World of Workflows: a Benchmark for Bringing World Models to Enterprise Systems
Abstract: Frontier LLMs excel as autonomous agents in many domains, yet they remain untested in complex enterprise systems where hidden workflows create cascading effects across interconnected databases. Existing enterprise benchmarks evaluate surface-level agentic task completion similar to general consumer benchmarks, ignoring true challenges in enterprises, such as limited observability, large database state, and hidden workflows with cascading side effects. We introduce World of Workflows (WoW), a realistic ServiceNow-based environment incorporating 4,000+ business rules and 55 active workflows embedded in the system, alongside WoW-bench, a benchmark of 234 tasks evaluating constrained agentic task completion and enterprise dynamics modeling capabilities. We reveal two major takeaways: (1) Frontier LLMs suffer from dynamics blindness, consistently failing to predict the invisible, cascading side effects of their actions, which leads to silent constraint violations, and (2) reliability in opaque systems requires grounded world modeling, where agents must mentally simulate hidden state transitions to bridge the observability gap when high-fidelity feedback is unavailable. For reliable and useful enterprise agents, WoW motivates a new paradigm to explicitly learn system dynamics. We release our GitHub for setting up and evaluating WoW.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy Explanation of “World of Workflows: a Benchmark for Bringing World Models to Enterprise Systems”
What is this paper about?
This paper builds a realistic “test world” called World of Workflows (WoW) to see how well AI assistants (like big chatbots) can work inside complex company software. In these systems, doing one thing (like assigning a device to a person) can secretly trigger a chain of other changes in different databases—like dominoes falling. The paper shows that today’s AIs are good at following simple instructions but often miss these hidden chain reactions, which can break company rules without anyone noticing.
What were the researchers trying to find out?
The authors focused on three simple questions:
- Do hidden “workflows” (automatic rules in the system) make it hard for AI agents to finish tasks while following company rules?
- If we give the AI better visibility into what’s changing behind the scenes, does it become more reliable?
- Can today’s AI models “imagine” the hidden side effects of their actions, even when they can’t see everything?
How did they test it?
They built a realistic environment using ServiceNow (a popular enterprise platform) and a benchmark called WoW-bench.
- WoW includes:
- 4,000+ business rules and 55 active workflows (think: lots of if-then rules and automated processes).
- Tools the AI can call (APIs) to perform actions, like creating tickets or changing user roles.
- Partial visibility: the AI doesn’t see everything that changes—just some feedback.
- Two types of “what the AI can see”:
- Tool responses: basic messages like “success” or “error.” This is how most systems work—quick, but hides side effects.
- Audit logs: a detailed list of what changed in the database (like receipts). This gives much more visibility but is harder to get in real life.
- Four kinds of tasks (234 total):
- Agentic tasks: multi-step jobs that require planning and checking rules over time.
- Constraint understanding: tasks that test whether the AI can spot when hidden workflows silently break a rule.
- Action prediction: given some changes, guess which tool action caused them.
- Audit prediction: given an action, predict exactly what will change behind the scenes.
Key idea explained simply:
- “Workflow” = a chain of automatic actions triggered by a change. Like: “If a student gets more than 3 library books, their access level drops by one.”
- “Partial observability” = the AI only sees a slice of what’s going on, not the whole system.
- “World model” = the AI’s mental simulator—its ability to predict what will happen next.
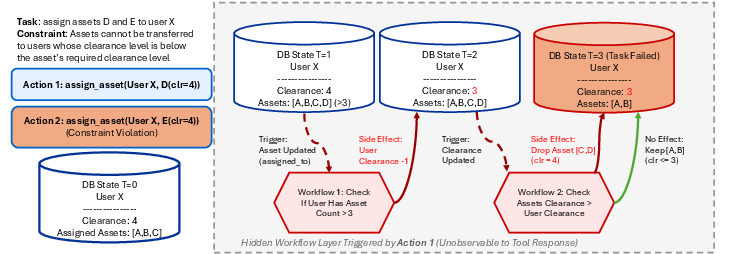
A simple example:
- The AI assigns two assets (D and E) to User X. Locally, that looks okay.
