- The paper introduces Chat2Workflow, a rigorous benchmark evaluating LLMs’ ability to generate executable visual workflows from multi-turn natural language instructions.
- It details a methodology that maps dialogue histories to JSON-to-YAML transformations, using pass and resolve metrics to ensure both format correctness and functional execution.
- Experimental analysis reveals significant gaps between representation accuracy and real-world execution, emphasizing the need for improved adaptive reasoning and error recovery.
Chat2Workflow: Systematic Benchmarking for Executable Visual Workflow Generation by LLMs
Motivation and Context
The automation of agentic workflows—sequences of structured operations orchestrated for real-world processes—has become a fundamental paradigm in industrial intelligence. Despite the proliferation of workflow platforms like Dify and Coze that map business logic into Directed Acyclic Graphs (DAGs) and YAML configurations, actual workflow development remains labor-intensive and error-prone, requiring domain expertise and extensive manual refinement. The central research question addressed is whether LLMs can generate executable workflows directly from natural language instructions robustly and reliably, especially across evolving requirements and multi-round dialogue interactions.
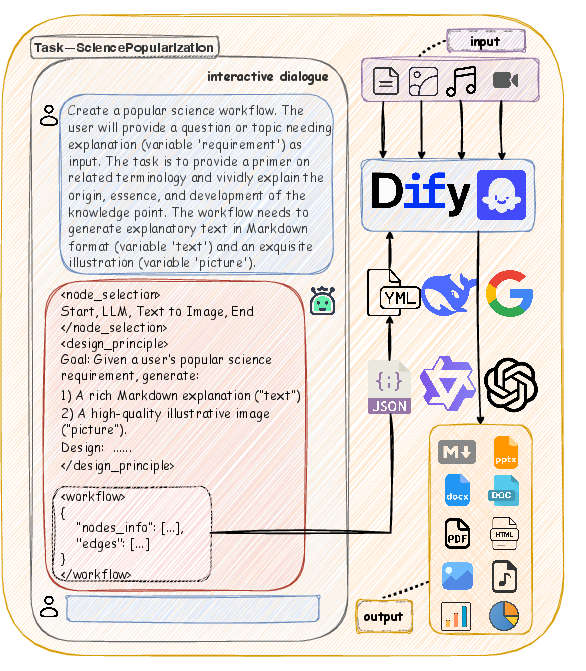
Figure 1: An illustrative Chat2Workflow task with realistic natural-language instructions and direct compatibility with industrial platforms.
Benchmark Design and Methodology
Chat2Workflow is constructed from 27 tasks spanning six representative domains: AIGC, Research, Document, Education, Enterprise, and Developer. Each task is composed of 2–4 rounds of multi-turn instructions, reverse-engineered from production workflows and augmented with domain-relevant test cases. The benchmarks enforce clear input/output variable specification and usage of key functional nodes, ensuring both breadth and depth in workflow complexity.
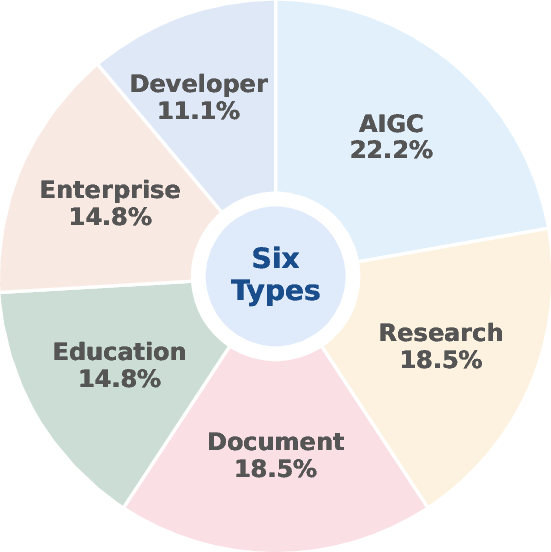
Figure 2: Task type distribution in Chat2Workflow, capturing six industrial domains.
Workflow Generation Pipeline
The generation task is formalized as a mapping from multi-turn dialogue (task instruction q, history H) to a graph-structured workflow G(V,E) via the LLM agent Mθ. The output is a simplified JSON representation comprising selected nodes, design rationale, and structured connectivity, which is transformed into executable YAML for platform compatibility. A curated knowledge base for the top 20 node types is provided as supplemental context.
