- The paper presents a novel dual-scale architecture that integrates global navigation via a Sparse Spatial Memory Graph with a local, geometry-enhanced control policy.
- It leverages a hybrid retrieval mechanism combining DINOv2-based keyframe and object-level matching to generate connectivity-aware node trajectories, achieving SR 78.5 and SPL 59.3 on HM3D.
- Ablation studies and dynamic testing validate MG-Nav’s resilience and the critical role of the VGGT-adapter in refining local obstacle avoidance and goal localization.
MG-Nav: Dual-Scale Visual Navigation via Sparse Spatial Memory
Framework Overview
MG-Nav proposes a dual-scale architecture for zero-shot visual navigation, explicitly integrating global memory-guided path planning with local, geometry-augmented policy control. Central to this approach is the Sparse Spatial Memory Graph (SMG), a region-centric memory representation used to unify high-level semantic-topological planning with low-level action execution.
MG-Nav decomposes the navigation problem as follows: the agent is first globally localized and guided using SMG, planning a connectivity-aware node-path from its current observation to the goal. Along this node-path, a foundation navigation policy—augmented by the VGGT-adapter—executes local control, handling obstacle avoidance and precise goal localization, especially in the presence of dynamic environmental changes.
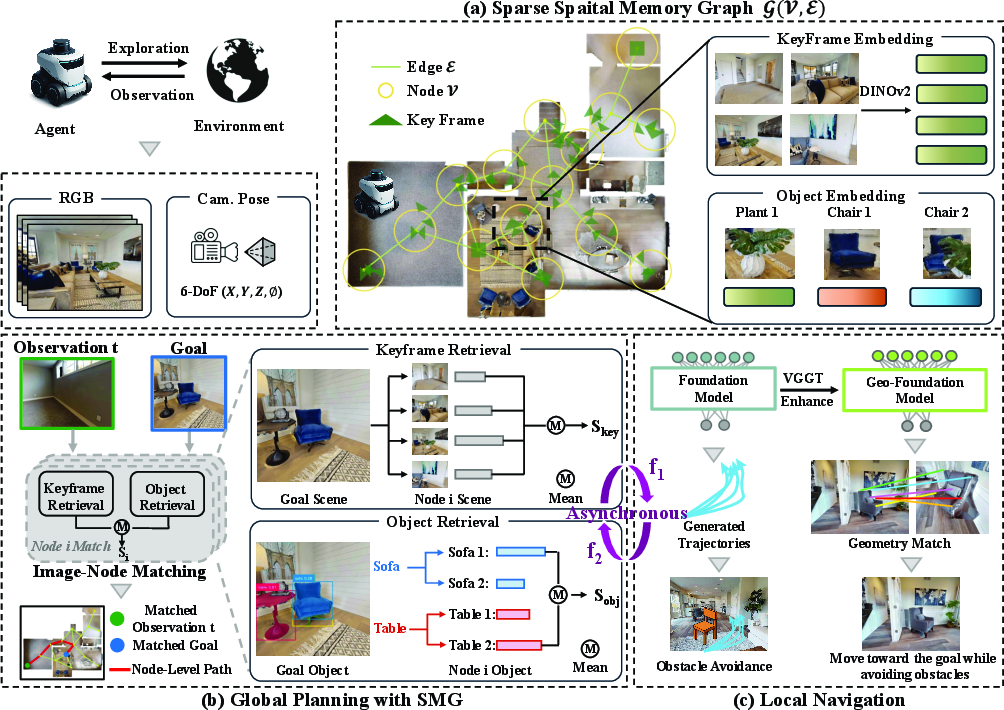
Figure 1: MG-Nav workflow, illustrating SMG construction, global planning by node retrieval, and local navigation with geometric enhancement.
Sparse Spatial Memory Graph (SMG) Representation
The SMG is a graph G=(V,E) where each node V denotes a spatial region and each edge E encodes physical reachability. Nodes aggregate multi-view keyframes (extracted using DINOv2) and object instance semantics (via Grounded-SAM segmentation), ensuring that both appearance diversity and object-level structure are represented. Node construction uses Farthest-Point Sampling to guarantee spatial representativeness.
For each node, embeddings include the 3D center, a set of diverse keyframes, and aggregated object descriptors. Edges are temporally derived from demonstration tours, directly reflecting feasible traversals.
