- The paper introduces Claw-Eval-Live, a dynamic benchmark that evaluates workflow agents using live public signals and reproducible snapshot releases.
- It details a novel signal-to-task pipeline employing MILP-based optimization to select diverse, discrimination-aware tasks across business and local workflows.
- Benchmark results reveal that leading LLM-based agents struggle with multi-system, business-critical tasks, highlighting key gaps in agent reliability.
Claw-Eval-Live: Dynamic Benchmarking for Real-World Workflow Agent Competence
Introduction and Motivation
Claw-Eval-Live (2604.28139) formalizes a new paradigm in benchmarking autonomous agents for end-to-end workflow automation. Traditional evaluation suites for LLM-based agents typically rely on static, hand-curated task sets and grade primarily based on final outputs, rendering them poorly aligned with the evolving landscape of real-world workflow demand and insufficiently rigorous in verifying faithful task execution. Claw-Eval-Live departs from this paradigm by establishing a live benchmark that:
- Separates a time-varying layer of public workflow signals for dynamic task calibration from a reproducible, time-stamped release snapshot.
- Merges business service automation with local workspace repair in a single benchmark, spanning 105 executable tasks.
- Implements action-grounded, hybrid grading, combining deterministic execution evidence with rubric-bound LLM judges for semantic verification.
The benchmark thus targets the core open challenges for practical workflow agents: maintaining alignment with actual, shifting user needs and providing robust, evidence-based measures of true agentic completion beyond superficial plausibility.