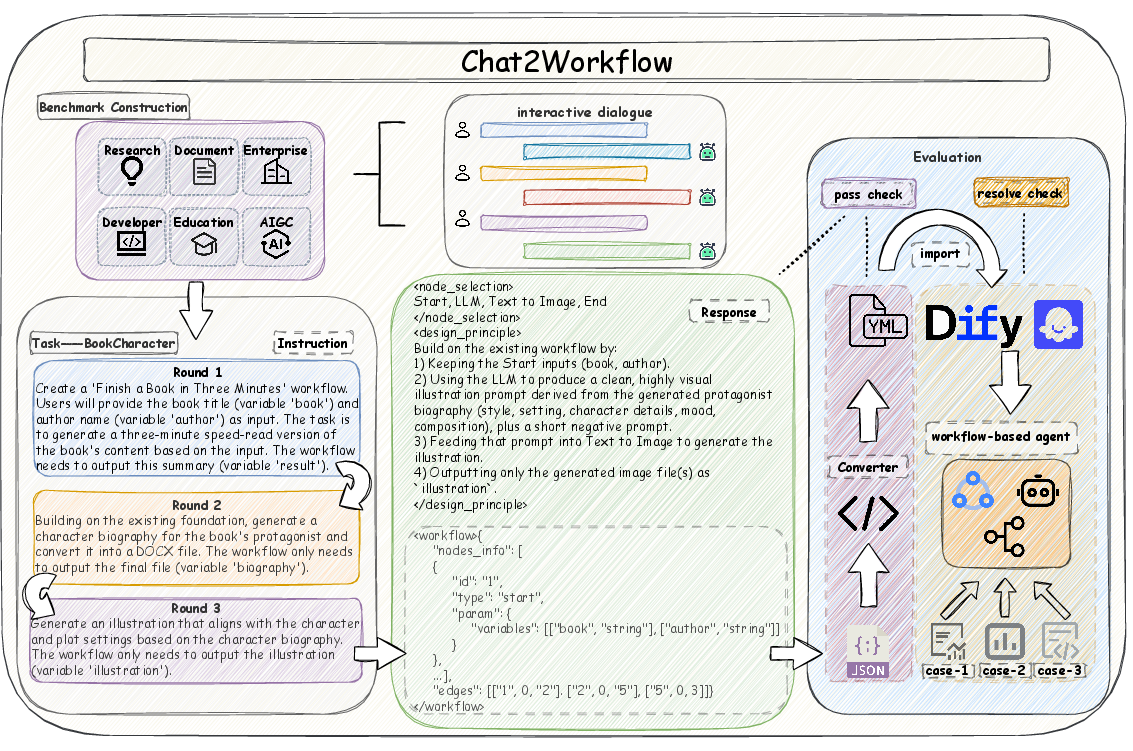
Figure 3: Construction and evaluation framework: workflow collection, dialogue-based generation, JSON-to-YAML transformation, and execution with pass/resolve metrics.
Evaluation Protocol
Chat2Workflow introduces a dual-stage evaluation: pass rate quantifies format correctness and logical consistency (see Algorithm 1 in the paper), while resolve rate assesses end-to-end functional adherence by verifying actual execution outputs against test cases (Algorithm 2). These metrics are semantically grounded, with automated LLM evaluations aligning closely with human judgments (100% for pass, 98.83% for resolve).
Experimental Analysis
Model Performance Across Domains
Fifteen LLMs (four proprietary, eleven open-source) are systematically benchmarked. Gemini-3-Pro-Preview attains the highest average resolve rate (71.59%), yet all models exhibit a significant disparity between pass rate and resolve rate. A correct format is insufficient for functional execution; inflated scores are frequent for representation-only metrics. GLM-4.6 demonstrates the maximum gap (20.96% average), emphasizing the fragility of current LLMs under operational constraints.
Long-Horizon and Evolving Instructions
Analysis of multi-round dialogues reveals consistent performance degradation across rounds for all models, corroborating the challenge of maintaining workflow fidelity under requirement evolution.
