Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
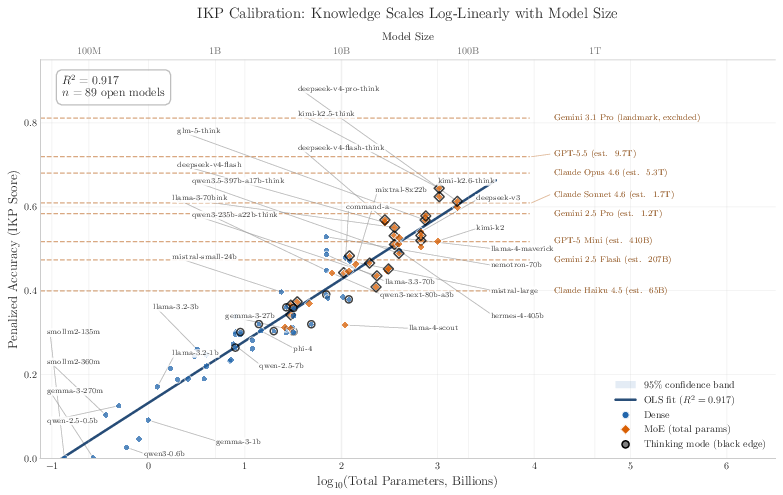
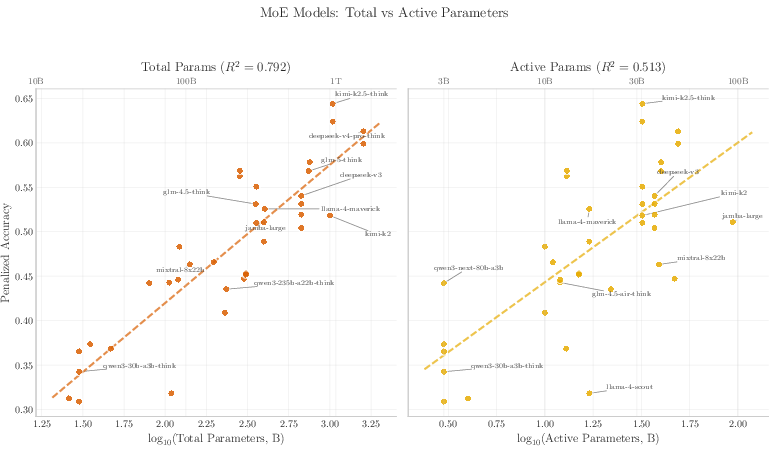
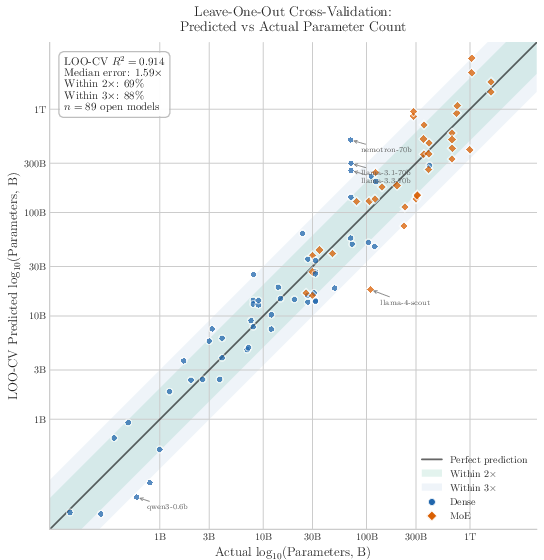
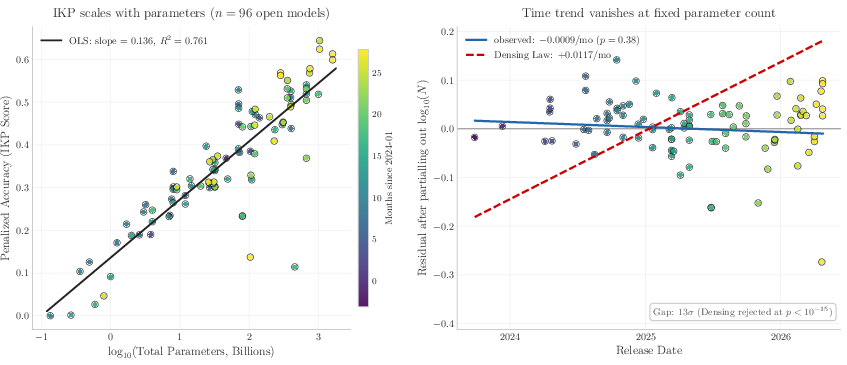
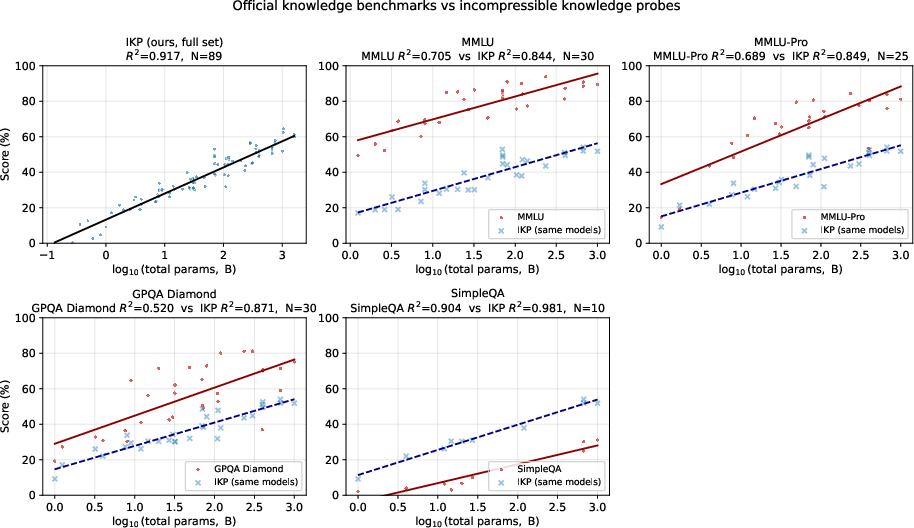
Abstract: Closed-source frontier labs do not disclose parameter counts, and the standard alternative -- inference economics -- carries $2\times$+ uncertainty from hardware, batching, and serving-stack assumptions external to the model. We exploit a tighter intrinsic bound: storing $F$ facts requires at least $F/$(bits per parameter) weights, so measuring how much a model \emph{knows} lower-bounds how many parameters it \emph{has}. We introduce \textbf{Incompressible Knowledge Probes (IKPs)}, a benchmark of 1{,}400 factual questions spanning 7 tiers of obscurity, designed to isolate knowledge that cannot be derived by reasoning or compressed by architectural improvements. We calibrate a log-linear mapping from IKP accuracy to parameter count on 89 open-weight models (135M--1,600B) spanning 19 vendors, achieving $R2 = 0.917$; leave-one-out cross-validation confirms generalization (median fold error $1.59\times$, $68.5\%$ within $2\times$ and $87.6\%$ within $3\times$). For Mixture-of-Experts models, total parameters predict knowledge ($R2 = 0.79$) far better than active parameters ($R2 = 0.51$). We evaluate 188 models from 27 vendors and estimate effective knowledge capacity for all major proprietary frontier models; for heavily safety-tuned models the estimates are lower bounds, since refusal policy can hide tens of percentage points of "refused but known" capacity. The widely-reported saturation of reasoning benchmarks does not imply the end of scaling. Procedural capability compresses under the "Densing Law," but across 96 dated open-weight models the IKP time coefficient is $-0.0010$/month (95\% CI $[-0.0031, +0.0008]$) -- indistinguishable from zero, and rejecting the Densing prediction of $+0.0117$/month at $p < 10{-15}$. Factual capacity continues to scale log-linearly with parameters across generations and across vendors.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Incompressible Knowledge Probes: A simple explanation
What this paper is about (the big idea)
The paper asks a surprisingly simple question: If a company won’t tell you how big their AI model is, can you still guess its size just by talking to it? The authors say yes. They test how many specific, hard-to-guess facts a model remembers. Because each fact takes up some “space” inside the model, the more rare facts a model can recall, the bigger it probably is.
