- The paper introduces Android Coach, which implements a Single State Multiple Actions paradigm to use expensive state samples more effectively.
- It integrates a Process Reward Model and ACLOO advantage estimation to stabilize critic training and reduce gradient variance in policy updates.
- Empirical evaluations show that Android Coach improves sample efficiency and success rates on Android benchmarks compared to traditional RL methods.
Enhancing Online GUI Agent Training Efficiency via the Single State Multiple Actions Paradigm
Motivation and Background
The development and deployment of autonomous GUI agents in the Android ecosystem have been increasingly constrained by the sample inefficiency inherent to reinforcement learning (RL) in online environments. GUI agents, powered by vision-LLMs (VLMs), must interact with high-latency emulators, where every interaction is computationally expensive and often bottlenecked by environment transitions rather than model inference. Conventional RL frameworks for agentic training operate under the Single State Single Action (SSSA) paradigm: each costly state collected during an online rollout is used for exactly one action decision and subsequent policy update, followed by an irrevocable transition. As a result, existing RL algorithms such as PPO and group-wise GRPO are unable to sufficiently explore the state-action space, limiting the potential for efficient credit assignment and policy improvement.
Android Coach Framework: Single State Multiple Actions
The Android Coach framework introduces a paradigm shift by enabling Single State Multiple Actions (SSMA) at each online state, fundamentally decoupling action sampling from environment interactions. Upon collecting a batch of states from parallel emulator rollouts, the actor samples multiple candidate actions per state. These actions are not executed in the environment, but are instead evaluated by a learned critic (Q-function), enabling rich exploration with constant interaction cost.
This design is illustrated in the system diagram, where the bottleneck of online interaction is alleviated via rapid inference and multi-action sampling for each state.
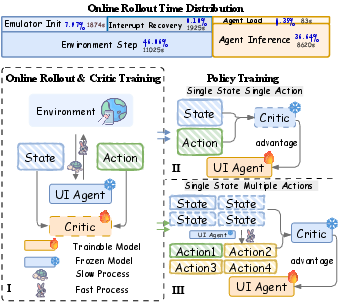
Figure 1: Analysis of online rollout time and the contrast between SSSA and SSMA paradigms in RL agent training. Android Coach leverages each expensive state by maximizing action sampling per interaction.
The full pipeline comprises four stages: online rollouts, critic update, multi-action resampling, and policy update governed by a group-wise advantage estimator.
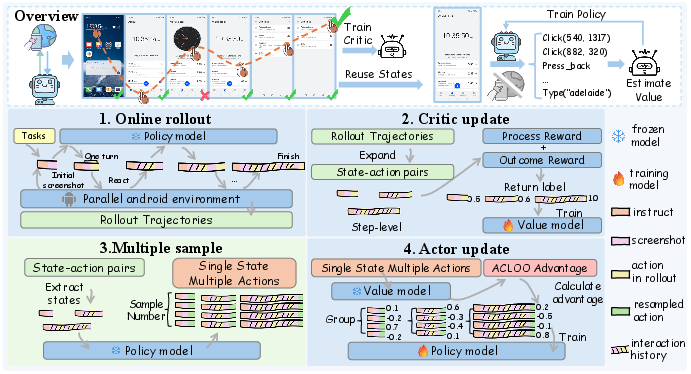
Figure 2: Android Coach RL training pipeline covering online rollouts, critic update with returns, multi-action sampling for each state, and actor update using the leave-one-out strategy.
Process Reward Modeling and Reliable Critic Training
A critical bottleneck in agentic RL for GUI tasks is reliable action evaluation. The Android Coach framework augments conventional outcome-based reward supervision with a fine-grained Process Reward Model (PRM), pretrained to assign step-level reward signals based on trajectory consistency and reasoning correctness. The PRM is trained with reasoning-context annotations and positive/negative step labels extracted from curated datasets and high-quality online rollouts.
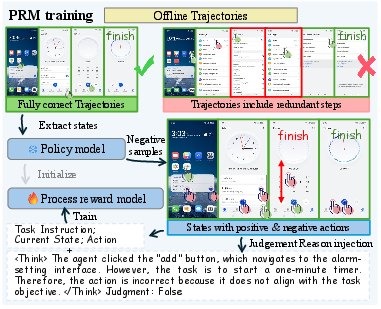
Figure 3: Dataset construction pipeline for process reward modeling. Positive and negative step labels are generated via context reasoning and ground truth comparison.
The Q-function critic is then trained online with returns synthesized from weighted Monte Carlo estimates combining process rewards and trajectory-level outcome rewards. A pretraining phase on the PRM dataset stabilizes value estimation and mitigates distributional shift, enabling more precise evaluation of candidate actions sampled in SSMA training.
