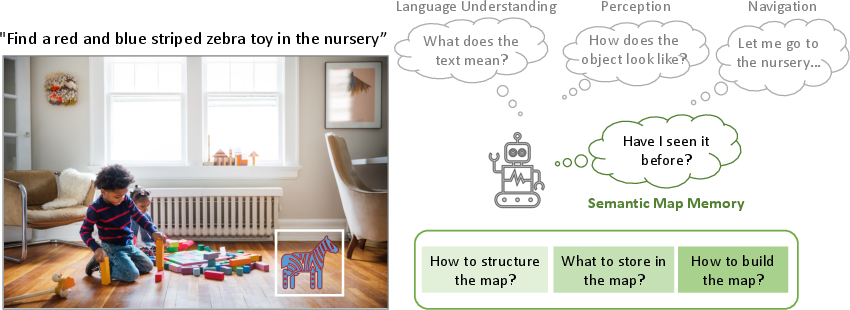
- The paper systematically categorizes map-building methods by evaluating spatial structures and semantic encoding techniques.
- It demonstrates how integrating vision-language models enables zero-shot generalization and flexible, open-vocabulary map representations.
- The survey identifies critical challenges such as scalability, real-time processing, and standardized evaluation, guiding future research.
Semantic Mapping in Indoor Embodied AI: Advances, Challenges, and Future Directions
Overview and Motivation
Semantic mapping is a foundational capability enabling embodied agents—including robots and virtual agents—to operate meaningfully in complex indoor environments. The surveyed paper systematically reviews semantic map-building methods for indoor embodied AI, centering on their structural representations (spatial grids, topological graphs, dense geometric, hybrid) and semantic encoding (explicit or implicit information). This perspective is distinct from prior work that mostly ties map-building to particular downstream applications, instead focusing on the underlying properties of map representations themselves. The survey further analyzes methodological connections to classical robotics, particularly SLAM, and underlines pressing challenges in scalability, efficiency, and evaluation.
Semantic maps encode not only spatial geometry, but also high-level semantic content such as object categories and affordances. This is crucial for agents tasked with long-horizon reasoning, planning, navigation, and manipulation in open-world or dynamic indoor environments. Building and maintaining such maps demand sophisticated solutions positioned at the intersection of vision, language, memory, and multimodal sensor fusion.
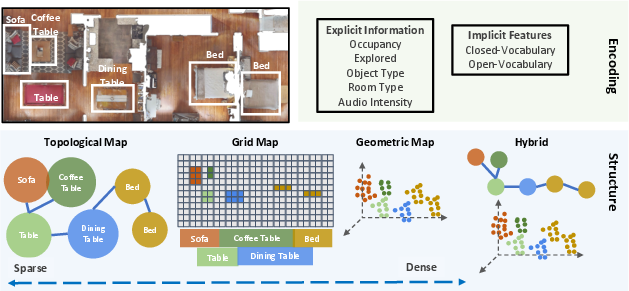
Figure 1: The survey categorizes semantic map-building methods in embodied agents based on their map structure (e.g., spatial grid, topological, dense geometric, or hybrid) and the nature of semantic encoding (explicit or implicit information).
Taxonomy of Semantic Map Representations
Map Structure: Spatial, Topological, Dense Geometric, Hybrid
The survey lays out a principled taxonomy based on map structure:
- Spatial grid maps are typically 2D or 3D discrete grids aligned with the physical environment, maintaining high-resolution spatial fidelity. They are widely used for navigation and spatial reasoning tasks, although they pose challenges in scalability and memory utilization.
- Topological maps abstract the environment as a graph, with nodes representing landmarks or important regions and edges denoting spatial or semantic relationships. These are memory-efficient and scale well with environment size but often lack detailed global context.
- Dense geometric maps store semantic and geometric information at each 3D point (as in point clouds or Gaussian splats), offering the most spatial detail and supporting per-point semantic reasoning; they enable open-vocabulary, multi-task functionality but face high memory and computational costs.
- Hybrid maps attempt to combine the strengths of multiple structures, e.g., using a topometric approach with both grid and landmark-based representations. Such combinations can support spatially precise planning while enabling abstract, semantic reasoning.
