StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?
Abstract: LLMs have recently demonstrated strong capabilities as autonomous agents, showing promise in reasoning, tool use, and sequential decision-making. While prior benchmarks have evaluated LLM agents in domains such as software engineering and scientific discovery, the finance domain remains underexplored, despite its direct relevance to economic value and high-stakes decision-making. Existing financial benchmarks primarily test static knowledge through question answering, but they fall short of capturing the dynamic and iterative nature of trading. To address this gap, we introduce StockBench, a contamination-free benchmark designed to evaluate LLM agents in realistic, multi-month stock trading environments. Agents receive daily market signals -- including prices, fundamentals, and news -- and must make sequential buy, sell, or hold decisions. Performance is assessed using financial metrics such as cumulative return, maximum drawdown, and the Sortino ratio. Our evaluation of state-of-the-art proprietary (e.g., GPT-5, Claude-4) and open-weight (e.g., Qwen3, Kimi-K2, GLM-4.5) models shows that while most LLM agents struggle to outperform the simple buy-and-hold baseline, several models demonstrate the potential to deliver higher returns and manage risk more effectively. These findings highlight both the challenges and opportunities in developing LLM-powered financial agents, showing that excelling at static financial knowledge tasks does not necessarily translate into successful trading strategies. We release StockBench as an open-source resource to support reproducibility and advance future research in this domain.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
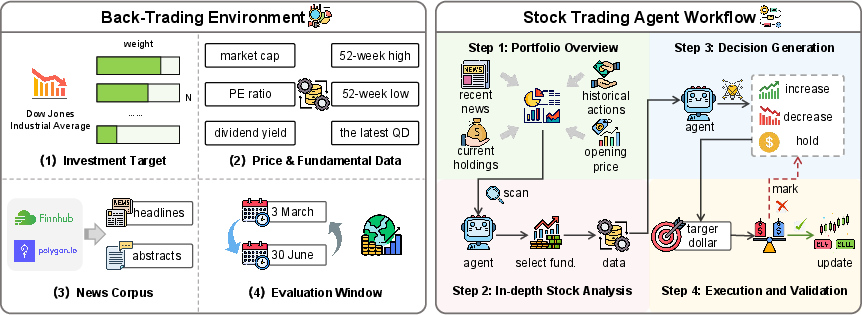
This paper introduces StockBench, a new way to test whether AI agents built from LLMs can make good decisions when trading real stocks over several months. Instead of just answering finance questions, these AI agents must react to real market signals each day—like prices, company data, and news—and decide whether to buy, sell, or hold. The goal is to measure not only how much money they can make, but also how well they manage risk.
Objectives
The paper asks three simple questions:
- Can LLM-based agents trade stocks in a realistic setting, day after day, and make a profit?
- Do these agents handle risk (like big losses) better than simple strategies?
- Does knowing lots of finance facts (good at Q&A) actually help with real trading decisions in a fast-changing market?
Methods and Approach
Think of StockBench like a “stock market video game” that uses real past data. The AI agent logs in each morning and makes choices, just like a regular investor.
Here’s how it works:
- Realistic setup: The agents trade 20 well-known Dow Jones stocks from March to June 2025. This time period was chosen so models wouldn’t have seen the data during training (like giving a test with questions written after the textbook).
- Daily inputs: Each day, the agent gets three types of clues:
- Prices: What stocks opened at and recent movements.
- Fundamentals: Simple facts about a company’s health (like market size, P/E ratio, and dividends).
- News: Up to five recent headlines from the past 48 hours.
- Trading workflow (four steps): 1) Portfolio overview: Scan all 20 stocks and see what’s going on. 2) In-depth analysis: Pick some stocks and look at their financial stats more closely. 3) Decision: For each stock, decide whether to buy more, sell some, or hold. 4) Execution: Turn dollar amounts into share counts. If the plan spends more cash than available, fix it and try again.
- Baseline for comparison: A simple “buy-and-hold” strategy that splits money equally across all 20 stocks on day one and then does nothing until the end. This is like a basic, hands-off approach.
- How performance is judged:
- Cumulative return: How much the portfolio gained or lost by the end.
- Maximum drawdown: The worst drop from a peak to a low point during the test (a measure of pain).
- Sortino ratio: A score that looks at return but only penalizes the “bad” ups and downs (downside volatility), not the good ones.
