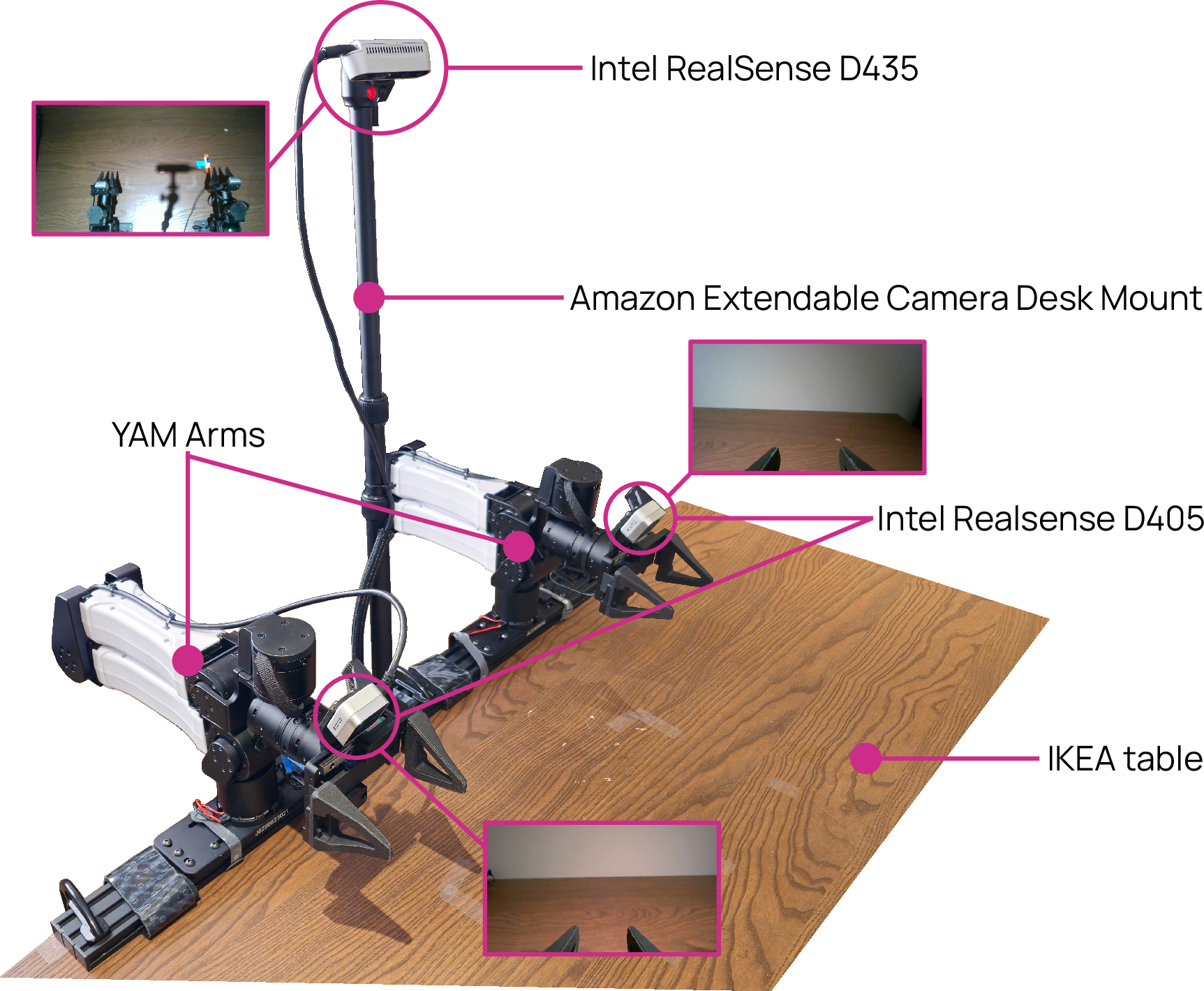
- MolmoAct2-BimanualYAM: 720 hours of two-arm robot demonstrations (largest open bimanual dataset to date).
- MolmoAct2-SO100/101: a cleaned-up set from low-cost community robots, keeping good-quality examples.
- MolmoAct2-DROID: a filtered, high-quality subset of the large DROID dataset for the Franka robot.
These cover many tasks and environments so the model learns to generalize.
3) Turning motions into “tokens” the model can learn
Robots move continuously (numbers like angles and speeds), but LLMs work with tokens (like words). To bridge this:
- They built OpenFAST Tokenizer (fully open) that compresses one second of robot motion into a small sequence of tokens.
- It’s trained on millions of action snippets from different robots, so it works across many “embodiments” (robot bodies).
Analogy: It’s like zipping robot movements into a compact code the model can read and predict.