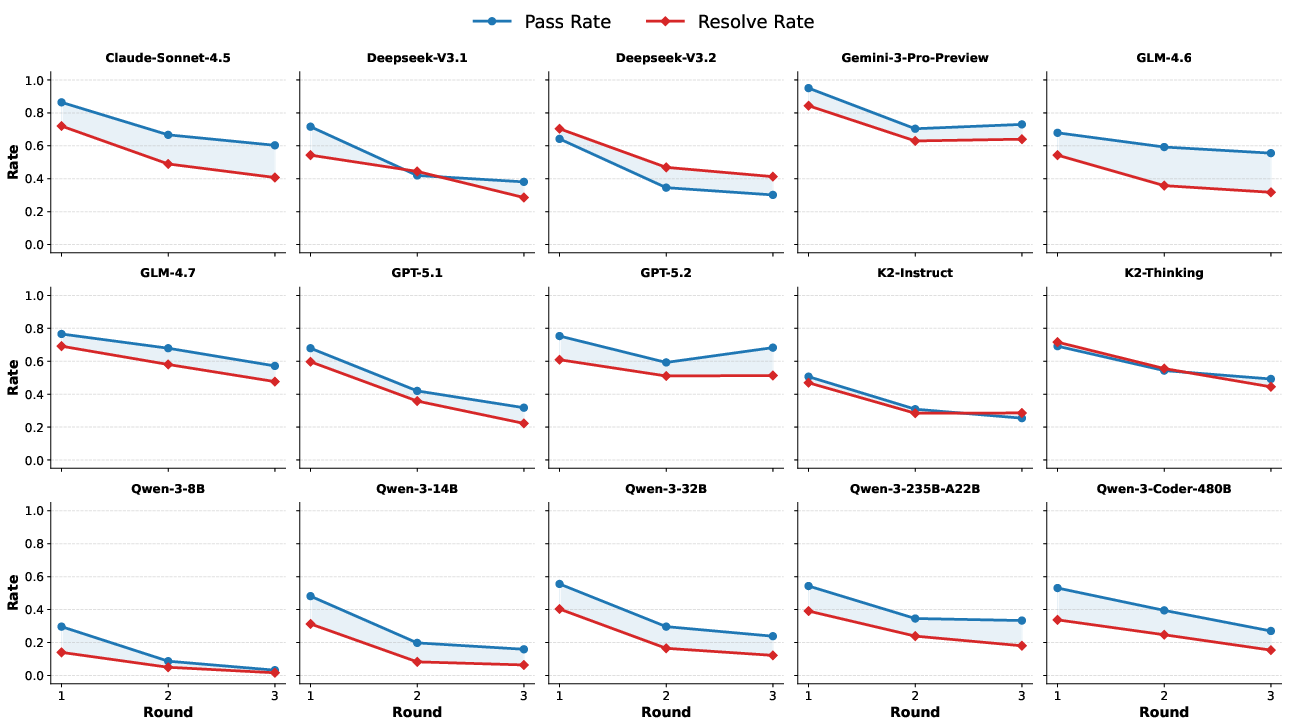
Figure 4: Pass and resolve rates decrease steadily as the number of dialogue rounds increases, exposing agentic brittleness under evolving scenarios.
Failure Modes and Case Analysis
Detailed inspection exposes characteristic failure modes: invalid edge connections (Kimi-K2-Instruct), logical inconsistency in node declarations (GLM-4.6), and brittle handling of iteration constructs. Only GPT-5.2 generates a valid and executable workflow in a complex StudyPlanner scenario.