Main Findings
What did they learn?
- Mixed success versus the simple baseline: In the four-month window studied, several AI agents earned slightly more than the buy-and-hold approach and also had smaller worst-case drops. However, strong performance in finance Q&A did not guarantee better trading. Being good at facts and static tests isn’t the same as making smart moves in a noisy, fast-changing market.
- Risk management showed promise: Many agents had lower maximum drawdowns than the baseline, meaning they sometimes avoided the worst dips better than doing nothing.
- “Reasoning” models weren’t always better: Models tuned to think step-by-step (like “Think” versions) did not consistently beat simpler instruction-following versions. More “thinking” didn’t automatically mean better trading decisions.
- Errors matter: Agents often made two kinds of mistakes:
- Arithmetic errors: Miscalculating how many shares to buy with a given budget.
- Schema errors: Outputting the wrong format (like messy JSON), which breaks the trading system.
- Reasoning-heavy models made fewer math mistakes but more formatting mistakes, possibly because they “overthink” and produce complex outputs.
- Scaling up is hard: When increasing the number of tradable stocks (from 5 up to 30), performance became more unstable. Bigger portfolios made the job tougher, especially for smaller models.
- Inputs help: Removing news or fundamental data reduced performance. Agents did best when they combined both types of information—numbers and narratives.
- Market conditions change the story: In a separate test, during a market downturn (bearish period), AI agents generally failed to beat the baseline. In an upturn (bullish period), many did better. This suggests some agents are more suited to rising markets than falling ones.
Why is this important?
- It shows that making smart, money-related decisions day after day is a very different skill than answering test questions.
- It highlights the need to judge AI agents on both profit and safety (risk), especially when real money could be involved.
Implications and Impact
StockBench gives researchers and builders a fair, updated, and realistic test bed to improve AI trading agents. The key takeaways:
- Don’t assume an AI that aces finance quizzes will be a great trader. Dynamic decision-making requires different skills.
- Real trading needs careful risk control. Lower drawdowns are valuable, even if profits aren’t huge.
- Better tools and training are needed to reduce errors and handle more complex portfolios.
- Performance depends on market conditions. Future agents must adapt to both good times and bad.
- By open-sourcing StockBench and keeping it “contamination-free” (using new data not seen during training), the community can build and compare agents more fairly, speeding up progress toward safer, smarter financial AI.
In short, StockBench is a stepping stone: today’s LLM agents show hints of promise, but they’re not reliable stock traders yet. This benchmark will help researchers make them safer, steadier, and more effective over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to enable actionable follow-up work.
- Transaction costs and market frictions are not modeled (commissions, bid–ask spreads, slippage, taxes). Open question: How do the agents’ returns and risk metrics change when realistic execution costs and tax considerations are applied?
- Order execution realism is limited to fills at the opening price with no order types, partial fills, or intraday dynamics. Open question: What is the impact of realistic microstructure (limit/market orders, partial fills, price impact, latency) on agent performance?
- Short selling, leverage, and margin are excluded. Open question: How do LLM agents perform under broader instrument sets (shorting, options, ETFs, futures) and explicit leverage/margin constraints?
- Dividend and corporate action handling is unspecified (ex-dividend timing, split/merger effects, cash crediting). Open question: Does incorporating realized dividends and corporate actions materially change outcomes?
- Baselines are restricted to equal-weight buy-and-hold. Open question: Do LLM agents outperform widely used systematic baselines (e.g., momentum, mean-reversion, moving-average crossover, risk parity, minimum variance, DJIA index tracker)?
- Statistical rigor is limited (three seeds, 82 trading days, no confidence intervals or multiple-comparisons control). Open question: Are observed outperformance and risk differences statistically significant under bootstrapping, out-of-sample testing, and corrections for multiple model comparisons?
- Composite ranking via equal-weighted z-scores may bias conclusions. Open question: How sensitive are rankings to alternative metric sets and weightings (e.g., Sharpe, Calmar, Omega, alpha vs benchmark, tracking error) and to different composite formulations?
- Sortino ratio definition is incomplete (excess return Rp and minimal acceptable return/risk-free rate not specified). Open question: How do results change under different MAR/risk-free assumptions and alternative downside definitions?
