- The paper introduces GLMap, a novel dual-modality mapping system that integrates explicit 3D Gaussian geometry with language tokens for open-vocabulary navigation.
- It employs an analytical Gaussian estimator with curvature-aware merging to capture both instance-level and region-level spatial semantics accurately.
- Empirical evaluations demonstrate significant improvements in success rates and SPL on zero-shot ObjectNav and situated question answering tasks.
Multi-Scale Gaussian-Language Map for Zero-shot Embodied Navigation and Reasoning
Introduction
This work introduces the Multi-Scale Gaussian-Language Map (GLMap) for open-vocabulary zero-shot embodied navigation and situated reasoning. The core motivation is to provide a spatial memory that is both semantically and geometrically rich, explicitly aligned with the input modalities of large language- or multimodal models (LMs, VLMs, MLLMs). GLMap fuses metric spatial grids with multi-scale semantic units, in which each unit maintains both a natural language description and a 3D Gaussian visual representation. This dual-modality design addresses issues with existing maps that either lack geometric detail, miss multi-scale context, or are misaligned with the token-based interfaces of large models.
GLMap: Representation, Construction, and Update
Architecture and Semantic Granularity
GLMap is structured as a 2D grid, where each cell indexes instance-level and region-level semantic units. Instance units describe object-level entities and store both open-vocabulary language tokens and compact 3D Gaussian sets estimated directly from local point clouds. Region units aggregate instance sets and provide higher-level descriptions (e.g., functional areas, affordance contexts), omitting direct 3D Gaussian storage for memory efficiency. All semantic units are indexed globally, supporting cross-viewpoint consistency and spatial queries.
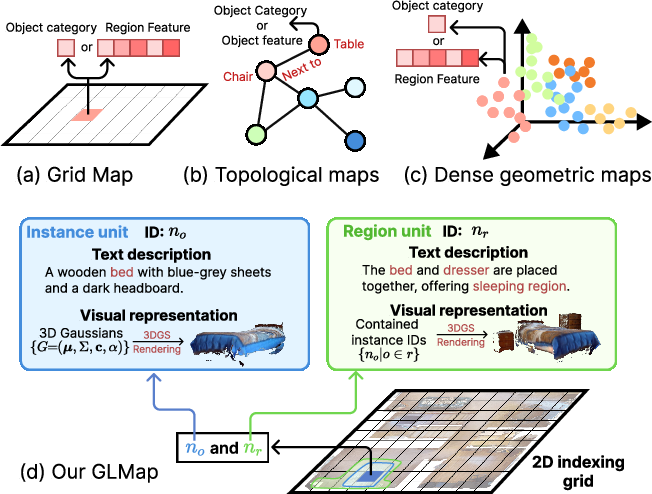
Figure 1: GLMap combines metric grid localization with explicit instance/region semantics and a dual-modality (language + rendered visual) interface, fully compatible with large pretrained models.
Analytical Gaussian Estimation
3D Gaussian representations are derived via an analytical estimator operating on dense point clouds, exploiting known camera intrinsics and per-frame depth. Voxels are used to aggregate neighborhood points; mean and covariance are directly computed to obtain G=(μ,Σ,c,α). To suppress spatial redundancy, a curvature-aware merge step fuses Gaussians where appropriate, preserving fine boundaries in high-curvature areas but aggressively merging in flat regions.
Incremental Update
GLMap is incrementally updated from online RGB-D observations. Instance segmentation leverages state-of-the-art open-vocabulary grounding and segmentation (GroundingDINO, MobileSAM). For each observation, language and geometry cues are matched with existing GLMap units using cosine similarity of text embeddings and Gaussian similarity (controlled by both appearance and spatial parameters). Instance and region units that match are merged, maintaining global ID consistency.