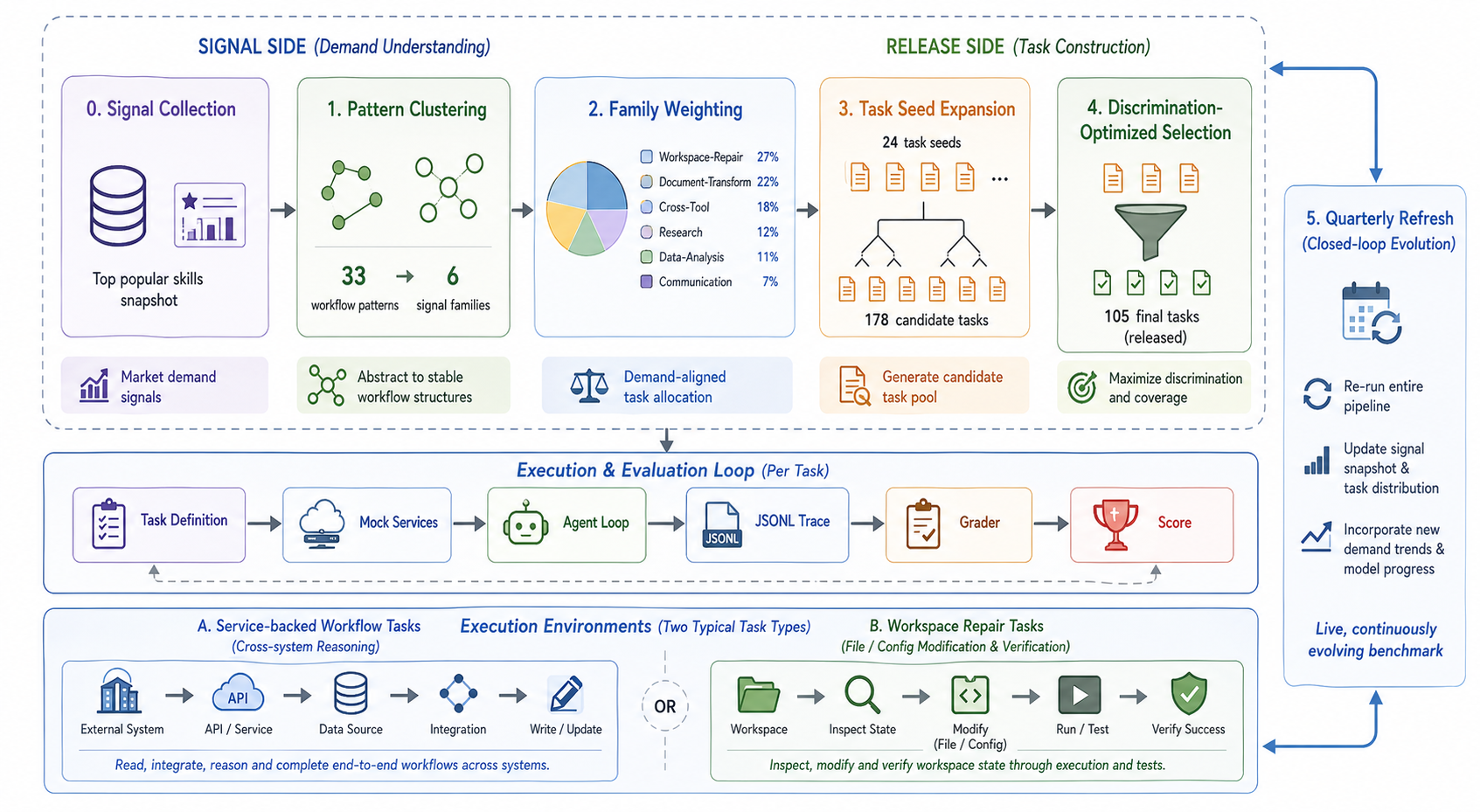
Figure 1: Claw-Eval-Live overview, detailing the periodic process from public workflow signal collection through task clustering, selection, execution, and double-grounded grading for evolving, discriminative benchmark releases.
Signal-to-Task Pipeline and Release Construction
A defining feature of Claw-Eval-Live is its signal-calibrated construction pipeline. Rather than relying solely on expert curation or historic datasets, Claw-Eval-Live sources its priors from a refreshable snapshot of popular skills in the tool ecosystem (e.g., ClawHub Top-500), which represent externally observable signals regarding prevailing workflow demands.
The release generation pipeline is comprised of:
- Signal Collection: Time-stamped gathering of public workflow usage indicators, each with provenance and functional labeling.
- Pattern Clustering: Grouping signals by shared user objective, affected artifact types, and required execution surfaces, yielding stable workflow patterns.
- Family Weighting: Aggregation of pattern-level signal strength into weighted task families for mixture calibration.
- Seed Expansion and Implementation: Transformation of weighted patterns into executable, pilot-screened candidate tasks with curated fixtures and graders.
- Discrimination-Aware Selection: MILP-based optimization to select a subset maximizing family coverage and inter-model discrimination, while filtering brittle and non-discriminative tasks.
This methodology guarantees that each public release is both representative of real-world demand at a specific point in time and robust to reproducible, traceable evaluation.
