- The paper introduces a novel method repurposing Vision-Language Models for mapless navigation via learned scene imagination and human-inspired waypoint prediction.
- It employs a hierarchical architecture integrating future-view imagination, selective foveation memory, and VLM-guided planning to enhance exploration efficiency.
- Empirical evaluation on multiple datasets demonstrates notable performance gains, achieving up to 6% improvement in success rate over traditional pipelines.
ImagineNav++: Repurposing Vision-LLMs for Mapless Embodied Navigation via Scene Imagination
Background and Motivation
The development of open-vocabulary, mapless embodied visual navigation systems represents a key challenge for autonomous robots operating in unstructured environments. Traditional frameworks for object-goal navigation heavily rely on cascaded sensor data processing, pose estimation, semantic mapping, and LLM-driven reasoning to inform exploration (Figure 1). These pipelines are susceptible to compounding errors in localization and segmentation, suffer from high computational overhead, and are fundamentally limited in their representation of spatial geometry when relying on textual abstractions. ImagineNav++ (2512.17435) introduces a paradigm shift, leveraging the discriminative capabilities of Vision-LLMs (VLMs) and learned scene imagination to transform navigation planning into a sequence of best-view image selection tasks, obviating the need for mapping and explicit geometric reasoning.
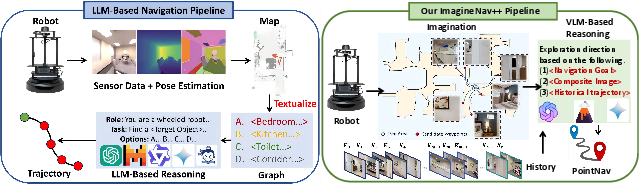
Figure 1: Comparison between conventional LLM-based navigation and the ImagineNav++ pipeline, highlighting bypassing of mapping and translation stages via direct VLM-based image selection.
Framework Architecture
ImagineNav++ employs a hierarchical structure with four main modules: future-view imagination (Where2Imagine + NVS), selective foveation memory, high-level VLM-based planning, and low-level point-goal navigation (Figure 2). At each episode, the agent captures a panoramic RGB(-D) observation; the Where2Imagine module predicts semantically salient future waypoints by distilling human navigation preferences learned from large-scale demonstrations. These waypoints are used by a novel view synthesis (NVS) model (PolyOculus) to generate synthetic future observations. The VLM planner is prompted with both these imagined scenes and hierarchical memory of past salient frames and selects the next waypoint for exploration, which is executed via a point navigation controller.
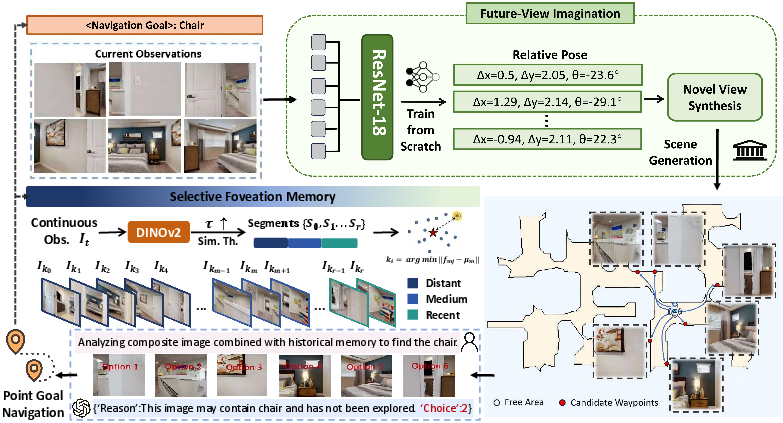
Figure 2: Schematic of the mapless, open-vocabulary navigation pipeline, featuring imagination, hierarchical memory integration, and VLM-guided decision-making.
Learning Human-Inspired Waypoint Generation
The Where2Imagine module is trained on the Habitat-Web human demonstration dataset, reformulating natural indoor exploration as waypoint prediction from RGB observations. Key findings indicate a consistent preference by humans for moving toward semantically meaningful cues, e.g., doors, which structurally facilitate efficient exploration (Figure 3). Where2Imagine employs depth-based filtering and restricts angular prediction to avoid NVS failure modes, using a ResNet-18 backbone for pose regression. This design ensures the generation of plausible, semantically rich candidate waypoints from onboard sensing only.