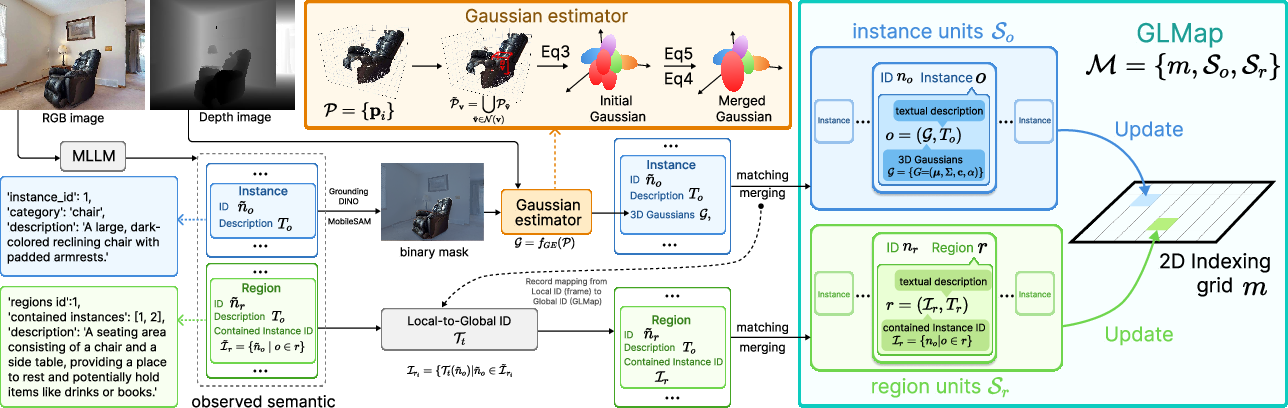
Figure 2: Incremental construction of GLMap by semantic parsing, geometric estimation, and merging based on cross-view semantic-geometric consistency.
Downstream Embodied Tasks and Large Model Integration
The GLMap design exposes explicit text and rendered visual representations per semantic unit, obviating the need for feature-to-token projection layers that are otherwise required for alignment with LMs/VLMs/MLLMs. This enables direct integration in diverse embodied reasoning settings:
- Zero-shot Object Navigation: GLMap supports open-vocabulary targets and guides navigation using value maps computed from semantic unit-to-goal similarity. The maximum-likelihood location in the value map determines frontier-based waypoints.