- Hidden workflow 1 kicks in: User X now has more than 3 assets, so their clearance is lowered.
- Hidden workflow 2 kicks in: some assigned assets are now “too high” for the lowered clearance, so those assets get removed.
- The AI only saw “success” messages—but behind the scenes, rules were broken and things changed.
What did they find?
- Today’s top AI models struggle in these complex systems. They often:
- Miss hidden side effects.
- Break rules without noticing.
- Confuse names with unique IDs (like mixing up “Alice” with her database ID).
- Fail to reason over multiple steps when things depend on each other.
- Giving the AI audit logs (the detailed “receipts” of changes) helped a lot:
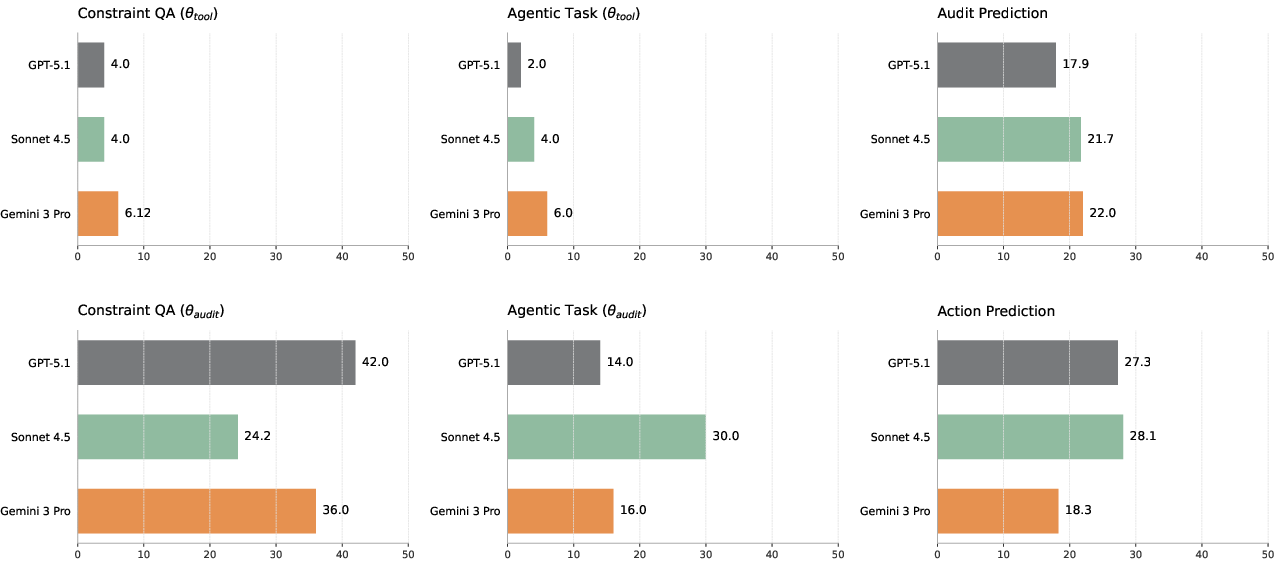
- Task success under rules went up by as much as 7x in some cases.
- For example, one model’s “rule-following success” jumped from about 2% to 14% with audit logs.
- But even with audit logs, performance was far from perfect—some reasoning problems remained.
- When asked to predict the hidden changes (audit prediction) or figure out which action caused them (action prediction), models performed under 30% accuracy. That means the AI’s “mental simulation” of the system is still very weak.
Why is this important?
In real companies, tasks have to follow strict rules—like permissions, privacy, safety, and approvals. If an AI can’t predict or notice hidden chain reactions, it may:
- Think it completed a task when it actually broke a rule.
- Make silent mistakes that affect other parts of the system.
- Be unreliable for real work.
This benchmark shows that making AIs safe and reliable isn’t just about better instructions—it’s about teaching them how the “world” of enterprise systems behaves behind the scenes.
What does this mean for the future?