Think of a model like a backpack. Reasoning skills are like clever ways to pack, but facts are like actual items. No matter how tidy you pack, if you bring more items, you need a bigger backpack. This paper measures the “items” (facts) to estimate the backpack’s size (the number of parameters).
What they wanted to find out (the key questions)
- Can we estimate the size of a black-box AI model (one we can use but can’t open) by testing what factual knowledge it has stored?
- Do newer training tricks make models “know more facts” without needing more size, or do facts still need real storage space?
- For special models that use many “experts” (Mixture-of-Experts, or MoE), is the total number of parameters what matters for storing facts, or just the part used at any moment?
- Can we tell whether two models are related (trained from similar data or not) just by how they answer rare questions—even when we can’t see their insides?
How they did it (the approach, in plain language)
The authors built a test called Incompressible Knowledge Probes (IKPs). Here’s how it works, using everyday ideas:
- They wrote 1,400 factual questions, spread across 7 levels from “common” to “really obscure.” The obscure questions are designed so you can’t figure them out with logic—they have to be memorized. Example: the exact founding year of a small museum, or a lesser-known researcher’s field plus a real paper title they wrote.
- They carefully avoided questions you could compute or guess by rules (like math or naming conventions). These would measure reasoning, not stored knowledge.
- They asked many open, known-size models these questions, always in the same way (temperature 0, direct answers). The model’s responses were judged as:
- Correct (full credit),
- Correct but weak (for certain researcher questions if you got the field right but didn’t name a real artifact; half credit),
- Refusal (like “I don’t know”; zero),
- Confidently wrong (a penalty).
- Penalizing confident wrong answers discourages bluffing.
- Then they looked for a simple relationship between “how well a model does on these fact questions” and “how many parameters it has.” They found a very clean pattern: as the number of parameters goes up by 10×, the IKP score increases by roughly the same amount each time (a log-linear relationship).
- After “calibrating” this pattern on 89 open models (whose sizes are known), they flipped it around: for a new, closed model, measure its IKP score and estimate how big it must be to store that much rare factual knowledge.
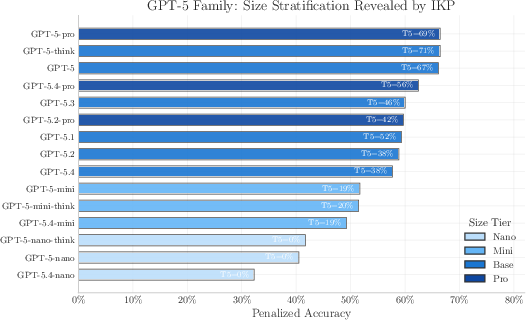
- For Mixture-of-Experts (MoE) models (imagine many specialist mini-models working together), they tested whether “total parameters” or “just the part switched on at a time” better predicts factual knowledge. Total parameters won.
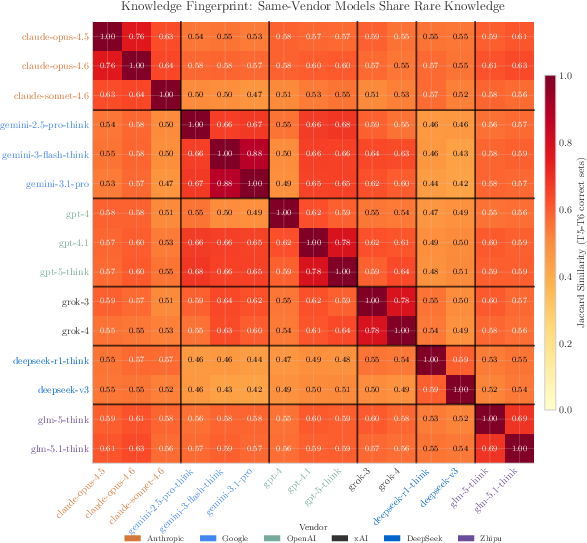
- They also introduced a “knowledge fingerprint” trick: if two models give the same weird wrong answers to obscure questions, they likely share training or lineage—even without seeing their code or weights.
What they found (the main results and why they matter)
Here are the most important findings:
- A strong size–knowledge link:
- Accuracy on IKP questions rises predictably with model size across 3 orders of magnitude. The fit is very strong (R² ≈ 0.92), which means IKP score is a reliable way to estimate a model’s parameter count.
- In simple terms: if a model knows more obscure facts, it’s almost certainly bigger.
- The estimates generalize well:
- In leave-one-out tests (pretend each model is unknown in turn), the typical error was about 1.6×. About 69% of models were within 2× and 88% within 3×. That’s good for a black-box method.
