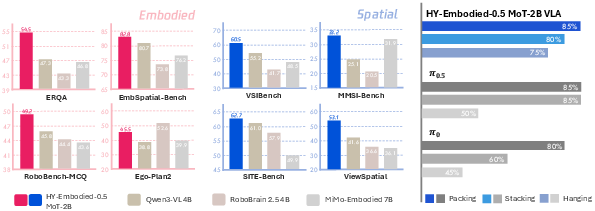
HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
Abstract: We introduce HY-Embodied-0.5, a family of foundation models specifically designed for real-world embodied agents. To bridge the gap between general Vision-LLMs (VLMs) and the demands of embodied agents, our models are developed to enhance the core capabilities required by embodied intelligence: spatial and temporal visual perception, alongside advanced embodied reasoning for prediction, interaction, and planning. The HY-Embodied-0.5 suite comprises two primary variants: an efficient model with 2B activated parameters designed for edge deployment, and a powerful model with 32B activated parameters targeted for complex reasoning. To support the fine-grained visual perception essential for embodied tasks, we adopt a Mixture-of-Transformers (MoT) architecture to enable modality-specific computing. By incorporating latent tokens, this design effectively enhances the perceptual representation of the models. To improve reasoning capabilities, we introduce an iterative, self-evolving post-training paradigm. Furthermore, we employ on-policy distillation to transfer the advanced capabilities of the large model to the smaller variant, thereby maximizing the performance potential of the compact model. Extensive evaluations across 22 benchmarks, spanning visual perception, spatial reasoning, and embodied understanding, demonstrate the effectiveness of our approach. Our MoT-2B model outperforms similarly sized state-of-the-art models on 16 benchmarks, while the 32B variant achieves performance comparable to frontier models such as Gemini 3.0 Pro. In downstream robot control experiments, we leverage our robust VLM foundation to train an effective Vision-Language-Action (VLA) model, achieving compelling results in real-world physical evaluations. Code and models are open-sourced at https://github.com/Tencent-Hunyuan/HY-Embodied.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces HY-Embodied-0.5, a pair of smart computer models designed to help robots and other devices understand the real world and act in it. Think of them as “brains” that can look, read, and reason so they can plan and do tasks in homes, offices, or factories.
There are two versions:
- A small, fast model (about 2B active parameters) that can run on a robot or a small computer onboard.
- A big, powerful model (about 32B active parameters) for tougher problems and deeper reasoning.
Both models are trained to see the world clearly, understand where things are in space, and think through what to do next.
What questions are the researchers trying to answer?
The team is tackling two big challenges that today’s vision-LLMs (VLMs) struggle with:
- Can a model see and understand tiny, real-world details well enough to guide a robot’s hands? (Fine-grained visual perception)
- Can it plan and predict actions in changing, real-world scenes, not just describe pictures on the web? (Embodied reasoning for prediction, interaction, and planning)
In simple terms: How do we go from “the model can describe a picture” to “the model can help a robot pick up the right mug from behind a book and put it on the table”?
How did they build and train the models?
The researchers used a mix of clever architecture and lots of carefully prepared data, then trained the models in several stages.
Model design (the “brain” structure)
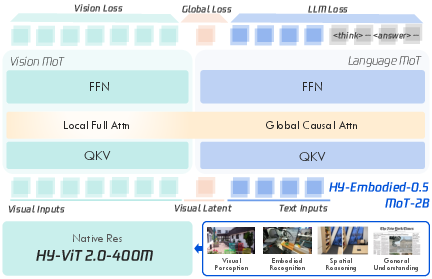
- Vision + language: The model has a part that “sees” (a Vision Transformer, or ViT) and a part that “talks and thinks” (a LLM).
- Two toolsets in one brain (Mixture-of-Transformers, or MoT): The model keeps separate “paths” for visual tokens and text tokens, like having two specialized toolkits—one tuned for images, one for words. This helps it get better at seeing without forgetting how to talk and reason.
- Visual “sticky notes” (latent tokens): After each image or video frame, the model adds a special, learnable token—like a personal sticky note—that captures a summary of the visual scene and connects it to language. This helps images and words “meet in the middle.”
- Native-resolution vision encoder: Their upgraded ViT can handle images at their real size/resolution and compress them into compact codes, a bit like zipping a file without losing important details.
