- The paper introduces CausalNav, a navigation system that integrates dynamic embodied graphs and LLM-based semantic reasoning for outdoor robotic autonomy.
- The paper leverages open-vocabulary object tracking, precise ego-motion estimation, and dynamic filtering to enhance real-time performance and safety.
- The paper demonstrates state-of-the-art performance in simulation and real-world tests, achieving high success rates and reduced collision counts in dynamic scenarios.
CausalNav: A Scene Graph-based Semantic Navigation System for Dynamic Outdoor Robot Autonomy
Introduction
CausalNav addresses the challenge of language-directed autonomous navigation in large, dynamic outdoor environments—settings where robots must maintain semantic awareness and robust planning under open-vocabulary queries. Existing methods are limited by static maps, shallow semantic understanding, or poor real-world generalization, and most visual-language navigation (VLN) benchmarks focus on structured, indoor tasks with stepwise instructions. CausalNav introduces a novel paradigm by fusing open-vocabulary perception, dynamic memory graphs, and hierarchical reasoning for robust long-horizon navigation directed by natural language.
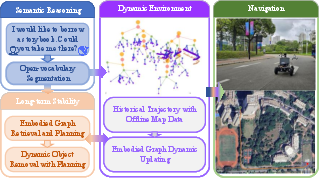
Figure 1: The overall workflow of CausalNav, integrating open-vocabulary semantic reasoning, dynamic environment adaptation, and embodied graph-based planning for robust navigation in complex outdoor environments.
Core Methodology
Embodied Graph Construction and Updating
CausalNav employs an Embodied Graph—a multi-level semantic scene graph constructed via LLMs and augmented with Retrieval-Augmented Generation (RAG). The graph hierarchically fuses coarse-grained environmental data (e.g., buildings) and fine-grained detections (e.g., hydrants), dynamically updated as the agent navigates. Key components of the architecture include:
- Open-Vocabulary Object Tracking: Utilizes YOLO-World for 2D detection, temporal association with ByteTrack, and fuses RGB with LiDAR for 3D bounding box estimation.
- Ego-Motion Estimation: Leverages LiDAR-inertial odometry for accurate trajectory and node updates.
- Dynamic Object Filtering: Incorporates BEV-based CenterPoint, motion estimation, and a spatial-temporal corridor representation to prevent graph pollution by mobile entities (see Figure 2).
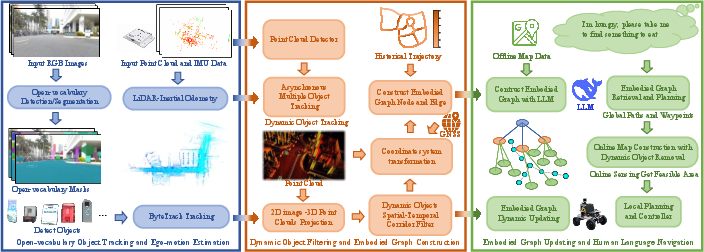
Figure 3: The CausalNav framework: (1) open-vocabulary object tracking and ego-motion estimation, (2) dynamic object filtering and embodied graph construction, and (3) graph updating and language-guided planning.

Figure 2: Example of multi-timestep 3D bounding boxes for a dynamic vehicle within its spatial-temporal corridor, facilitating dynamic entity filtering.