The authors suggest a new direction for building trustworthy AI agents at work:
- Build dynamics-aware agents:
- Agents should keep a structured “mental map” of the system (who’s who, what’s assigned, what changed).
- They should simulate what might happen before acting, especially when they can’t see everything.
- They might use “probe” actions to learn system rules (like testing a button to see what it triggers).
- Don’t rely on “zero-shot” guessing:
- In complex, hidden systems, just prompting a model isn’t enough.
- Agents need to learn and update their internal models of how the system’s workflows behave.
Final takeaway
The paper introduces a realistic test bed—World of Workflows—that reveals a key weakness in today’s AIs: dynamics blindness, or not seeing and predicting the hidden chain reactions in enterprise software. Giving more visibility helps, but it isn’t a complete fix. To make AI reliable for real companies, we need agents that don’t just act—they understand and predict how their actions ripple through the system.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and benchmark.
- External validity: How well do findings transfer beyond ServiceNow to other enterprise stacks (e.g., SAP, Oracle, Salesforce, custom ERPs) with different schemas, workflows, and access models? Quantify generalization by porting WoW tasks to at least one additional backend.
- Workflow representativeness: Are the 55 workflows and 4.8K rules sufficiently representative of real enterprise dynamics? Provide a taxonomy of workflow types, coverage metrics (e.g., trigger patterns, side-effect breadth), and expert validation to assess realism and gaps.
- Cross-system integrations: Real enterprises involve cross-application automations (e.g., identity providers, email, ticketing across platforms). Add and evaluate workflows that trigger or depend on external systems and APIs to test agents under inter-system dynamics.
- Temporal/asynchronous behavior: Current environment appears predominantly synchronous; does it model queueing, time delays, scheduled jobs, and eventual consistency? Introduce and study latency/jitter effects on planning and state estimation.
- Concurrency and multi-actor interactions: How do agents cope with simultaneous edits, race conditions, and conflicting updates from other users or automations? Add multi-agent/concurrent scenarios to evaluate conflict detection and resolution.
- Scale stress testing: What happens as tables, records, and workflow counts scale 10–100×? Create scale-up variants to characterize performance degradation and memory/state-tracking failure modes.
- Minimal observability requirements: What is the least amount of state evidence (e.g., sampled audits, key tables only, event summaries) needed to reach acceptable TSRUC? Systematically ablate audit fidelity, sampling rate, and field redaction to find practical observability budgets.
- Audit availability constraints: Since full audits are costly/privileged, assess proxies (e.g., change-event streams, digest summaries, sampled logs) and measure the reliability/latency trade-offs relative to full-audit “oracle” observations.
- Metrics beyond final state: TSR/TSRUC are computed on final state; intermediate violations and recovery are not disentangled. Add metrics for per-step violations, time-to-violation detection, recovery success, and risk-weighted severity of violations.
- Order- and timing-aware audit scoring: Current IoU on audit tuples ignores ordering/temporal dependencies. Develop metrics that capture causal ordering, multi-row transactions, and partial-credit for correctly predicted tables/columns with minor value deviations.
- Tool parameter grounding: Many errors stem from ID vs. display-name confusion. Introduce and evaluate schema-grounded parameter typing, validation, and canonicalization layers; quantify reduction in representation errors.
- Dynamics-aware baselines: The paper motivates dynamics-aware agents but evaluates only zero-shot LLMs. Implement and compare baselines with explicit state stores, symbolic simulators, learned forward models, or model-based RL to measure the attainable gains.
- Learning from interaction: WoW is positioned as evaluation-only. Explore on-policy/off-policy training using audit traces, probe actions, and counterfactuals; report sample efficiency and generalization to unseen workflows.