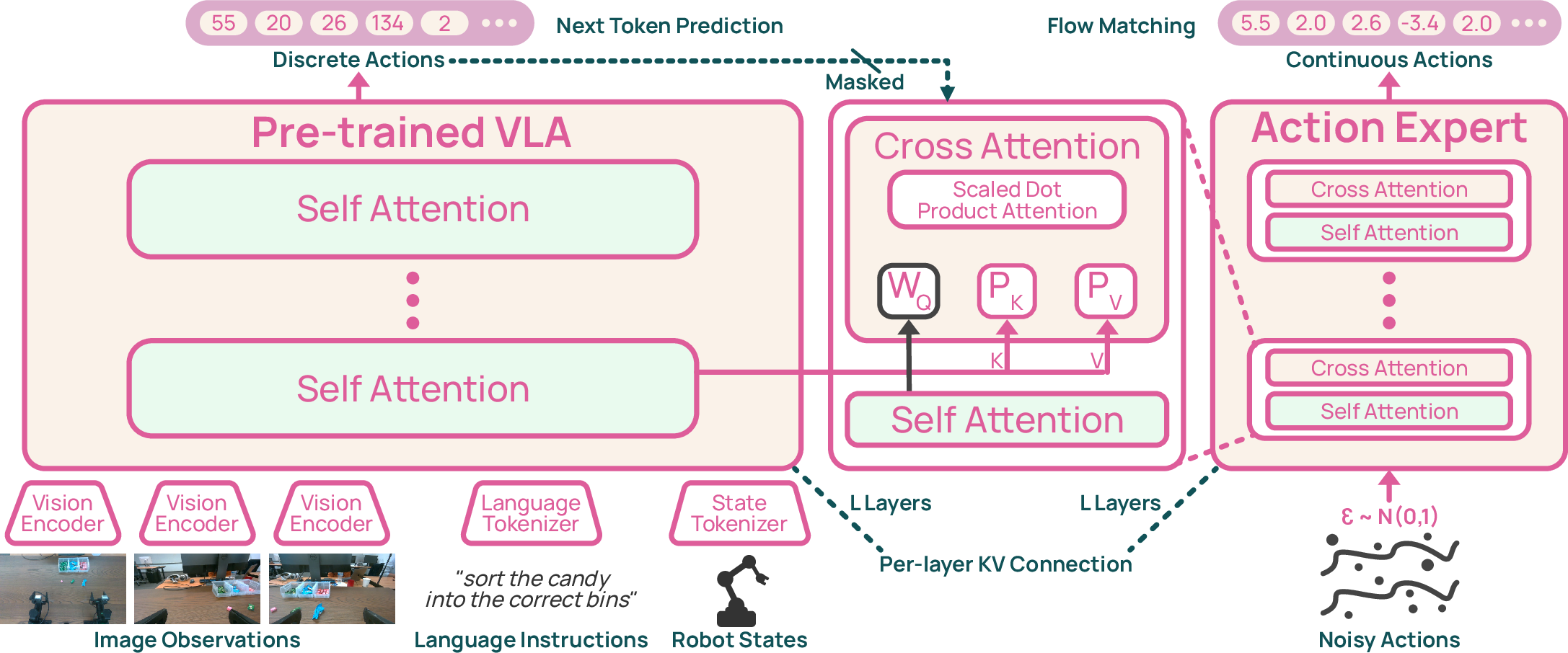
4) A new way to connect language and continuous actions
- The base model predicts action tokens, but real robots need smooth, continuous movements.
- They add an “action expert” that turns those token-level predictions into smooth trajectories using a technique called “flow matching.”
- Flow matching is like starting with noisy guesses and learning how to denoise them into the correct motion path.
- This expert is plugged into the model’s “per-layer KV cache,” which you can think of as the model’s short-term memory at each layer. This gives the action expert rich context about what the model sees and reads, without slowing things down too much.
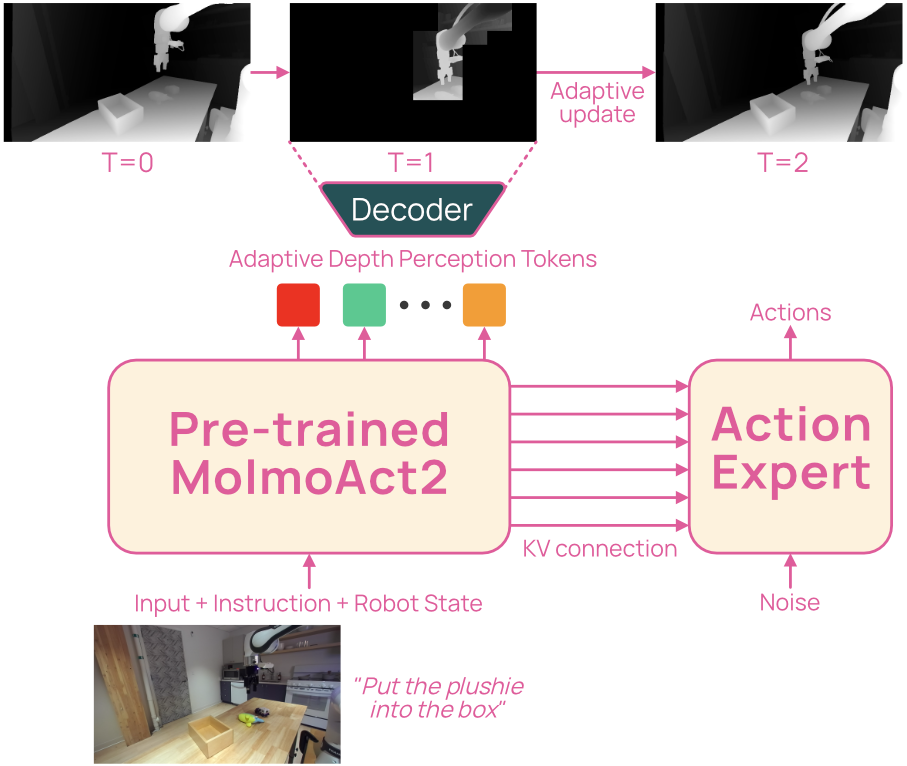
5) Faster, smarter reasoning about depth (MolmoAct2-Think)
- Robots need depth understanding (how far things are) to act safely.
