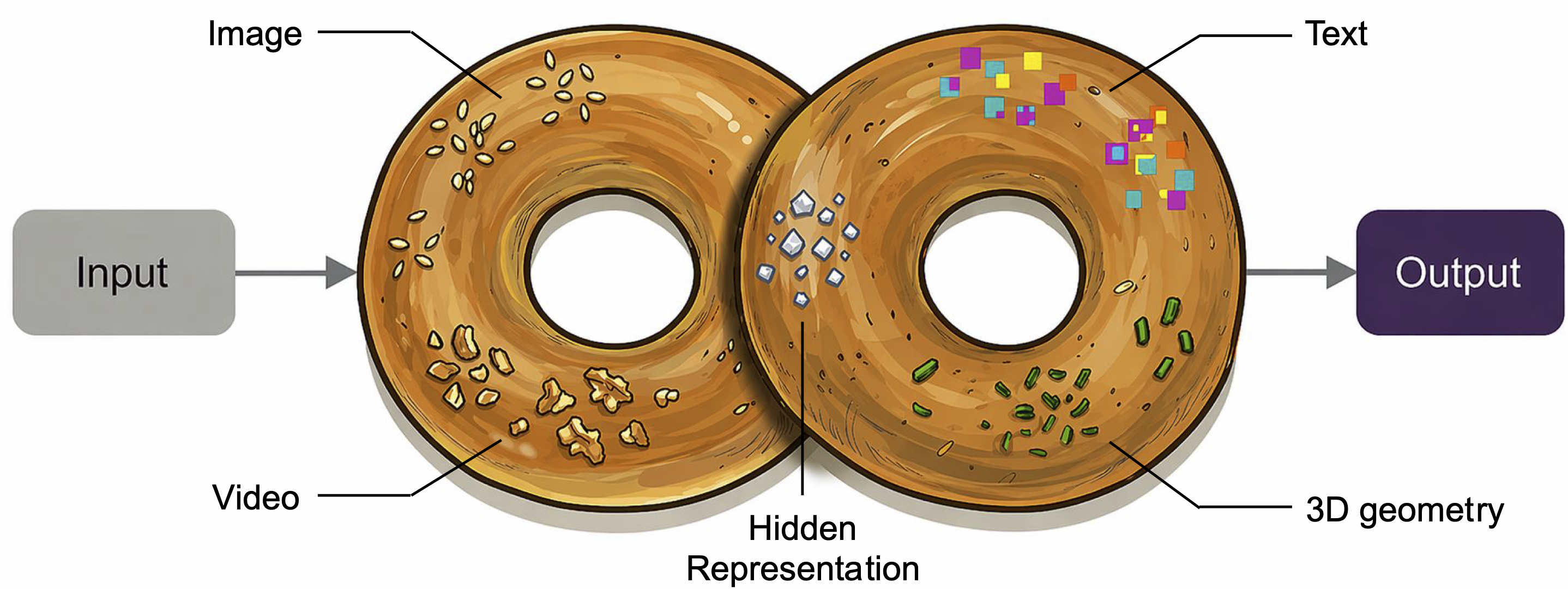
Context Unrolling in Omni Models
Abstract: We present Omni, a unified multimodal model natively trained on diverse modalities, including text, images, videos, 3D geometry, and hidden representations. We find that such training enables Context Unrolling, where the model explicitly reasons across multiple modal representations before producing predictions. This process enables the model to aggregate complementary information across heterogeneous modalities, facilitating a more faithful approximation of the shared multimodal knowledge manifold and improving downstream reasoning fidelity. As a result, Omni achieves strong performance on both multimodal generation and understanding benchmarks, while demonstrating advanced multimodal reasoning capabilities, including in-context generation of text, image, video, and 3D geometry.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new kind of AI model that can understand and create many types of information—text, pictures, videos, and even 3D shapes—inside one system. The big idea is called “Context Unrolling.” It means the model doesn’t rush to answer right away. Instead, it first “thinks” by gathering and writing down helpful clues across different media (like making notes, sketching rough layouts, or estimating 3D structure), and then uses those clues to give a better, more accurate final result.
What questions are the researchers asking?
- Can one model learn to handle many media types (text, images, videos, 3D) at once, instead of using a separate model for each task?
- If the model “thinks out loud” across different media before answering—like writing a plan, making a quick sketch, or imagining a new camera view—does that make its answers more accurate and reliable?