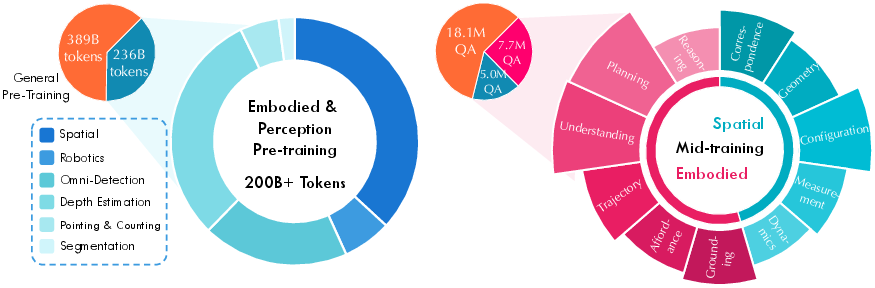
Data they used (what the models learned from)
To make the model good at real-world tasks, the team didn’t just use internet pictures. They built a huge, diverse training set that included:
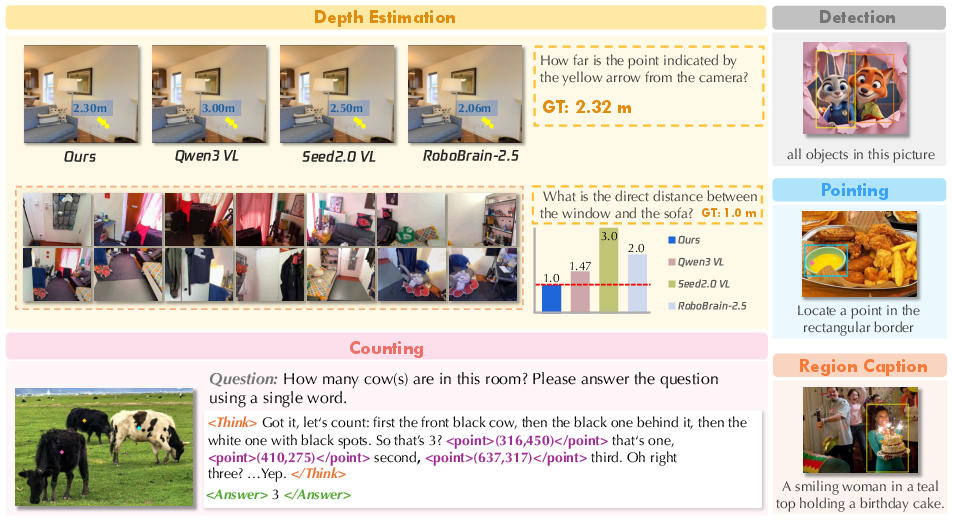
- Visual perception: object detection, depth (how far things are), and segmentation (drawing exact outlines of things).
- Embodied data: tasks a robot would do—like pointing at objects, understanding affordances (e.g., “this handle can be pulled”), drawing motion paths, judging what step comes next, and planning multi-step actions.
- Spatial understanding: 3D geometry, matching points across frames, measuring sizes and distances, and reasoning about where objects are relative to each other.
- General understanding: captions, math, reading documents, charts, and following complex instructions—so the models still have broad knowledge.
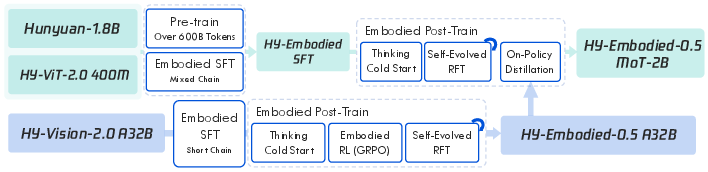
Training process (how they taught the models)
The training had several stages:
- Large-scale pre-training: Build the basics—align vision and language and learn physical-world cues.
- Mid-training: Focus more on embodied and spatial tasks to make the models better at agent-like work.
- Supervised fine-tuning: Give examples with step-by-step “Chain-of-Thought” solutions, so the model learns how to explain and think through problems.
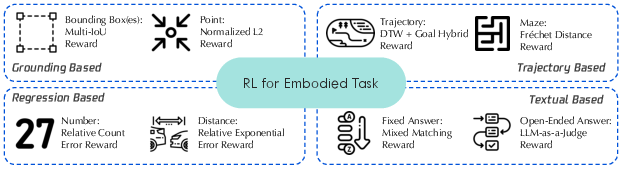
- Reinforcement learning (RL): Let the model try multiple answers and give it a “score” (reward) that matches the task. For example:
- Geometric tasks get graded by how close or overlapping the shapes are.
- Trajectories (paths) get graded by how similar the predicted path is to the correct one.
- Counts or multiple choice get exact-match scores.
- Open questions use a judge model to assess correctness.
- This is like practicing with feedback that says not just “right/wrong,” but “how close you are.”
- Iterative “self-evolving” training: The model generates many attempts, keeps the good ones with strong reasoning, and learns from them. This helps improve the quality of its thinking, not just its final answers.