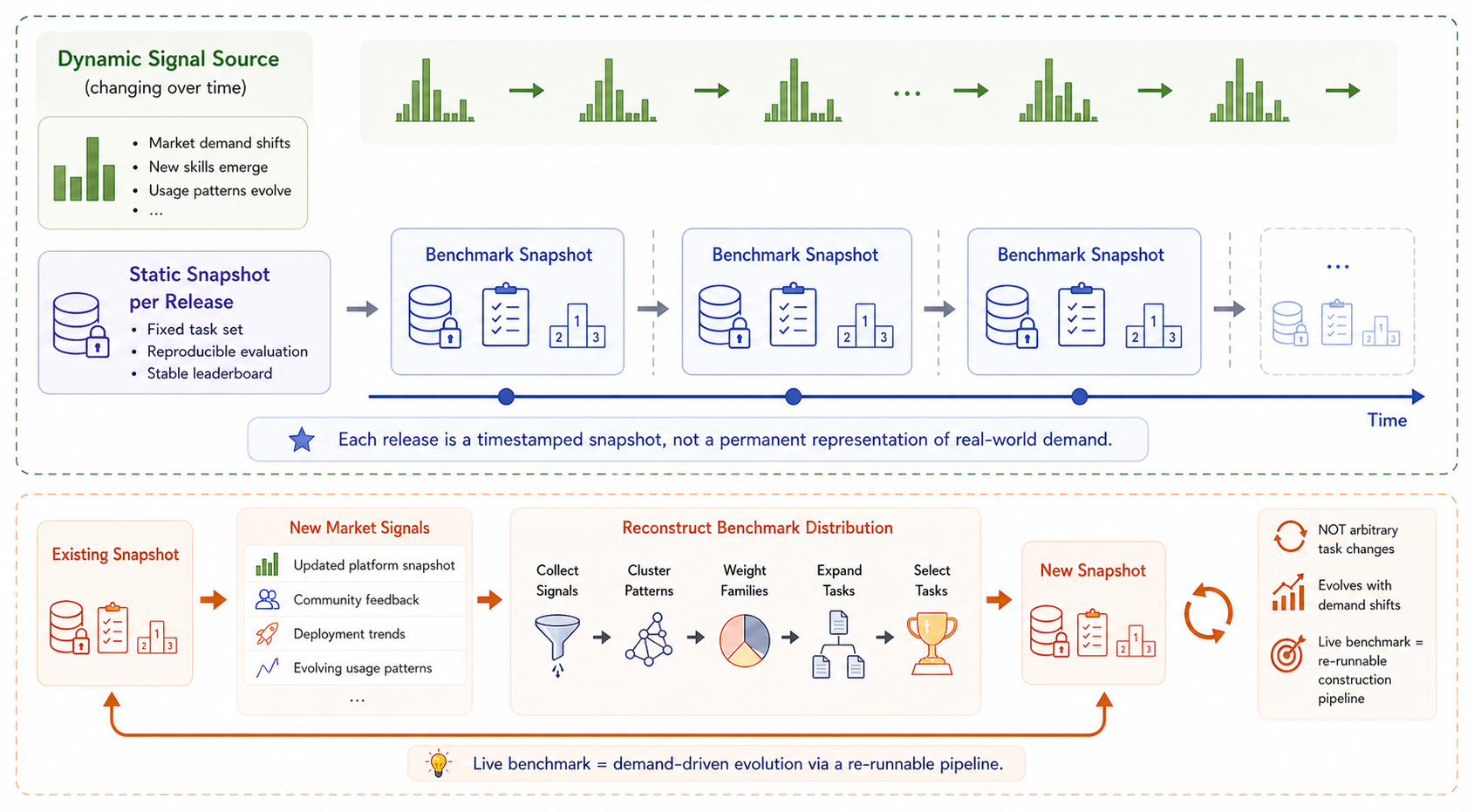
Figure 2: Signal-to-snapshot construction, showing the mapping from public workflow signal clusters to weighted, pilot-screened, discrimination-aware benchmark releases.
Benchmark Composition and Evidence-Based Grading
Claw-Eval-Live partitions its task suite between two key execution surfaces:
- Service-Backed Workflows: Tasks operationalized through business-facing services (CRM, finance, calendar), demanding correct, cross-system stateful interactions.
- Workspace Repair: Terminal and local environment tasks (e.g., SHELL/W-family), emphasizing artifact-level inspection, edits, and post-run verification.
Each task instance is a fully executable workflow, with YAML task definitions, controlled fixtures, explicit tool schemas, and deterministic or hybrid graders. The grading architecture is hierarchical:
- Rule-Based Extraction: Deterministic checks from tool traces, audit logs, and post-run artifacts for core data retrieval, accuracy, and action verification.
- LLM Judging (GPT-5.4): Applied strictly for semantic facets unresolvable by deterministic means, strictly bound to observable evidence and scoring rubrics.
This dual-pronged approach directly addresses the limitations of output-only grading, instead evaluating the "can do" (actual trajectory and action completion) rather than mere "can say" (final answer fluency).