- MoE models: total size matters:
- For models that activate only some “experts” at a time, the total number of parameters predicts factual knowledge much better than the “active” parameters. Storing facts is a whole-model job.
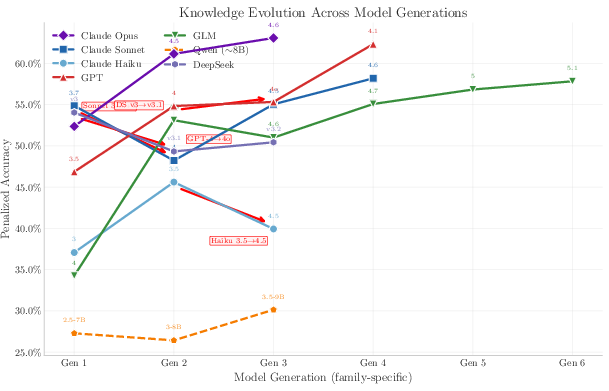
- Facts don’t “compress” like reasoning does:
- There’s a popular idea (the “Densing Law”) that models keep getting more capable per parameter as training tricks improve. That’s true for skills like reasoning and following instructions.
- But for pure facts, the authors found no improvement over time at fixed size. In other words, you can’t cram more rare facts into the same number of parameters just by changing training methods. Facts still need space.
- This supports the idea that factual knowledge is “incompressible”: each fact needs a certain number of bits, so more facts need more parameters.
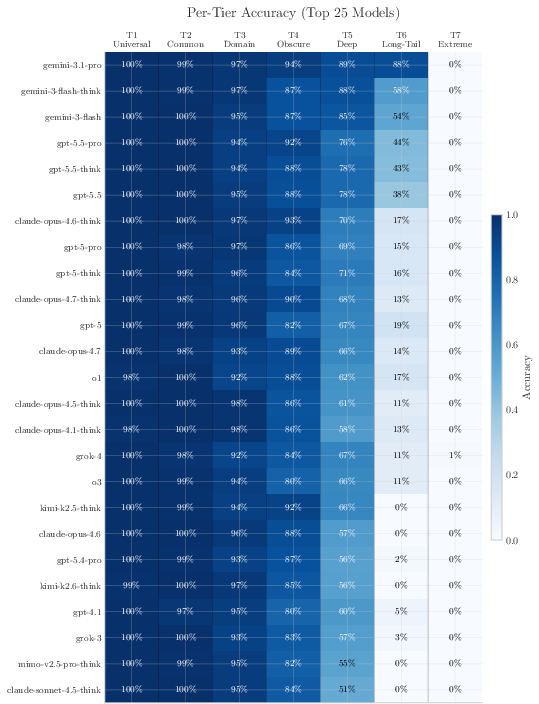
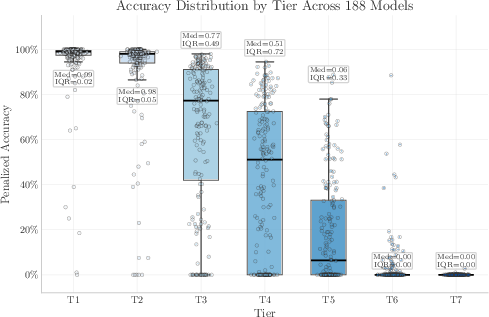
- Tiered difficulty reveals where models differ:
- Easy tiers (T1–T2) saturate fast—most decent models get them right.
- Middle tiers (especially T3) are most informative and separate models well.
- Very hard tiers (T6–T7) are almost impossible for open models; top proprietary models show some T6 gains, but T7 is still near-zero, acting like a “ceiling” for today’s training data.
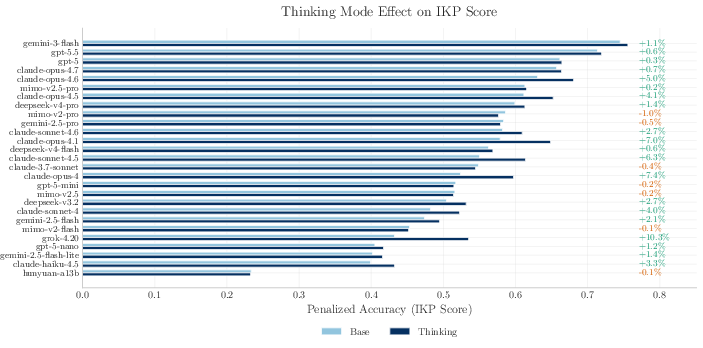
- Thinking mode helps a little, but doesn’t create facts:
- Asking a model to “think step by step” gives small gains for retrieving facts, especially on medium tiers, but it doesn’t add new knowledge to the model.
- Refusal policies can hide knowledge:
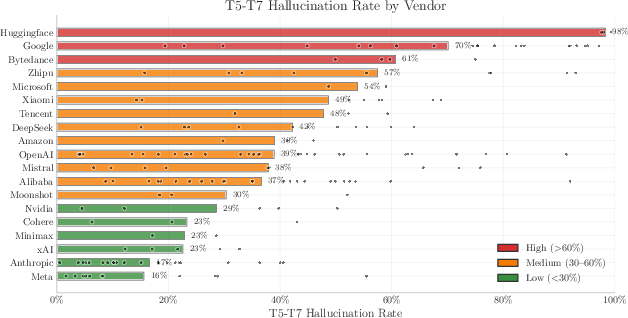
- Strong safety or refusal rules may make a model say “I don’t know” more often, lowering its IKP score even if it “knows” internally. So some estimates are lower bounds.
Why this matters (the impact)
- A new way to estimate model size from the outside:
- Companies often don’t share parameter counts. Older methods guessed size from price, speed, or hardware, but those can be misleading. IKPs give an “intrinsic” estimate by probing what the model actually knows.
- Clear evidence that scaling still matters for knowledge:
- Even if reasoning benchmarks seem “topped out,” this doesn’t mean we’re done scaling models. Rare factual knowledge keeps scaling with size.
- Practical tools for researchers and users:
- You can quickly compare models’ factual capacity, pick the right one for knowledge-heavy tasks, and spot when a “small” model is pretending to be big (or vice versa).
- The “knowledge fingerprint” method helps detect whether two black-box models are closely related—useful for auditing and transparency.
- Open resources:
- The authors released the questions, code, and results so others can run IKPs through a standard API and reproduce the estimates.