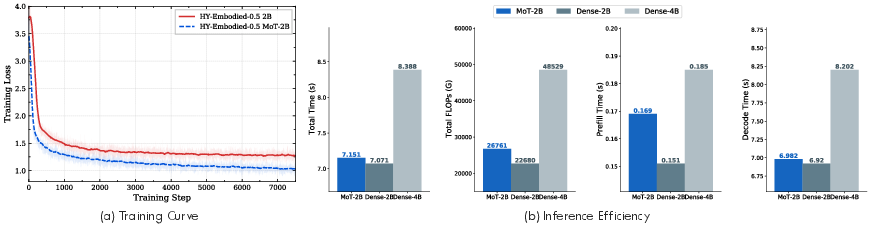
- Distillation from big to small: The big model acts like a teacher and transfers its skills to the smaller model, so the small one performs much better than it otherwise would while staying fast.
What did they find?
The models were tested on 22 different benchmarks covering:
- Visual perception,
- Spatial reasoning,
- Embodied understanding (things you’d need for real-world robot tasks).
Key results:
- The small MoT-2B model beat other similar-sized models on 16 out of 22 benchmarks and had a strong overall average, even outperforming some larger competitors.
- The large MoE-32B model reached top-tier performance, comparable to or better than frontier models like Gemini 3.0 Pro on these embodied-focused tests.
- In real robot control experiments, they used the VLM as a base to train a Vision-Language-Action (VLA) model. This VLA performed well in physical tests—showing the foundation models aren’t just good on paper, but also useful for real-world robot tasks.
Why this matters: It shows that carefully designed models and training can bridge the gap between “understanding images” and “doing things in the world.”
Why is this important?
- Better robot helpers: These models can help robots understand scenes more precisely and plan actions more reliably. That’s useful for home assistants, warehouse robots, or inspection drones.
- Safer and more dependable behavior: With better depth, geometry, and spatial reasoning, a robot is less likely to make mistakes like knocking things over or grabbing the wrong object.
- Efficient deployment: The small 2B model, boosted by the big teacher, can run on devices at the edge (on-robot), enabling faster, more private, and more reliable operation without needing a constant internet connection.
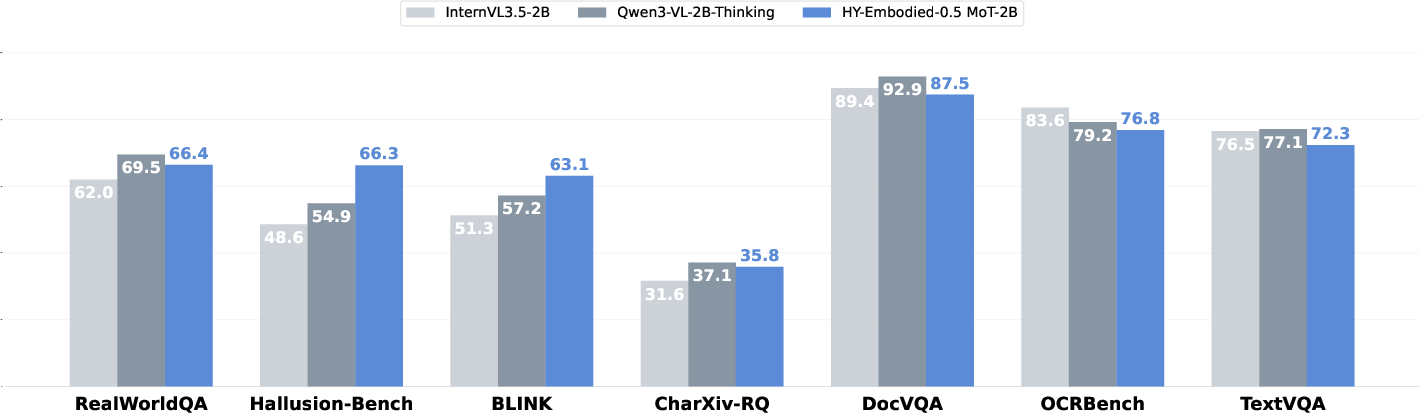
- Generalizable skills: The models can also handle regular vision-language tasks well, not just robotics, making them versatile.
In short, HY-Embodied-0.5 shows a practical path to turning advanced AI perception and reasoning into real-world action—bringing us closer to useful, trustworthy agents that can see, think, and do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research.
- Missing latency/throughput and memory profiles for both
MoT-2B(edge) andMoE-A32B(server) across representative hardware; no real-time guarantees (e.g., ms/frame at target resolutions), energy usage, or quantization results for on-device deployment. - No ablations isolating the contributions of Mixture-of-Transformers (modality-specific QKV/FFN), bidirectional attention for vision tokens, visual next-code prediction, global loss on latent tokens, and visual latent tokens; unclear trade-offs with language capability, cross-modal alignment, and training stability.