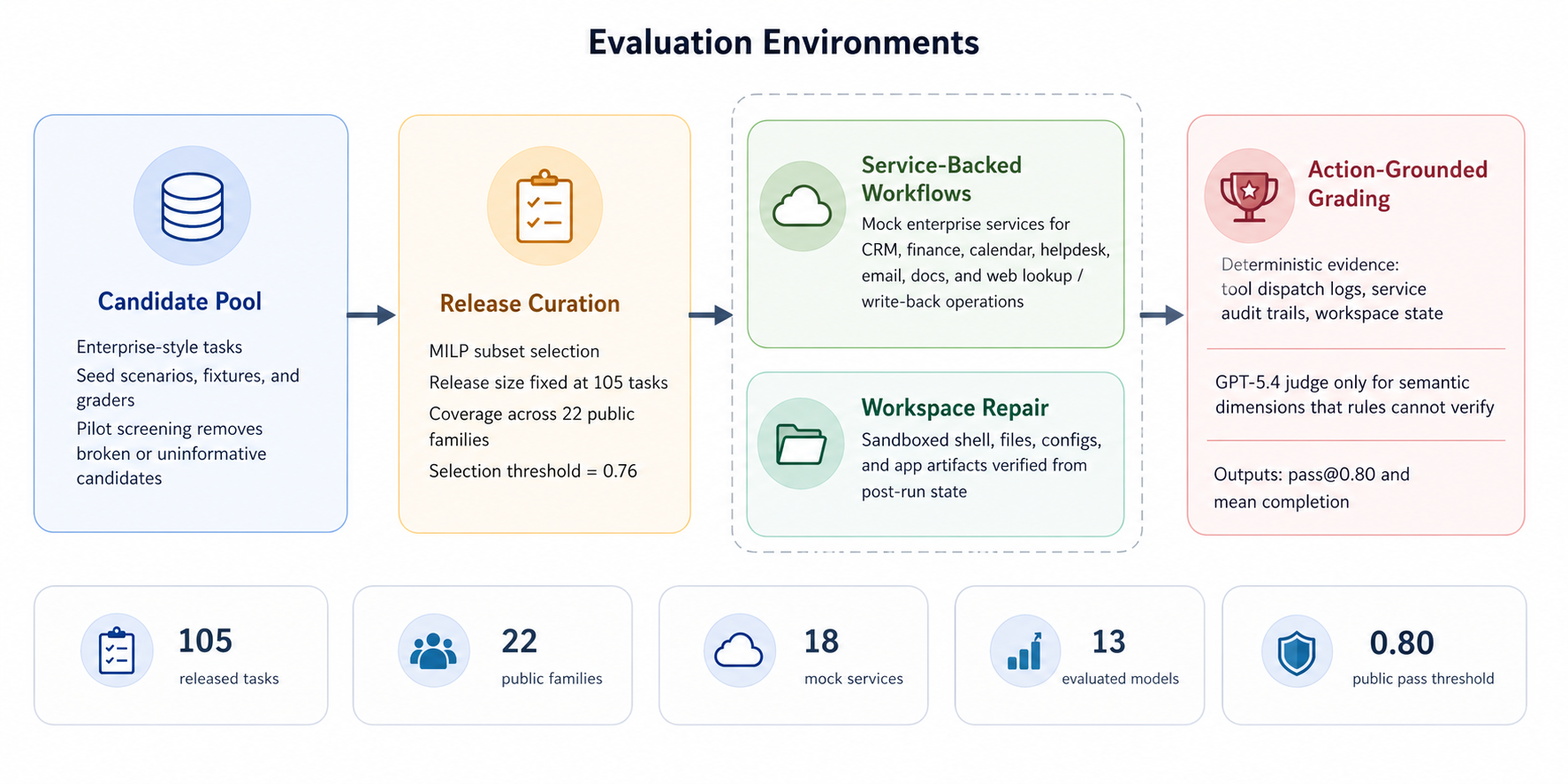
Figure 3: End-to-end benchmark pipeline: piloting, screening, curation, environment execution, and evidence-based grading, with LLM judges invoked as needed for semantic assessments.