- Does this “Context Unrolling” help with a wide range of tasks: understanding pictures, generating images from text, editing images and videos, and predicting 3D information (like depth or camera angles)?
How does the model work? (Methods explained simply)
Think of the model as a team of specialists sharing one workspace:
- “Text specialist” writes short or long notes describing what’s important.
- “Vision specialist” creates rough visual building blocks (called visual tokens) that outline structure and layout—like a stick-figure plan before drawing details.
- “3D specialist” estimates depth (how far things are) and camera motion, or imagines new viewpoints of a scene (as if walking around an object).
- All these pieces get added to a shared “notebook” (the context) before the model produces a final answer, image, or video.
This step-by-step approach is the “Context Unrolling” process:
- Start with the input (text, image, video, etc.).
- Invoke small skills (“atomic primitives”) to build helpful context:
- Describe the scene in text (chain-of-thought).
- Roll out visual tokens (a structural scaffold for images).
- Estimate 3D cues (camera pose, depth).
- Synthesize new views (imagine looking from the left/right/up/down).
- After building this context, generate the final output (answer the question, create an image, produce a video, estimate a depth map).
Two more design ideas:
- Mixture-of-Experts (MoE): Like a team where different “experts” handle different parts, so the model stays efficient while being capable.
- Training on many modalities: The model learns from text, images, videos, and 3D data (like depth maps and camera transformations), plus “hidden” internal representations. This gives it many complementary views of the world.
Analogy: It’s like a detective solving a case. Instead of jumping to a conclusion, the detective gathers witness statements (text), studies photos (images), watches security footage (video), builds a 3D model of the scene, and takes notes. Only then does the detective present a well-supported answer.
What did they find, and why does it matter?
- Better visual understanding with “thinking”
- When the model writes short reasoning steps before answering (like listing objects and relationships), its accuracy improves on visual question answering and similar tasks.
- Why it matters: Text-based “thinking” helps it avoid mistakes and handle complex questions more reliably.
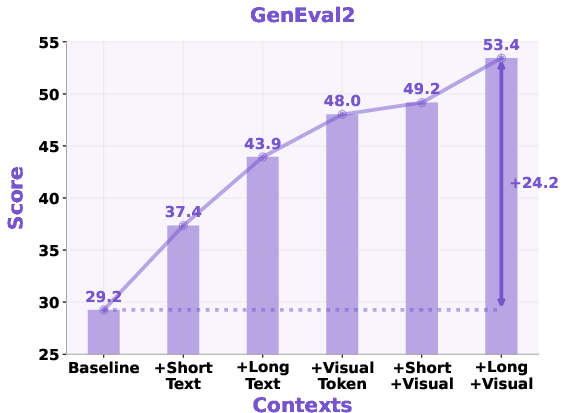
- Stronger image generation with layered context
- For text-to-image, the model first expands the prompt with extra helpful details (short or long notes) and/or generates visual tokens (a structured sketch) before making the final image.
- Results: Adding either detailed text or visual tokens improves how well the image matches the prompt—especially for tricky parts like counting objects or keeping spatial relationships correct. Combining both works best.
- They also tried “oracle” text (high-quality prompt rewrites from another strong model). With better context, results jump even higher, showing that context quality is a main driver of performance.
- Why it matters: This reduces ambiguity. Instead of trying to draw from a vague prompt, the model clarifies what to draw first, then paints.