Actor Optimization with Leave-One-Out Advantage
To efficiently utilize multi-action samples per state, Android Coach proposes Actor-Critic Leave-One-Out (ACLOO) advantage estimation. For each sampled action, the baseline is constructed as the average Q-value of peer actions (excluding the current one). This estimator is statistically unbiased and reduces gradient variance by centering the advantage signal, obviating the need for a separate value-function network.
Policy optimization proceeds with the PPO surrogate loss, leveraging ACLOO as the advantage for gradient updates.
Empirical evaluation on AndroidLab and AndroidWorld benchmarks demonstrates that Android Coach substantially improves both agent performance and training efficiency. UI-TARS-1.5-7B trained with Android Coach achieves 7.5% and 8.3% higher success rates on the respective benchmarks, outperforming strong proprietary models (e.g., Claude-Sonnet-4). Under fixed interaction budgets, Android Coach attains comparable or superior success rates with 1.4× higher sample efficiency than SSSA approaches like PPO and GRPO. The success is attributed to increased action sampling per state and effective group-wise advantage guidance.
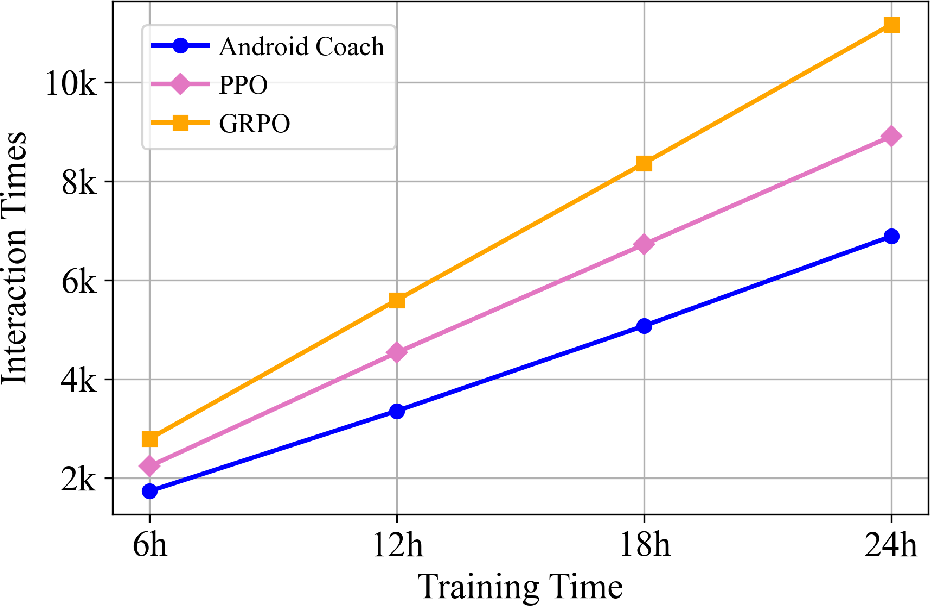
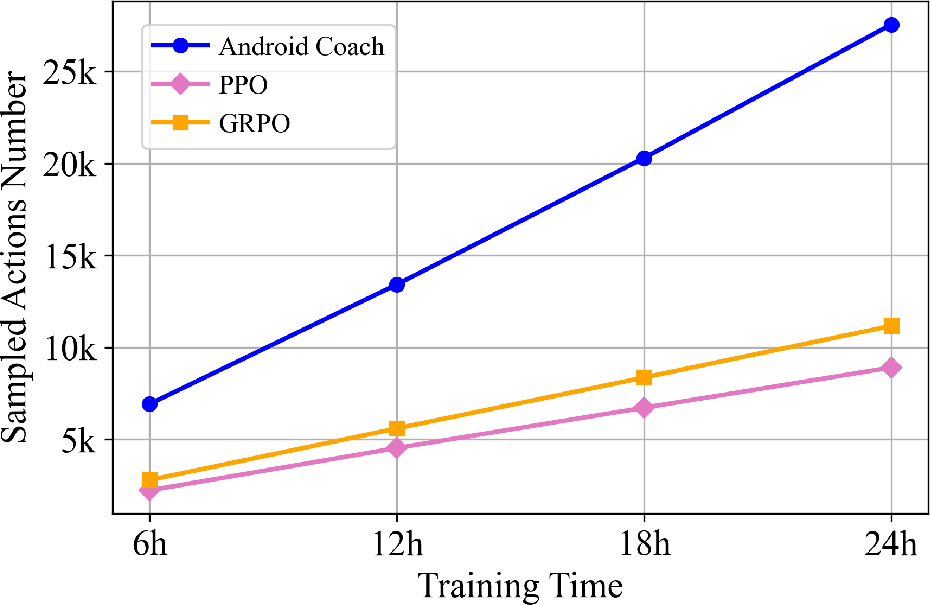
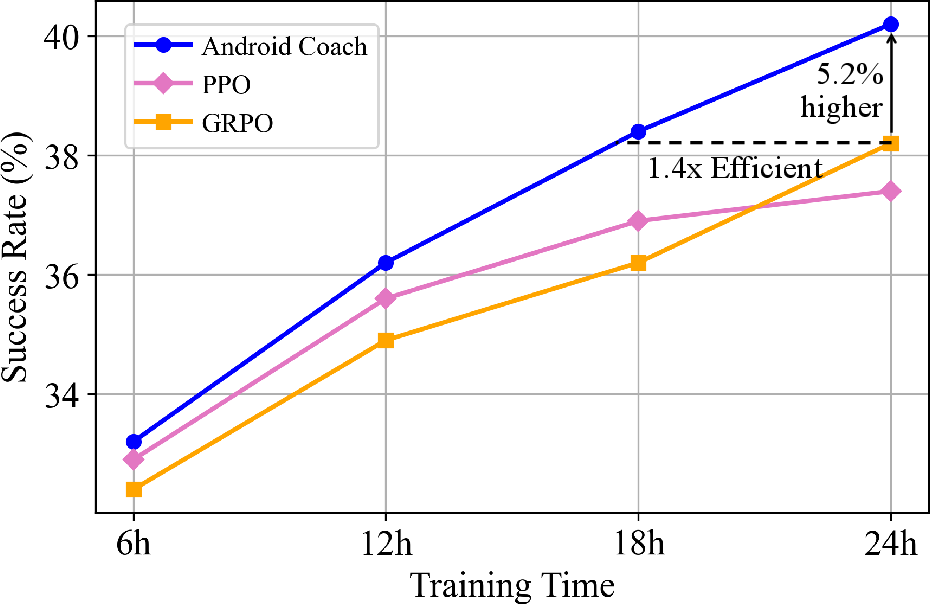
Figure 4: Interaction times comparison demonstrates Android Coach's ability to reduce emulator interactions under matched training budgets.
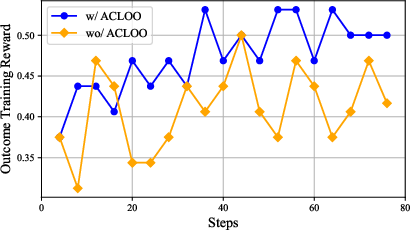
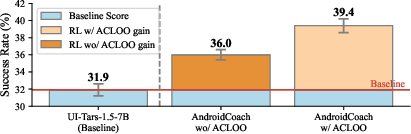
Figure 5: Outcome reward curves show consistently higher average rewards during training when employing ACLOO advantage estimation.
Ablations reveal that increasing the number of sampled actions per state yields diminishing but still substantial gains, with only sub-linear increases in wall-clock training cost. Critic pretraining on process data is necessary for stable convergence; step-level rewards via PRM further increase reasonable operation ratios and final success rates.
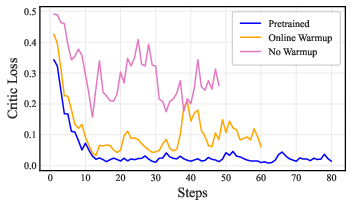