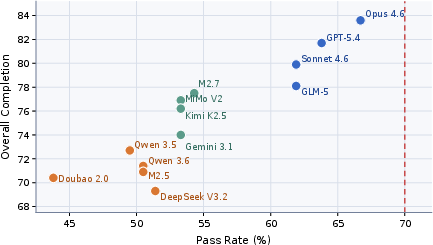
The current public release consists of 105 tasks spanning 22 finely-grained workflow families, evaluated on 13 frontier models. The main leaderboard metrics are:
- Pass Rate: Fraction of tasks passed under a stringent threshold (0.80).
- Overall Completion: Mean score across all tasks.
Key highlights from the reported results:
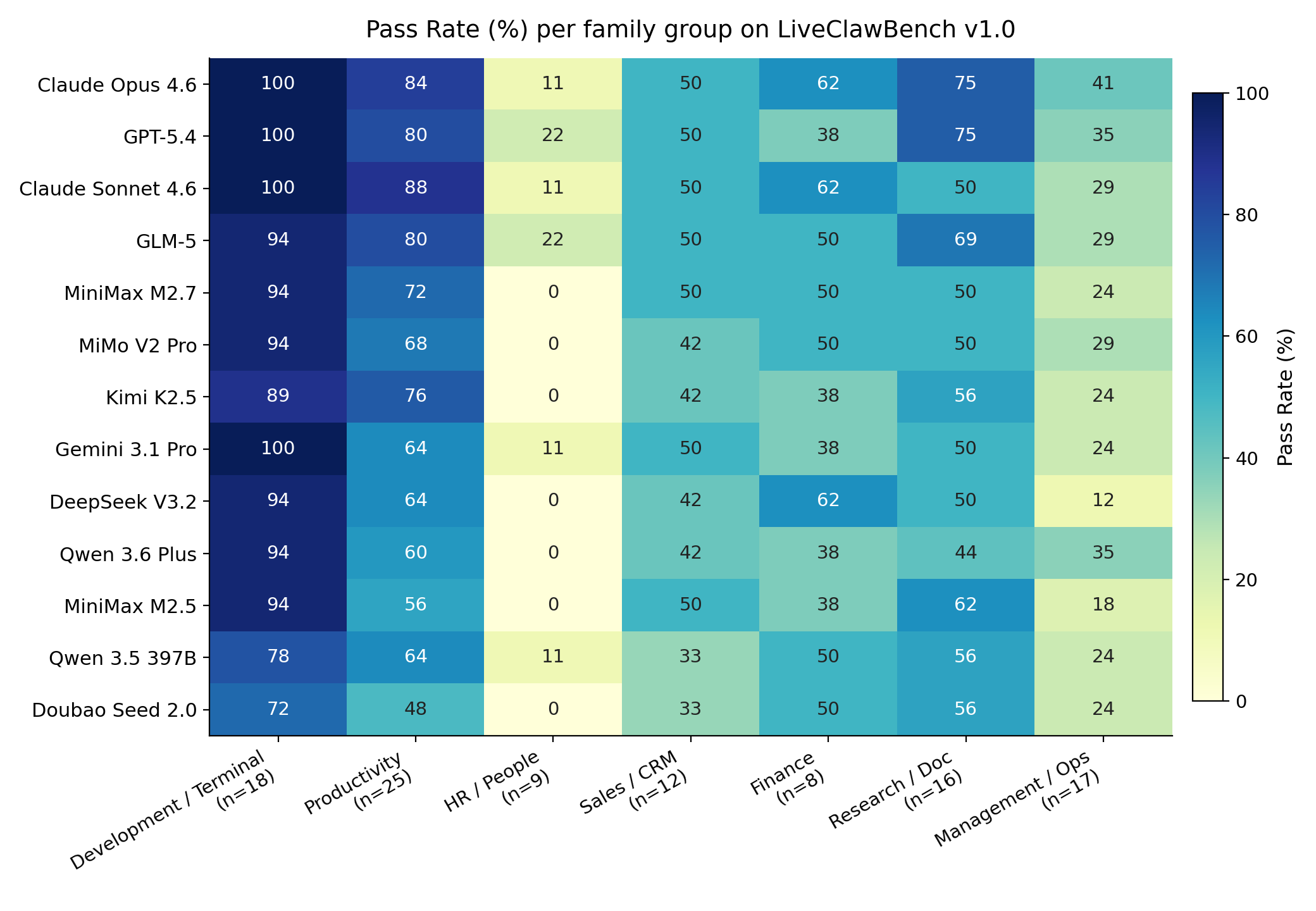
Family-level disaggregation reveals pronounced heterogeneity:
Service-backed workflows, in particular, are unsolved: even the best models are below 60% pass rate, whereas local workspace tasks often approach or reach 100%.