- Traditional “reasoning” can be slow because the model generates lots of extra tokens.
- MolmoAct2-Think speeds this up by only recomputing depth for parts of the scene that changed since the last moment—like only redrawing the parts of a picture that moved.
Result: You keep the benefits of geometric reasoning but at a fraction of the delay.
What did they find?
- Better performance across many tests:
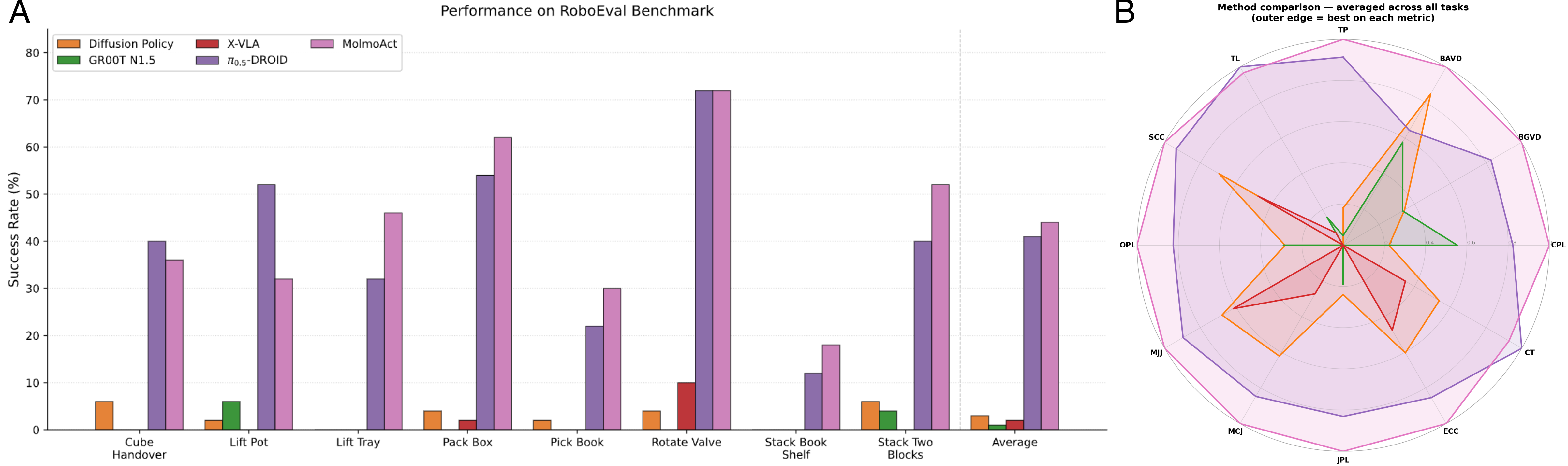
- MolmoAct2 outperforms strong baselines (including a well-known model called π₀.₅) across 7 simulation and real-world benchmarks.
- The Molmo2-ER “brain” beats powerful models like GPT-5 and Gemini Robotics ER-1.5 on 13 embodied-reasoning benchmarks, reaching an average of about 63.8% and improving 17 points over its starting point.
- Works out of the box:
- Their fine-tuned versions for SO-100/101 and DROID Franka can be deployed directly on those robots with no extra training.