- “Contamination-free” claim is unverified for proprietary models with unknown training corpora and cutoffs. Open question: Can auditing protocols (e.g., provenance checks, temporal holdout beyond model cutoffs, synthetic blinds) substantiate contamination-free evaluation?
- Reproducibility of dynamic news inputs is unclear (API-based retrieval, top-5 selection). Open question: Will the authors release a frozen snapshot (full text, timestamps, URLs, hashes) and documented ranking criteria to guarantee exact replication?
- Action schema is ambiguous: Step 3 specifies “increase/decrease/hold,” but execution references “dollar targets.” Open question: What is the precise decision format (position sizing rules, target weights/amounts, constraints) and how is sizing determined?
- Turnover, trade count, and average holding period are not reported. Open question: What are agents’ trading intensities, and how do turnover and holding periods affect costs and realized performance?
- Historical price context is minimal (opening price, 52-week high/low) without time-series features. Open question: Does providing richer historical signals (returns, volatility, technical indicators, rolling fundamentals) improve agent decisions?
- Memory and planning across days are constrained (only past 7 days of actions shared). Open question: How do longer memory windows, episodic memory, or planning modules impact consistency, regime adaptation, and performance?
- Tool augmentation is not explored, despite arithmetic and schema errors. Open question: Do calculator tools, schema validators, self-checkers, or constrained decoding materially reduce execution errors and improve returns?
- Scalability beyond 20 DJIA constituents shows degradation but is not dissected. Open question: Which bottlenecks (context limits, analysis load, action sizing) drive performance decay, and what architectures/workflows enable stable scaling to larger universes?
- Market regime analysis is preliminary (bear-period underperformance noted). Open question: Can regime-aware agents (regime detection, adaptive prompts, conditional policies) improve robustness across downturns and high-volatility phases?
- Liquidity modeling is limited to available cash; stock-level liquidity is not considered. Open question: How do volume constraints, ADV-based sizing, and liquidity-adjusted risk affect feasibility and outcomes?
- Decision horizon is fixed to daily at market open. Open question: How do results vary across intraday, weekly, or monthly horizons, and what is the horizon that best matches LLM strengths vs. costs?
- Human comparison is absent. Open question: How do LLM agents compare to retail/professional discretionary baselines when given the same information and constraints?
- Explainability and attribution are not evaluated (do rationales correspond to actual drivers?). Open question: Can the benchmark measure decision-grounding quality (alignment to news/fundamentals), confidence calibration, and post-hoc attribution to inputs?
- Prompt fairness and decoding sensitivity are under-specified. Open question: How robust are outcomes to prompt variants, instruction vs. CoT, sampling temperature, and system settings; can standardized prompt suites reduce bias across models?
- Period length is short (four months). Open question: Do findings hold under longer rolling windows (multi-year), multiple non-overlapping test periods, and different start dates to assess generalization and seasonality?
- Asset coverage is narrow (large-cap DJIA). Open question: How do agents perform on mid/small caps, higher-news-volatility names, sector-specific sets, and international markets?
- News preprocessing, relevance ranking, and language/paywall handling are not detailed. Open question: What is the impact of deduplication, time alignment, sentiment labeling, and top-k truncation on decision quality?
- Safety/compliance is not considered (risk disclosures, suitability constraints). Open question: How should the benchmark incorporate compliance guardrails (position limits, suitability filters, risk warnings) for deployment to retail contexts?
- Data reliability and failure modes (API outages, delayed feeds) are not addressed. Open question: How do agents handle missing/delayed inputs (imputation, fallback logic) without degrading decisions?
- Adaptation/learning is not explored (agents are zero-shot). Open question: Can fine-tuning, RL on historical regimes, or online learning improve profitability and stability without overfitting?
- Risk measurement is limited (max drawdown and Sortino). Open question: Add path-dependent and tail-risk metrics (drawdown duration, VaR/CVaR, time-to-recovery) and factor exposures (beta, sector/factor loadings) to assess true risk management.
- Cost-effectiveness is unmeasured (token usage, latency, dollar cost per decision). Open question: What is the performance–cost frontier, and which workflows yield the best risk-adjusted returns per dollar of inference?
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging StockBench’s open-source benchmark, trading workflow, and empirical findings.