- Insufficient detail on the
MoE-A32Brouting mechanism (token vs. expert-level gating, load-balancing losses, expert utilization statistics, dropout/aux losses) and how these choices affect scaling efficiency, inference cost, and stability. - Visual next-code prediction uses a 2k codebook and 8×8 patch compression, but the effect of codebook size, reconstruction fidelity, and compression ratio on fine-grained perception and downstream spatial tasks is unquantified; no robustness analysis to high-frequency details.
- Visual latent tokens: number per image/video frame, dimensionality, and placement strategy are not specified; unclear whether they persist at inference, how they scale to videos/multi-image inputs, and whether they induce train–test distribution shifts.
- Bidirectional attention for vision tokens within an autoregressive decoder is presented without a discussion of training/inference consistency, potential leakage across interleaved modalities, or implications for streaming/online perception.
- Temporal modeling remains implicit (frames as separate “visual elements”); no dedicated temporal encoder, memory, or recurrence for long-horizon video; open questions on scaling to multi-minute egocentric streams, memory limits, and temporal credit assignment.
- On-policy distillation details are under-specified (teacher prompting, sampling temperature, response formats, KL vs. regression objectives, use of
\think/\no_thinktokens); unclear how much of the large model’s capability transfers toMoT-2Band where it fails. - Reinforcement learning lacks KL-regularization-to-reference or other safety constraints; risk of reward hacking and distributional drift is not quantified; no evidence of retention of low-level perception skills after RL.
- LLM-judged rewards for open-ended tasks are vulnerable to judge bias and instability; no calibration or agreement analysis with human raters; no adversarial/counterfactual tests to detect systematic reward exploitation.
- Iterative rejection-sampling fine-tuning (RFT) uses an unspecified “stronger teacher” to score reasoning quality; the sensitivity to teacher choice, risk of homogenizing reasoning styles, and impact on diversity/generalization remain untested.
- Data provenance and licensing are not detailed; extensive use of auto-labeled and VLM-generated annotations introduces unknown noise/bias rates; no audits of label error, demographic/scene bias, or their downstream safety impact in embodied settings.
- Potential benchmark contamination is unaddressed (deduplication against the 22 benchmarks and robot test tasks); no reporting of overlap rates or safeguards against leakage from large in-house corpora.
- Camera intrinsics normalization and coordinate normalization to
[0, 1000]may introduce discretization bias; robustness to diverse cameras/lenses and calibration errors is not evaluated; no zero-shot calibration or cross-camera generalization study. - Affordance and grounding data partly rely on synthetic instructions and VLM-generated prompts; realism and linguistic diversity versus real user instructions are not validated (e.g., user studies or human-authored test sets).
- Spatial-centric datasets (ScanNet family, ARKitScenes) have strong indoor biases; generalization to outdoor, industrial, metallic/reflective surfaces, transparent objects, and severe clutter is not evaluated.
- Modality coverage is limited to vision-language; no integration of proprioception, force/torque, tactile, IMU, or audio—modalities that are critical for embodied manipulation and safety.
- Safety for real-world robotics is not addressed (uncertainty estimation, action safety filters, limit-aware planning, intervention policies, and fail-safe behaviors); no risk assessments or safety benchmarks.
- Real-world VLA results lack basic experimental details (tasks, success rates, resets, sample efficiency, generalization to unseen objects/scenes, number of trials, statistical significance), hindering reproducibility and fair comparison.
- Evaluation emphasizes offline QA-style benchmarks; limited or no closed-loop, interactive embodied benchmarks (e.g., ALFRED, Habitat, BEHAVIOR, ManiSkill) to measure planning and control under action feedback.
- Long-context handling is claimed (up to 32k tokens) but scaling behavior with many frames/images, memory–accuracy trade-offs, and alternatives (sliding windows, retrieval, compression) are not analyzed.
- Edge deployment claims are not substantiated with quantization/sparsity results (INT8/INT4, structured pruning), thermal constraints, or battery-life measurements on target devices.
- Robustness to common real-world shifts (occlusions, illumination changes, motion blur, sensor noise, weather, adversarial patches) and uncertainty calibration in spatial predictions is not reported.
- No qualitative or quantitative failure analysis (error taxonomy for spatial reasoning, grounding, counting, trajectory prediction) to inform targeted improvements and safety mitigations.
- Open-sourcing notes omit whether the specialized pretraining/mid-training data will be released; without data access, pretraining-level reproduction and independent validation are infeasible.