- Faster, more interpretable reasoning:
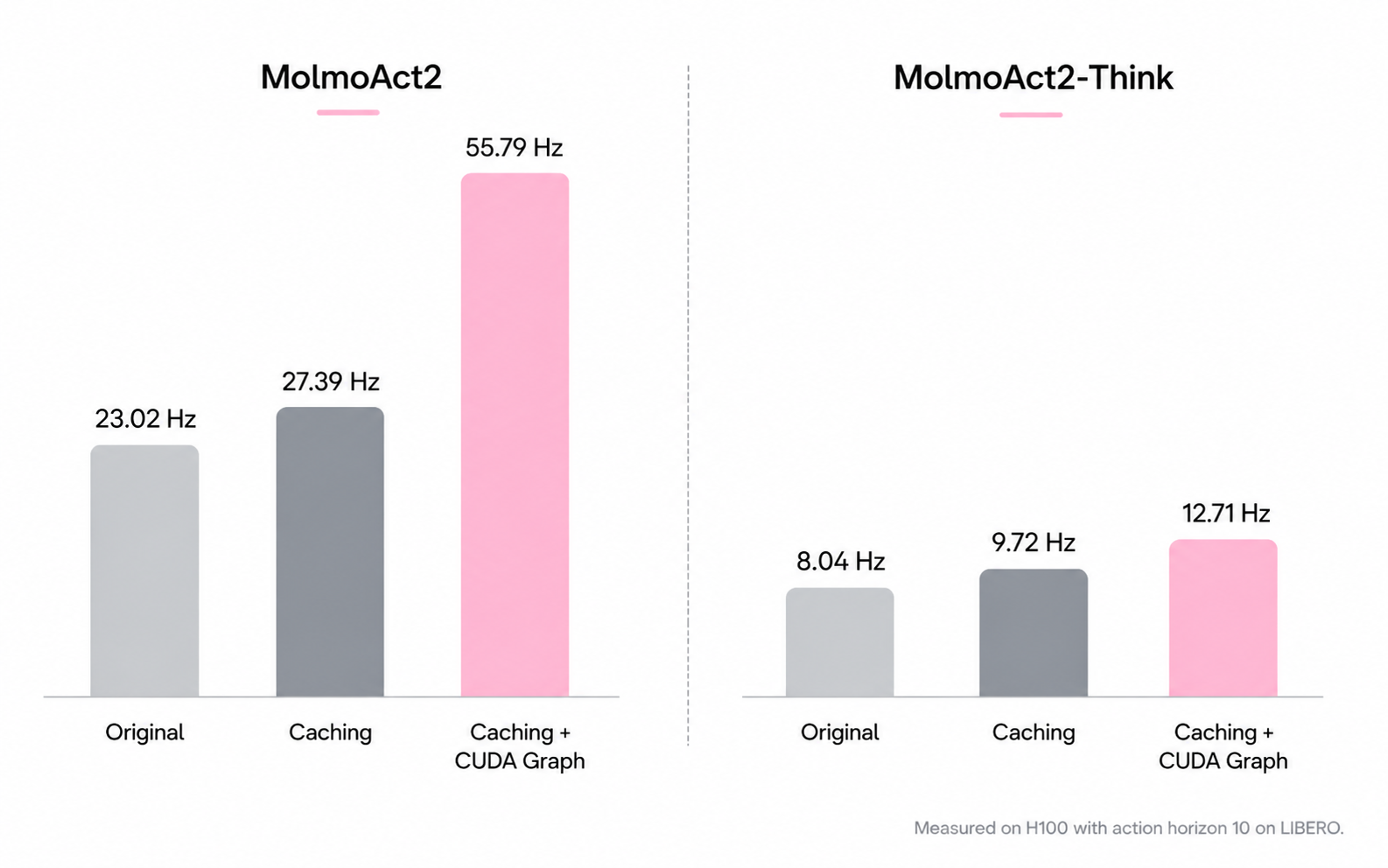
- MolmoAct2-Think gives more performance and makes it easier to see why the robot made certain decisions (because it predicts geometry in an understandable way), yet keeps latency low.
Why this is important:
- It shows you can have strong, real-world robot policies that are open, fast enough for feedback control, and adaptable across different robots.
Why does this matter?
- Fully open: They released the model weights, code, and complete training data. This helps transparency and lets researchers, students, and companies build on top of it.
- Affordable hardware: The datasets and models target low-to-medium-cost setups, broadening who can experiment with advanced robotics.
- Real-world readiness: The system is designed for practical tasks—from household chores to lab work—making robots more useful outside carefully staged demos.
- Faster, clearer reasoning: By keeping the “thinking” fast and visible, developers can debug and trust the robot’s actions more easily.
In short
MolmoAct2 is an open, practical robot “brain” that sees, understands, and acts—quickly and reliably. It learns from huge, well-curated datasets; compresses robot motions into tokens it can predict; turns those predictions into smooth actions; and reasons about depth only where needed. It performs better than strong alternatives on many tests and is ready for real-world use on accessible robots.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or under-explored in the paper. Each point is written to be concrete and actionable for follow-on research.
- Latency and real-time control characterization is incomplete:
- No end-to-end latency breakdown is reported (token generation, KV-cache use, flow expert inference) across hardware tiers (e.g., desktop GPUs vs edge devices) and control rates (10–100 Hz). Report ms/step, jitter, and closed-loop lag for MolmoAct2 vs MolmoAct2-Think.
- The adaptive-depth reasoning method claims reduced latency but lacks quantitative analyses of the speed–accuracy trade-off across different motion magnitudes, scene-change thresholds, and camera resolutions.
- Adaptive-depth reasoning details are under-specified:
- The mechanism to detect “scene regions that change” (e.g., differencing strategy, thresholds, temporal filters) and its robustness to illumination changes, sensor noise, and camera auto-exposure is not described or evaluated.
- The source of supervision for “depth tokens” (true depth vs pseudo-depth from a model) and the impact of depth prediction errors on control are not detailed.
- KV-cache conditioning design lacks ablations and memory profiling:
- No comparison of per-layer KV conditioning versus last-layer-only, hidden-state conditioning, or pooled visual features is provided.
- Memory/compute overhead of storing and projecting KV caches per layer at inference time is not quantified, raising questions about deployment feasibility on low-power hardware.