- Finance — Pre-deployment evaluation harness for AI trading agents
- Use case: Banks, hedge funds, and brokerages can score LLM-based trading agents against contamination-free, multi-month scenarios using StockBench’s composite metrics (Final Return, Max Drawdown, Sortino).
- Tools/workflows: StockBench CI pipeline for model gating, regime-specific test windows, portfolio-size stress tests (5/10/20/30 assets), z-score ranking, error logging (arithmetic/schema).
- Assumptions/dependencies: Requires live or recent market data licenses (prices, fundamentals, news), inclusion of transaction costs and slippage in bespoke extensions, and vendor API reliability for large context windows.
- Finance — Risk-testing sandbox for retail brokerage “AI co-pilots”
- Use case: Brokerages can safely sandbox agent outputs (buy/sell/hold) without executing real trades, validating liquidity constraints and JSON schema adherence before enabling any human-in-the-loop workflows.
- Tools/workflows: Execution validator (liquidity and budget checks), schema guards, calculator tools to prevent arithmetic mistakes, daily open decision simulation.
- Assumptions/dependencies: Strong compliance guardrails; paper’s results indicate agents struggle in downturns—limit to advisory or paper-trading.
- Finance — Research desk assistant for portfolio overview and news synthesis
- Use case: Equity research teams get daily portfolio scans with summarized top-5 news per ticker, relevant fundamentals, and risk flags; human analysts validate trade ideas.
- Tools/workflows: Portfolio overview stage, news API integration (48-hour window), fundamentals fetch, human review queue.
- Assumptions/dependencies: News relevance ranking, timely data feeds, clear “not financial advice” disclosures; avoid automated execution.
- Software/Fintech — Reliability wrappers for agent outputs
- Use case: Productize “schema-guard” and “calc-guard” layers to reduce common agent errors identified in the paper (JSON format and arithmetic).
- Tools/workflows: Structured output enforcement, function-calling calculators, retry/revision loops on bad outputs.
- Assumptions/dependencies: Access to tool-use features in chosen LLMs; rate limits and latency management.
- Academia/Education — Hands-on module for AI-in-finance courses
- Use case: Universities and training programs use StockBench to teach realistic agent evaluation, risk metrics, contamination avoidance, and regime sensitivity.
- Tools/workflows: Course labs replicating four-stage workflow, ablations on news/fundamentals, regime comparisons (downturn vs upturn windows).
- Assumptions/dependencies: Compute resources for multiple model runs and seeds; simplified data licenses for instruction.
- Policy/RegTech — Pilot audits of AI trading tools
- Use case: Regulators and regtech firms run pilot audits to assess AI agent risk profiles using benchmarked drawdown and downside-risk metrics before approving consumer exposure.
- Tools/workflows: Minimum threshold checks (e.g., max drawdown caps), regime stress tests, documentation of contamination-free evaluation periods.
- Assumptions/dependencies: Regulatory willingness; alignment on standardized test protocols; inclusion of realistic frictions.
- Daily life — Paper-trading simulator for DIY investors
- Use case: Consumers experiment with agent-generated suggestions in a simulated environment, tracking risk-adjusted performance without real capital at stake.
- Tools/workflows: Portfolio simulation, risk dashboards (drawdown, Sortino), human override, educational prompts.
- Assumptions/dependencies: Clear disclaimers; no auto-execution; results vary by market regime and portfolio size.
- Finance/Procurement — Vendor benchmarking and model selection
- Use case: Compare proprietary and open-weight LLMs (e.g., GPT-5, Claude-4, Qwen3 variants) using contamination-free windows to inform procurement decisions.
- Tools/workflows: Standardized runs with multiple seeds, ablation on input modalities (news vs fundamentals), composite ranking reports.
- Assumptions/dependencies: Representative tickers (DJIA top-20 are a starting point); extend to sector-specific universes; incorporate fees and constraints relevant to the institution.
Long-Term Applications
These applications require further research, scaling, or development to address reliability, compliance, and performance gaps identified by the paper.
- Finance — Regime-aware autonomous trading co-pilots
- Use case: Agents that detect market regimes (bull/bear/sideways) and adapt strategies, improving robustness in downturns where current agents underperform.
- Tools/workflows: Regime classification, dynamic policy switching, reinforcement learning with drawdown constraints; hybrid quant + LLM architecture.