In short, this paper shows a simple-yet-powerful idea: count how many rare facts a model truly remembers, and you can estimate how big it really is. Reasoning can be made more efficient with better techniques, but facts still need storage. That means if we want models that know more of the world’s long-tail knowledge, we still need more parameters—or better (and probably larger) training data—because facts won’t squeeze themselves smaller.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes strong claims about estimating black-box LLM sizes via IKP factual capacity. The following concrete gaps and open questions remain for future research to address:
- External validity beyond English and current domains:
- The probe set is dominated by founding years and CS researcher subfields; evaluate whether the log-linear mapping holds for other fact types (e.g., biomedical, legal, cultural artifacts), low-resource domains, and non-English languages.
- Assess cross-lingual robustness (e.g., prompts and entities in Chinese, Arabic, Hindi) and tokenization effects on “incompressible” facts.
- Reliance on a single LLM judge:
- Results depend on Gemini 3 Flash Preview as the judge; quantify judge drift across versions and vendors, and establish inter-annotator agreement with human adjudication.
- Test judge ensembles and adjudication redundancy to bound systematic bias and rare-fact misclassification.
- Landmark dependence and reproducibility:
- Tiers are anchored by specific landmark models (including Gemini 3.1 Pro at T6), which can inflate within-family scores; develop an open-weight-only landmark ladder and a process to “freeze” landmarks for longitudinal comparability.
- Provide procedures to rebase tier assignments when landmarks change or become unavailable.
- Public benchmark gaming:
- Once probes are public, vendors can memorize them; design rotating, hidden, and adversarially-generated splits, and policy for periodical refresh, to maintain usefulness for black-box estimation.
- Prompting and scoring sensitivity:
- Quantify sensitivity to prompt wording, system prompts, and instruction styles (single-turn vs multi-turn, clarifying questions), as well as temperature/top‑p settings and sampling seeds.
- Report per-model confidence intervals from repeated runs; the current single-run, temperature-0 setup may understate variance for borderline cases.
- “Refused but known” capacity:
- Develop methods to estimate and correct for “known-but-refused” knowledge (e.g., refusal-overriding prompts, neutral paraphrases, or hint scaffolding) and integrate this into parameter estimates.
- Model the interaction between RLHF/safety tuning and IKP scores to separate accessibility from storage.
- MoE modeling granularity:
- The finding that total parameters outperform active parameters in predicting IKP accuracy needs finer controls: how do gating sparsity, expert load balance, shared-expert ratios, and router entropy affect factual storage?
- Establish standardized “total parameter” definitions across MoE implementations to avoid apples-to-oranges comparisons.
- Retrieval and tool-use confounds:
- Many frontier models integrate retrieval or tools; IKP forbids tools but APIs may silently retrieve. Create a retrieval-detected/blocked protocol and a retrieval-permitted variant to quantify how much external memory inflates apparent factual capacity.
- Quantization, pruning, and serving-stack effects:
- Characterize how different quantization levels, pruning strategies, KV-cache compression, and speculative decoding affect IKP accuracy and parameter estimates.
- Distinguish degradation in recall due to serving choices from true parameter-count differences.
- Data recency and quality confounds:
- The “Densing Law” falsification uses release date as a proxy for recipe progress; isolate data freshness and curation quality explicitly (e.g., matched-size retrains with more recent/cleaner data) to test whether bits-per-fact efficiency shifts over time.
- Assumptions about incompressibility:
- Correlated facts can compress; quantify per-probe entropy and residual compressibility to bound the “bits per fact” actually required by IKP items rather than citing global 2–4 bits/param results from synthetic setups.
- Test whether new architectures with structured memory (e.g., kNN-LM, product-key memories, recurrence) change effective bits-per-parameter for factual storage.
- Tier construction and popularity proxies:
- Tiers are validated by landmark monotonicity and seeded by Common Crawl frequency; evaluate alternative popularity/frequency signals (e.g., search logs, Wikipedia pageviews, OpenAlex popularity) and measure tier robustness across proxies.
- Expand T7 with facts known to appear in pretraining corpora at ultra-low frequency to disambiguate corpus-coverage ceilings from parameter ceilings.
- Statistical modeling and uncertainty:
- OLS on aggregate accuracy assumes homoskedasticity and linearity on log‑params; adopt a hierarchical per-tier logistic model with heteroskedastic errors and provide confidence intervals on slope/intercept and per-model estimates.
- Move from point estimates to Bayesian inversion with credible intervals that propagate judge error, sampling variance, and tier uncertainty.
- Extrapolation risk at the frontier:
- The calibration is based on open weights up to ~1.6T; parameter estimates >1.6T are extrapolations. Construct controlled open-weight scale-ups (or synthetic capacity sweeps) to validate linearity beyond current bounds.
- Coverage of dynamic/temporal facts:
- Most probes are static; design IKPs for time-varying facts (e.g., leadership changes) to test whether models store temporal slices vs rely on recency priors, and how that affects parameter estimates.
- API routing and version ambiguity:
- OpenRouter and vendor endpoints may serve A/B tested or upgraded backends without notice; include endpoint fingerprinting and version pinning to ensure the evaluated distribution is stable and identifiable.
- Evidence-aware researcher probes:
- The evidence bundles come from OpenAlex/DBLP and manual curation; quantify coverage gaps, long-tail author name disambiguation errors, and judge false positives/negatives on cited artifacts.
- Extend beyond CS researchers to other disciplines to test generality and reduce within-field training-data bias.
- Penalty design and model strategy:
- The chosen λ = −1.0 discourages bluffing and interacts with refusal policies; systematically explore alternative penalty schemes and their impact on calibration fit, especially for heavily safety-tuned or conservative models.
- Per-tier predictive sufficiency:
- T3 is most informative; formalize a minimal-cost sub-benchmark with error guarantees (sample size vs. estimation error trade-offs) for practitioners who cannot run all 1,400 probes.
- Hallucination-similarity fingerprinting:
- Provide formal power analyses, expected false-positive/false-negative rates, and robustness under prompt/temperature changes for the proposed Jaccard + shared-error test to distinguish retrains vs lineages.
- Distinguishing storage vs access:
- Develop interventions (e.g., few-shot cues, retrieval hints, CoT scaffolds) to separate “stored but hard-to-access” facts from “not stored,” enabling parameter estimates that account for retrieval latency within the network.