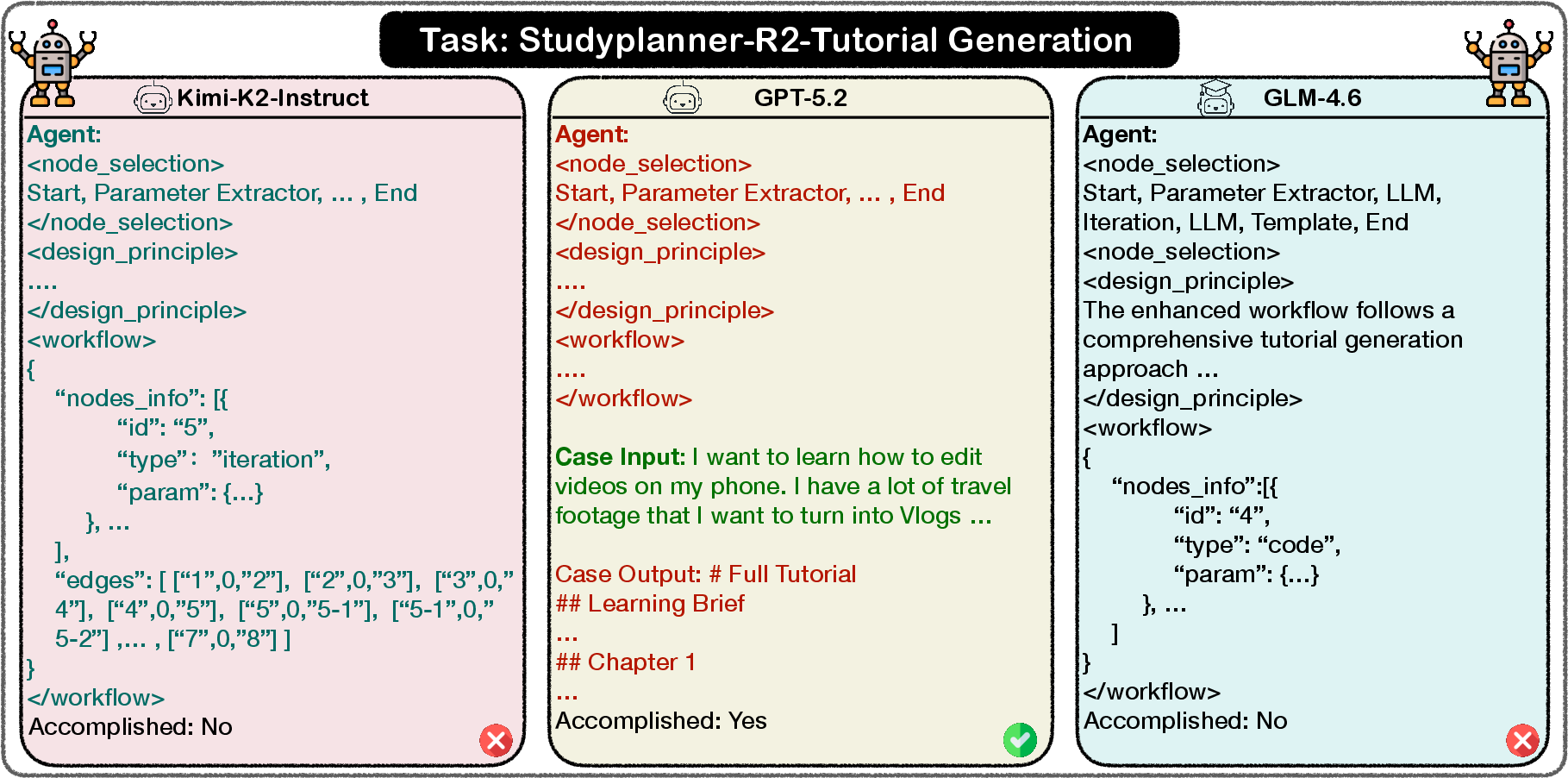
Figure 5: StudyPlanner outputs—invalid edge (Kimi-K2-Instruct), valid workflow (GPT-5.2), inconsistent declarations (GLM-4.6).
Platform-specific execution confirming GPT-5.2’s correctness is demonstrated below:
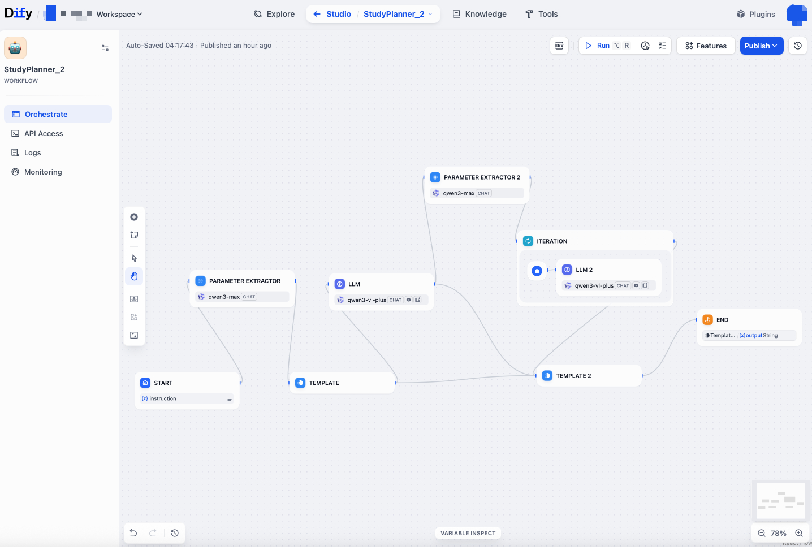
Figure 6: Dify workflow generated by GPT-5.2 in StudyPlanner round two.
