- The paper introduces MolmoAct, a novel action reasoning model that integrates perception, planning, and control to enable robust and explainable spatial reasoning in robotics.
- It employs a structured three-stage pipeline using depth-aware perception tokens, visual reasoning trace tokens, and discretized action tokens for enhanced optimization and fine-tuning.
- Experimental results show significant improvements including a 6.3% gain on LIBERO tasks and a 23.3% boost in out-of-distribution scenarios, underscoring its real-world applicability.
"MolmoAct: Action Reasoning Models that can Reason in Space" (2508.07917) - An Overview
The paper "MolmoAct: Action Reasoning Models that can Reason in Space" focuses on advancing robotic foundation models by integrating perception, planning, and control through a structured three-stage pipeline. MolmoAct, the core framework introduced, aims to achieve both robust performance and high explainability by employing a novel action reasoning model that excels in spatially grounded reasoning, as illustrated in Figure 1.
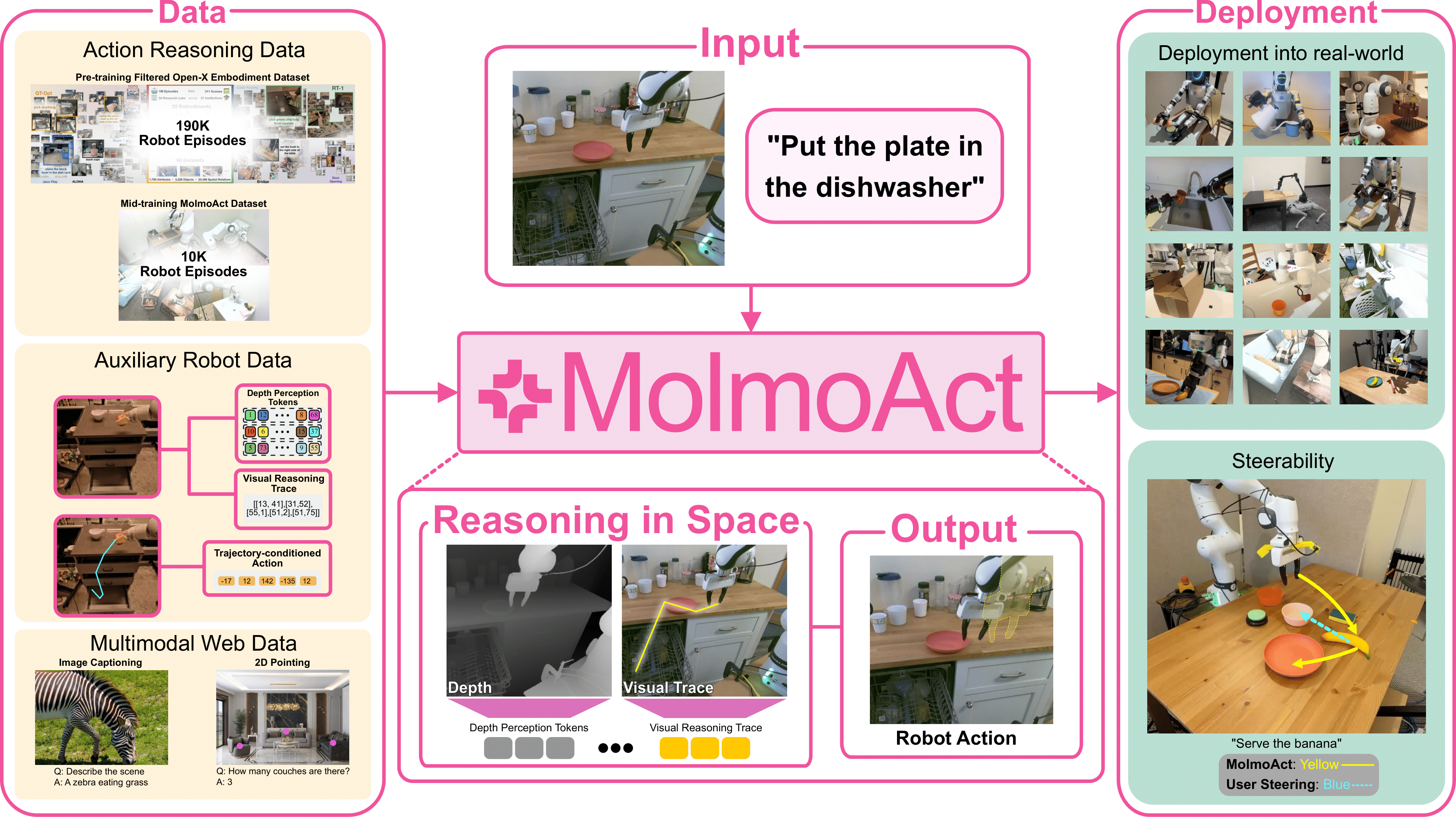
Figure 1: Overview of MolmoAct's architecture demonstrating the connection between language instructions, spatial reasoning, and robot actions.