- Robustness to benchmark contamination:
- Since parts of IKP are derived from Wikidata and public corpora, verify that high scores reflect internalization rather than memorization via near-verbatim pretraining copies; add probes sourced from curated, license-compliant corpora with traceable inclusion/exclusion in known datasets.
- Ethical and policy considerations:
- Assess the implications of releasing a tool that estimates proprietary parameter counts; anticipate adversarial countermeasures (e.g., targeted memorization or obfuscation) and propose governance for responsible use.
These items aim to make the IKP framework more generalizable, robust, and trustworthy for estimating black-box model size and factual capacity.
Practical Applications
Overview
This paper introduces Incompressible Knowledge Probes (IKPs)—a 1,400-question benchmark that isolates factual knowledge stored in model parameters—to estimate black-box LLM parameter counts, audit long‑tail knowledge, and fingerprint model lineages via API-only access. Below are practical, real-world applications derived from the findings, methods, and tools, grouped by deployment horizon.
Immediate Applications
The following can be deployed now with the released IKP toolkit and standard model APIs.
- Stronger procurement and competitive analysis via API-only size estimates
- Sectors: software, cloud/AI services, finance (vendor due diligence), public sector procurement
- What to do: Use IKP to estimate effective parameter counts of proprietary models (with uncertainty bands) to inform buy/build decisions, pricing negotiations, and vendor comparison beyond throughput/pricing “inference economics.”
- Tools/workflows/products: Integrate the open-source IKP evaluator into model evaluation pipelines; schedule periodic runs on candidate APIs; track per-tier accuracy and aggregated parameter estimates.
- Assumptions/dependencies: Estimates carry wide prediction intervals (≈3× 90% PI); refusal-heavy models produce lower-bound estimates; temperature/prompt/judge must be held constant; testing must comply with API terms.
- Release-over-release regression detection and model selection
- Sectors: software, MLOps, enterprise IT
- What to do: Add IKP as a CI gate for API updates to detect factual knowledge regressions (e.g., tighter refusal policies) and re-route workloads to models with stronger T3–T5 performance for long-tail facts.
- Tools/workflows/products: “IKP smoke test” in model deployment CI; dashboards comparing tiered scores across versions; automated alerting when tier scores drop.
- Assumptions/dependencies: Stable prompts and judge configuration; some models may show step-changes on T6 due to landmark effects (documented in the toolkit).
- Knowledge routing and RAG policy tuning
- Sectors: software, search, enterprise knowledge management, healthcare and finance (regulated question answering)
- What to do: Use per-tier accuracy (especially T3–T5) to set thresholds for when to answer from parametric memory versus invoking retrieval/grounding to reduce hallucinations on rare facts.
- Tools/workflows/products: “Tier-aware” router that checks T3/T4 scores; fallback to retrieval when tier probability is high; A/B tests linking IKP tiers to retrieval triggers.
- Assumptions/dependencies: Domain mismatch may require a domain-specific IKP; IKP probes are in English and CS-heavy by default—extend probes to specific domains/languages for best effect.
- Safety/guardrail and refusal-policy audits (“refused but known” tax)
- Sectors: trust & safety, compliance, public sector
- What to do: Use the penalized scoring (WRONG < REFUSAL) and refusal rates to quantify how much knowledge is hidden by policy; calibrate guardrails to reduce unnecessary refusals without increasing bluffing.
- Tools/workflows/products: Refusal/bluffing heatmaps by tier; pre/post-safety-tuning IKP runs; policy tuning playbooks keyed to tier outcomes.
- Assumptions/dependencies: Penalization λ must be consistent; a conservative judge (e.g., Gemini 3 Flash Preview) is assumed to have low error rate (~0.1–0.2%).
- API lineage and serving verification with knowledge fingerprints
- Sectors: software, IP enforcement, marketplaces/platforms, governance
- What to do: Apply rare‑fact Jaccard overlap + hallucination similarity to detect whether an endpoint silently switched base weights, uses a sibling model, or is a full retrain/distill of another model.
- Tools/workflows/products: Continuous fingerprint monitors for API endpoints; “drift reports” indicating lineage regime changes; marketplace verification badges (“same weights,” “sibling,” “retrain”).
- Assumptions/dependencies: Requires consistent probing over time; similar fingerprints can arise from shared training data; ethical and legal review for fingerprinting use in commercial settings.
- MoE capacity audits and architecture decisions
- Sectors: model development, software (inference optimization), cloud/edge AI
- What to do: Use the paper’s result that total parameters correlate better than active parameters for factual capacity to decide MoE design trade-offs (e.g., expert count vs activation budget).
- Tools/workflows/products: Internal ablation studies using IKP while varying MoE total vs active param budgets; design guides prioritizing total-capacity for knowledge-heavy workloads.
- Assumptions/dependencies: Correlation (R²≈0.79 total vs 0.51 active) is empirical and may vary by architecture and data; requires access to training runs.
- Benchmarking and reporting that separates reasoning from knowledge
- Sectors: AI governance, academia, product evaluation
- What to do: Pair reasoning/densing benchmarks with IKP to report both compressible procedural capability and incompressible factual capacity, preventing overclaims like “small model equals big model.”
- Tools/workflows/products: Dual-metric model cards; internal scorecards for procurement; public evaluations adding IKP to MMLU/HELM-style suites.
- Assumptions/dependencies: Time-stability of IKP scores vs strong time trends in reasoning tasks; alignment with community standards.
- Rapid capability screening with T3-focused mini-probes
- Sectors: startups, integrators, applied research
- What to do: Run a 200-probe “T3-heavy” quick test to approximate overall ranking when compute or budget is limited (T3 shows the highest correlation with overall accuracy).
- Tools/workflows/products: Lightweight “IKP-200” harness, with thin T1/T2 sanity and T5/T6 ceiling checks.
- Assumptions/dependencies: Reduced set increases variance; assumes similar domain coverage.
- Academic and lab evaluation of knowledge absorption across communities
- Sectors: academia, research policy
- What to do: Use IKP-like researcher probes to quantify which research communities (subfields/regions) flow into models and identify gaps or biases in representation.
- Tools/workflows/products: Departmental audits of researcher recognition; funding or open-access initiatives targeted to underrepresented areas.
- Assumptions/dependencies: Current researcher probes exclude ML/AI to avoid contamination; extending to other fields requires curated evidence bundles.