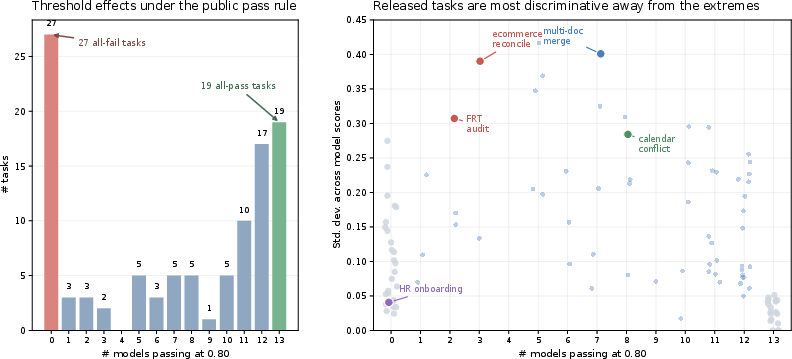
Task Discrimination and Benchmark Integrity
Task-level analysis shows pronounced threshold effects:
This meticulous calibration ensures that Claw-Eval-Live is not susceptible to ceiling/floor effects and delivers meaningful separation among agent capabilities.
Practical Implications and Future Development
The dual grounding in live signal distribution and observable agent action differentiates Claw-Eval-Live from prior, static or solely output-verified benchmarks. The findings point to several substantive implications:
- Current LLM-based workflow agents are well below deployment-suitable reliability, especially for business-critical, multi-system coordination and nuanced HR/management workflows.
- Practical deployment must consider not only leaderboard position but also detailed family-level accuracy and API usage efficiency.
- The static nature of most existing benchmarks makes them susceptible to drift with environmental/tooling change, underscoring the value of Claw-Eval-Live's refresh protocol for continued relevance.
Theoretically, Claw-Eval-Live could inform the development of more sophisticated agent architectures that:
- Better model cross-system evidence requirements and action dependencies.
- Exhibit more robust procedural grounding and less reliance on superficial output forms.
- Adapt dynamically to changing real-world workflow distributions.
Future expansions may include finer-grained, real-time task calibration, extension to multimodal and mobile workflows, and integration with deeper process trace analysis to further close the "can do"–"can say" gap.
Conclusion
Claw-Eval-Live advances the state of agent benchmarking by introducing a live, double-calibrated standard that mirrors the evolving, heterogeneous landscape of real-world workflow automation demands. The focus on reproducible, time-stamped snapshot releases, combined with rigorous evidence-based grading, exposes fundamental challenges and progress gaps facing current workflow agents. The approach not only strengthens evaluation reliability for both researchers and practitioners but also lays the groundwork for a more responsive, continuously relevant benchmarking paradigm in autonomous agent research.