Figure 6: Critic loss curves under different initialization strategies validate the necessity of PRM-aligned pretraining for stable joint optimization.
Android Coach's process reward model training relies on structured, balanced datasets with reasoning-context annotation for step-wise supervision.
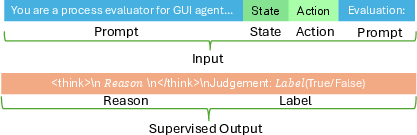
Figure 7: Process Reward Model training format comprising instruction, state, action, and logical reasoning for reward assignment.
The prompt utilized for process reward judgment integrates context reasoning and rigorous action validation.
Figure 8: Prompt template for Process Reward Model ensuring meticulous step-level evaluation in GUI agent RL.
Implications and Future Directions
The SSMA paradigm fundamentally enhances agentic RL sample efficiency, establishing a blueprint for online RL algorithms in high-latency environments. By maximizing action exploration per state and leveraging step-level evaluative signals, Android Coach enables scalable improvement of GUI agents with fixed interaction budgets. Future research may integrate advanced system parallelism to further accelerate wall-clock training, extend process reward modeling to arbitrary environments, and develop non-LLM verifier architectures to reduce reward assignment hallucinations.
From a theoretical standpoint, the leave-one-out advantage formulation can be generalized to broader actor-critic domains, and the process reward principle paves the way for more granular credit assignment in sequential decision-making tasks.
Conclusion
Android Coach presents a robust and efficient RL training framework for GUI agents, leveraging Single State Multiple Actions to maximize sample efficiency and performance within the constraints of expensive emulator interactions. The integration of process rewards and leave-one-out advantage estimation ensures reliable guidance and stable convergence. Experimental validation confirms significant improvements over prevailing RL baselines—both in agentic success and training efficiency—making Android Coach a compelling paradigm for scalable, online reinforcement learning in GUI interaction environments (2604.07277).