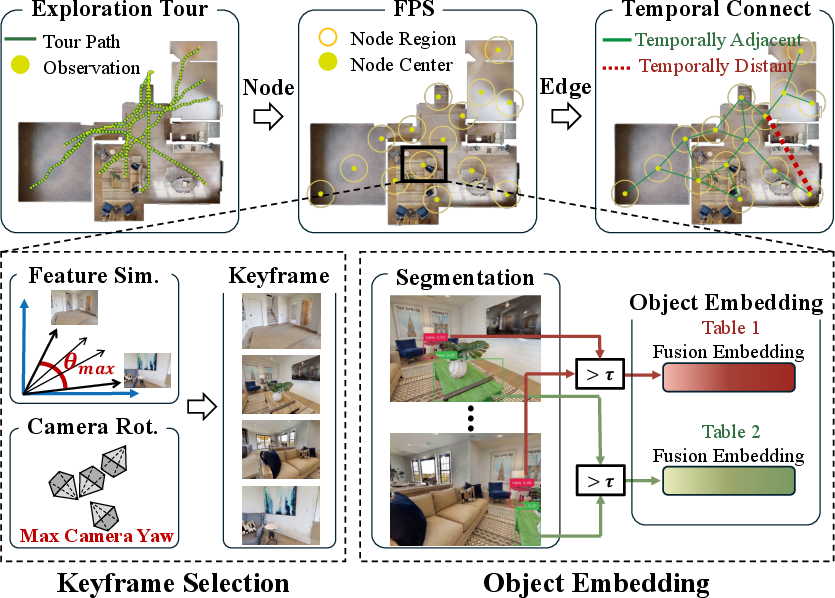
Figure 2: SMG construction pipeline, showing aggregation of multi-view and object embeddings per region.
Global Planning & Hybrid Retrieval
Global planning with SMG involves a hybrid two-stage retrieval mechanism. First, the agent matches its current view and the goal image to corresponding nodes using global appearance similarity (keyframe retrieval) and object-level matching (object retrieval). Keyframe similarity is computed via DINOv2 embedding cosine distance, while object similarity aligns segmented entities and averages matching scores. The best-scoring nodes anchor the agent’s starting and objective regions.
Upon localization, A* search is applied across the SMG to produce a node-level trajectory. Each segment of this trajectory anchors a waypoint, which structures the navigation problem into manageable, locally-executable sub-goals.
Local Navigation with VGGT-enhanced Policy
Local navigation is handled by a foundation diffusion policy (NavDP), operating in both point-goal and image-goal modes. Execution between waypoints utilizes point-goal conditioning, transitioning to image-goal for final visual alignment.
The VGGT-adapter module integrates 3D-aware geometric cues from the Visual Geometry Group Transformer (VGGT) into the foundation policy. VGGT feature maps from both observation and goal images are pooled, concatenated, and projected via a lightweight MLP adapter, enriching the policy’s embedding space with multi-view spatial correspondence. Ablations confirm that this geometric conditioning substantially improves viewpoint robustness and precise goal approach.
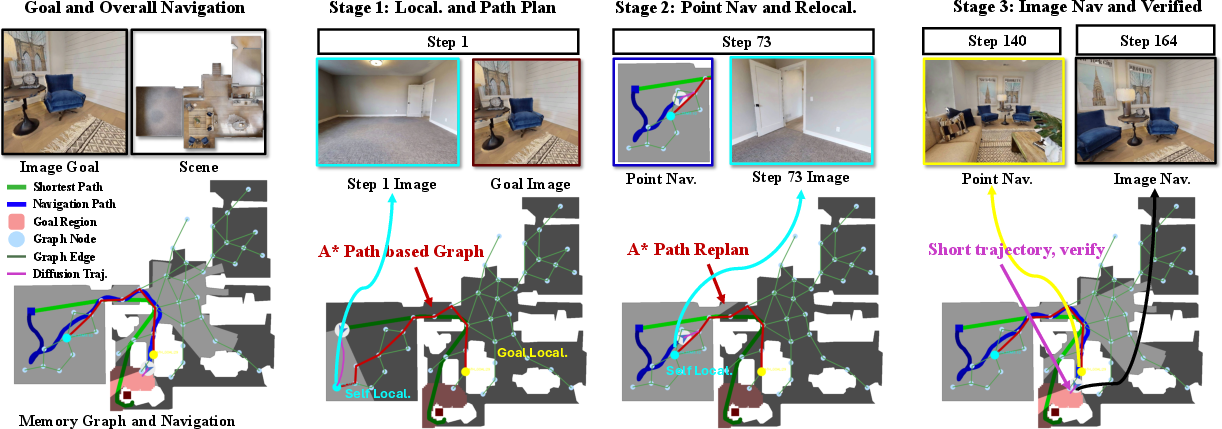
Figure 3: MG-Nav’s decision pipeline, highlighting sequential steps: node localization, trajectory planning, point-to-point navigation, and final goal verification.