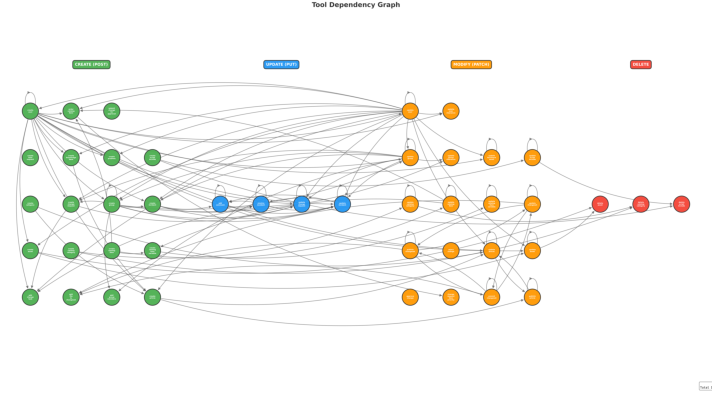
- Tool-Dependency Graph Sampling validity: The sampling method is only described in the appendix without validation of difficulty or coverage. Provide distributional statistics (path length, branching factor, dependency depth) and compare against alternative sampling schemes.
- Statistical rigor and variance: Report confidence intervals, per-task variance, and significance tests for TSR/TSRUC and audit/action prediction. Quantify run-to-run variability and sensitivity to prompt seeds and decoding parameters.
- Reproducibility details: Specify prompts, agent controllers, retry/validation policies, tool selection strategies, and seeds. Release evaluation harnesses to ensure comparable re-runs across labs and model updates.
- Long-horizon generalization: Agentic tasks average 13 steps; real workflows can span far longer horizons. Introduce curricula increasing horizon length and measure where causal rollout breaks.
- Partial documentation signals: Many enterprises provide schema docs and business rule text. Evaluate how supplying workflow/business-rule descriptions or schema metadata affects dynamics prediction and constraint compliance.
- Human-in-the-loop dynamics: Approvals, escalations, and manual overrides are common. Add approval gates and human feedback to measure collaboration strategies and the ability to plan around pending/failed approvals.
- Non-determinism and failure handling: Inject workflow failures, retries, exceptions, and inconsistent states; evaluate robustness, rollback strategies, and safe fallback planning.
- Versioning and environment drift: ServiceNow updates or configuration drift can alter behavior. Define version pinning, CI checks, and drift-detection protocols to ensure benchmark stability over time.
- Data leakage and prior exposure: LLMs may have been trained on ServiceNow docs, conflating domain familiarity with world modeling. Design unseen custom schemas/workflows and evaluate transfer to detect true dynamics learning.
- Economic efficiency metrics: Current “Cost/Task” conflates model pricing and token usage. Report normalized efficiency (tokens/action, actions/success, compute per TSRUC point) and sensitivity to observation verbosity (tool vs. audit).
- UI-API gap: Many real agents must mix UI and API interactions. Add mixed-modality tasks to evaluate handoffs, grounding, and error recovery across interfaces.
- Ethics and privacy constraints: Realistic data often include PII and strict access controls. Develop synthetic-yet-realistic PII patterns and access-control workflows to test compliance without violating privacy.
- Cyclic and conflicting workflows: How do agents handle cycles, conflicting rules, or oscillatory side effects? Introduce adversarial rule sets and termination conditions to study convergence and safe intervention strategies.
- Coverage of enterprise subdomains: Current modules focus on ITSM-like domains. Expand to finance/procurement, HR, and compliance-heavy processes to test constraint reasoning under varied policy regimes.
- Minimal state abstraction design: What forms of agent-internal state (e.g., key–value stores, knowledge graphs, fact tables) most reduce the representation gap? Benchmark alternative abstractions and their impact on dynamics prediction and TSRUC.