- Discrete–continuous interface interplay is not thoroughly analyzed:
- The model co-trains a discrete action head and a continuous flow expert, but there’s no ablation on whether the discrete head improves, harms, or is redundant for continuous control at inference.
- Gradient detachment of the VLM during expert training may limit joint optimization; benefits/risks of allowing end-to-end gradients are not explored.
- Action tokenization and chunking design trade-offs are untested:
- The impact of the OpenFAST tokenization (2048-token vocab, Fourier-domain quantization, BPE) on fine-grained motion precision and contact-rich manipulation is not quantified (e.g., reconstruction error vs task success).
- One-second action chunks may cause boundary artifacts or lag; there is no evaluation of chunk length, overlap strategies, smoothing, or receding-horizon scheduling across varied control frequencies.
- Control-mode and embodiment coverage remain narrow:
- The approach is demonstrated on arm-centric manipulation (YAM, SO-100/101, Franka). Generalization to mobile manipulation, non-holonomic platforms, legged robots, drones, force/impedance control, or soft robotic actuation remains open.
- Handling of force–torque, tactile, or audio inputs is not addressed; potential gains from multimodal sensing are unexplored.
- Generalization, robustness, and OOD behavior are not deeply evaluated:
- Robustness to distribution shift (novel objects, clutter, lighting, camera placement changes), adversarial/ambiguous instructions, and sensor failures is not assessed.
- Long-horizon, multi-stage task performance (subgoal tracking, recovery from errors, cumulative error growth) remains unclear.
- Dataset quality, coverage, and bias require deeper analysis:
- While TOPReward filtering is applied, the bias it introduces (e.g., pruning difficult but informative failures) and its correlation with downstream success are not examined.
- Task/object/scene balance and long-horizon coverage in the new datasets (MolmoAct2-BimanualYAM, SO100/101, filtered DROID) are not quantified; skew may limit generalization.
- The impact of community-sourced SO-100/101 data heterogeneity (varying calibrations, camera qualities) on model robustness is not measured.
- Language re-annotation via a VLM is insufficiently validated:
- Re-labeling increases instruction diversity, but there is no human audit of instruction accuracy, faithfulness to demonstrations, or effect on policy performance.
- Risk of hallucinated or semantically drifted instructions and their effect on behavior isn’t analyzed.
- Camera calibration and multi-view fusion assumptions are unclear:
- Randomizing camera order improves invariance, but the model’s sensitivity to miscalibration, focal changes, and view-dependent depth ambiguities is not studied.
- There is no description of how the model handles egocentric–exocentric misalignment without explicit calibration data.
- Safety and deployment risk management are not addressed:
- There is no discussion of safety constraints (torque/velocity limiting, collision avoidance, human-in-the-loop supervision), fail-safes, or certification pathways for real-world use.
- Failure mode taxonomy and safe recovery strategies (e.g., stopping on low-confidence or anomalous sensor readings) are not specified.
- Compute footprint and deployment feasibility are under-documented:
- Training requires substantial resources (e.g., 64×H100), but inference compute, memory, and energy requirements on accessible hardware (Jetson/CPU-only) are not reported.
- Throughput vs accuracy trade-offs for tiled crops, frame sampling, and expert depth are not characterized for practical deployments.
- Evaluation scope leaves unanswered questions:
- Claims of outperforming baselines span “7 benchmarks” and “13 embodied-reasoning benchmarks,” yet per-task details (protocols, success definitions, error bars, statistical significance, failure breakdowns) are missing.
- Cross-site, cross-user “in-the-wild” trials with standardized metrics are not presented.
- Continual learning and adaptation are not explored:
- No procedure is described for online refinement, preventing catastrophic forgetting during incremental updates, or leveraging self-supervised signals during deployment.
- Interpretability beyond depth tokens is limited:
- While MolmoAct2-Think offers geometric grounding, there is no broader framework to attribute decisions (e.g., which views/objects influenced actions), surface confidence, or explain failure causes.
- Legal/ethical considerations for community data are not discussed:
- Potential licensing restrictions, privacy issues, or dataset governance for community-contributed SO-100/101 data are not analyzed.
- Societal impacts, misuse risks, and mitigation strategies for deploying generalist robotic policies are not addressed.
- Hyperparameter and recipe sensitivity is unknown:
- The specialize-then-rehearse schedule, embodied/general mix ratio, NLP proportion, and K values for flow training lack sensitivity analyses that would guide reproducibility and adaptation to other scales.
- Benchmarking against world-model rollouts lacks fairness checks:
- The latency/computation comparisons to world-model-based policies are qualitative; like-for-like baselines, matched hardware, and controlled task difficulty are needed to substantiate speed–performance claims.
Practical Applications
Practical Applications of MolmoAct2, Molmo2-ER, and Associated Assets
Below are actionable, real-world applications derived from the paper’s models, datasets, methods, and tooling. Each item notes sector alignment, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
These can be deployed now with available weights, code, and data on supported embodiments (YAM, SO-100/101, Franka/DROID), assuming standard lab/SME integration effort.
- Bimanual manipulation for routine service tasks
- Use case: Out-of-the-box or lightly fine-tuned execution of household and small-business tasks (e.g., folding laundry, untangling cables, washing dishes, bussing/clearing tables, scanning groceries, packing medication, pouring tea).