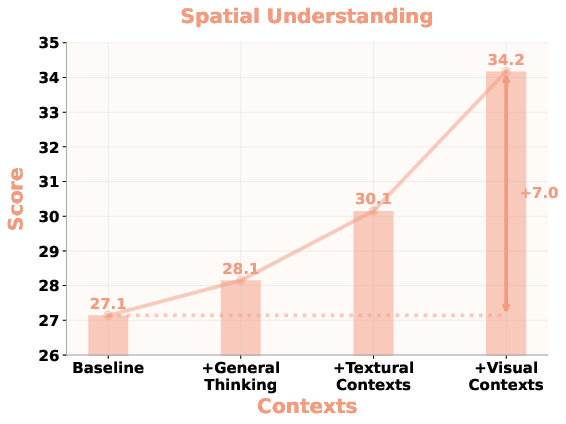
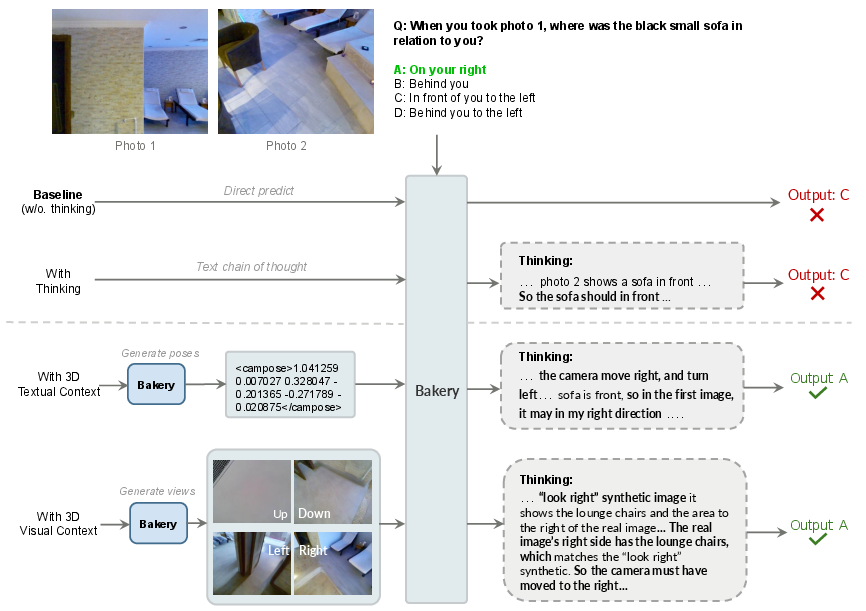
- Better 3D/spatial reasoning by “thinking with 3D”
- Some questions need 3D understanding (e.g., “Which object is to the left across two different views?”). Text-only reasoning often fails here.
- If the model first estimates camera poses (a 3D textual context) or imagines new viewpoints (a 3D visual context), it answers more accurately.
- Why it matters: Real-world scenes are 3D. Bringing in 3D cues before answering makes reasoning more grounded and less confused by perspective.
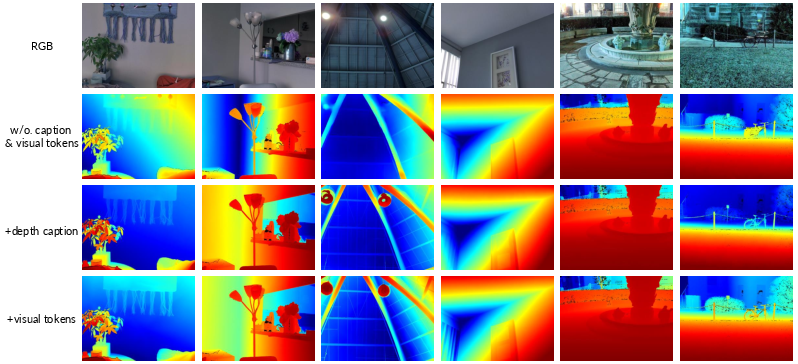
- Improved depth estimation through targeted context
- Before predicting a depth map from a single photo, the model writes a “depth caption” focused on spatial relations (like near/far, in front/behind).
- This targeted text helps more than a generic caption. Adding visual tokens (structural hints) helps even more.
- Why it matters: The right kind of context (task-relevant and constraint-like) guides the model toward sharper, more consistent depth predictions.
- Broad, competitive performance across tasks
- Understanding: Competitive with strong open models on standard benchmarks.
- Image generation and editing: Outperforms several well-known public systems on prompt-following tests; shows strong editing quality.
- Video generation and editing: Comparable scores on recognized benchmarks; especially strong at following instructions in editing.
- 3D geometry: Camera pose and depth estimation are on par with specialist models in many cases.
Overall importance: The model isn’t just a bag of features. Its main strength is using multiple skills to build a useful internal workspace before deciding—leading to more accurate, faithful, and consistent results.
What could this change in the future?
- More reliable AI “reasoning”: Instead of only thinking in words, future systems may “think” across text, images, and 3D, building evidence step by step. This can reduce mistakes and hallucinations.
- One model for many jobs: A unified model that can read, draw, edit, and reason in 3D reduces the need for separate, task-specific systems.
- Smarter planning: The model could learn when to think more (e.g., generate a new view) and when to answer quickly, depending on task difficulty—like a student deciding when to show their work.