- Action-space interfaces are under-specified: how predicted coordinates, boxes, or waypoints are mapped to robot frames and control stacks (kinematics, calibration, unit consistency, latency compensation) is not described.
- MoT decouples vision and language processing but the mechanisms for cross-branch fusion, information flow, or potential representation drift are not analyzed; alternatives (cross-attention bridges, adapters) remain unexplored.
- Video sampling policy (frame rate, stride, selection) and its effect on temporal reasoning and performance are not reported; no ablations on frame density vs. accuracy/latency.
- Spatial hallucination mitigation (e.g., geometric self-checks, uncertainty-aware decoding, self-consistency) is not addressed, despite known issues in VLMs for counting/pointing/grounding.
- Aggregate benchmark scores are reported without confidence intervals, variance across seeds, or statistical significance; per-task gains and failure cases are not decomposed to guide research focus.
Practical Applications
Immediate Applications
The following applications can be piloted or deployed now using the open-source HY-Embodied-0.5 models (MoT-2B for edge; MoE-32B for higher-accuracy cloud) and the released training/evaluation pipeline.
- Robot bin-picking and kitting with fine-grained grounding (Robotics, Manufacturing)
- What: Improve grasp target selection, part identification, and pose-aware picking using 2D/3D detection, segmentation, depth, and affordance cues.
- Tools/workflows: HY-Embodied MoT-2B on robot controller; ViT 2.0 encoder; grounding + affordance QA prompts; VLA policy fine-tuned on local demos; ROS2 node wrapping.
- Assumptions/dependencies: Calibrated RGB/RGB-D camera; robot stack integration (ROS2/MoveIt); domain-tuned prompts; safety interlocks.
- Assembly line quality control and defect triage (Manufacturing)
- What: Count components, localize defects, verify placement tolerances via measurement and segmentation tasks.
- Tools/workflows: Segmentation and measurement QA heads; on-prem inference; multi-camera QA verification using task-aware rewards for partial credit.
- Assumptions/dependencies: Stable lighting; annotated golden references; acceptance criteria thresholds; SOP alignment.
- Warehouse shelf auditing and inventory counting (Retail, Logistics)
- What: Accurate counting, missing item detection, and placement validation using pointing/counting and configuration reasoning.
- Tools/workflows: Handheld or robot-mounted cameras; on-device MoT-2B; simple prompt templates; API returning counts/locations.
- Assumptions/dependencies: SKU recognition mapping; planogram data; occlusion handling; periodic calibration.
- Mobile manipulation for pick-and-place and tool use (Robotics)
- What: Grounding objects, predicting affordance points, and generating short waypoint trajectories from images and instructions.
- Tools/workflows: VLA trained on in-house demos using the provided RL+RFT recipe; trajectory-based rewards (DTW/Fréchet); on-policy distillation to edge model.
- Assumptions/dependencies: Safe motion planner; collision models; task-specific tuning; real-world demonstrations.
- AR-guided measurement and maintenance assistance (AR/VR, Field Service)
- What: On-device room area estimation, distance/size measurement, and spatial relation guidance for technicians.
- Tools/workflows: Smartphone/tablet app embedding MoT-2B; prompts for measurement tasks; overlay visual markers.
- Assumptions/dependencies: Camera calibration; acceptable accuracy thresholds; UI for ambiguity resolution.
- Drone and robot inspection triage (Energy, Infrastructure, Construction)
- What: Localize and rank issues (corrosion, cracks, missing parts) and measure distances/clearances; generate waypoint suggestions.
- Tools/workflows: Edge/cloud hybrid with MoE-32B for adjudication; geometry/configuration QA; trajectory scoring rewards.
- Assumptions/dependencies: Flight safety constraints; high-res imagery; ground truth sampling for calibration.
- Indoor navigation assistance and scene understanding (Smart Home, Retail, Hospitality)
- What: Locate objects, describe spatial layout, and provide relative direction (left/right/front/back) to guide users or robots.
- Tools/workflows: Spatial-centric QA (correspondence, configuration, geometry); voice + camera UI; optional AR overlays.
- Assumptions/dependencies: Up-to-date scene view; egocentric camera; latency targets for interactive guidance.
- Assistive perception for low-vision users (Healthcare, Accessibility)
- What: Read labels, count pills, localize personal items, and describe scene affordances safely.
- Tools/workflows: On-device MoT-2B for privacy; OCR/chart/document parsing prompts; conservative uncertainty handling.
- Assumptions/dependencies: Regulatory and privacy policies; fallback to human support; calibrated confidence thresholds.
- Lab and classroom robotics education (Education, Academia)
- What: Teach embodied perception, planning, and reward design using the open pipelines and datasets.