MolmoAct Architecture
The MolmoAct model builds upon the Multimodal Open LLM (Molmo), designed to enhance the capabilities of VLAs by extending structured reasoning beyond visual and linguistic contexts into the action domain. This is done using a three-stage pipeline that transforms perceptual inputs and language instructions into actionable outputs. The architecture employs depth-aware perception tokens, visual reasoning trace tokens, and action tokens to navigate and interact within a 3D environment.
The training regimen for MolmoAct utilizes a two-stage process consisting of pre-training and post-training, as depicted effectively in Figure 2.
Figure 2: The detailed training process of MolmoAct across two stages: Pre-training and Post-training phases.
In the pre-training phase, the vision-language backbone, based on Molmo, learns from a data mixture comprising 26.3 million samples. This stage ensures robust performance and efficient fine-tuning, reducing training time compared to closed-source models like GR00T N1 by over five times. The action is formulated as a vision-language sequence modeling task, leveraging action tokenization, and discretizing action dimensions into 256 bins which closely preserve the ordinal structure and improve optimization convergence times significantly.
Data Curation and Mid-training
A significant contribution of the paper is the development of the MolmoAct Dataset, which enhances MolmoAct's generalization and provides a set of high-quality robot trajectories for training (Figure 3). This dataset is pivotal during the mid-training stage, in which MolmoAct is refined using 2 million specialized samples, which improves its generalization and action steering capabilities.
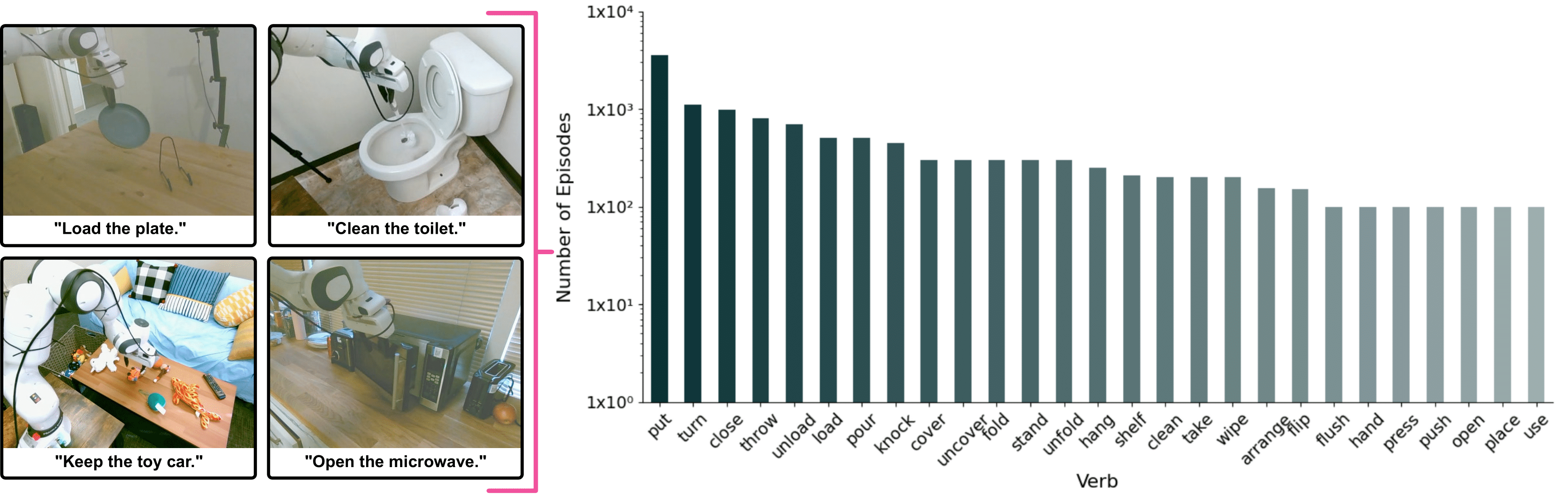
Figure 3: Examples and verb distribution in the MolmoAct Dataset, highlighting a variety of tasks and the distribution of commonly used verbs.
