- The paper introduces VDG-Uni3DSeg, which integrates offline LLM-generated textual descriptions and unpaired CLIP-encoded visual references to enhance point cloud segmentation.
- It employs a spatial enhancement module and a transformer-based unified mask decoder to achieve superior semantic, instance, and panoptic segmentation, with notable improvements in mAP and PQ metrics.
- The approach reduces annotation costs by eliminating real-time 2D-3D alignment, delivering state-of-the-art results on benchmarks like S3DIS, ScanNet, and ScanNet200.
Visual-Description-Guided Unified Point Cloud Segmentation
Motivation and Background
Unified segmentation of 3D point clouds for semantic, instance, and panoptic tasks is foundational to computer vision applications—specifically autonomous driving, robotics, AR/VR, and large-scale scene understanding. Point cloud data presents critical challenges: sparsity, lack of contextual cues, and limited annotated data restrict the efficacy of conventional approaches. Prior transformer-based unified frameworks (e.g., OneFormer3D) demonstrate limitations in fine-grained class and instance delineation due to insufficient semantic/contextual cues and reliance on unimodal supervision, failing to match the achievements observed in 2D vision tasks.
Conventional multi-modal 3D segmentation methods typically require paired 2D-3D data and on-the-fly captioning, leading to increased annotation effort and computational complexity. This work introduces VDG-Uni3DSeg, a framework that innovatively integrates pre-generated LLM-based class descriptions and unpaired internet image references via pretrained VLMs (CLIP) to establish robust offline multimodal guidance, circumventing online 2D-3D alignment and improving scalability, deployment, and class/instance discriminability.
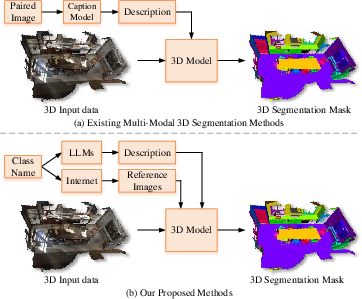
Figure 1: Comparison between existing multi-modal 3D segmentation methods and VDG-Uni3DSeg. The proposed approach leverages offline-generated references for enhanced efficiency and robustness.
Framework Overview
VDG-Uni3DSeg consists of a sparse 3D point cloud encoder, a Spatial Enhancement Module (SEM) with sparse attention for efficient contextual modeling, textual/visual reference query generation via LLM and CLIP, and a multi-modal transformer-based unified mask decoder. Offline multimodal references (class descriptions and diverse internet images) are encoded into queries that are fused with spatially enhanced 3D point features. The decoder jointly predicts semantic, instance, and panoptic masks across closed-set classes.
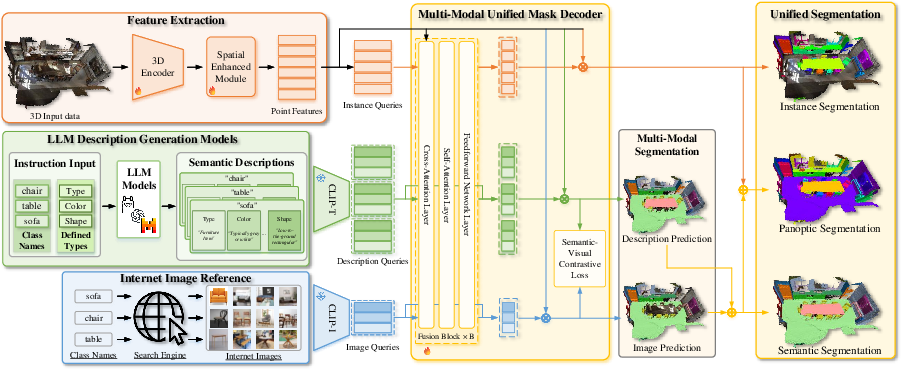
Figure 2: Schematic of the VDG-Uni3DSeg pipeline incorporating 3D encoding, spatial enhancement, and multimodal fusion for unified mask prediction.
Multi-Modal Reference Query Construction
- Description reference queries: For each class, an LLM (LLaMA 3.1) generates multiple rich, in-context attribute-based descriptions spanning appearance, texture, and geometry. These are CLIP-encoded to produce a set of textual queries per class, capturing high-level semantics and generalizing to unseen classes via consistent description strategies.
- Image reference queries: For each class, diverse unpaired images are retrieved from the web (based on CLIP similarity), encoded via CLIP's visual encoder, and serve as fine-grained real-world visual anchors.