- Assumptions/dependencies: Better downturn performance and stability; explicit risk limits; continuous evaluation across evolving windows.
- Finance — End-to-end AI trading with broker integration
- Use case: Semi-autonomous systems that place trades under strict risk controls, audit trails, and human oversight in production environments.
- Tools/workflows: OMS/EMS integration, transaction-cost analysis (TCA), slippage modeling, compliance workflows, kill-switches.
- Assumptions/dependencies: Regulatory approval, robust error handling, verified schema and arithmetic correctness, strict cybersecurity and KYC/AML controls.
- Finance — Multi-asset expansion beyond DJIA equities
- Use case: Extend agent workflows to ETFs, bonds, commodities, FX, and crypto while maintaining contamination-free evaluation and realistic inputs.
- Tools/workflows: Broader data ingestion, cross-asset risk modeling, sector/regional diversification, intraday decision variants.
- Assumptions/dependencies: Data coverage, market microstructure differences, higher-fidelity simulators.
- AI/ML Research — RL training frameworks with financial rewards and risk penalties
- Use case: Train agents using rewards shaped by returns, drawdown, and downside volatility (Sortino), leveraging StockBench as a safe training/evaluation loop.
- Tools/workflows: Reward shaping, off-policy evaluation, counterfactual “what-if” simulation, curriculum across regime windows.
- Assumptions/dependencies: Prevention of overfitting to short windows; realistic simulators including fees and liquidity; reproducibility across updates.
- Policy/Standards — Industry-wide audit norms for AI trading
- Use case: Establish standards for contamination-free backtesting, multi-seed evaluations, regime stress tests, and error reporting before consumer deployment.
- Tools/workflows: Certification protocols, minimum performance/risk thresholds, continuous benchmark updates, independent test labs.
- Assumptions/dependencies: Multi-stakeholder buy-in; harmonization across jurisdictions; auditability and transparency requirements.
- Software Engineering — Formal verification of agent outputs
- Use case: Guarantee arithmetic correctness and schema adherence using verifiable tool chains, static checks, and constrained generation.
- Tools/workflows: Typed JSON schemas, formal calculators, programmatic output validation, deterministic execution paths.
- Assumptions/dependencies: Advances in constrained decoding and tool-use orchestration; model compliance under verification regimes.
- Finance — Explainable decision pipelines combining news and fundamentals
- Use case: Transparent reasoning for trade recommendations that link specific news events and fundamental signals to actions and risk projections.
- Tools/workflows: Attribution methods, rationale templates, auditor-friendly reports; hybrid systems where LLMs interpret and quant models execute.
- Assumptions/dependencies: Reliable explanations that correlate with performance; avoidance of “overthinking” errors in reasoning-tuned models.
- Academia — Longitudinal studies on benchmark contamination and evolving market tests
- Use case: Ongoing research programs that track how model training corpora overlap with market periods, updating StockBench to remain contamination-free and predictive.
- Tools/workflows: Temporal data curation, leakage auditing, annual benchmark refreshes, multi-year performance tracking.
- Assumptions/dependencies: Sustained community maintenance; data licensing; methodological consensus on leakage detection.
- Daily life — Regulated consumer-grade AI investment advisors
- Use case: Retail-facing advisors offering explainable, risk-managed suggestions with strong guardrails and proven robustness across regimes.
- Tools/workflows: Suitability checks, fiduciary compliance, human-in-the-loop approvals, conservative policies in bearish markets.
- Assumptions/dependencies: Regulatory approval, stable downturn performance, clear liability frameworks, continuous monitoring.
- Fintech Infrastructure — “StockBench-as-a-Service” for continuous model monitoring
- Use case: Hosted service that continuously evaluates deployed agents against fresh, contamination-free windows, issuing alerts on drawdown spikes or schema failures.
- Tools/workflows: Live benchmarking, drift detection, error telemetry dashboards, automated rollback triggers.
- Assumptions/dependencies: Reliable data feeds, operational SLAs, integration with model ops and trading risk systems.
Glossary
- Ablation Study: A method of analyzing a system by removing components to assess their contribution. "we conduct an ablation study by progressively removing these inputs."