Steering and Explainability
MolmoAct introduces an innovative feature: steering action execution through visual reasoning traces. This dual-modality interface leverages explicit intermediate representations that provide users with a more direct and less ambiguous means to guide robotic behavior (Figure 4).
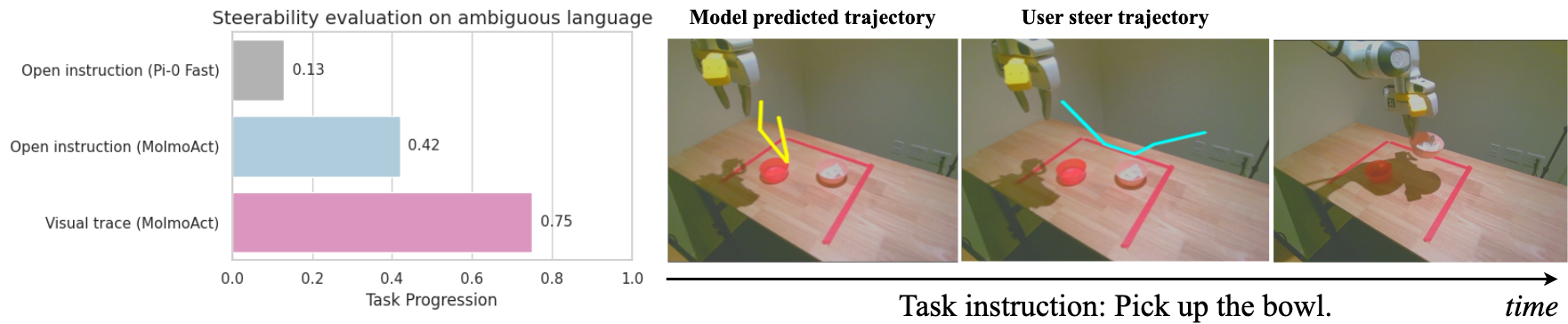
Figure 4: MolmoAct's steerability with visual trace steering demonstrates high success rates in task completion.
Unlike language-only control systems, MolmoAct utilizes depth perception tokens ($V_{\mathrm{depth}$) and visual reasoning trace tokens (τ), which together form a comprehensive spatial and temporal representation of the task environment. By processing instructions in this structured manner, the model achieves precise, explainable action sequences essential for tasks that require spatial interaction (Figure 5).
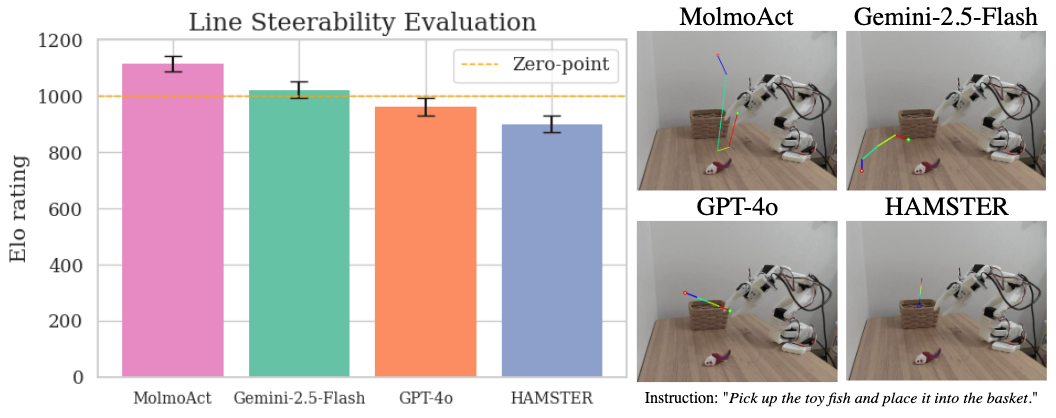
Figure 5: Line steerability evaluation across models, demonstrating MolmoAct’s superior performance with error bars indicating standard error.