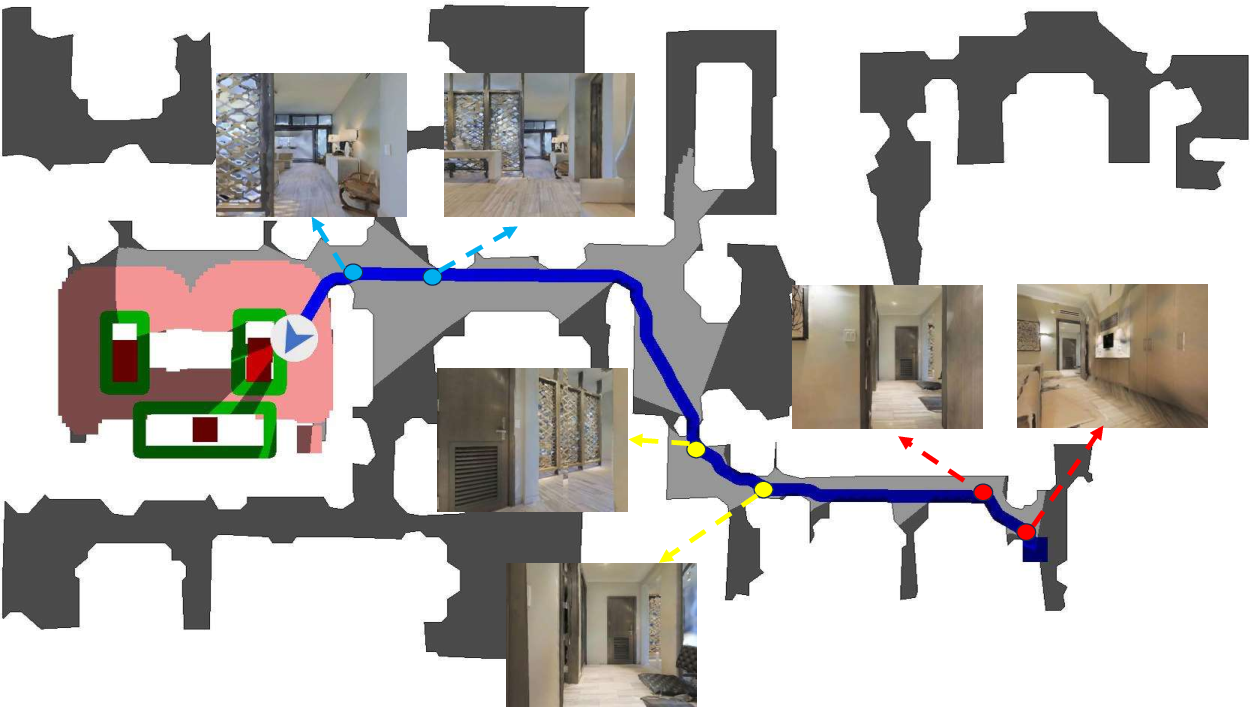
Figure 3: Human demonstration trajectories prioritize semantic exploration cues, providing supervision for Where2Imagine design.
Synthetic future observations at predicted waypoints exhibit enhanced semantic diversity relative to current frames, supporting robust VLM discrimination of exploration utility (Figure 4).

Figure 4: Imagination module generates diverse semantic scenes at plausible future waypoints, improving the informativeness of VLM prompts.
Spatial memory in long-horizon navigation is critical yet constrained by context windows and perceptual noise. ImagineNav++ introduces a keyframe-based, sparse-to-dense hierarchical memory architecture using DINOv2 features for unsupervised semantic similarity clustering. The algorithm adapts memory density according to segment recency, with high granularity for recent frames and coarse sampling for distant history. This strategy preserves spatial coherence and structural saliency (Figure 5).

Figure 5: Hierarchical memory visualization emphasizes intersections and corners, maintaining optimized memory allocation via feature saliency.
VLM-Guided Planning and Prompt Engineering
Planning is performed by prompting advanced VLMs (GPT-4o-mini) with imagined future observations, hierarchical memory, and the goal specification. Structured prompts require the VLM to select among candidates and to provide reasoning in a JSON format, facilitating transparency and auditability. The full prompt-response interface is shown in Figure 6.

Figure 6: End-to-end input/output trace for VLM-based exploration direction selection in object-goal navigation.
Experiments on Gibson, HM3D, and HSSD datasets demonstrate that ImagineNav++ achieves state-of-the-art performance in mapless, open-vocabulary navigation, surpassing map-based VLFM and graph-based UniGoal in complex scenarios by up to 6% in success rate, and establishing a new SPL benchmark in the InsINav task. Notably, performance is robust even without dataset-specific fine-tuning due to the generic NVS. Oracle experiments replacing NVS images with real ground-truth frames reveal further gains, indicating that scene imagination quality is currently the bottleneck for maximum performance.
Ablation studies highlight that:
- Future-view imagination yields a marked improvement over standard observation-based navigation.
- Where2Imagine provides an additional boost over uniform sampling, especially in escaping local minima and promoting structural exploration (Figures 5, 6, 7).
- Hierarchical memory substantially increases success rates and path efficiency and reduces input token count (avg. 20 keyframes for 500 steps).