- Sector: Robotics, Hospitality/Retail, Light Manufacturing, Healthcare (non-clinical logistics).
- Tools/Workflows: MolmoAct2 and MolmoAct2-Think checkpoints; YAM <$6K setup; SO-100/101; Franka (DROID subset); ROS2 integration; camera calibration workflow; adaptive-depth inference for low-latency control.
- Assumptions/Dependencies: Task space aligns with dataset coverage; proper safety guards and human supervision; reliable graspers; real-time compute available on robot or edge GPU; environment variability within generalization range.
- Rapid embodiment adaptation in academic and SME labs
- Use case: Fine-tune MolmoAct2 to new hardware variants or custom end-effectors using the provided pretraining recipe and open datasets; reproduce and extend VLA research with full pipelines.
- Sector: Academia, Robotics Startups.
- Tools/Workflows: Training code; OpenFAST Tokenizer; curated data (MolmoAct2-BimanualYAM, SO-100/101, DROID subset + academic OXE targets); specialize-then-rehearse training schedule; per-layer KV-cache action expert.
- Assumptions/Dependencies: Access to modest GPUs for fine-tuning; robot drivers and state telemetry standardized to tokenizer format; calibration.
- Low-latency, interpretable action reasoning in real-world loops
- Use case: Deploy MolmoAct2-Think on resource-constrained platforms; visualize depth-token “what changed” for debugging and operator trust while maintaining control rates.
- Sector: Robotics (field ops, QA), Safety/Compliance.
- Tools/Workflows: Adaptive-depth reasoning; depth-token heatmaps/logs; latency-aware inference settings; failure analysis dashboards.
- Assumptions/Dependencies: Stable camera setup with sufficient scene redundancy; operator workflows to review reasoning outputs.
- Open, cross-embodiment action logging, compression, and replay
- Use case: Compress 1-second continuous trajectories across diverse robots into discrete tokens for storage, auditing, imitation learning, or policy distillation.
- Sector: Software for Robotics, MLOps.
- Tools/Workflows: OpenFAST Tokenizer as a library or service; standardized 32-D padded action format; log ingestion pipelines; BPE-token archives for data versioning.
- Assumptions/Dependencies: Consistent normalization/telemetry schema; adherence to 1–99 percentile scaling; gripper handling conventions.
- High-quality, low-cost teleoperation dataset collection at scale
- Use case: Replicate the 720-hour YAM-style teleop pipeline for new domains or tasks with clear quality protocols (limited retries, idle filters).
- Sector: Academia, Robotics Startups.
- Tools/Workflows: Off-the-shelf <$6K YAM bill of materials; teleop interfaces; TOPReward or similar quality gate; idle-frame filters; structured schemas.
- Assumptions/Dependencies: Operator training; availability of space/fixtures/objects; adherence to protocol for repeatability.
- Automated relabeling and quality control for community robot datasets
- Use case: Improve instruction diversity and correctness in existing corpora (e.g., SO-100/101, Open X-Embodiment subsets) via open VLM relabelers and TOPReward filtering.
- Sector: Data Ops for Robotics, Open-Source Communities.
- Tools/Workflows: Qwen family VLMs or Molmo2-ER for relabeling; multi-stage filters (schema checks, license checks, eval removal, TOPReward gate); scripts to double unique labels.
- Assumptions/Dependencies: License compliance for re-annotation; careful prompt design; human spot checks to prevent drift.
- Embodied spatial reasoning for AR/VR, human-robot interaction, and inspection
- Use case: Use Molmo2-ER for pixel-accurate pointing, multi-view correspondence, and temporal reasoning in non-robot applications (e.g., AR assistive pointing, egocentric–exocentric matching, video QA for procedures).
- Sector: Software (AR/VR), Industrial Inspection, Education.
- Tools/Workflows: Molmo2-ER API as a multimodal reasoning backend; ego–exo mapping modules; dataset bootstrapping for procedural QA.
- Assumptions/Dependencies: Camera models and calibration for metric-consistent pointing; domain alignment to training distribution.
- Benchmarking, reproducibility, and pedagogy in embodied AI
- Use case: Use open weights, data, and recipes to teach VLA/VLM concepts; run head-to-head comparisons against baselines; create course labs and public benchmarks.
- Sector: Academia, Standards Bodies.
- Tools/Workflows: Released checkpoints and full datasets; training/eval scripts; embodied reasoning benchmark suite (13 tasks cited).
- Assumptions/Dependencies: Course/lab access to robots or simulators; compute for students; safety protocols.
Long-Term Applications
These require additional research, scaling, validation, or regulatory clearances before widespread deployment.
- Generalist assistance in home and eldercare settings
- Use case: Reliable daily living assistance (tidying, dishes, laundry, mobility aids) with explainable reasoning and low-latency control.
- Sector: Healthcare (Assistive Tech), Home Robotics.
- Tools/Products: Consumer-grade bimanual assistants; on-device adaptive-depth reasoning; caregiver-facing dashboards with depth-token interpretability.