- Localization and domain-readiness checks
- Sectors: education, public sector, healthcare, finance
- What to do: Expand IKP with local institutions, regulations, and rare entities to certify whether a model “knows” critical local/domain-specific facts before deployment.
- Tools/workflows/products: Localized IKP packs (e.g., clinical rare-drug facts, municipal procedures); pre-deployment readiness reports.
- Assumptions/dependencies: Domain ground truth must be curated; regulatory approvals may require additional validation.
- Competitive intelligence without weights
- Sectors: strategy, investment, M&A
- What to do: Track rivals’ “effective capacity” and knowledge profiles over time using IKP and fingerprints; validate scale-up claims versus point releases or post-training-only changes.
- Tools/workflows/products: Capacity trend dashboards; alerting when a competitor crosses T6 thresholds; briefings for leadership.
- Assumptions/dependencies: Wide intervals mean estimates are for banding, not precise size; landmark-specific inflation must be handled (e.g., Gemini 3.x T6).
- End-user guidance: pick the right chatbot for obscure queries
- Sectors: daily life, education
- What to do: Rely on models with higher T3–T5 scores for questions about obscure local events, institutions, or niche topics; otherwise use retrieval-based tools.
- Tools/workflows/products: Consumer-facing “best-for-rare-facts” badges in app stores; routing in personal assistants.
- Assumptions/dependencies: Public reporting of IKP scores; per-language/domain variance.
Long-Term Applications
These require further research, scaling, standardization, or domain adaptation.
- Regulatory transparency standards for factual capacity
- Sectors: policy/regulation, standards bodies
- What to do: Incorporate IKP-like audits into model cards and compliance disclosures (e.g., “effective knowledge capacity,” per-tier scores, refusal/bluff rates).
- Tools/workflows/products: Standardized IKP protocols; accredited third-party auditors; regulatory reporting portals.
- Assumptions/dependencies: Consensus on probe governance, frequency, and acceptable uncertainty; handling of vendor-specific safety policies.
- Insurance and risk pricing linked to rare-fact reliability
- Sectors: insurance, healthcare, finance
- What to do: Use tiered IKP scores to price risk of high-stakes hallucinations on rare facts (e.g., rare drugs, low-cap issuers, local compliance rules); mandate retrieval for tiers where capacity is low.
- Tools/workflows/products: Underwriting models keyed to T4–T6 scores; policy riders requiring guardrails.
- Assumptions/dependencies: Domain-specific IKPs with validated ground truths; clear linkage between IKP tiers and incident rates.
- Training-data strategy guided by long-tail coverage gaps
- Sectors: AI labs, data providers, publishers
- What to do: Drive data acquisition and curation to improve coverage in underrepresented long-tail regions revealed by IKP tiers; prioritize public, verifiable sources.
- Tools/workflows/products: “Long-tail coverage dashboards” for data teams; publisher partnerships; incentives for open-access artifacts.
- Assumptions/dependencies: Legal/ethical data sourcing; diminishing returns at extreme tails (T7 ceiling).
- Architecture co-design for knowledge vs procedure
- Sectors: AI R&D
- What to do: Allocate parameter budgets and MoE designs explicitly for factual storage (total params) versus procedural skills (compressible), using IKP as the knowledge-side objective.
- Tools/workflows/products: Multi-objective training targets tracking IKP and reasoning benchmarks; expert-routing strategies tuned for knowledge retention.
- Assumptions/dependencies: Stability of bits/parameter ranges; generalization of total-param rule across future MoE innovations.
- Provenance and distillation-detection frameworks at scale
- Sectors: IP law, platforms/marketplaces, governance
- What to do: Combine knowledge fingerprints with other signals to detect unauthorized distillation or weight reuse across vendors and enforce licensing.
- Tools/workflows/products: Cross-vendor registries of knowledge fingerprints; adjudication workflows for provenance disputes.
- Assumptions/dependencies: Legal acceptance of fingerprint evidence; robustness against convergent training on shared corpora.
- Sector-specific IKP suites (healthcare, finance, energy, robotics, education)
- Sectors: healthcare (rare-disease/medication facts), finance (issuer/regulatory minutiae), energy (facility standards), robotics (device-specific specs), education (curricular long-tail)
- What to do: Build IKP-like probe banks per sector to audit memorized domain knowledge and decide retrieval/guardrail requirements.
- Tools/workflows/products: Certified sector IKP packs; compliance badges; deployment playbooks.
- Assumptions/dependencies: Expert curation and continuous updates; alignment with sector regulators.
- Model marketplaces ranked by factual capacity bands
- Sectors: AI platforms, procurement
- What to do: Offer catalog filters and SLAs keyed to IKP bands (e.g., “T3 ≥ 80%”) so buyers can match tasks to models with sufficient knowledge capacity.
- Tools/workflows/products: Tiered service levels; automated rerouting to maintain SLAs.
- Assumptions/dependencies: Community acceptance of IKP-like metrics; standardized evaluation cadence.
- Personalized assistants that learn user-specific long-tail facts
- Sectors: consumer software, enterprise productivity
- What to do: Use IKP-derived thresholds to identify deficits in parametric knowledge and automatically augment with structured memory or retrieval for user/org-specific facts.
- Tools/workflows/products: Hybrid memory managers that treat “T6/T7-like” items as external memory entries; privacy-preserving local stores.
- Assumptions/dependencies: Reliable detection of “unknowns” (refusals over bluffing); secure storage and consent mechanisms.
- Cross-lingual and low-resource fairness audits
- Sectors: policy, academia, global NGOs
- What to do: Extend IKP to multiple languages/regions to quantify inequities in long-tail knowledge and inform funding or corpus-building programs.
- Tools/workflows/products: Multilingual IKP packs; public leaderboards tracking cross-lingual T3–T6.
- Assumptions/dependencies: High-quality ground truth in low-resource settings; adjudication for transliteration/name collisions.
- Compute and hardware planning grounded in incompressible capacity
- Sectors: AI labs, cloud providers, investors
- What to do: Use the non-densing behavior of factual capacity to forecast required parameter counts (and thus compute costs) for target long-tail coverage.
- Tools/workflows/products: Capacity planners linking target IKP tiers to parameter and compute budgets.
- Assumptions/dependencies: Stability of log-linear scaling; future architectural gains mainly affect procedure, not factual storage.
- Public watchdog leaderboards for factual capacity
- Sectors: civil society, media, policy
- What to do: Maintain independent IKP leaderboards across releases to track whether frontier models are scaling factual capacity and to discourage “benchmark gaming” focused only on reasoning tasks.