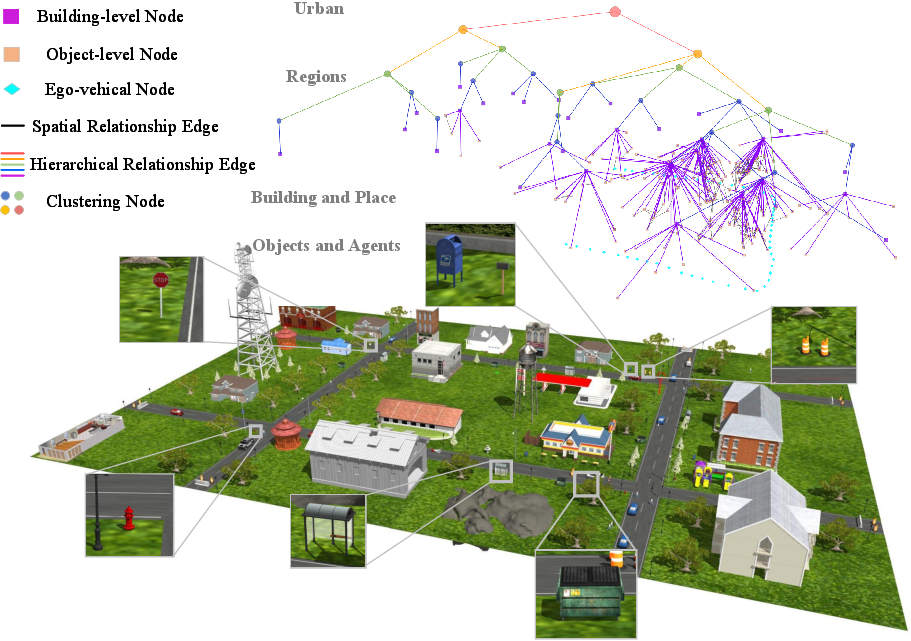
Figure 4: Simulation environment and constructed Embodied Graph, illustrating the fusion of object-level and building-level nodes for multi-scale semantic representation.
Online updates to the graph are carried out in real time, representing both structural (map-derived) and event-driven (perceptual) changes within a temporal window. This ensures consistent, updated memory for semantic retrieval and planning.
Hierarchical Semantic Clustering and Retrieval
The static graph after dynamic filtering supports hierarchical clustering: object nodes are aggregated based on spatial-semantic similarity into clusters, which are further grouped under buildings. Semantic similarities use both spatial proximity and representation similarity (embedding cosine similarity), making the system resilient to LLM aliasing and open-vocabulary instructions.
Hierarchical retrieval over the Embodied Graph is realized through an LLM-based probability model, allowing flexible and accurate query resolution that simultaneously considers semantic and spatial factors through tunable fusion parameters (α, β, γ).
Language-Guided Navigation and Hierarchical Planning
Given a natural language instruction, CausalNav performs global semantic retrieval over the Embodied Graph to localize the target. If necessary, offline map data or historical trajectories provide coarse global routes; local planning is performed with real-time RH-Map and obstacle-aware informed-RRT*, followed by smoothing and NMPC-CBF for safe, dynamically feasible execution under evolving real-world constraints.
Experimental Evaluation
Simulation Results
CausalNav is evaluated against NoMaD, ViNT, GNM, and CityWalker on urban-scale Gazebo environments with synthetic dynamics. Four main metrics are reported: Success Rate (SR), Success weighted by Path Length (SPL), Collision Count (CC), and Trajectory Length (TL). Results indicate:
- CausalNav achieves 100% SR in short-range and 92% in medium-range tasks, outperforming baselines, and exhibits significantly reduced collisions (CC) and path lengths (TL) in dynamic scenes.
- CityWalker achieves similar SR and SPL but suffers notably higher CC, mainly due to inferior handling of moving obstacles.
- The dynamic graph update mechanism is pivotal: removing online updates leads to a 12% drop in SR and marked increases in CC and TL.
Ablation studies on retrieval parameters confirm optimal performance at α=β=0.5, γ=1.5, suggesting balanced spatial-semantic fusion and LLM query sharpness (Figure 5).