- Instance Navigation: Fine-grained localization is achieved by leveraging region semantics and compositional instances, capturing attribute and spatial relation cues beyond category labels.
- Situated Question Answering (SQA): GLMap enables situation grounding and spatial context extraction by projecting probabilities onto spatial grids (e.g., estimating if the agent faces a coffee table), synthesizing context views with 3D Gaussian Splatting, and prompting MLLMs with both rendered multi-view images and symbolic descriptions.
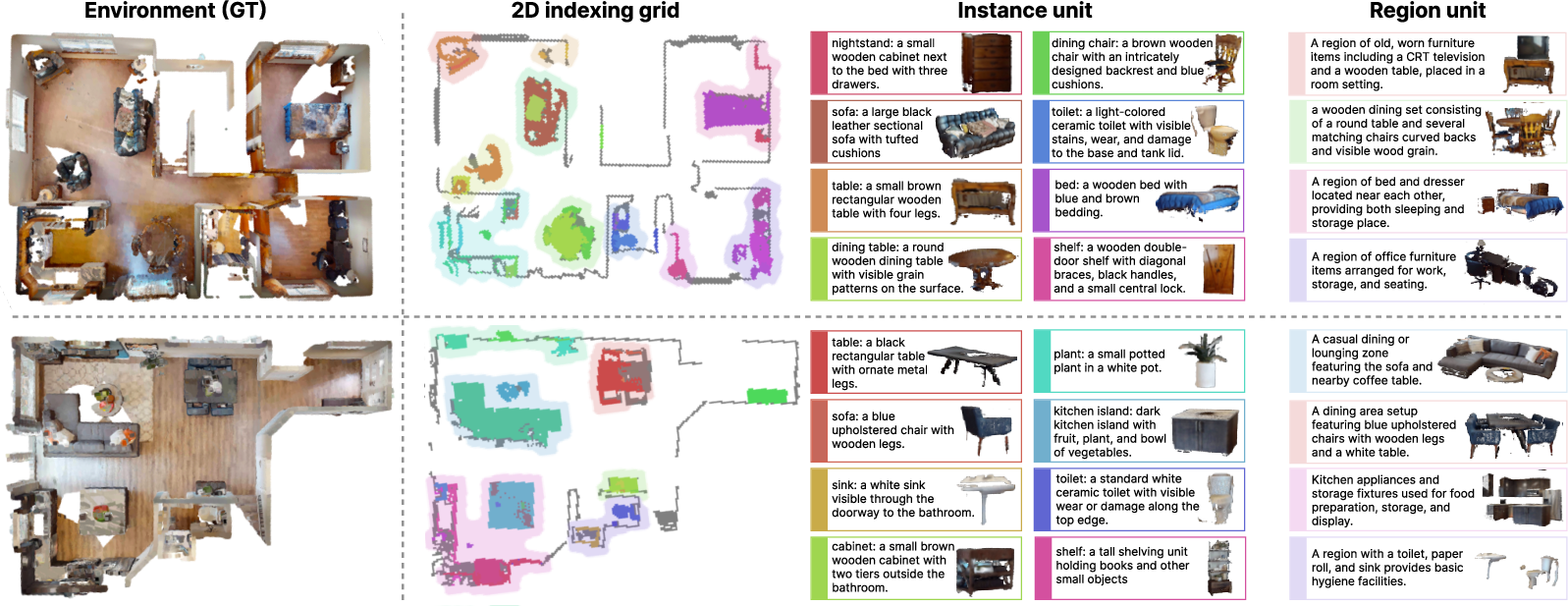
Figure 3: Visualization of GLMap components, showing high-fidelity spatial localization, instance attribution, and context-aware region aggregation, with both recorded language and rendered views.
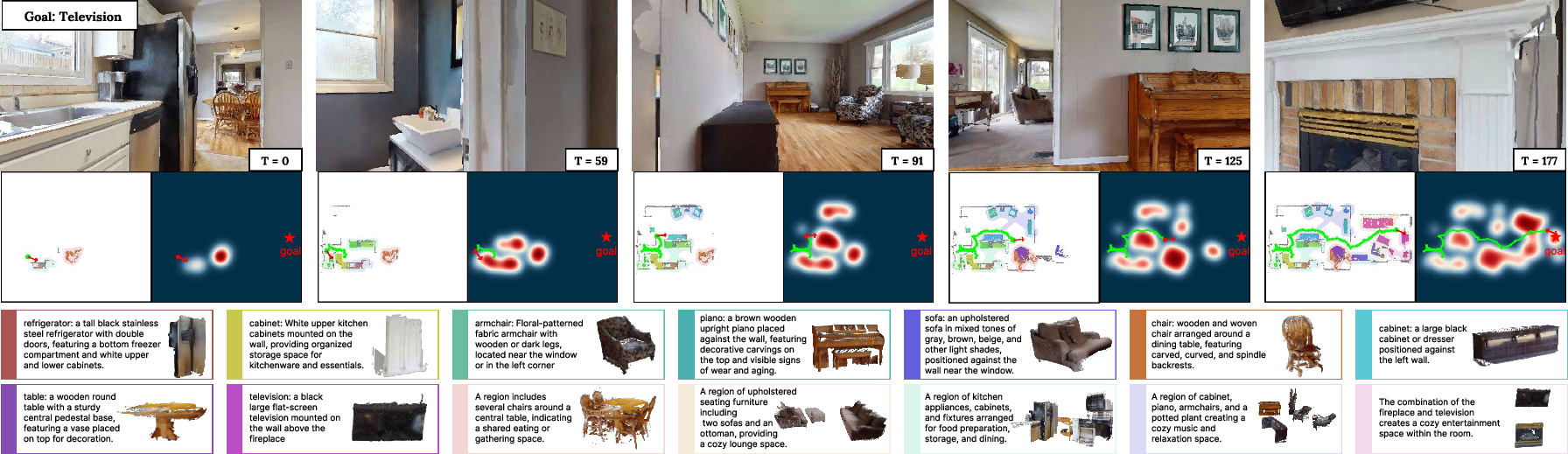
Figure 4: Use of GLMap in ObjectNav—the value map, computed by semantic matching, reflects predicted target likelihood over space.