Multi-Modal Unified Mask Decoder
A transformer-based decoder fuses semantic and visual queries with spatially enhanced 3D features via cross-attention. Description and image-based predictions are ensembled through max-pooling to harness both attribute-level and instance-specific cues, which strengthens the model’s capacity for precise mask prediction. Semantic and instance masks are ultimately merged for panoptic output.
Optimization and Losses
Training employs established segmentation losses (cross-entropy, Dice, BCE), but introduces a Semantic-Visual Contrastive (SVC) loss. SVC explicitly aligns 3D features with both textual and visual queries per class in the joint embedding space, promoting intra-class compactness and inter-class separability among the feature representations, which is critical for discriminative segmentation. Hyperparameters balance the contributions of instance, semantic, and multimodal alignment losses.
Empirical Results
VDG-Uni3DSeg is evaluated on S3DIS, ScanNet, and ScanNet200—with comprehensive benchmarks for semantic, instance, and panoptic segmentation. The approach consistently surpasses prior state-of-the-art baselines, demonstrating:
- On S3DIS Area-5, a +2.1 mAP50 and +1.4 mAP gain over OneFormer3D for instance segmentation. Panoptic PQ improved by +4.1 and PQth by +9.6.
- On ScanNet, improvement in instance segmentation mAP50 (+1.3) and mIoU (+0.4), and panoptic segmentation PQ.
- On ScanNet200 (198 fine-grained classes), SOTA mAP/IOU/PQ across all segmentation tasks, evidencing robustness in high-class-count settings.
Qualitative results show significantly more consistent instance and semantic mask boundaries compared to OneFormer3D, especially in complex or cluttered scenes with small or ambiguous objects.





Figure 3: Ground-truth segmentation visualizations for comparison.

Figure 4: VDG-Uni3DSeg instance segmentation results on ScanNet demonstrate robust delineation in cluttered scenarios.
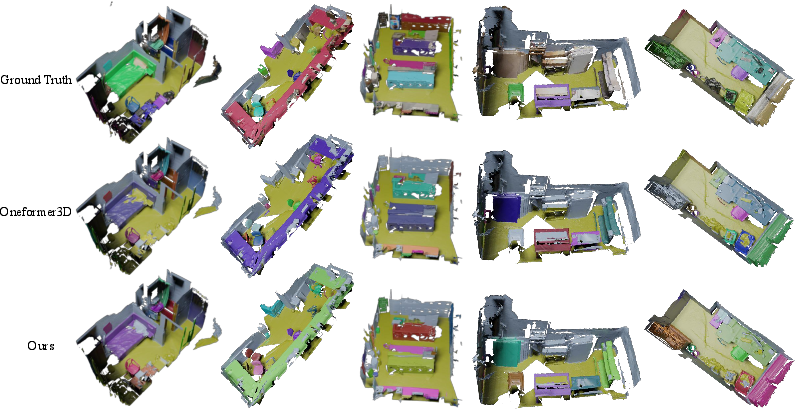
Figure 5: VDG-Uni3DSeg panoptic segmentation qualitatively improves stuff/thing consistency and instance clarity.
Ablation studies highlight the necessity of every pipeline component. Removal of the SEM or SVC loss leads to the most pronounced declines in panoptic and instance metrics, confirming the superiority of spatial modeling and multimodal contrastive alignment. Disabling description or image queries likewise degrades accuracy, underlying the benefit of multi-source supervision.
Implications
This work establishes a scalable, annotation-efficient paradigm for closed-set unified 3D segmentation, leveraging offline LLM-generated semantics and unpaired internet-sourced visual anchors. Critical implications include:
- Annotation cost reduction: Eliminates the requirement for paired multimodal scene annotation or real-time captioning.
- Offline, parallelizable reference construction: Decouples multimodal data acquisition from online scene inference.
- Robustness/efficiency: The closed-set paradigm improves computational tractability and deployment practicality in real-world settings compared to open-vocabulary or paired-label approaches.
In addition, the pipeline is adaptable—future work may extend towards open-vocabulary segmentation or improved image-3D alignment with stronger cross-modal matching. Incorporating further external knowledge or multimodal pretraining could drive additional gains in feature generalization, transferable scene understanding, and unsupervised/weakly supervised 3D perception.
Conclusion
VDG-Uni3DSeg achieves SOTA segmentation across semantic, instance, and panoptic tasks on major 3D benchmarks by synergistically integrating offline LLM-generated descriptions and unpaired visual references through CLIP-based multimodal queries. The architecture is underpinned by efficient spatial reasoning and explicit multimodal contrastive objectives. These findings evidence the efficacy of leveraging external semantic/visual knowledge for robust, scalable 3D scene analysis and lay the foundation for broader multimodal vision-language-3D integration in practical AI systems.