Experimental Evaluation
The experimental evaluation performed in both simulation and real-world settings demonstrates the efficacy of MolmoAct exceeding that of competitive benchmarks on datasets like LIBERO and SimplerEnv. Significant statistical performance improvements were recorded, particularly in tasks with more complex spatial reasoning requirements such as the LIBERO-Long task category where a notable 6.3% gain over the ThinkAct model was observed.
The mid-training phase with the MolmoAct Dataset yields an improvement of 5.5% on the general performance over the base model, a noteworthy enhancement (Figure 6).
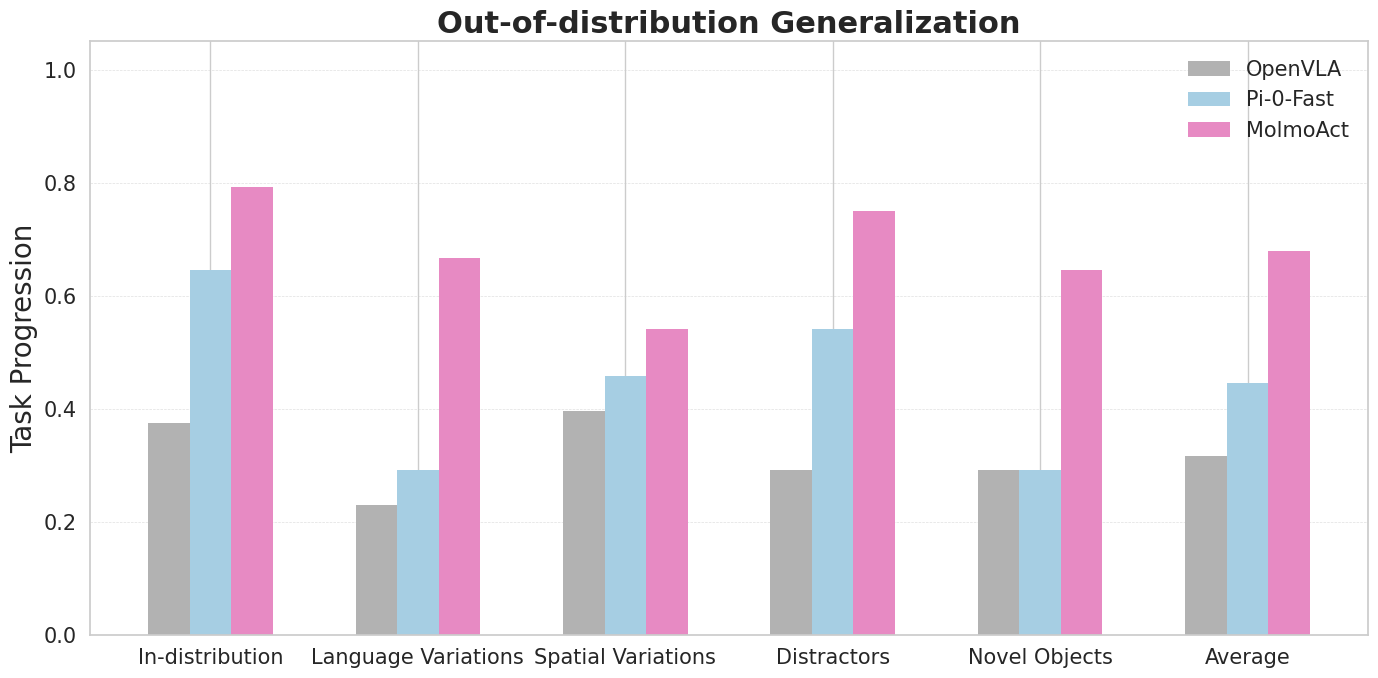
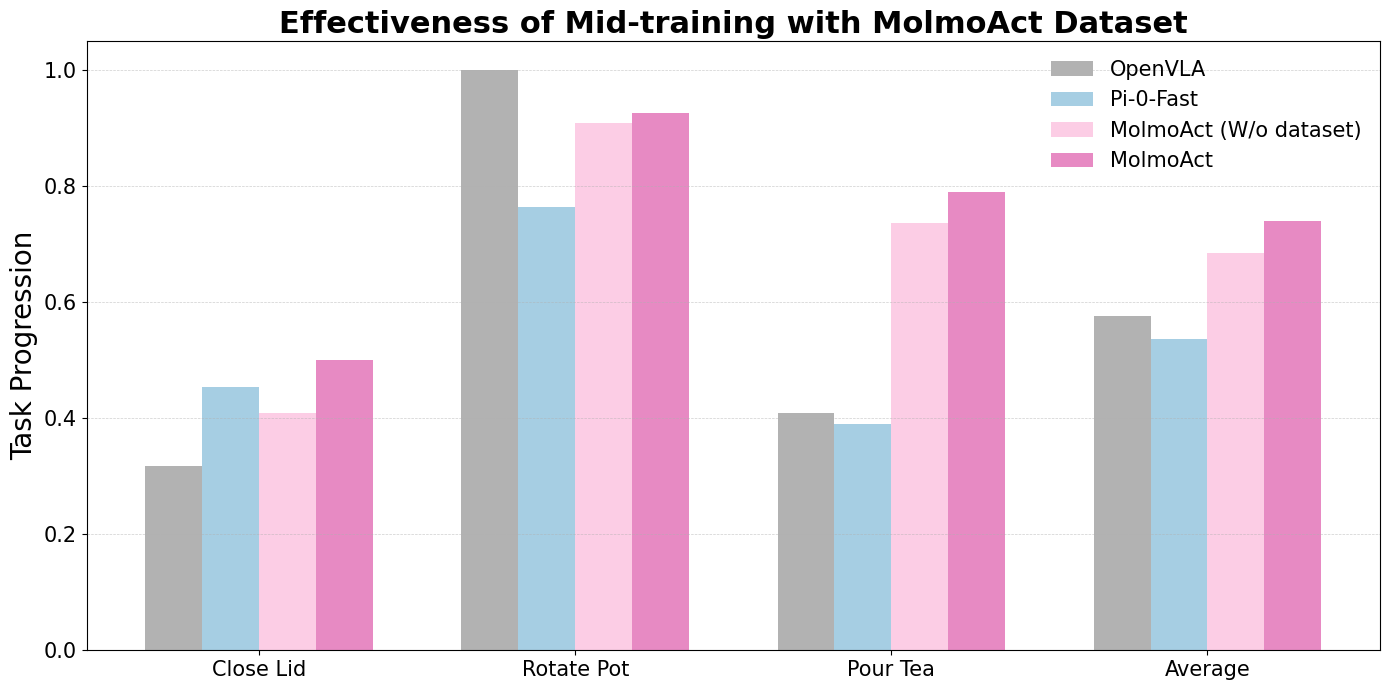
Figure 6: MolmoAct generalizes beyond training distributions.
The results also demonstrate MolmoAct's ability to outperform baselines in out-of-distribution scenarios with a 23.3% increase over other models. Besides, the model's effectiveness in adaptive and interactive scenarios, utilizing human-directed visual trace steering, suggests real-world adaptability and potential for expansive application in robotics (Figure 7).
Figure 7: MolmoAct outperforms competitors in both single-arm and bimanual real-world tasks.
Conclusion
MolmoAct is established as an effective and comprehensive action reasoning model for robotic applications, integrating visual and linguistic modalities with a novel spatial reasoning framework that allows for both explainable and steerable robotic behaviors. The open-source nature of MolmoAct, along with the release of all relevant data and model weights, represents an important contribution to the community, providing resources for future research in developing ARMs. The results highlight MolmoAct's strong zero-shot performance, efficient fine-tuning capability, and robust generalization across a diverse array of robotic tasks and scenarios. Future work may focus on enhancing
MolmoAct's depth perception to further augment its capacity for fine-grained robotic manipulation, thereby supporting more extensive and intricate real-world applications in AI-driven robotics.