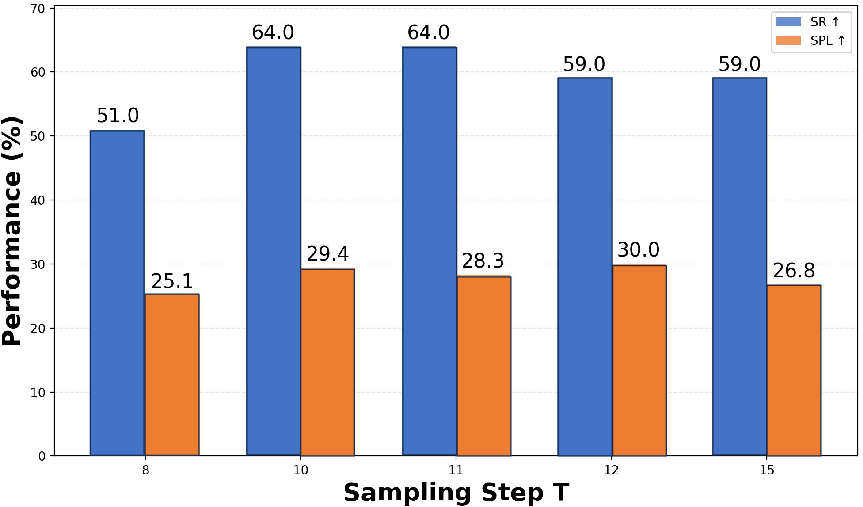
Figure 7: Optimal sampling interval (T) for Where2Imagine maximizes navigation performance.
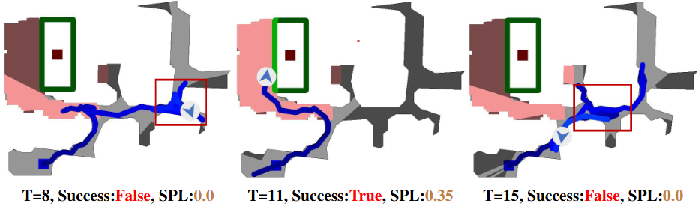
Figure 8: Trajectory comparisons illustrate local trapping when T is too small and missed semantics when T is too large.

Figure 9: Where2Imagine generates poses concentrated in navigable regions, outperforming uniform sampling in semantic density.
Analysis of Trajectories and Failure Modes
Successful navigation examples verify the efficacy of combined imagination and structured memory in multi-room, long-horizon tasks, while failure cases predominantly stem from NVS synthesis errors or ambiguous instances not properly marked in the simulator (Figure 10).
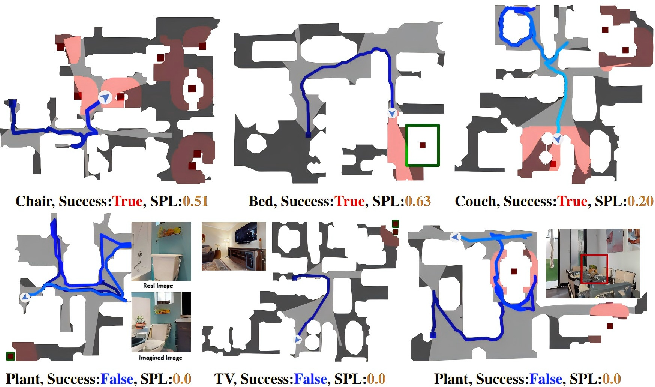
Figure 10: Top-down visualizations contrast success and failure cases, elucidating critical factors in VLM-driven object-goal navigation.
Implications and Future Directions
ImagineNav++ demonstrates that VLMs, empowered by sophisticated scene imagination and saliency-aware memory integration, can achieve robust mapless navigation in open-vocabulary settings without categorical retraining or explicit spatial mapping. The approach significantly reduces architectural complexity and computational cost while retaining zero-shot generalization. Its reliance on future-view imagination highlights the importance of perceptual diversity and synthetic data quality, pointing toward improvements in generative modeling. The memory design underscores the value of adaptive context compression for scalable robot deployment with advanced multimodal large models.
Practical implications include the potential for deployment in resource-constrained real-world environments, real-time adaptation, and lifelong learning capabilities. Theoretical implications extend to the design of embodied agents whose cognitive architecture reflects a hybrid of episodic memory and predictive simulation, opening avenues for multimodal reasoning and general-purpose decision-making.
Conclusion
ImagineNav++ robustly repurposes VLMs for embodied navigation via scene imagination, outperforming conventional pipelines and many map-based approaches in both open-vocabulary object and instance navigation tasks. By integrating learned human-inspired imagination, hierarchical memory compression, and prompt-based planning, it efficiently addresses spatial reasoning and long-term exploration challenges. Future work may expand multimodal goal specifications, reduce inference latency, and explore continual adaptation in a dynamic world, aligning the agent design with principles of scalable, general-purpose autonomy.