- Tools/workflows/products: Open dashboards; reproducibility packages; disclosure norms.
- Assumptions/dependencies: Sustainable funding and governance; vendor engagement for clarifications and safety nuances.
Notes on feasibility across applications:
- IKP estimates are intrinsic and vendor-agnostic but should be interpreted as effective knowledge capacity, not exact parameter counts; use bands for decisions.
- Safety tuning and refusal policies can hide knowledge; treat low scores on hard tiers as lower bounds unless refusal is separately audited.
- The paper’s judge and probes skew toward English/CS; domain and language extensions are advisable before high-stakes deployment.
- Some families (e.g., those used as landmarks) exhibit tier inflation; follow toolkit guidance to avoid biased comparisons.
Glossary
- Active parameters: The subset of parameters actually used per token in a Mixture-of-Experts model during inference; contrasted with total parameters. "For Mixture-of-Experts models, total parameters predict knowledge () far better than active parameters ()."
- Bits per parameter: An empirical estimate of how many bits of factual information can be stored per model parameter. "with an empirical storage capacity of --$4$ bits of factual knowledge per parameter"
- Black-box: A setting where only input-output behavior is observable, without access to internal weights or architecture. "and one that uses only black-box API access."
- Bootstrap confidence interval: A CI computed via resampling (bootstrapping) rather than parametric assumptions. "[95\% bootstrap CI: ]"
- Calibration curve: The empirically fitted relationship mapping measured accuracy to parameter count (or vice versa). "IKP calibration curve."
- Chain-of-thought: A prompting or reasoning technique where the model generates intermediate reasoning steps to improve performance. "supporting the interpretation that chain-of-thought helps with knowledge retrieval"
- Common Crawl: A large-scale web crawl dataset often used as a proxy for web frequency/popularity. "seven difficulty tiers (T1--T7) defined by entity-popularity proxies (Common Crawl document frequency)"
- Confidence interval (CI): A statistical range that likely contains the true parameter value with a specified confidence level. "the IKP time coefficient is /month (95\% CI )"
- Densing Law: An empirical observation that capability per parameter doubles rapidly over time, implying compressibility of procedural skills. "Procedural capability compresses under the ``Densing Law,''"
- DBLP: A computer science bibliography database used for researcher sampling and metadata. "DBLP / arXiv researcher records"
- Factual capacity: The amount of factual knowledge a model can store in its parameters. "Factual capacity continues to scale log-linearly with parameters across generations and across vendors."
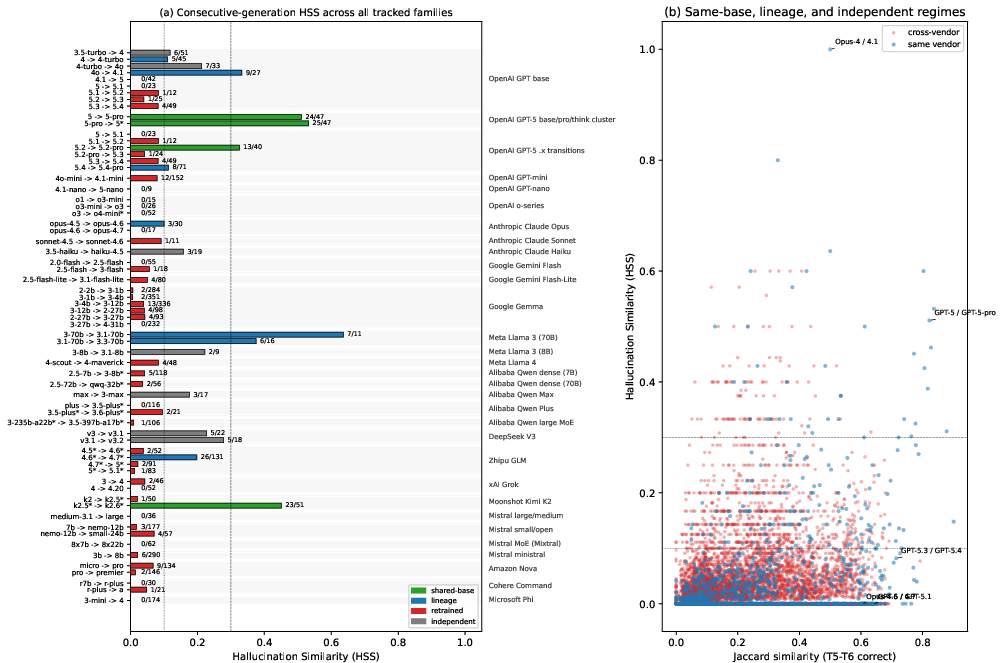
- Fingerprinting (knowledge fingerprinting): Identifying model lineage or identity via distinctive behavioral patterns on probes. "Knowledge fingerprinting. Combining rare-fact Jaccard overlap with hallucination similarity (the rate at which two models produce the same wrong answer on rare facts) yields a training-free test that distinguishes weight-sharing siblings, post-training lineages, and full retrains"
- Grokking: A phenomenon where models suddenly generalize after memorization once capacity or training progresses sufficiently. "showing that models ``memorize until their capacity fills, at which point grokking begins.''"
- Hallucination similarity: The tendency of two models to agree on the same incorrect answers, used as a similarity metric. "A black-box hallucination-similarity test---rare-fact agreement on wrong answers---separates weight-sharing siblings, post-training lineages, and full retrains without model weights."
- Heap’s law: A relationship describing how vocabulary size grows with corpus size; used here to ground a complexity-based model of knowledge. "proposing a Syntax-Knowledge model grounded in Heap's and Zipf's laws"
- IKP (Incompressible Knowledge Probes): A benchmark designed to measure factual knowledge that cannot be compressed by architectural or training improvements. "We introduce Incompressible Knowledge Probes (IKPs), a benchmark of 1{,}400 factual questions spanning 7 tiers of obscurity"
- Implicit knowledge base: The idea that pretrained LMs internally store factual associations akin to a knowledge base. "pretrained LLMs serve as implicit knowledge bases"
- Jaccard overlap: A set-similarity metric (intersection over union) used to compare rare-fact outputs between models. "Combining rare-fact Jaccard overlap with hallucination similarity"
- Key-value memories (in transformers): The interpretation of feed-forward layers as storing associative mappings from keys to values (facts). "Transformer feed-forward layers function as key-value memories for factual associations"
- Kolmogorov complexity: A measure of the shortest description length of data; used to formalize knowledge acquisition and compression. "formalize knowledge acquisition through the lens of Kolmogorov complexity"
- Landmark models: A fixed set of reference models used to define tier boundaries for probe difficulty. "Six landmark models spanning from 0.5B to frontier define the tier boundaries:"
- Leave-one-out cross-validation (LOO-CV): A model validation method where one example is held out at a time to assess generalization. "leave-one-out cross-validation confirms generalization (median fold error , within and within )."