- Real-world applications: Better spatial understanding and multimodal reasoning can help in robotics, AR/VR, design tools, and creative assistants that need to see, plan, and generate.
In short, the paper shows that when an AI takes a moment to gather the right kinds of multimodal clues before answering, it becomes more capable and trustworthy across many tasks. That’s the heart of “Context Unrolling.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research.
- Unspecified policy for “when and how to unroll” context: no algorithm for selecting the sequence of primitives φ_t, stopping criteria T, or adaptive allocation of compute; study RL-/bandit-based policies that trade off quality vs latency and learn primitive invocation conditioned on input difficulty.
- Hidden reasoning space is underdefined: the paper introduces a “hidden reasoning space” but does not specify its representation, training objective, interface with other modalities, or its ablation impact; isolate and quantify its contribution to downstream tasks.
- Visual tokenization details are missing: how discrete visual tokens are obtained (VQ-VAE/codebook size/training), jointly learned vs frozen, how they differ for images vs videos, and how token vocabulary affects structure preservation; perform systematic tokenization ablations.
- Context quality vs content ambiguity: gains are shown with longer “think” contexts, but confounded by token budget; disentangle length from information content by controlling for length and varying specificity/structure to establish causal drivers of improvement.
- Gap to “oracle” contexts remains large: the paper shows substantial boosts using Gemini-3 Pro rewrites but does not propose a self-improving pathway; explore bootstrapping, self-consistency, and distillation from oracles to close the self-rollout–oracle gap without external models.
- Error propagation from self-generated contexts: no analysis of compounded errors when subsequent primitives condition on hallucinated intermediate outputs; develop confidence estimates and guardrails for context acceptance/rejection and study cascading failure modes.
- Lack of a unified cost–quality analysis: iterative unrolling increases inference cost and latency; provide speed/compute vs accuracy trade-off curves per task and quantify marginal utility of each primitive.
- Mixture-of-Experts (MoE) routing across modalities is opaque: no disclosure of expert specialization, load balancing, or cross-modal interference; probe routing behavior, expert collapse, and fairness across modalities, and test alternative routing constraints.
- Training data composition and coverage are unspecified: sources, proportions, interleaving strategies, and licenses across modalities (esp. 3D/pose/depth) are not detailed; release a data card and ablate how data mixtures affect each capability (e.g., object-centric vs scene-centric 3D).
- Reproducibility details are thin: training compute, schedules, loss weights across tasks, curricula for “reasoning-oriented multimodal content,” and code availability are not provided; necessary for independent replication and fair comparisons.
- Evaluation uses internal or downsampled subsets: several claims rely on in-house metrics and downsampled MMSI; report full-benchmark results, statistical significance, and per-category breakdowns to assess generalization and reliability.
- Limited error analysis: few negative cases or qualitative failures are shown (e.g., MMSI categories where text-only CoT fails); provide systematic failure categorization (counting, occlusion, foreshortening, verb/action, long-tail objects).
- Any-to-any claim is only partially demonstrated: many modality paths (e.g., video→3D, 3D→video, image→3D editing, multi-hop chains) are not empirically evaluated; enumerate supported modality mappings and benchmark them explicitly.
- Video generation constraints: capped at 480×640 and 12 s; unclear scalability to higher resolutions, longer durations, and long-horizon temporal coherence; quantify resource needs and degradation with sequence length.
- 3D geometry scope is narrow: evaluates only depth and camera pose; no surface reconstruction, view-consistency, scale recovery, or dynamic-scene understanding; extend to meshes/point clouds, metric scale, and NVS faithfulness metrics.
- Camera parameters represented as text: precision, quantization, and numeric stability of text-format camera parameters are not discussed; compare textual vs structured numeric formats (e.g., tensors) for 3D tasks.
- Handling modality conflicts and noise: the model composes heterogeneous signals but the conflict resolution strategy (e.g., weighting text vs visual vs 3D cues) is unspecified; study robustness to noisy/contradictory inputs and learnable arbitration mechanisms.
- Workspace memory design is unclear: how the “shared workspace” is represented, updated (⊕ operator), managed over long contexts, and pruned is not described; evaluate memory growth, context contamination, and forgetting across iterative steps.
- Termination and verification strategies: no method for verifying intermediate contexts (e.g., self-consistency checks, cross-modal validation) or deciding when sufficient evidence has been accumulated; implement verifiers and stopping rules.