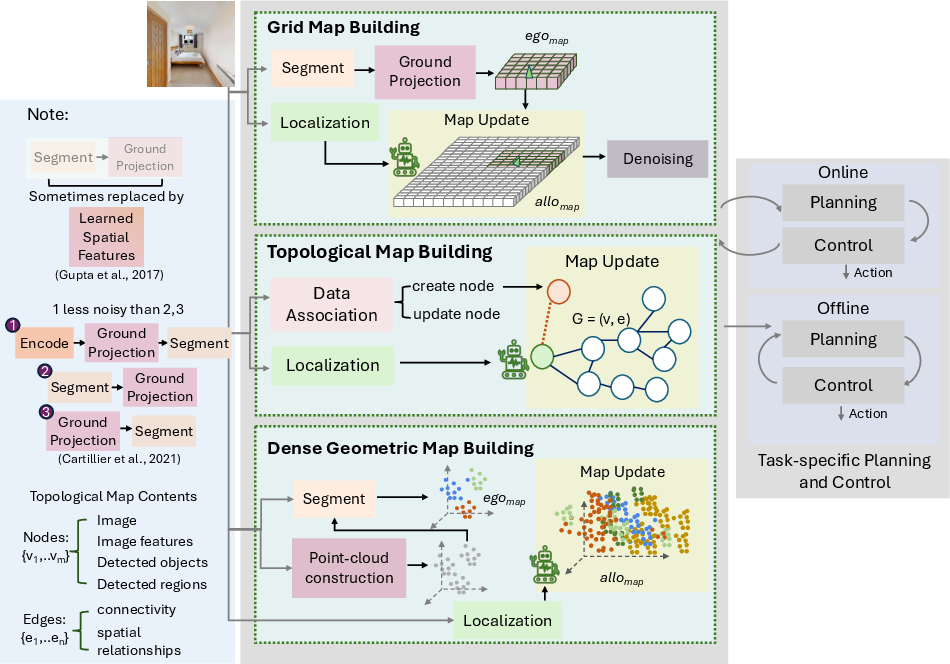
Figure 3: Grid map building: spatial grid maps are constructed from segmented sensory input, projected and registered to a global allocentric frame, and updated over time.
Figure 4: Timeline showing increased diversity in map structures and a recent shift toward open-vocabulary semantic maps leveraging large vision/LLMs.
Semantic Encoding: Explicit vs. Implicit
Encodings are categorized as:
- Explicit encoding stores predefined quantities per cell or node—such as occupancy, object class labels, visited status, or audio levels. These are interpretable and support fine-tuning to specific tasks, but are limited to a preset vocabulary.
- Implicit encoding assigns latent features learned by neural models, including vision or vision-language foundation model embeddings (e.g., CLIP, BLIP-2). Implicit features can be either closed- or open-vocabulary and support generalized and task-agnostic querying, but they may be less interpretable and harder to assess directly.
The paper documents a decisive recent trend: moving from closed-vocabulary, task-specific encodings to open-vocabulary, queryable, and general-purpose map representations via integration of foundation models.
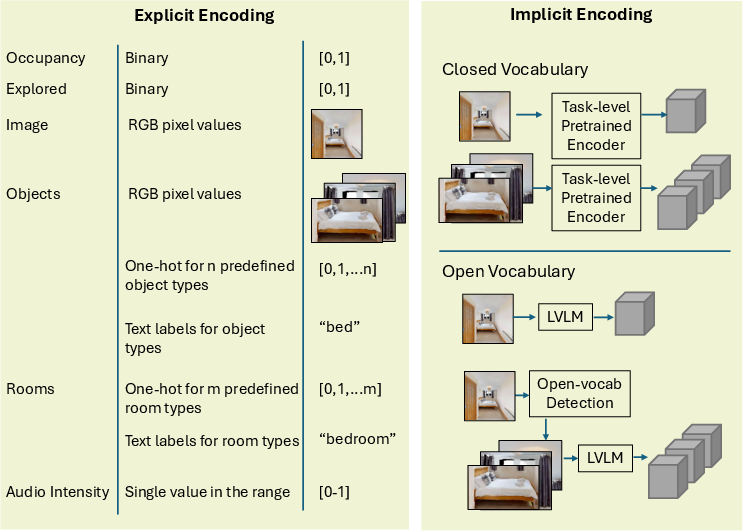
Figure 6: Map encoding describes whether the map’s stored values are explicit (interpretable, pre-selected quantities) or implicit (latently learned feature representations).