Glossary
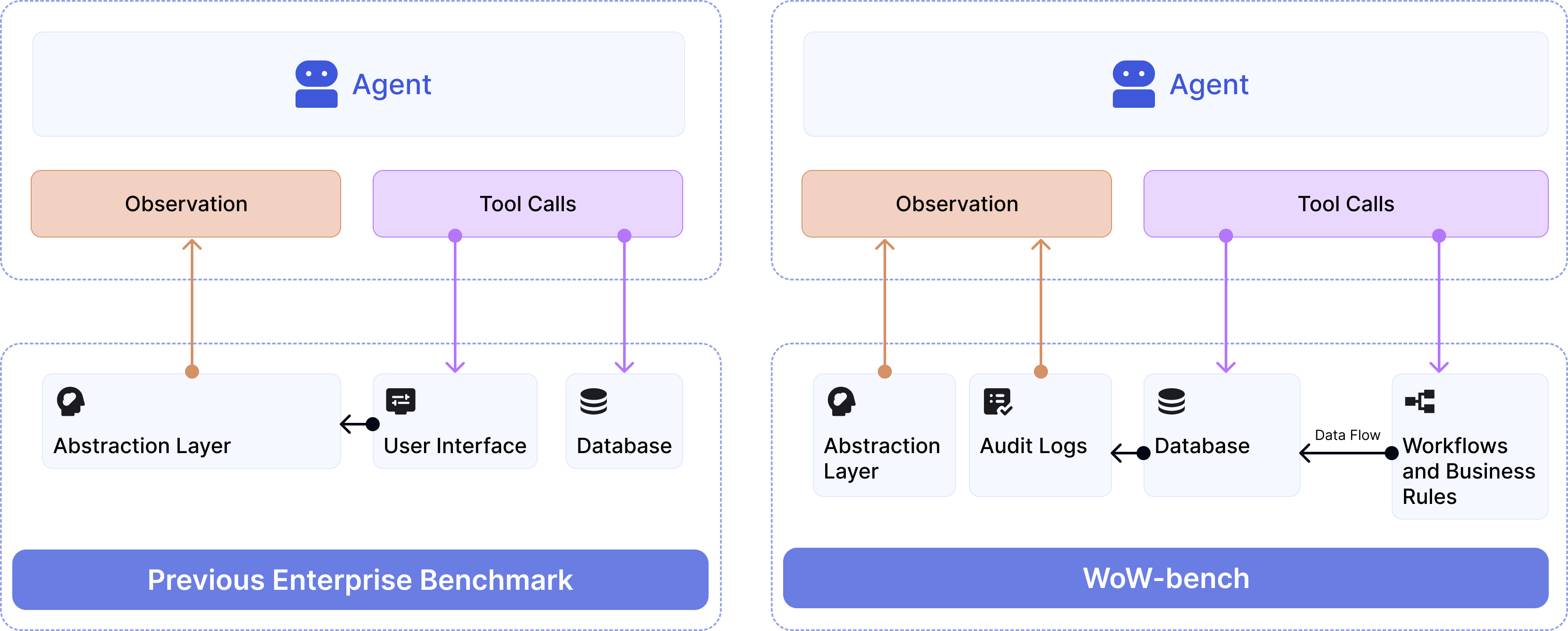
- Ablation study: a controlled comparison that varies one component of a system to measure its impact on performance. "WoW provides two forms of observations as an ablation study: tool response, which provides direct API feedback, and table audit logs, a structured representation of database state changes."
- Action Prediction: the inverse dynamics task of inferring which action produced an observed change in state. "Audit Prediction (Forward Dynamics) and Action Prediction (Inverse Dynamics) tasks."
- Agentic tasks: multi-step tasks requiring autonomous planning, decision-making, and tool use by an AI agent. "We designed 50 long-horizon agentic tasks (avg. 13 steps)"
- Audit logs: structured records of database updates that detail what changed, often used to trace side effects. "using audit logs as observation increases the task success rate by at most 7x"
- Big world hypothesis: the notion that the true world state is vast and only partially observable, making full state estimation intractable. "aligns with the big world hypothesis"
- Business rules: system-defined logic that automatically enforces policies or computations on database events. "There are 55 active workflows and 4.8K business rules in ServiceNow."
- Cascading side effects: downstream, indirect state changes triggered by an initial action, often via hidden workflows. "predict the invisible, cascading side effects of their actions"
- Causal rollout: forward simulation of cause-and-effect chains to anticipate future consequences before acting. "This highlights a breakdown in causal rollout."