- Lack of calibrated uncertainty: neither intermediate contexts nor final outputs expose calibrated confidence; add uncertainty estimates to gate context reuse and to improve reliability under distribution shift.
- Post-training for context construction is future work: no empirical exploration of RLHF/RLAIF or cost-aware reinforcement to learn “unroll” policies; benchmark policies trained to optimize end-to-end task performance under compute budgets.
- Hallucination and safety risks in generated contexts: no analysis of how self-generated images/videos/depth maps might introduce unsafe or biased content into the reasoning loop; integrate safety filters and assess bias propagation across modalities.
- Comparison fairness: baseline mismatches (different data/compute) and lack of head-to-head against strong unified pipelines with external tools leave relative benefits ambiguous; include tool-augmented baselines and normalize for compute where possible.
- Scaling laws for context unrolling are unstudied: how performance scales with more primitives, larger context windows, and model size is unknown; derive scaling curves and diminishing returns thresholds per task class.
- Generalization under domain shift: robustness to out-of-distribution scenes, unusual camera intrinsics, motion blur, and low-light is not reported; add OOD test suites and stress tests for 3D and video.
- Catastrophic interference vs synergy: while unification claims synergy, no evidence is provided that adding modalities/tasks does not harm others; run controlled “add/remove modality” ablations to measure interference.
- Long-horizon, interactive settings: the framework is not tested in multi-turn agent scenarios where the model must plan and iteratively gather evidence; evaluate on embodied or tool-use benchmarks that require sequential context construction.
- Safety, licensing, and privacy of training resources: data provenance and potential PII inclusion are not addressed; publish dataset licenses and privacy mitigations, especially for videos and 3D scans.
- Audio and additional modalities are absent: extension to audio/speech, proprioception, or haptics—natural candidates for “native” multimodality—is not explored; investigate whether context unrolling transfers to audio-conditioned tasks.
- Exposure bias in closed-loop generation: conditioning on self-generated contexts can create feedback loops; test scheduled sampling, critic-guided filtering, or edit-distance penalties to reduce drift.
- Metrics for “context unrolling” effects are unstandardized: beyond task outcomes, there is no metric for context usefulness/quality or contribution attribution per primitive; develop diagnostic metrics and causal interventions (e.g., randomized ablations).
- Quantization and deployment constraints: no discussion of memory/latency implications for edge or interactive applications; benchmark lightweight variants and explore distillation of unrolling policies to smaller models.
Practical Applications
Overview
The paper introduces a unified multimodal model that natively learns and reasons across text, images, video, 3D geometry, and latent “visual tokens.” Its core contribution—Context Unrolling—treats modality-specific capabilities (e.g., chain-of-thought text, camera pose estimation, novel view synthesis, depth captions, structural visual tokens) as atomic primitives that are invoked to build an intermediate, task-relevant context before producing a final output. This boosts fidelity, compositionality, and spatial consistency in understanding and generation tasks. Below are practical application ideas grounded in the reported findings, benchmarks, and design choices.
Immediate Applications
The following applications can be piloted or deployed now, leveraging the demonstrated capabilities (T2I/image editing, T2V/video editing, document/chart VQA, camera pose and monocular depth estimation, spatial reasoning) and the model’s “think-first” workflows.
- Creative production copilots for images and videos (Advertising, Media/Entertainment)
- What: Improved prompt adherence and compositional control in text-to-image/video and image/video editing by auto-unrolling “text-think” (structured prompt rewrites) and rolling out “visual tokens” (structural priors) before synthesis.
- Tools/workflows:
- A design suite plug-in that creates a long-form structured prompt + layout/structure tokens, then renders and iteratively refines outputs.
- A brand compliance assistant: expands briefs into constraint-like contexts (counts, positions, relations) to reduce off-brand generations.
- Assumptions/dependencies:
- Creator oversight remains necessary to catch residual hallucinations.
- Current video limits (≈640×480, ≈12s) constrain certain commercial uses.
- Latency/compute budgets must accommodate pre-synthesis “thinking.”
- Catalog and ad image generation with spatial/attribute guarantees (Retail/E-commerce)
- What: Product imagery with better attribute correctness, counts, and spatial relations (e.g., “three blue mugs aligned in a row”).
- Tools/workflows:
- “Structured prompt rewriter” + “visual token scaffolding” to enforce object counts/relations.
- Batch pipeline for multi-variant image generation adhering to product specs.