- Tools/workflows: Course labs with RL (GRPO) rewards (grounding/regression/trajectory/textual); RFT iterations; open benchmarks.
- Assumptions/dependencies: Compute access (single GPU for 2B); safe educational robot kits; curated tasks.
- GUI and device control with camera feedback (Software, RPA)
- What: Agents that visually ground UI elements and sequence actions with trajectory-like plans for device interactions.
- Tools/workflows: General VLM data + spatial grounding prompts; “think/no_think” prompting for short/long reasoning chains.
- Assumptions/dependencies: Consistent UI layouts; sandboxed execution; accessibility layer integration.
- Construction progress monitoring and site measurement (AEC)
- What: Count installed components, verify spatial relations, estimate room areas, and flag deviations from plans.
- Tools/workflows: Measurement/configuration QA; periodic scans with handheld cameras; reporting dashboards.
- Assumptions/dependencies: Reference BIM/plan data; controlled capture routes; tolerance definitions.
- Security/patrol event triage with partial credit scoring (Security)
- What: Detect spatial anomalies and rank concerns; use dense geometric rewards to avoid all-or-nothing outputs during training.
- Tools/workflows: Cloud MoE-32B for complex scenes; patrol robot cameras; graded alerts.
- Assumptions/dependencies: Privacy-compliant processing; human-in-the-loop escalation; environment-specific calibration.
- Data curation and weak-labeling at scale (Cross-sector ML Ops)
- What: Use the paper’s automated annotation pipeline (VLM + SAM + teacher verification) to bootstrap detection/grounding datasets.
- Tools/workflows: Annotation scripts; quality judges; normalization to unified formats (e.g., 0–1000 coords).
- Assumptions/dependencies: Teacher VLM availability; sampling policies; QA budget for spot checks.
- Benchmarking and evaluation of embodied capabilities (Academia, Policy)
- What: Adopt the 22-benchmark suite and reward taxonomies for standardized capability assessment across perception, reasoning, and planning.
- Tools/workflows: Open evaluation code; reward templates (IoU, Chamfer, DTW, regression); result reporting.
- Assumptions/dependencies: Replicable test sets; agreed scoring thresholds; publication of evaluation protocols.
Long-Term Applications
These opportunities require further research, integration, or certification (e.g., broader data coverage, higher reliability, scaling, or regulatory approval).
- General-purpose home robots with long-horizon autonomy (Robotics, Consumer)
- What: Robots that plan, manipulate, clean, and fetch across diverse households using robust spatial/dynamics understanding and iterative self-evolving training.
- Dependencies: Reliable grasping/manipulation, lifelong learning, robust safety; enriched real-world datasets; low-latency on-device compute.
- Language-driven industrial cobots that learn new tasks on the fly (Manufacturing)
- What: Natural-language instruction to teach new assembly or inspection tasks; on-policy distillation from cloud MoE to edge units across fleets.
- Dependencies: Safe task generalization; line changeover procedures; certification for human-robot collaboration.
- Surgical and interventional robotics with vision-language planning (Healthcare)
- What: Tool tracking, tissue affordance reasoning, and step-wise planning in minimally invasive procedures.
- Dependencies: Medical-grade reliability; sterilization and latency constraints; FDA/CE approvals; extensive domain-specific datasets.
- Autonomous vehicles and mobile robots with unified spatial reasoning (Transportation, Logistics)
- What: Integrate spatial-centric depth/configuration/dynamics reasoning with multi-sensor stacks for planning and prediction.
- Dependencies: Sensor fusion beyond monocular vision; safety validation; real-time guarantees; adverse-condition robustness.
- Disaster response and search-and-rescue robots (Public Safety)
- What: Robust perception and planning in unstructured, dynamic environments with partial observability.
- Dependencies: Extreme generalization; fault tolerance; ruggedized hardware; human-robot teaming protocols.
- Construction and assembly robots for complex tasks (AEC, Manufacturing)
- What: On-site robots capable of measurement, alignment, and multi-step assembly guided by spatial reasoning and planning.
- Dependencies: Tolerance-centric training; high-precision localization; integration with BIM and site logistics.
- City-scale digital twins with embodied agents (Smart Cities, Energy)
- What: Agents that reason about infrastructure states, plan maintenance, and schedule inspections using geometric and configuration reasoning.
- Dependencies: Standardized data pipelines; privacy-preserving operations; interoperability with asset management systems.
- Personal AR assistants with continuous spatial cognition (Consumer, Enterprise)
- What: Always-on AR agents that measure spaces, locate items, and guide multi-step tasks in real time.
- Dependencies: Efficient, power-aware edge inference; reliable egomotion; privacy constraints; UI/UX maturity.