- Constraint Understanding: the capability to determine which constraints apply and how actions may violate them in hidden or dynamic contexts. "For Constraint Understanding tasks specifically, success requires identifying the exact constraint violated and the action responsible (Exact Match)."
- Dynamics blindness: an agent’s failure to foresee system state transitions and hidden workflow-induced effects. "Frontier LLMs suffer from dynamics blindness, consistently failing to predict the invisible, cascading side effects of their actions"
- Forward Dynamics: predicting the next state or set of state changes given the current state and an action. "Audit Prediction (Forward Dynamics):"
- Grounded world modeling: maintaining an explicit, evidence-based internal model of hidden state transitions to bridge limited observability. "requires grounded world modeling"
- Intersection over Union (IoU): a set-overlap metric measuring the similarity between predicted and true sets of changes. "using Intersection over Union (IoU)."
- Inverse Dynamics: inferring the action that most likely caused an observed change in state. "Action Prediction (Inverse Dynamics):"
- MCP tools: Model Context Protocol tools that provide standardized tool-calling interfaces for agents to act via APIs. "Since the primary interaction method in WoW is MCP tools, we will not discuss the details of general software engineering and web agents."
- Model-Based Reinforcement Learning: an RL approach that learns a predictive model of environment dynamics to plan actions. "requires Model-Based Reinforcement Learning approaches"
- Observability gap: the mismatch between limited feedback available to the agent and the rich, hidden underlying system state. "A key hypothesis of this work is that the \"unreliability\" of current agents stems from an observability gap."
- Oracle observation: a privileged observation setting that exposes detailed state changes (e.g., audit logs) beyond standard tool feedback. "we introduce an oracle observation setting."
- Oracle-level state visibility: near-complete access to true state transitions, enabling more reliable long-horizon decision-making. "bridging the \"dynamics gap\" with oracle-level state visibility"
- Partially Observable Markov Decision Process (POMDP): a formal framework for decision-making where the agent receives incomplete information about the state. "we model the tasks in WoW as an Partially Observable Markov Decision Process (POMDP)."
- Relational database: a structured data model organized in linked tables representing the global enterprise state. "the complete configuration of the underlying relational database."
- State transition function: the mapping from a current state and action to the next state in a dynamical system. " is the state transition function."
- Symbolic grounding: linking textual references to stable, structured entities and identifiers in the system. "The Representation Gap: Lack of Symbolic Grounding"
- Task Success Rate (TSR): the proportion of tasks in which the stated goal is satisfied. "We report Task Success Rate (TSR) and Task Success Rate Under Constraint (TSRUC):"
- Task Success Rate Under Constraint (TSRUC): the proportion of tasks completed while also satisfying all constraints. "We report Task Success Rate (TSR) and Task Success Rate Under Constraint (TSRUC):"
- Tool-Dependency Graph Sampling: a trajectory construction technique ensuring outputs of one tool feed into inputs of subsequent tools. "a Tool-Dependency Graph Sampling technique"
- Workflows: orchestrated, multi-step automations that execute on triggers and can modify the database asynchronously. "There are 55 active workflows and 4.8K business rules in ServiceNow."
- World models: models that simulate environment dynamics to predict consequences of actions. "world models serve as predictive simulators for physical tasks"
- Zero-shot: performing a task without task-specific training data or examples. "effectively function as zero-shot world models"
Practical Applications
Immediate Applications
Below is a curated set of concrete applications that can be deployed now based on the paper’s findings and artifacts (WoW environment and WoW-bench). Each item notes target sectors, potential tools/products/workflows, and feasibility assumptions or dependencies.