- Assumptions/dependencies:
- Stronger results when prompts include explicit constraints; domain-specific finetuning may help rare SKUs.
- Brand safety and licensing checks for generative assets.
- Multi-view asset creation from sparse photos (Retail, Real Estate, Design, Games)
- What: Use camera pose estimation + monocular depth + novel view synthesis (NVS) as context to generate additional views, 360° spins, or quick 3D proxies.
- Tools/workflows:
- “Spin Studio” that estimates poses/depth from a few product/room images, synthesizes canonical views, and exports image sets for web showcases.
- Assumptions/dependencies:
- Real-time 3D is not guaranteed; quality depends on input coverage and texture complexity.
- Object-centric scenes may require more data (noted CO3Dv2 gap in some metrics).
- Spatial question answering across views (Software, Robotics R&D, Security/Forensics prototyping)
- What: Answer spatial queries (e.g., relative positions/motions) by first estimating camera poses or “imagining” novel views before deciding.
- Tools/workflows:
- Spatial QA tool that automatically invokes pose estimation and/or NVS to disambiguate viewpoints prior to answering.
- Assumptions/dependencies:
- Throughput may preclude heavy NVS for large-scale, real-time pipelines.
- Camera intrinsics/EXIF metadata, when available, can improve stability.
- Document and chart assistants (Finance, Enterprise IT, Research/Academia)
- What: Document VQA, chart/table understanding, and diagram QA with optional “text-think” to improve reasoning and reduce hallucinations.
- Tools/workflows:
- Enterprise document assistant that parses PDFs, slides, and charts; produces structured answers with chain-of-thought summaries.
- Assumptions/dependencies:
- Data governance and PII handling policies; tracing and auditing chain-of-thought artifacts may be necessary.
- Accessibility: enriched alt-text and scene descriptions (Public sector, EdTech)
- What: “Depth captions” that explicitly describe spatial relations, object order, occlusions, support/contact—improving image descriptions for screen readers.
- Tools/workflows:
- Accessibility middleware that adds geometry-informed captions to web images.
- Assumptions/dependencies:
- Must avoid over-confident incorrect spatial claims; provide confidence estimates.
- Data labeling accelerators for 3D tasks (Autonomy simulation, GIS, VFX)
- What: Generate approximate camera poses and monocular depth as pre-labels for datasets, accelerating 3D pipelines.
- Tools/workflows:
- Labeling tool that runs pose/depth “think” passes, then surfaces uncertain regions for human review.
- Assumptions/dependencies:
- Outputs should be treated as priors; integration into QA workflows is key.
- Interactive learning aides that “think with images” (Education)
- What: Tutors that interleave textual reasoning with visual scaffolds (e.g., synthesized intermediate views or object layouts) to teach geometry/physics concepts.
- Tools/workflows:
- Lesson builders that produce multimodal step-by-step explanations and visualizations per concept.
- Assumptions/dependencies:
- Pedagogical alignment and content moderation; avoid over-reliance on synthesized visuals for factual claims.
- Consistency-first game asset prototyping (Gaming)
- What: Generate character/prop images with stable counts/relations/layout using visual-token scaffolding and long-form prompts.
- Tools/workflows:
- Asset generator that outputs consistent turnarounds and pose-varied sprites from few references.
- Assumptions/dependencies:
- Style and IP constraints; tune on domain art styles for best results.
Long-Term Applications
These opportunities require further research, scaling, or engineering (e.g., larger models, lower latency, RL-style policies for when/how to unroll, higher video resolution/length, robust safety).
- Embodied agents with multimodal chain-of-thought (Robotics, Warehousing, Field Ops)
- What: Robots that dynamically choose to estimate pose, synthesize hypothetical views, and produce depth captions before acting.
- Tools/products:
- A policy-optimized “context unrolling” controller that learns when to allocate compute to perception primitives.
- Assumptions/dependencies:
- Real-time constraints, safety certifications; robust failure detection; datasets covering edge cases; on-device acceleration.
- AR assistants with spatially grounded guidance (Consumer AR, Industrial AR)
- What: Wearable assistants that reason about 3D scenes—narrating spatial instructions, checking placements, and “imagining” missing views to reduce ambiguity.
- Tools/products:
- On-device multimodal workbench that fuses live video, depth, and text reasoning for procedural guidance (e.g., assembly, maintenance).
- Assumptions/dependencies:
- Efficient on-device inference; privacy-preserving pipelines; high-quality IMU/camera calibration.