Relation to SLAM and Embodied System Design
The survey clarifies the interplay between traditional SLAM and semantic mapping for embodied AI. While SLAM in robotics emphasizes precise geometric mapping and localization, Semantic SLAM and recent embodied AI approaches increasingly integrate semantics for higher-level reasoning, often relaxing strict localization for efficiency and abstraction.
Additionally, the architectural design of embodied AI systems influences map-building:
- End-to-end approaches learn direct sensory-to-control mappings, sometimes with differentiable memory modules but generally lacking structured spatial/semantic memory.
- Modular pipelines decouple visual encoding, mapping, exploration, and planning, enabling reusability and interpretability at the cost of greater system complexity.
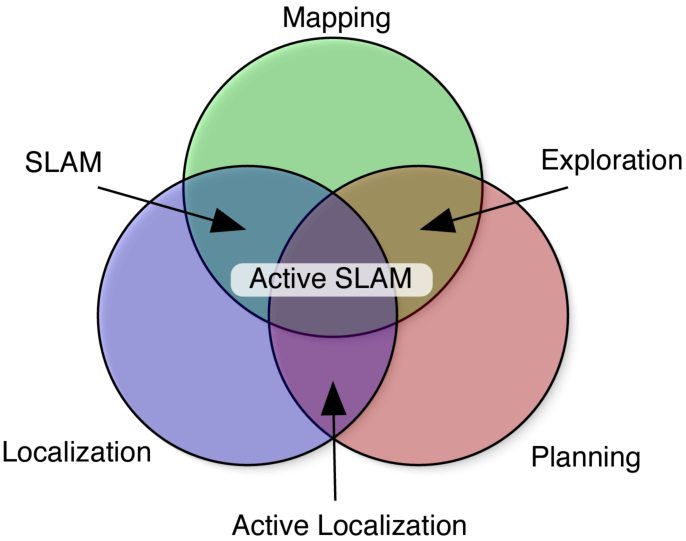
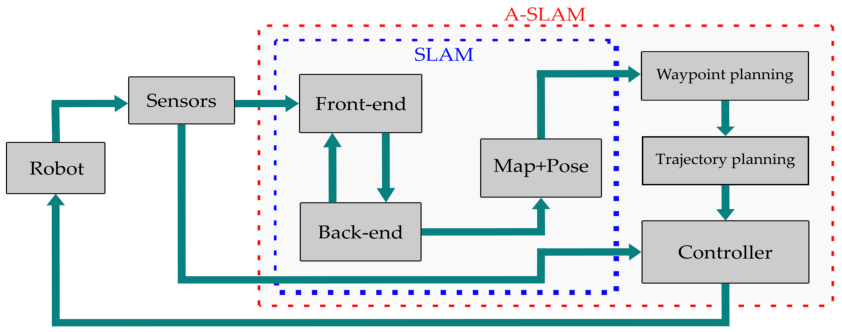
Figure 7: SLAM’s core tasks (mapping, localization, planning) are tightly interwoven, with modular or end-to-end architectures possible for embodied AI systems.
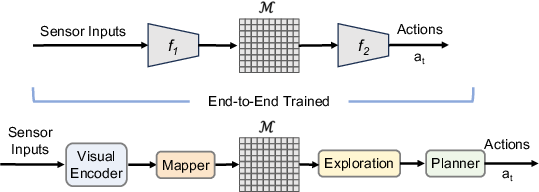
Figure 8: End-to-end (top) versus modular (bottom) embodied system architectures.
Open-Vocabulary and Multimodal Semantic Mapping
A major advance highlighted by the survey is the adoption of open-vocabulary, queryable semantic maps via large foundation models. These representations, built using models like CLIP, LSeg, OWL-ViT, and BLIP-2, permit robots to represent and retrieve semantic information beyond fixed object category sets, supporting flexible querying and generalization to novel instructions or visual targets.
Recent methods structure open-vocabulary maps as spatial grids, topological graphs, or dense 3D/point cloud representations. Aggregation and querying mechanisms leverage feature similarity scores, often integrating high-level task planners powered by LLMs, allowing robust cross-modal reasoning.
