- The paper reveals that LLMs internally store up to 40% more factual knowledge than is evident in their generated outputs.
- It employs a dual scoring framework that compares internal classifier predictions with external token-level probabilities across 1,700 curated questions.
- The study suggests that improved decoding techniques could better harness hidden knowledge, enhancing reliability in knowledge-intensive tasks.
Hidden Factual Knowledge in LLMs
The paper "Inside-Out: Hidden Factual Knowledge in LLMs" explores the phenomenon whereby LLMs encode more factual information in their internal parameters than is observable through their direct outputs. This concept, termed as 'hidden knowledge', has significant implications for understanding the limits and potentials of LLMs in knowledge representation and retrieval tasks.
Framework for Hidden Knowledge
The researchers introduce a robust framework to methodically investigate hidden knowledge within LLMs. They propose a formal definition of knowledge for LLMs in a question-answering setting. Knowledge is quantified per question based on the model's ability to correctly rank the likelihood of (correct, incorrect) answer pairs. The framework distinguishes between internal knowledge, derived from intermediate computations of the model, and external knowledge, derived from the model's token-level probabilities.
Hidden knowledge is present when internal knowledge metrics surpass external ones, indicating the model internally "knows" answers it cannot generate reliably.
Study Design and Execution
A comprehensive case study was conducted using three popular open-weight LLMs under a closed-book question answering (QA) setup. The experiment utilized approximately 1,700 carefully curated questions to evaluate the models' hidden knowledge. Several scoring methods were employed to assess knowledge:
- External Scoring Methods:
- Token-level probabilities of generating an answer (P(a|q)).
- Length-normalized probability scores.
- Internal Scoring Methods:
- A linear classifier trained on the model's hidden representations to predict answer correctness.
The distinct separation of internal and external scoring allows for a direct comparison of the knowledge expressed versus encoded.
Findings
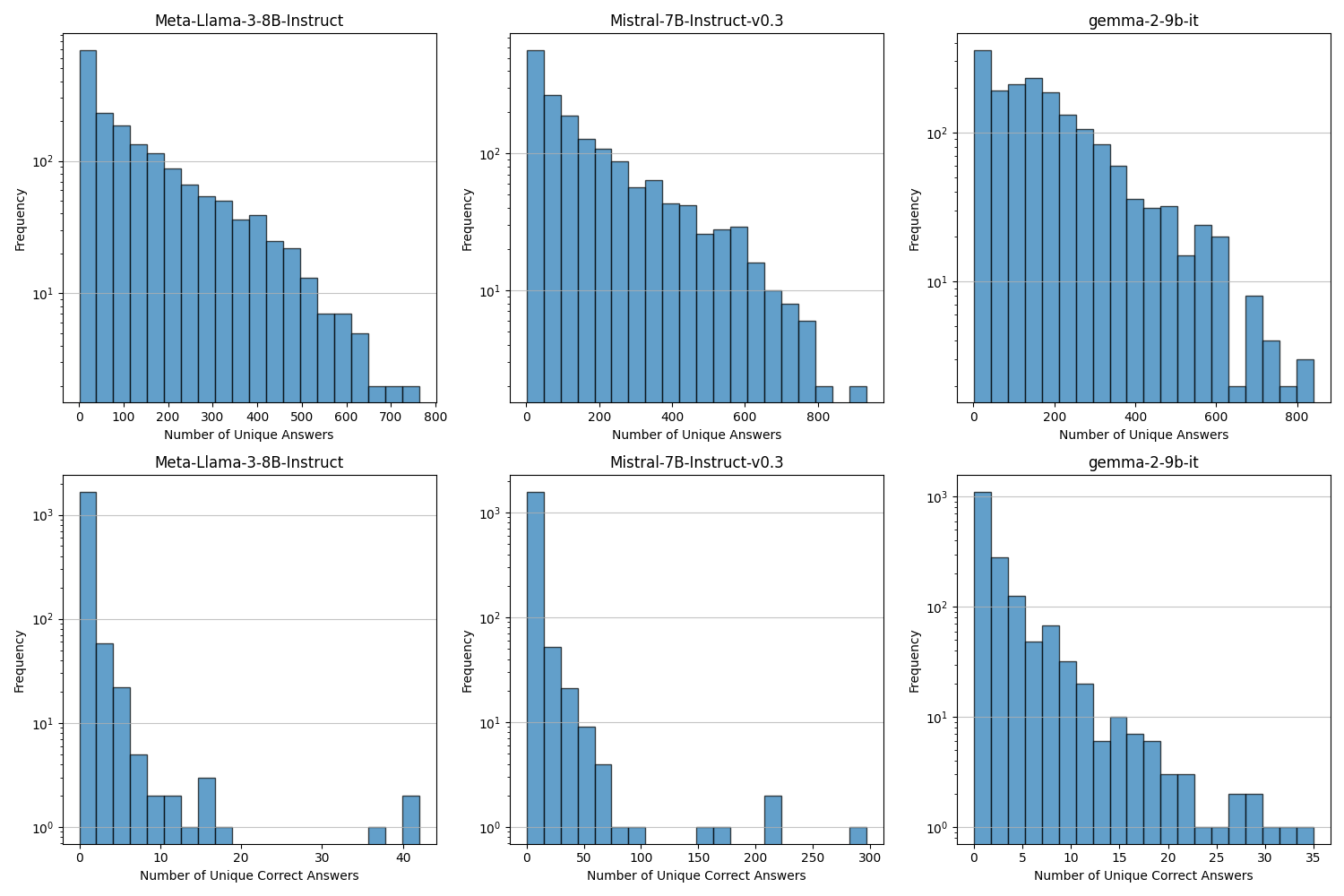
Figure 1: The paper quantifies the number of unique answers and unique correct answers per question, illustrating the diversity and challenges in the QA setups.
Key findings include:
- LLMs universally encode more factual data internally than expressed externally, with an average relative gap of about 40%.
- A significant portion of encoded knowledge is deeply hidden, leading to scenarios where a correct answer is encoded but not generated even once across 1,000 attempts. This highlights fundamental generation limitations in LLMs.
Implications and Practical Applications
These insights illuminate several critical avenues for application and research:
- Decoding Improvements: There's potential to mine more correct answers through improved decoding strategies leveraging internal model signals, as highlighted by the notable performance gap in internal vs. external knowledge measurement.
- Model Reliability: Understanding hidden knowledge in LLMs can enhance model reliability in knowledge-intensive applications by developing methods to unearth and utilize suppressed knowledge acts.
- Implications for Scale: Counters the assumption that model scaling and increased compute during testing alone will surface all factual knowledge—pointing instead to sophisticated techniques that account for model internals.
Conclusion
The framework and findings presented in this study challenge prevalent notions about the capabilities of LLMs, urging a reconsideration of how these models' 'knowledge' is defined and evaluated. It sets a foundational basis for exploring innovative methods to access the wealth of factual knowledge deeply embedded within LLMs, ultimately aiming to develop models that are not only larger but inherently more transparent and informative. Future work might focus on refining decoding mechanisms to align more closely with the rich internal landscapes of these models to fully leverage the encoded knowledge.