- Medical imaging copilots with multimodal reasoning (Healthcare)
- What: Multimodal assistants that combine medical images with textual knowledge and geometry-aware context to explain findings and generate educational visuals.
- Tools/products:
- Radiology teaching aids that create geometry-informed explanations and cross-view consistency checks.
- Assumptions/dependencies:
- Regulatory approvals (e.g., FDA); clinically curated training data; stringent guardrails; robust uncertainty quantification.
- Media provenance and inconsistency forensics (Policy, Media, Trust & Safety)
- What: Use cross-view spatial reasoning and “imagination-as-context” to detect physically inconsistent manipulations across videos/images.
- Tools/products:
- Forensic analyzers that attempt novel-view verification and pose-based consistency checks.
- Assumptions/dependencies:
- Adversarial robustness; low false-positive rates; explainability for legal/adjudication contexts.
- Industrial inspection and planning via “imagination” (Manufacturing, Energy/Utilities)
- What: Systems that propose inspection viewpoints by synthesizing candidate views, highlighting likely blind spots or occlusions.
- Tools/products:
- Viewpoint planner that couples pose/depth estimation with NVS to guide drone/robot inspections of assets (e.g., turbines, substations).
- Assumptions/dependencies:
- Accurate scene priors; integration with SLAM and flight controllers; safety validation.
- Scalable “any-to-any” 3D asset pipelines (E-commerce, Games, Digital Twins)
- What: From sparse photos/text to consistent multi-view images/videos and 3D proxies, then to meshes or Gaussian splats, using unrolled contexts as constraints.
- Tools/products:
- Pipeline that exports structured contexts (poses, depth, layout tokens) as contracts for downstream 3D reconstruction and material baking.
- Assumptions/dependencies:
- Quality thresholds for commercial use; domain adaptation; IP compliance.
- Personalized multimodal tutoring agents (Education)
- What: Tutors that adaptively choose when to generate diagrams, novel views, or depth captions as part of instruction, not just text explanations.
- Tools/products:
- Multimodal lesson planners that learn a policy over context-building steps based on learner performance.
- Assumptions/dependencies:
- Measurement of learning gains; accessibility compliance; content safety.
- Autonomy perception stacks with unified context (Autonomous Driving/Drones)
- What: Unified perception models that condition predictions on intermediate geometric and generative contexts to improve robustness under occlusions and distribution shifts.
- Tools/products:
- Perception engines co-optimized with RL to decide when to invoke pose/depth/NVS under uncertainty.
- Assumptions/dependencies:
- Strict real-time performance, robustness in the open world, interpretability.
- Multimodal workbench for knowledge workers (Enterprise Software)
- What: A “shared workspace” that persists and composes intermediate contexts (long-form text, visual tokens, geometry) across tasks (e.g., analysis, presentation, simulation).
- Tools/products:
- SDK that exposes primitives: describe, layout, pose, depth, novel view, verify; policies to choose context steps per task.
- Assumptions/dependencies:
- Governance and audit of chain-of-thought artifacts; cost controls for compute-heavy steps.
- Standards and governance for multimodal chain-of-thought (Policy/Standards)
- What: Frameworks for logging, auditing, and redacting intermediate multimodal contexts (including synthesized views) in regulated workflows.
- Tools/products:
- Traceability standards and dashboards for context unrolling steps in high-stakes domains.
- Assumptions/dependencies:
- Agreement on privacy implications of generated intermediate visuals; alignment with sector-specific regulations.
Notes on Feasibility and Integration
- Performance envelopes: The paper reports strong image understanding/generation and competitive video/3D metrics, but current video is limited in resolution/duration, and some object-centric 3D benchmarks show gaps—plan pilots accordingly.
- Cost/latency trade-offs: Context unrolling adds steps (e.g., long-form text, pose, NVS, visual tokens). Production deployments should learn policies for when to unroll to balance quality vs. throughput.
- Reliability and safety: Self-generated contexts can hallucinate; introducing “oracle” contexts in experiments shows headroom but relies on external models. Deploy guardrails, confidence scoring, and human-in-the-loop review for high-stakes use.
- Data and domain coverage: Feasibility improves with domain-tuned prompts and, where allowed, fine-tuning or adapters for sector-specific content (e.g., medical, industrial).
- IP and compliance: Generative assets require licensing, watermarking/provenance, and compliance with brand and regulatory standards.