- Assumptions/Dependencies: High success-rate thresholds; rigorous safety, fail-safes, and certifications; robust perception in clutter; privacy-preserving onboard compute.
- Wetlab and small-batch automation
- Use case: Semi-autonomous execution of common lab protocols (pipetting, sorting, labeling, sample prep) with vision-language instructions.
- Sector: Biotech/Pharma R&D, Education Labs.
- Tools/Products: Bench-top bimanual robots; reagent/tool adapters; protocol-to-action translators leveraging MolmoAct2 backbones; traceable depth-token logs.
- Assumptions/Dependencies: Sterility and precision requirements; domain-specific tooling; compliance (GLP/GMP); high-fidelity perception of transparent/reflective labware.
- Flexible micro-factories and on-demand manufacturing
- Use case: Rapid reconfiguration of assembly lines for short runs using language-conditioned generalist controllers instead of bespoke task pipelines.
- Sector: Manufacturing, Industrial Automation.
- Tools/Products: KV-connector adapters for industrial PLC/robot arms; libraries of action experts attached to enterprise VLMs; fleet orchestration with shared tokenized skill libraries.
- Assumptions/Dependencies: Cycle-time and reliability matching industrial standards; integration with safety cages/sensors; certification.
- Retail and logistics automation beyond static skills
- Use case: In-store item handling, shelf restocking, e-commerce kitting, returns processing with minimal reprogramming.
- Sector: Retail, Warehousing/Logistics.
- Tools/Products: SKU-aware perception tied to Molmo2-ER; multi-camera ego–exo correspondence for aisle and backroom; standardized action-token archives for auditing.
- Assumptions/Dependencies: Handling a wide object distribution; throughput targets; safety around customers; integration with inventory systems.
- Standardized, certifiable interpretability for embodied AI
- Use case: Regulatory frameworks that require action reasoning traces (e.g., depth-token deltas) for safety cases, post-incident analysis, and continuous compliance.
- Sector: Policy/Regulation, Insurance.
- Tools/Products: “Reasoning recorder” modules; conformance tests for embodied QA and pointing accuracy; audit-ready token logs and replay.
- Assumptions/Dependencies: Consensus on interpretability metrics; data retention/privacy doctrines; third-party audit ecosystems.
- Cross-domain control via KV-cache adapters
- Use case: Reusing the per-layer KV-cache conditioning approach to graft continuous-control experts onto discrete-token VLMs in other domains (e.g., UAVs, agricultural robots, energy inspection).
- Sector: Aerospace, Agriculture, Energy.
- Tools/Products: Domain-specific action experts; sensor-to-token connectors; mixed-modality replay buffers tokenized by OpenFAST.
- Assumptions/Dependencies: Robust domain data; safety envelopes for outdoor/large-scale systems; latency constraints and edge compute.
- Foundation datasets and community pipelines as public infrastructure
- Use case: Publicly maintained, quality-filtered, license-clean datasets and tokenizers fueling community-driven advances and equitable access.
- Sector: Public Sector, Standards, Nonprofits.
- Tools/Products: National/consortia data hubs; open evaluation leaderboards; “dataset QA” services (TOPReward-like).
- Assumptions/Dependencies: Sustainable funding; consistent quality gates; legal frameworks for shared data.
- Multimodal assistants for education and workforce training
- Use case: Hands-on curricula where students instruct a robot in natural language to perform assembly, lab, or shop exercises, with interpretable feedback.
- Sector: Education/EdTech, Workforce Development.
- Tools/Products: Classroom-safe robot kits; cloud-hosted MolmoAct2 with sandboxed inference; lesson plans mapped to embodied reasoning benchmarks.
- Assumptions/Dependencies: Safety and durability in classroom settings; budget constraints; teacher training.
- Simulation-to-real pipelines with token-level unification
- Use case: Train in diverse simulators, compress policies and trajectories with OpenFAST, and transfer to real robots using shared token vocabularies and KV adapters.
- Sector: Robotics R&D, Tooling Providers.
- Tools/Products: Token-consistent sim data exporters; automated domain randomization aligned with embodied QA; sim–real validation suites.
- Assumptions/Dependencies: High-fidelity sim sensors; domain gap mitigation; scalable fine-tuning budgets.
Notes on Cross-Cutting Dependencies
- Safety and compliance: Many deployments will require independent safety systems (e.g., force limits, vision-based emergency stops), human-in-the-loop supervision, and regulatory approvals.
- Compute and latency: While MolmoAct2-Think reduces latency, meeting tight control loops may still require optimized on-device accelerators and careful model pruning/quantization.
- Data and licensing: Although the paper applies license checks, downstream commercial use must re-validate licensing and data provenance, especially for community-sourced datasets.
- Hardware variability: Real-world robustness depends on calibration quality, gripper/end-effector capability, camera placement, and control-rate synchronization with the tokenizer’s chunking.
- Generalization boundaries: Despite strong benchmarks, domain shifts (materials, lighting, novel objects) may require extra fine-tuning or task-specific demonstrations.
- Human factors: For service and healthcare contexts, user acceptance, training, and ergonomics are crucial; interpretability features should be integrated into operator UX.