Dual-Scale Planning Loop
MG-Nav operates planning and execution at different timescales. The global loop (slow, every Tg steps) reevaluates localization and refines the SMG trajectory; the local loop (fast, every Tℓ≪Tg steps) executes near-term control and obstacle avoidance. This asynchronous control mitigates drift and allows rapid adaptation to dynamic scene disruptions with minimal overhead.
Experimental Results
On the HM3D Instance-Image-Goal benchmark, MG-Nav achieves SR 78.5 and SPL 59.3, exceeding all foundation, RL, and memory-based baselines by significant margins (e.g., BSC-Nav: 71.4/57.2, GaussNav: 72.5/57.8, UniGoal: 60.2/23.7). MP3D Image-Goal results show analogous trends, with MG-Nav at 83.8/57.1 (SR/SPL). The empirical improvements are attributed to the dual-scale design and hybrid use of semantic and geometric information.
Robustness to Dynamic Environment Changes
Evaluation under dynamic rearrangements (adding 5 or 10 random obstacles at navigation time) demonstrates that MG-Nav retains high performance with only minor absolute drops in SR and SPL (e.g., 73.53 → 68.63 SR). In contrast, traditional mapping-based approaches such as BSC-Nav and UniGoal exhibit pronounced degradation due to their dependence on stale, geometry-fixed global memory.
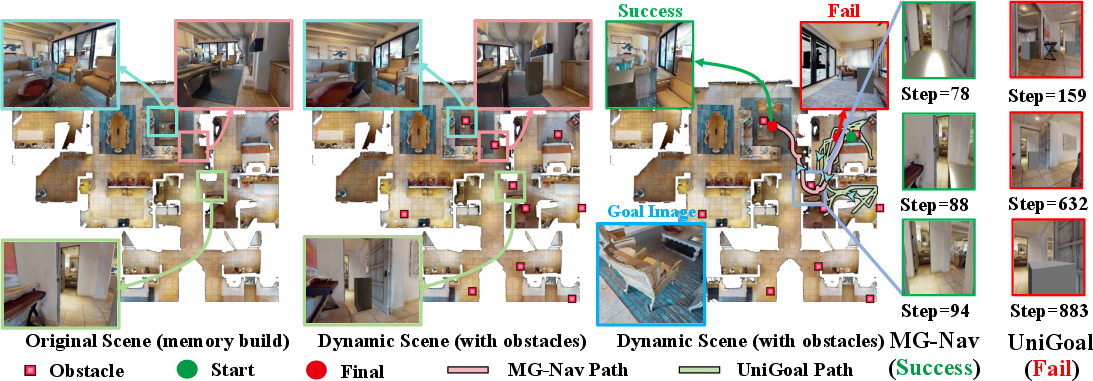
Figure 4: Robustness comparison in a rearranged scene; MG-Nav dynamically avoids new obstacles and completes navigation, while UniGoal is trapped.
Ablation Studies
Component and retrieval strategy ablations validate the dual-scale formulation. Adding SMG to the foundation policy raises HM3D Instance-Image-Goal SR/SPL from 24.7/12.6 to 74.0/56.1. Enabling the VGGT-adapter yields further gains to 78.5/59.3. Relying solely on keyframe or object-level retrieval impairs performance; the hybrid strategy is essential for robust, viewpoint-consistent matching. Varying SMG sparsity reveals that excessive coarsening diminishes both success and path efficiency.
Practical and Theoretical Implications
MG-Nav demonstrates that dual-scale navigation with sparse visual-semantic memory can rival and surpass dense 3D map-based agents without requiring depth or repeated environmental scans. This formulation offers strong generalization in previously unseen or changing scenes, a key criterion for real-world deployment of embodied AI in domestic robotics, autonomous delivery, and AR/VR telepresence.
On the theoretical side, MG-Nav bridges topological and instance-level navigation by exploiting both semantic anchoring and geometric view alignment. This could inspire a new generation of approaches favoring region-level memory and global-local architectural decoupling.
Future Directions
Further advances may involve:
- Online and continual memory augmentation: enabling agents to incrementally update or refine their SMG as the environment changes.
- LLM-based semantic reasoning: incorporating high-level language or task reasoning atop the SMG.
- Joint policy-memory co-adaptation: end-to-end training of both global memory and local policy for specific downstream tasks or domains.
Conclusion
MG-Nav introduces a robust, dual-scale navigation paradigm, establishing new benchmarks in visual goal-reaching with strong resilience to scene dynamics and without reliance on dense geometric priors. The explicit decoupling of region-centric global planning from foundation policy-driven local control, anchored by hybrid semantic-geometric retrieval, sets a precedent for efficient, scalable, and flexible embodied navigation in complex, real-world environments.