- Tooling opportunity: An SDK exposing the model’s primitives (describe, pose, depth, NVS, visual tokens) as callable operators is a natural integration point across products and research workflows.
Glossary
- AbsRel: Absolute Relative Error; a common metric for evaluating depth estimation where lower is better. "AbsRel "
- Any-to-any multimodal learning: A training/inference setup where any input modality can map to any output modality. "supports any-to-any multimodal learning."
- Atomic primitives: Minimal, callable sub-capabilities the model can invoke during reasoning (e.g., describe, predict pose, synthesize view). " are atomic primitives (e.g.,
describe,''predict pose,''roll out visual tokens,''synthesize a novel view,'' ``estimate depth'')" - Atomicity: A stress-test measure assessing robustness as prompts include more compositional requirements. "We also report atomicity, which evaluates robustness under increasing prompt compositionality."
- AUC@30: Area Under the (accuracy) Curve up to a 30-degree/threshold; used to summarize camera pose estimation accuracy. "AUC30 "
- Camera pose estimation: Predicting camera orientation and position from images. "camera pose estimation, novel view synthesis, and depth estimation"
- Chain-of-thoughts: Step-by-step textual reasoning used to structure intermediate inferences before producing an answer. "(i) fine-grained textual reasoning (chain-of-thoughts)"
- Compositional generalization: The ability to correctly handle prompts composed of multiple interacting requirements. "compositional generalization."
- Context composition: The operation of adding newly generated intermediate results into the evolving context. " denotes context composition."
- Context Unrolling: An emergent process where the model explicitly reasons across multiple modalities before final prediction. "We observe that prediction quality improves as models perform Context Unrolling across more modalities"
- Context-conditioned decoding: Generating outputs conditioned on an iteratively constructed intermediate context. "followed by context-conditioned decoding:"
- Discrete visual tokens: Non-continuous visual representations (tokens) carrying structural cues used as conditioning context. "visual contexts denote the discrete visual tokens."
- Geometry-as-Context: Using explicit geometric information (e.g., camera poses) as intermediate context to improve reasoning. "3D Textural Contexts: Geometry-as-Context."
- Hidden reasoning space: An internal latent space dedicated to supporting multimodal reasoning before output. "We additionally introduce a hidden reasoning space as a dedicated latent representational space"
- In-context generation: Producing outputs (text, images, video, 3D) by leveraging and expanding the current context without additional training. "including in-context generation of text, image, video, and 3D geometry."
- Interleaved data paradigm: A training scheme where multimodal data are interleaved to encourage cross-modal reasoning. "Building upon the interleaved data paradigm introduced in BAGEL"
- Latent representational space: An internal, learned feature space where different modalities can be jointly represented. "a dedicated latent representational space"
- Latent world knowledge space: A shared internal space encoding world knowledge that different modalities project onto. "a shared latent world knowledge space"
- Mixture-of-Experts architecture: A neural architecture that routes inputs to a subset of specialized expert subnetworks. "adopts a mixture-of-experts architecture."
- Monocular depth estimation: Predicting scene depth from a single RGB image. "the long-standing problem of monocular depth estimation"
- Multimodal manifold: The shared structure of world knowledge represented across different modalities. "Each modality provides only a partial and biased view of this multimodal manifold"
- Novel view synthesis: Generating new viewpoints of a scene from given observations. "novel view synthesis"
- Oracle contexts: High-quality, near-ground-truth intermediate contexts used to estimate upper-bound performance. "oracle contexts yield a substantial leap in generation quality"
- Relative Pose Error (RPE): A metric measuring error in estimated camera motion, reported as translation (trans) and rotation (rot). "RPE trans"
- Shared workspace: The common context buffer where intermediate textual, visual, and geometric artifacts are written for subsequent reasoning. "into a shared workspace before producing predictions."
- Soft TIFA: A metric variant measuring prompt-level correctness for generation tasks. "Soft TIFA measures prompt-level correctness."
- Text-think: An explicit pre-answer reasoning mode where the model generates intermediate textual descriptions/constraints. "enable a text-think mode before answering."
- World knowledge manifold: The learned, structured representation of real-world knowledge across modalities. "learn a world knowledge manifold"
- Zero-shot: Performing a task without task-specific fine-tuning or examples at inference time. "in the zero-shot manner"
Collections
Sign up for free to add this paper to one or more collections.