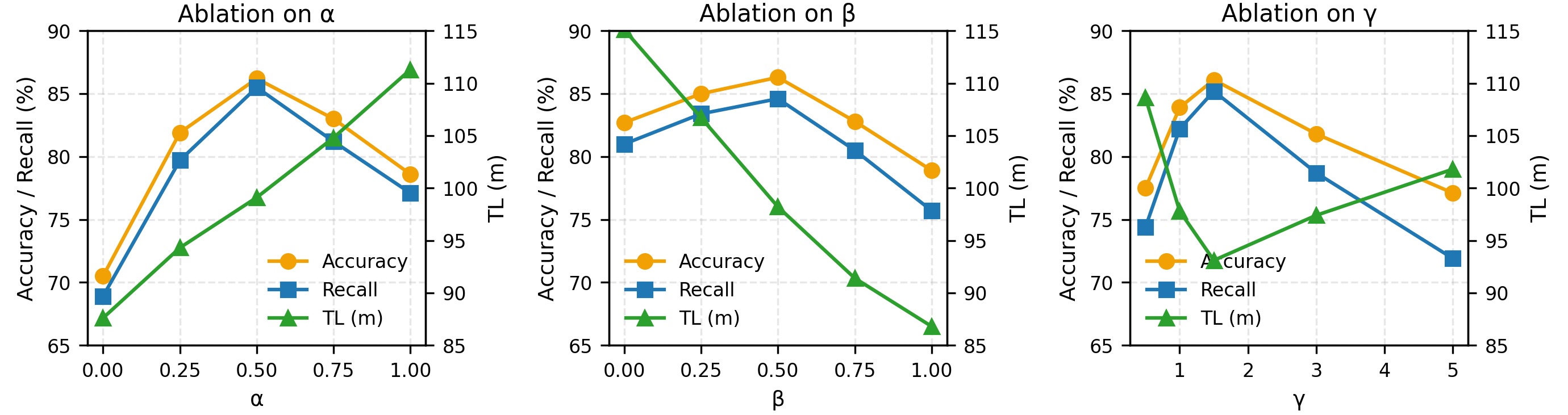
Figure 5: Ablation study of semantic retrieval parameters (α, β, γ) on accuracy, recall, and trajectory length.
CausalNav attains real-time performance (10 Hz) with only modest computational overhead versus simpler learning-based policies.
Real-World Deployment
The system is validated on a large-campus robot with RealSense, 3D LiDAR, and RTK-GNSS/INS fusion (Figure 6). Evaluations are conducted on both short- (130 m) and long-range (512 m) tasks:
- Only CausalNav completes long-range, building-level navigation in dynamic real-world conditions—competing methods consistently fail due to collision or environmental mismatch.
- CityWalker, despite strong simulation results, underperforms outdoors due to poor generalization to lighting and dynamic variance.
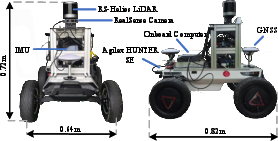
Figure 6: Mobile robot platform used for real-world navigation experiments.
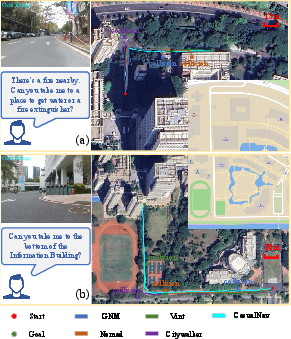
Figure 7: Real-world evaluation on different distance scales; only CausalNav achieves successful long-range navigation without collisions.
Additional Insights
- CausalNav operates robustly using edge-deployed, open-source LLMs, with only modest performance drop versus GPT-4o. This demonstrates practical viability without dependency on external APIs and provides privacy and latency advantages.
- Dynamic, hierarchical updates mitigate error accumulation from outdated memory, which is critical for consistent, safe navigation.
Implications and Future Directions
CausalNav represents a transition from static, brittle navigation policies toward semantic memory-driven, adaptive autonomy. The explicit handling of open-vocabulary commands, multi-granularity environment abstraction, and continual memory updates bridge the gap between language-driven reasoning and real-world robotic deployment.
Practical implications include:
- Scalable deployment in large, unpredictable outdoor environments (e.g., urban logistics, campus shuttles) where semantic and linguistic flexibility is required.
- Edge-based semantic graph and retrieval paradigms provide efficient alternatives to costly cloud models.
- The architecture’s memory modularity enables principled lifelong learning extensions.
Theoretically, this work pushes RAG-paradigms and embodied memory further, blending low-level perception, LLMs, and hierarchical planning—opening avenues for robust, generalized robot cognition.
Planned extensions include enhanced graph compression/memory mechanisms, richer multimodal (e.g., weather, illumination) fusion for further robustness, and exploration of long-horizon lifelong autonomy frameworks.
Conclusion
CausalNav delivers a unified framework for semantic, language-driven navigation in large-scale, dynamic outdoor environments. By leveraging a continually updated, multi-level Embodied Graph and integrating LLM-based semantic reasoning with robust perception and planning, the system achieves state-of-the-art results in both simulation and challenging real-world deployments. This work provides a blueprint for next-generation embodied navigation methodologies, emphasizing semantic flexibility, adaptive memory, and robust execution in complex, dynamic scenes.