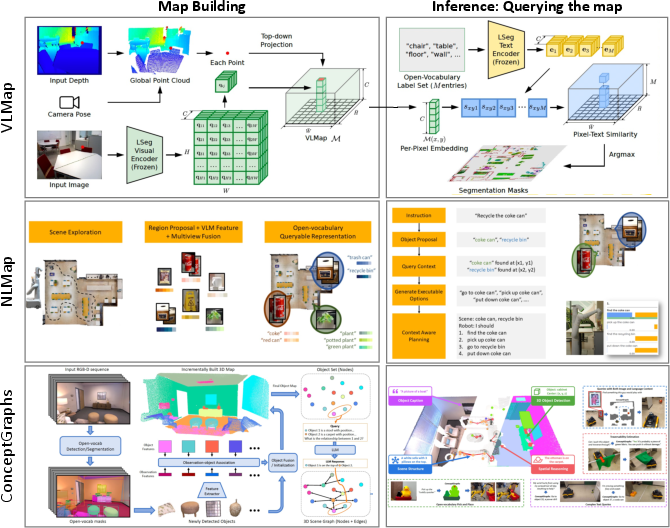
Figure 2: Open-vocabulary map building enables agents to build a reusable map for subsequent downstream tasks during inference, as demonstrated by VLMap and NLMap.
Key Numerical and Methodological Results
The survey presents several critical insights, including:
- Open-vocabulary mapping approaches, when paired with off-the-shelf vision-LLMs, can yield zero-shot generalization to object categories and language queries unseen during training, with competitive performance on navigation and manipulation tasks [gadre2023cows, huang2023visual, conceptgraphs].
- Dense geometric maps (via point clouds or Gaussians) enable fine-grained 3D reasoning but struggle to meet the requirements for real-time, memory-efficient operation in large or highly dynamic spaces [conceptfusion, qiu2024open].
- Hybrid and hierarchical scene representations improve scalability and abstraction, but efficient mechanisms for dynamic scene updating and cross-structure querying are yet unresolved [Rosinol20rss-dynamicSceneGraphs, hughes2024foundations].
Evaluation: Intrinsic and Extrinsic Metrics
Evaluation of semantic maps is widely recognized as a challenge:
- Extrinsic evaluation (task utility) dominates, with metrics such as Success Rate, SPL, and nDTW for navigation, or task success rate in manipulation.
- Intrinsic evaluation (direct map assessment) is less mature. The survey stresses the need for standardized metrics across accuracy, completeness, consistency, and robustness—especially for open-vocabulary, multimodal, and dynamic scene representations.
This gap is explicitly flagged as a major roadblock for method comparison and progress in the field.
Current Challenges
The primary technical challenges identified include:
- Scalability and Efficiency: Scaling to larger, denser, or persistently dynamic environments is limited by memory and compute—especially for dense or open-vocabulary maps.
- Real-Time Processing: Integrating fast semantic perception with spatial updating is currently beyond the capabilities of most map-building methods in robotics-scale environments.
- Noise, Uncertainty, and Robustness: Most embodied AI work presumes idealized sensing; robust uncertainty modeling (in simulation and reality) remains underexplored.
- Lifelong and Dynamic Adaptation: Current maps assume static or quasi-static worlds; efficient methods for updating semantic and geometric information over long operation are missing.
- Multimodal Fusion: Aligning information from vision, language, audio, and other senses for robust, queryable, and actionable memory remains unresolved.
- Standardized Intrinsic Evaluation: There is no accepted, broad-coverage benchmark suite for intrinsic map assessment, especially for dynamic, open-vocabulary embodied scenarios.
Implications and Discussion
The reviewed trends and challenges indicate pivotal shifts for embodied AI and robotics research:
Future Directions
The survey suggests research should prioritize:
- Flexible, dense, and efficient general-purpose semantic maps capable of real-time operation and broad downstream transfer;
- Online, adaptive, and lifelong updating of semantic and geometric representations, with explicit uncertainty modeling;
- Standardizing intrinsic evaluation metrics, moving beyond task completion to holistic map quality;
- Advanced multi-modal fusion and querying architectures, reconciling real-time constraints with the complexity of large foundation models;
- Hybrid and hierarchical structural designs balancing memory, scalability, spatial detail, and semantic abstraction.
Conclusion
This comprehensive survey (2501.05750) provides an authoritative categorization and critical analysis of methods for semantic map building in indoor embodied AI. By organizing research around core choices of map structure and semantic encoding, and by cross-referencing robotics and AI paradigms, it exposes major technical challenges and plots a focused trajectory for future advances. The paper strongly emphasizes the growing importance of general-purpose, open-vocabulary, and queryable semantic maps as foundational to the next generation of multi-modal, robust embodied intelligence.
References in this essay correspond to those in the original paper and should be mapped via (2501.05750).