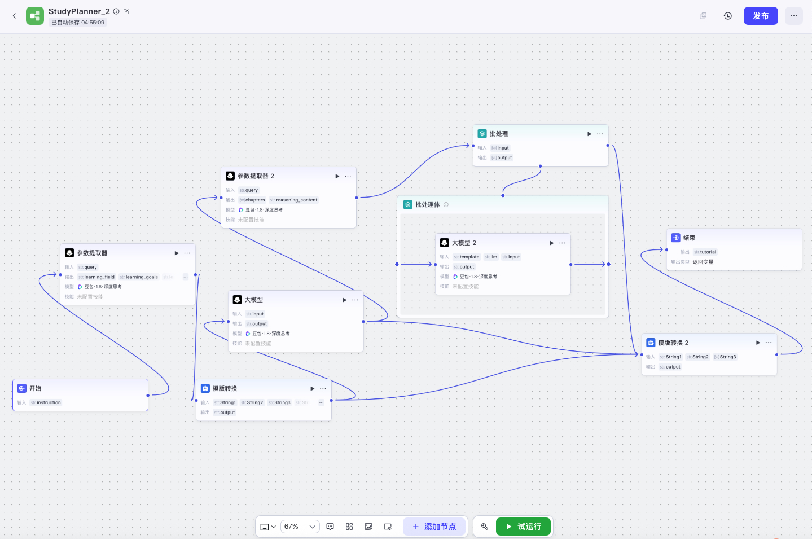
Figure 7: Coze workflow generated by GPT-5.2 in StudyPlanner round two.
Agentic Baseline and Error Recovery
An error-driven agentic framework, operationalized in OpenCode, employs structured variable summaries and targeted auto-repair modules (handling code fence malformations, JSON decode errors, topological violations, and node selection inconsistencies). Agentic prompting with five retry attempts delivers up to 5.34% absolute resolve rate improvements for GPT-5.2, but the models remain far from human-level reliability.
Chat2Workflow situates itself among benchmarks targeting tool-augmented LLMs, task automation, and planning/reasoning changes (e.g., TaskBench, PlanBench, ToolLLM, KnowAgent) but advances evaluation fidelity by enforcing strict execution checks and multi-turn dialogue handling. Existing works commonly fall short in ensuring real-world workflow usability, maintaining only format-level correctness or neglecting requirement evolution.
Implications and Future Directions
The empirical gaps identified in Chat2Workflow delineate the operational bottlenecks in current LLM-driven workflow automation:
- Practical automation is hindered by the semantic brittleness of output representations, inability to robustly handle requirement shifts, and the inadequacy of format-only validation.
- Larger model size yields consistent improvements, but domain post-training primarily enhances format adherence, not execution success.
- Agentic prompting (think vs. instruct) and explicit repair mechanisms demonstrate qualitative gains, but sustained, industrial-level reliability necessitates advances in structured reasoning, adaptive synthesis, and context management.
Future research is poised to explore lifelong agentic skill evolution, richer memory management frameworks, and scalable, domain-specific orchestration integrations for workflow engineering in enterprise-grade deployment scenarios.
Conclusion
Chat2Workflow provides a rigorous benchmark for advancing automated workflow generation with LLMs, emphasizing executable correctness, structural resilience, and adaptive reasoning over evolving requirements. Despite incremental improvements with agentic frameworks and larger models, a substantial real-world gap persists, underscoring the need for innovative research towards robust, adaptive, and fully automated workflow design and execution (2604.19667).