- Pre-deployment evaluation of enterprise agents (buyer/vendor benchmarking)
- Sectors: ITSM/IT Ops, CRM, ERP, shared services
- Tools/products/workflows:
- “Enterprise Agent CI” pipelines that run WoW-bench suites (agentic tasks, constraint understanding, audit/action prediction) as release gates
- “Agent Reliability Scorecard” reporting TSR/TSRUC, cost per task, and dynamics-blindness indicators
- Assumptions/dependencies: Access to the open-source WoW repo; a ServiceNow developer instance; ability to replicate or adapt WoW tasks to the organization’s sandbox; model/tool-call cost budgets
- Audit-log augmented observability for agents (7x uplift opportunity)
- Sectors: ITSM, Compliance/GRC, Healthcare (EHR), Finance (core banking, payments), Government case management
- Tools/products/workflows:
- “AuditLens” adapters that stream normalized table audit deltas to agents (MCP-compatible observation channel)
- “Post-action reconciliation” workflows that compare expected vs observed audit deltas
- Assumptions/dependencies: Audit logs enabled and accessible (latency, cost, privileges); data privacy controls; mapping of native audit schemas to a common tuple format (Table, Column, Old, New)
- State-grounded agent design patterns (reduce identity/ID errors)
- Sectors: Software/platform teams building copilots; any enterprise with relational systems
- Tools/products/workflows:
- “ID Grounder” resolvers to canonicalize names → sys_id before write operations
- Lightweight “state store” or working memory that tracks entity state across turns
- Two-phase commit for tools: dry-run predict → execute → verify via audits
- Assumptions/dependencies: Tooling to query authoritative IDs; MCP tools that support dry-run or a read-before-write discipline; training prompts/policies emphasizing symbolic grounding
- Constraint guardrails and safety checks for hidden workflows
- Sectors: Compliance/GRC, Risk, SecOps
- Tools/products/workflows:
- “ConstraintGuard” that encodes dynamic constraints and runs pre-flight checks using known workflow dependencies or past audits
- “Shadow-mode execution” that simulates actions and flags possible cascading violations before committing
- Assumptions/dependencies: Formalization of constraints; mapping from constraints to relevant tables/workflows; logs or knowledge of historical workflow side effects
- EvalOps/MLOps for agent updates in enterprise environments
- Sectors: Software, Platform Engineering, DevOps
- Tools/products/workflows:
- CI/CD integration where prompt/model/tooling changes must pass WoW-bench regression gates
- Canary evaluations on sandbox instances with automatic rollback on TSRUC regressions
- Assumptions/dependencies: Sandboxed environments mirroring production workflows; budget to run periodic test suites
- Training and upskilling (curriculum/labs on enterprise dynamics)
- Sectors: Academia (CS/IS), Enterprise L&D, Professional services
- Tools/products/workflows:
- Course modules on POMDPs in enterprise systems; hands-on labs using WoW’s audit/action prediction tasks
- Internal training for SRE/IT analysts on reading audit trails and spotting cascading side effects
- Assumptions/dependencies: ServiceNow developer instances for students/teams; curated datasets and task packs
- Vendor product improvement and transparent claims
- Sectors: LLM/model vendors, enterprise ISVs
- Tools/products/workflows:
- Use WoW-bench to produce public model cards showing TSRUC and dynamics metrics
- Fine-tune tool-use policies to reduce “dynamics blindness”
- Assumptions/dependencies: License clarity for benchmark usage; standardized reporting formats
- Consumer/no‑code automation “flow preview”
- Sectors: Productivity/No-code (Zapier, IFTTT, Make)
- Tools/products/workflows:
- “Flow simulator” that shows predicted downstream changes across connected apps before publishing a rule
- Assumptions/dependencies: Platform APIs that support dry-run or audit-like introspection; manageable cost/latency for previews
Long-Term Applications
These opportunities build on the paper’s call for dynamics-aware, state-grounded agents and will require additional research, productization, or standardization.