Glossary
- Adapter projections: Lightweight learned linear layers that map one model’s key/value representations into another module’s width so they can be used for conditioning. Example: "are linear VLM-to-expert adapter layers that align the VLM KV-cache dimensionality with the expert's cross-attention width"
- Adaptive-depth reasoning: A strategy that selectively recomputes only parts of a scene’s depth to reduce latency while maintaining geometric grounding. Example: "MolmoAct2-Think, an adaptive-depth reasoning variant"
- Affordance: The actionable possibilities an object or environment offers to an agent, used to reason about what actions are feasible. Example: "targeting planning, affordance, and future prediction"
- Autoregressive: A modeling approach that predicts each next token (or action) conditioned on previously generated tokens in sequence. Example: "a discrete autoregressive robot policy"
- Byte-Pair Encoding (BPE): A subword tokenization algorithm that iteratively merges frequent symbol pairs to build a compact vocabulary. Example: "finally applies byte-pair encoding to produce tokens"
- Chain-of-thought (CoT): Explicit, step-by-step intermediate reasoning traces generated by a model to improve accuracy and interpretability. Example: "chain-of-thought traces"
- Closed-loop control: A control regime where actions are computed continuously using feedback from current observations, requiring low-latency inference. Example: "too slow for closed-loop control."
- Cross-attention: An attention mechanism where a query sequence (e.g., actions) attends to a separate context sequence (e.g., vision-language features). Example: "cross-attention to the VLM"
- Delta end-effector control: Commanding changes (deltas) in a robot’s end-effector pose rather than absolute joint angles. Example: "including both absolute joint control and delta end-effector control."
- DiT-style action expert: A diffusion/flow-inspired Transformer block design that conditions action denoising on time embeddings and context. Example: "We use the modern DiT-style action expert, which models a flow-matching velocity field"
- Egocentric–exocentric correspondence: Reasoning that relates first-person (ego) and third-person (exo) views of the same scene or actions. Example: "egocentric--exocentric correspondence"
- Embodied reasoning: Spatial and physical reasoning grounded in an agent’s body, sensors, and actions within an environment. Example: "specialized for spatial and embodied reasoning"
- Flow matching: A training objective that learns a velocity field to transform noise into data (e.g., actions) by matching denoising directions. Example: "models a flow-matching velocity field"
- Flow objective: The loss used to train flow-matching models by predicting denoising velocities at sampled noise levels. Example: "we evaluate the flow objective at multiple noise levels."
- Frequency-domain transform: Representing time-based signals (e.g., action trajectories) in terms of frequencies before quantization or compression. Example: "It first represents the trajectory with a frequency-domain transform"
- Idle-frame filter: A data-cleaning step that removes segments with no meaningful robot motion to improve training signal. Example: "the provided idle-frame filter, which retains only contiguous non-idle action segments of at least one second."
- Key–Value (KV) cache conditioning: Using the stored attention keys and values from a backbone model as conditioning for another module, layer by layer. Example: "per-layer KV-cache conditioning"
- Long-horizon: Tasks or videos requiring reasoning over extended temporal spans, often involving multiple subgoals. Example: "human-annotated long-horizon embodied video"
- On-the-fly packing: Dynamically concatenating multiple short examples into a single training sequence to fully utilize the context window. Example: "we therefore use on-the-fly packing to combine multiple short examples into one 4200-token sequence."
- OpenFAST Tokenizer: An open-weight action tokenizer that discretizes continuous robot trajectories into compact tokens for autoregressive modeling. Example: "We provide OpenFAST Tokenizer, an open-weight, open-data action tokenizer"
- Pixel-accurate pointing: Precisely localizing targets at the pixel level for actions like selecting objects or regions in images. Example: "pixel-accurate pointing"
- Proprioceptive state: Internal robot state (e.g., joint positions/velocities, gripper status) used alongside observations for control. Example: "Proprioceptive state is represented separately"
- Supervised fine-tuning (SFT): Further training of a model on labeled examples to specialize or improve performance. Example: "8% consists of the text SFT data from Tulu"
- Teleoperated: Data collected by remotely controlling the robot, often to gather high-quality demonstrations. Example: "720 hours of teleoperated bimanual trajectories"
- Time embedding: A learned encoding of the diffusion/flow timestep that modulates network layers during denoising. Example: "the time embedding producing DiT-style shift, scale, and gate parameters"
- Vision Transformer (ViT): A Transformer architecture adapted for images by treating patches as tokens. Example: "Visual observations are encoded by the SigLIP2 ViT"
- Vision–Language–Action (VLA) model: A model that maps visual inputs and language instructions to actions for embodied agents. Example: "Vision-Language-Action (VLA) models aim to provide a single generalist controller for robots"
- Vision–LLM (VLM): A model jointly processing visual and textual inputs to produce language or multimodal outputs, often used as a backbone. Example: "a VLM backbone specialized for spatial and embodied reasoning"
- World-model rollouts: Simulated forward predictions of future states or frames used for planning or reasoning during inference. Example: "full world-model rollouts"
- Zero-shot performance: A model’s ability to perform tasks without task-specific training or fine-tuning. Example: "Zero-shot performance remains brittle"
Collections
Sign up for free to add this paper to one or more collections.