- Natural-language “programming” of warehouses and factories (Logistics, Manufacturing)
- What: Supervisors specify goals; embodied foundation model decomposes into grounded actions and trajectories for fleets.
- Dependencies: Robust multi-robot coordination; safety certification; conflict resolution; standardized APIs.
- Self-supervised fleet learning via on-policy distillation (Robotics Ops)
- What: Continuous model improvement from operational data; cloud-to-edge distilled updates verified with graded rewards.
- Dependencies: Data governance; validation sandboxes; rollback mechanisms; versioned deployment.
- Standardized regulatory frameworks for embodied AI (Policy)
- What: Adopt reward taxonomies and benchmark suites to define capability thresholds and safety margins for certification.
- Dependencies: Multi-stakeholder consensus; incident reporting standards; third-party test labs.
- Edge-first embodied AI chips and software stacks (Semiconductors, Software)
- What: Hardware and runtimes optimized for modality-adaptive MoT and latent-token flows in real-time VLM/VLA workloads.
- Dependencies: Co-design with model architectures; compiler/runtime support; vendor ecosystem buy-in.
Notes on Feasibility and Cross-Cutting Dependencies
- Data and domain shift: Many applications require domain adaptation with in-situ data and prompts; the paper’s automated labeling and teacher verification pipeline helps but still needs human QA.
- Sensors and calibration: Performance depends on camera quality, calibration, and sometimes depth inputs; geometric tasks benefit from accurate intrinsics/extrinsics.
- Compute and deployment: MoT-2B enables edge deployment on devices like Jetson-class GPUs; MoE-32B suits cloud or high-end on-prem for complex reasoning.
- Safety and compliance: High-stakes domains (healthcare, AV, HRC) require rigorous validation, certification, and conservative fail-safes.
- Integration: Effective use typically requires ROS2/planner integration, trajectory execution stacks, and UI/UX for human-in-the-loop oversight.
- Privacy and security: On-device inference reduces data exposure; policies for storage, auditing, and access control remain essential.
- Evaluation and monitoring: Adopt task-aware reward designs and the paper’s heterogeneous benchmark approach for ongoing QA and model health tracking.
Glossary
- Affordance: The actionable possibilities an object or environment offers to an agent, often conditioned on the agent’s capabilities and instructions. "Affordance prediction integrates visual grounding with user instructions, demanding a higher level of task comprehension."
- Asymmetric clipping: A reinforcement learning stabilization technique that clips importance ratios with different lower and upper bounds to reduce training instability. "we adopt asymmetric clipping with an effective importance-ratio range of , which we find more stable than a symmetric clipping rule in long-chain multimodal RL."
- Bidirectional attention: An attention pattern allowing tokens to attend to both past and future tokens, suitable for non-causal modalities like images. "we find that bidirectional attention is more beneficial for visual modeling,"
- Camera intrinsics and extrinsics: Parameters describing the internal characteristics of a camera (intrinsics) and its position and orientation in space (extrinsics), enabling coordinate transformations. "where camera intrinsics and extrinsics enable precise projection between coordinate systems."
- Chain-of-Thought (CoT): A training/inference approach that elicits or learns step-by-step intermediate reasoning traces before producing the final answer. "we construct Chain-of-Thought (CoT) trajectories via a human-model collaborative pipeline."
- Chamfer distance: A geometric metric measuring the average closest-point distance between two point sets, used to evaluate spatial predictions like trajectories or shapes. "such as IoU, Hungarian-matched IoU, normalized point distance, and Chamfer distance, which provide graded supervision for localization and fine-grained perception."
- Codebook: A discrete set of learned codes used to quantize or discretize continuous visual features for supervision or compression. "This representation features a codebook size of 2k and compresses every 88 image patch into a single discrete code."
- Cosine learning rate decay: A scheduling strategy where the learning rate follows a cosine curve over training to gradually reduce step size. "while introducing a cosine learning rate decay."
- Ego-motion: The motion of the camera (or agent) itself relative to the environment, as opposed to object motion. "including both camera ego-motion and object movement."
- Embodied agents: AI systems that perceive, reason, and act in the physical world, often via sensors and actuators. "foundation models specifically designed for real-world embodied agents."