- Dynamics-aware enterprise agent architectures (model-based control)
- Sectors: Software/AI platforms, Enterprise ISVs
- Tools/products/workflows:
- World-model components trained on audit deltas to predict
- Neuro-symbolic planners combining entity graphs with workflow triggers
- Assumptions/dependencies: Large-scale, privacy-compliant audit datasets; compute for simulation; acceptance of active “probe” strategies in sandboxes
- Enterprise digital twin for IT workflows (“what-if” engines)
- Sectors: ITSM, ERP, CRM
- Tools/products/workflows:
- Real-time emulators that simulate multi-hop workflow cascades for proposed changes
- Change-advisory tools that estimate TSRUC before rollout
- Assumptions/dependencies: Access to workflow definitions or sufficient audit-derived surrogates; accurate transition models; seamless integration with change management
- Cross-system world-model standards and adapters
- Sectors: Standards bodies, major vendors (ServiceNow, SAP, Oracle, Salesforce)
- Tools/products/workflows:
- Common audit delta schema and “Audit RPC” for MCP
- Interchange format for workflow triggers and constraints
- Assumptions/dependencies: Vendor buy-in; backward compatibility; governance around data sensitivity
- Autonomous change and risk control in production
- Sectors: GRC/Compliance, SRE/IT Ops
- Tools/products/workflows:
- Runtime “pre-execution simulation” with policy guards; automated remediation if predicted TSRUC < threshold
- Continuous monitoring comparing predicted vs observed audits to detect drift or novel cascades
- Assumptions/dependencies: Low-latency prediction; operational safety cases; human-in-the-loop governance
- Auditing-as-a-service and anomaly/cascade detection
- Sectors: Security, Finance, Healthcare compliance
- Tools/products/workflows:
- Services that learn expected cascade patterns and flag deviations or silent violations in near-real-time
- Assumptions/dependencies: Secure data sharing; contractual/regulatory alignment (HIPAA, SOX, PCI)
- Regulatory certification and procurement frameworks for AI agents
- Sectors: Public policy, Enterprise procurement
- Tools/products/workflows:
- “Enterprise Agent Reliability Grade” requiring passage of WoW-like benchmarks for certain risk classes
- Procurement checklists emphasizing observability (audit feeds) and constraint adherence (TSRUC)
- Assumptions/dependencies: Coordination with regulators and standards bodies; industry consensus on metrics
- Sector-specific dynamics-aware applications
- Healthcare: Order set and CDS simulations to prevent cascading contraindications
- Finance: Pre-trade/post-trade workflow simulation for compliance and settlement dependencies
- Energy/Manufacturing: ERP/CMMS change simulations for asset/maintenance cascades
- Public sector: Case management with dependency-aware automation and auditability
- Assumptions/dependencies: Domain-specific constraint codification; integration with legacy systems; sector regulations
- Automated workflow fuzzing and safety verification
- Sectors: QA/Testing, Platform engineering
- Tools/products/workflows:
- Fuzzers generating sequences that intentionally trigger cross-rule cascades; formal verification for invariants
- Assumptions/dependencies: Rich sandbox instances; formal specs of invariants and allowed side effects
- Privacy-preserving world-model training on audits
- Sectors: Privacy tech, Regulated industries
- Tools/products/workflows:
- Federated or synthetic-audit training regimes; DP mechanisms for audit data
- Assumptions/dependencies: Advances in privacy-preserving ML; representative synthetic generation
- Consumer-grade “safe automation agents” with flow dynamics
- Sectors: Smart home, Personal finance, No-code platforms
- Tools/products/workflows:
- Agents that simulate hidden rule cascades across apps/devices before committing changes; rollback-ready plans
- Assumptions/dependencies: Vendor APIs supporting simulation/dry-run; user-consent UX; cost management
Notes on Feasibility and Dependencies
- Audit visibility is pivotal: The paper shows up to 7x gains with audit observations; however, enabling and streaming audits has cost, latency, and permission implications, and often requires escalated access.
- Generalization beyond ServiceNow: While WoW is ServiceNow-based, porting to ERP/CRM stacks needs schema mapping, workflow adapters, and potentially vendor cooperation.
- Current LLM limits: Frontier models exhibit “dynamics blindness” and low forward/inverse dynamics accuracy; near-term deployments will benefit from explicit state stores, ID resolvers, and post-action verification rather than pure zero-shot autonomy.
- Governance: Many applications require human-in-the-loop oversight, formalized constraints, and change-management integration to be operationally safe in production.
Collections
Sign up for free to add this paper to one or more collections.