- Agentic Capability: The ability of an AI system to autonomously perceive, decide, and act in multi-step tasks. "This agentic capability is verified by benchmarks in various different domains, such as software engineering~\citep{jimenez2024swebench,yang2024sweagent}, scientific discovery~\citep{mialon2023gaia}, and marketing~\citep{chen2025xbench,barres2025tau2bench}, using the most recent advanced LLMs such as GPT-5~\citep{gpt5} and Claude-4~\citep{claude4}, highlighting their promise for workflow automation and productivity gains."
- Back-Trading Environment: A simulated trading setup using historical, time-restricted data to evaluate strategies as if in real time. "A back-trading environment, which contains historical data necessary for stock-trading decision making."
- Buy-and-Hold Baseline: A simple benchmark that purchases assets and holds them without further trading. "struggle to outperform the simple buy-and-hold baseline"
- Coefficient of Variation (CV): A normalized measure of dispersion defined as the ratio of the standard deviation to the mean. "coefficient of variation (CV)."
- Composite Rank: An aggregate performance score combining standardized metrics (e.g., return, drawdown, ratio). "we derive a composite rank by leveraging the z-score of each metric, averaging them to produce a single performance score."
- Contamination-Free: Designed to avoid training data leakage into evaluation, ensuring fair assessment. "a contamination-free benchmark designed to evaluate LLM agents in realistic, multi-month stock trading environments."
- Cumulative Return: The total percentage gain or loss of a portfolio over a period. "Performance is assessed using financial metrics such as cumulative return, maximum drawdown, and the Sortino ratio."
- Data Contamination: Unintended overlap between training and test data that can inflate evaluation results. "raising concerns about potential data contamination."
- Dividend Yield: Annual dividends per share divided by the stock price, indicating income return. "market capitalization, price-to-earnings (P/E) ratio, dividend yield, and trading range."
- Dow Jones Industrial Average (DJIA): A major U.S. stock market index of large industrial companies. "we select $20$ stocks from the Dow Jones Industrial Average (DJIA) with the highest weights as our investment targets."
- Downside Deviation: The standard deviation of negative returns used in risk-adjusted metrics like Sortino. "It is defined as the excess return divided by the downside deviation :"
- Equal-Weight Buy-and-Hold Strategy: A passive approach that allocates capital evenly across assets and holds. "we implement a passive equal-weight buy-and-hold strategy"
- Inductive Biases: Built-in assumptions of a model or workflow that influence learning and decisions. "since overly complicated workflows introduce inductive biases that may favor certain backbone LLMs."
- Investment Targets: The predefined set of assets available for trading in the evaluation. "The investment targets are a bundle of stocks that allow the trading agents to perform buy and sell operations."
- Liquidity: The availability of cash or tradable capacity to execute transactions without undue impact. "If the decisions of the agents exceed available liquidity, the system flags the issue and requires the agent to revise its decisions until they can be executed within available resources."
- Market Capitalization: The total market value of a company’s outstanding shares. "market capitalization, P/E ratio, and dividend yield."
- Maximum Drawdown: The largest peak-to-trough decline in portfolio value over a period. "Maximum Drawdown. The maximum drawdown quantifies the largest decline in portfolio value from its peak to its trough during the evaluation period, providing a measure of downside risk:"
- Price-to-Earnings (P/E) Ratio: A valuation metric comparing a company’s stock price to its earnings per share. "price-to-earnings (P/E) ratio"
- Risk-Adjusted Return: A performance measure that accounts for the risk taken to achieve returns. "fail to outperform this simple baseline in terms of both cumulative return and risk-adjusted return."
- Schema Error: A formatting mistake where outputs do not follow the required structured schema (e.g., JSON). "Schema Error, where the agent fails to adhere to the specified JSON output format, leading to parsing failures."
- Sortino Ratio: A risk-adjusted performance metric that penalizes only downside volatility. "The Sortino ratio is a risk adjusted return metric that penalizes only downside volatility."
- Temporal Separation: Ensuring the evaluation data occurs after the model’s training cutoff to prevent leakage. "ensuring temporal separation and avoiding any overlap with the training corpora of contemporary LLMs."
- Token Context Window: The maximum number of tokens an LLM can attend to in a single input. "All models are equipped with $32,768$ token context windows"
- Z-Score: A standardized score indicating how many standard deviations a value is from the mean, used for metric aggregation. "by leveraging the z-score of each metric"
Collections
Sign up for free to add this paper to one or more collections.