- Feed-Forward Network (FFN): The position-wise multilayer perceptron sublayer inside Transformer blocks that processes token representations. "we duplicate the Feed-Forward Network (FFN) and QKV parameters of the LLM,"
- Full-attention mechanism: An attention configuration (non-causal, unmasked) that allows all tokens to attend to each other, used here for visual tokens. "We further design an independent full-attention mechanism and apply auxiliary visual supervision for the vision component"
- Gradient checkpointing: A memory-saving technique that trades extra computation for reduced activation memory by recomputing intermediate results during backpropagation. "such as gradient checkpointing and parameter/optimizer offloading"
- GRPO: A reinforcement learning objective using group-relative advantages computed over multiple sampled responses to stabilize policy updates. "We optimize the model in the RL stage with a GRPO-based objective"
- Hungarian-matched IoU: Intersection-over-Union computed after assigning predicted and ground-truth items using the Hungarian algorithm, providing a fair matching for evaluation. "such as IoU, Hungarian-matched IoU, normalized point distance, and Chamfer distance, which provide graded supervision for localization and fine-grained perception."
- Intersection-over-Union (IoU): A standard metric for overlap between predicted and ground-truth regions, defined as the area of intersection divided by the area of union. "such as IoU, Hungarian-matched IoU, normalized point distance, and Chamfer distance, which provide graded supervision for localization and fine-grained perception."
- Latent thinking: The use of hidden intermediate “thought” representations or tokens that guide reasoning without being part of the final exposed output. "inspired by recent progress in latent thinking and vision registers"
- Mixture-of-Experts (MoE): An architecture with multiple expert subnetworks where a gating mechanism routes tokens to a subset of experts for efficient capacity scaling. "and a powerful Mixture-of-Experts (MoE) model (32B activated / 407B total parameters) engineered to tackle complex visual perception and embodied reasoning tasks."
- Mixture-of-Transformers (MoT): An architecture variant that provides separate or specialized Transformer components (e.g., per modality) to improve efficiency and performance. "we adopt a Mixture-of-Transformers (MoT) architecture to enable modality-specific computing."
- Modality-adaptive computation: Dynamically allocating different parameters or attention patterns depending on the input modality (e.g., vision vs. text). "we adopt a Mixture-of-Transformers architecture to enable modality-adaptive computation."
- Native-resolution Vision Transformer (ViT): A ViT configuration that processes images at their original resolution without aggressive resizing, preserving fine details. "we train an efficient yet powerful native-resolution Vision Transformer (ViT) optimized for edge-device deployment."
- Normalized longest common subsequence: A sequence similarity measure that scores partial order agreement between predicted and target sequences after normalization by length. "e.g., normalized longest common subsequence."
- On-policy distillation: Knowledge distillation where the student learns from teacher outputs generated on the student’s own sampled inputs (policy), reducing distribution shift. "we employ on-policy distillation to transfer the advanced capabilities of the large model to the smaller variant,"
- Parameter/optimizer offloading: Moving parameters and/or optimizer states to CPU or other memory to reduce GPU memory usage during training. "such as gradient checkpointing and parameter/optimizer offloading"
- PPO: Proximal Policy Optimization, a policy-gradient RL algorithm using a clipped surrogate objective to stabilize updates. "by matching the PPO mini-batch size to the rollout batch size."
- QKV: The query, key, and value projections used in Transformer attention mechanisms to compute attention weights and outputs. "modality-specific QKV and FFN layers,"
- Rejection sampling fine-tuning (RFT): A post-training method that filters and fine-tunes on high-quality or successful sampled trajectories to improve reasoning quality. "we introduce an iterative self-evolving training paradigm based on rejection sampling fine-tuning (RFT)."
- Supervised fine-tuning (SFT): Post-training on labeled data using standard supervised objectives (e.g., cross-entropy) to refine model capabilities. "rejection sampling supervised finetuning (SFT)"
- Visual grounding: Linking language expressions (e.g., referring phrases) to specific visual entities or locations in an image. "Visual grounding provides the foundational spatial guidance required for embodied execution."
- Vision registers: Special learnable tokens or slots used within a Transformer to store and manipulate visual information explicitly. "inspired by recent progress in latent thinking and vision registers, we append dedicated visual latent tokens"
- Vision-Language-Action (VLA): A model paradigm that maps visual and language inputs to action outputs for control in embodied tasks. "to train an effective Vision-Language-Action (VLA) model,"
- Vision-LLMs (VLMs): Multimodal models that jointly process visual and textual inputs for understanding and reasoning tasks. "To bridge the gap between general Vision-LLMs (VLMs) and the demands of embodied agents,"
- Visual latent tokens: Learnable tokens appended to visual input sequences to capture global or compressed visual semantics that assist downstream reasoning. "we append dedicated visual latent tokens to the end of each visual input sequence."
- Visual next-code prediction task: An auxiliary objective where the model predicts the next discrete visual code (from a codebook) for improved visual supervision. "we introduce a visual next-code prediction task to better optimize the vision branch in the MoT and provide stronger supervision signals."
Collections
Sign up for free to add this paper to one or more collections.