Empirical Evaluation and Analysis
Alignment with Large Models
Empirical investigations demonstrate that the explicit, dual-modality interface of GLMap is natively compatible with LLM-, VLM-, and MLLM-based pipelines in zero-shot settings. Augmenting state-of-the-art baselines with GLMap yields consistent improvements without the need for alignment pretraining.
- LLM-based methods show a +9.6% SR improvement on ObjectNav when using GLMap for semantic context provision.
- VLM and MLLM pipelines benefit from GLMap’s explicit segmentation, region reasoning, and the rendered image interface, with strong gains in SPL and SQA accuracy.
- Ablation studies indicate that combining instance and region units is complementary, with each individually enhancing navigation and reasoning, and their union yielding the highest metrics.
Comparison to Prior Mapping Structures
GLMap outperforms topological, grid, and dense geometric map baselines across navigation and reasoning tasks. Key factors include (i) accurate spatial localization, (ii) preservation of instance boundaries and multi-level aggregation, and (iii) direct interface with large models via explicit language and image modalities. Unlike feature field or scene graph approaches, GLMap supports incremental updates, region-instance compositionality, and open-vocabulary adaptation, demonstrating robust generalization across datasets and tasks.
- On zero-shot ObjectNav in HM3D, GLMap achieves 62.7% SR and 33.7% SPL, surpassing alternative maps and large-model-based baselines by a substantial margin.
- On InstNav, GLMap’s integration of region relationships and rendered instance context leads to 22.5% SR, outperforming state-of-the-art methods that rely on implicit representations.
- For SQA, the explicit context and spatial queries enabled by GLMap yield 58.5% EM-1, outperforming both implicit feature and 2D-bev-based reference methods.
Implications and Future Directions
GLMap provides a scalable and modular representation for embodied agents, integrating robust spatial memory, compositional semantics, and a direct, large-model-friendly interface. The analytic Gaussian estimator is CPU- and memory-efficient, suited for real-time incremental updates. By abstracting environment understanding via instances and regions, GLMap supports advanced querying (e.g., affordance, relational reasoning), cross-task transfer, and compositional reasoning in zero-shot settings. These capabilities make it a strong foundation for advanced AI agents operating across embodied, interactive, and open-vocabulary environments.
Future research directions include:
- Joint learning and adaptation of region aggregation strategies or instance similarity metrics in an end-to-end fashion with downstream policies.
- Extending explicit dual-modality mapping to include affordance and function-centric semantics (e.g., tool-use, manipulation-oriented representations).
- Scaling the paradigm to multi-agent settings, long-horizon autonomy, and real-world physical deployment with explicit 3D and semantic grounding.
- Investigating hybridization with diffusion-based policies and dynamic memory optimization in large-scale embodied environments.
Conclusion
Multi-Scale Gaussian-Language Map (GLMap) represents a principled advance in spatial-semantic memory for embodied intelligence, unifying explicit geometry, multi-scale instance/region semantics, and dual-modality large-model interfaces. By addressing the limitations of prior mapping paradigms and demonstrating strong empirical improvement across a spectrum of zero-shot navigation and reasoning tasks, GLMap establishes itself as a robust platform for downstream embodied AI research and future large-agent systems (2605.01736).