- Log-linear (relationship): A linear relationship in the logarithm of a variable (e.g., accuracy vs. log parameters). "We calibrate a log-linear mapping from IKP accuracy to parameter count"
- Logistic sigmoid: An S-shaped function modeling per-tier accuracy transitions with respect to log-parameters. "Per-tier accuracy follows a logistic sigmoid: "
- Long tail (of knowledge): The heavy-tailed distribution of fact popularity or mention frequency; rarer facts lie further down the tail. "Models with more capacity memorize facts further down the long tail."
- Mixture-of-Experts (MoE): An architecture where multiple expert subnetworks are selectively activated per input. "For Mixture-of-Experts models~\citep{shazeer2017outrageously, fedus2022switch}, total parameters () clearly outperform active parameters ()"
- Neural scaling laws: Empirical power-law relations linking model size, data, compute, and performance. "Neural scaling laws establish power-law relationships between model size, compute, data, and loss."
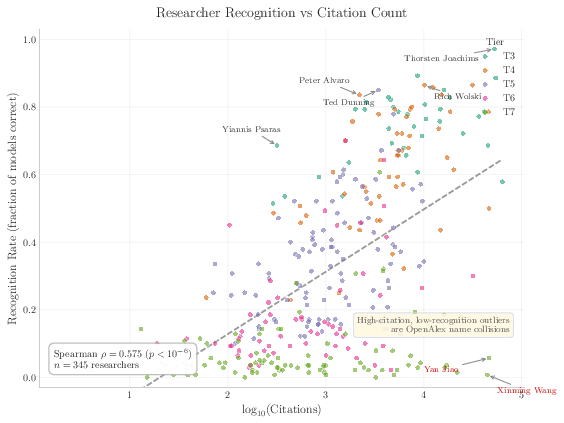
- OpenAlex: An open scholarly metadata catalog used for researcher evidence and sampling. "Researchers are sampled from DBLP and OpenAlex by citation-count buckets"
- Parametric memory: Knowledge stored in model weights as opposed to being retrieved from external tools or databases. "LLMs are unreliable on less popular facts, with parametric memory failing where retrieval succeeds."
- Parameter budget: The total number of parameters available to allocate across different functions (facts, procedures, language). "bounded above by the model's parameter budget"
- Penalized accuracy: An accuracy metric that includes penalties (e.g., for confident wrong answers) to discourage bluffing. "Penalized accuracy fits comparably to raw accuracy ()"
- Prediction interval (PI): A statistical interval predicting the range of future observations (e.g., estimated sizes) with a given probability. "The 90\% prediction interval (PI) factor is ."
- Quantization: Reducing numerical precision of model weights/activations to compress models and speed inference. "text-output statistical tests fail at for detecting quantization"
- R2 (coefficient of determination): A statistical measure of how well a regression explains variance in the data. "achieving "
- Regression (ordinary least squares): A method to fit linear relationships by minimizing squared residuals. "using ordinary least squares on open-weight models"
- Reinforcement Learning from Human Feedback (RLHF): Post-training via human preference signals to shape model outputs. "NVIDIA's heavy RLHF post-training pass"
- Residual standard error: The standard deviation of regression residuals, used to characterize calibration uncertainty. "derived from the calibration residual standard error of 0.042."
- Scaling laws: General relationships showing how performance changes with size or compute; includes neural scaling laws. "Neural scaling laws~\citep{kaplan2020scaling, hoffmann2022training} establish power-law relationships between model size, compute, data, and loss."
- Serving stack: The software/hardware infrastructure used to serve model inferences (affecting throughput/cost estimates). "serving-stack assumptions external to the model"
- Shadow-MoE: A technique for detecting distillation via MoE-specific patterns in a black-box setting. "achieving detection accuracy with a Shadow-MoE approach for black-box settings."
- Shannon entropy: A measure of the information content (in bits) of a random variable; used as a lower bound on factual storage. "bounded below by the Shannon entropy"
- SPARQL: A query language for RDF data, used to extract structured facts from Wikidata. "Wikidata via SPARQL"
- Spearman correlation: A rank-based correlation measure assessing monotonic relationships. "the highest Spearman correlation with overall accuracy ()"
- Tokenization effects: Errors or performance changes arising from how text is broken into tokens by the model. "tokenization effects"
- Two-sample testing: A statistical framework to decide whether two samples come from the same distribution. "formalize API model verification as a two-sample testing problem"
- Wikidata: A structured knowledge base used as a ground-truth source for factual probes. "Wikidata via SPARQL"
- Zipf’s law: A power-law distribution governing frequency of items like words or entity mentions. "Zipf's law"
- Zipfian distribution: Data following Zipf’s law; used to describe the popularity distribution of entities. "consistent with the Zipfian distribution of entity popularity"
- “Law of Knowledge Overshadowing”: A proposed law stating that popular facts overshadow obscure ones, increasing hallucinations on the latter. "The ``Law of Knowledge Overshadowing'' shows that popular knowledge suppresses less popular knowledge, with hallucination rate increasing log-linearly with knowledge popularity"
- Monotonicity filter: A probe-quality check that removes items where larger models don’t outperform smaller ones, indicating ambiguity. "identified by the monotonicity filter (Appendix~\ref{app:probes}): if a more-capable landmark gets a probe wrong while a less-capable one gets it right, the probe is dropped;"
- Post-training: Additional training (e.g., RLHF, instruction tuning) applied after pretraining to modify behavior. "post-training lineages"
- Refusal policy: Safety/alignment behavior causing the model to decline to answer certain prompts. "since refusal policy can hide tens of percentage points of ``refused but known'' capacity."
- Thinking mode: An inference setting enabling multi-step reasoning or deliberate outputs (often akin to chain-of-thought). "thinking mode~\citep{wei2022chain} improves penalized accuracy in 20 cases"
Collections
Sign up for free to add this paper to one or more collections.