- The paper presents Mini-o3, a novel VLM that uses iterative agentic image tool use to achieve deep multi-turn reasoning and state-of-the-art visual search performance.
- It introduces a cold-start supervised fine-tuning phase and a reinforcement learning strategy with over-turn masking to scale reasoning depth efficiently.
- Empirical results show that increasing interaction turns leads to higher accuracy, highlighting the model's practical benefits for complex visual search tasks.
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Introduction and Motivation
Mini-o3 addresses a critical limitation in current open-source Vision-LLMs (VLMs): the inability to perform deep, multi-turn reasoning in visual search tasks that require trial-and-error exploration. Existing models typically exhibit shallow reasoning patterns and are constrained to a small number of interaction turns, resulting in poor performance on complex visual search benchmarks. Mini-o3 is designed to scale both the depth and diversity of reasoning, enabling agentic tool use over tens of steps and achieving state-of-the-art results on challenging datasets.
Framework Overview
Mini-o3 implements a multi-turn agentic pipeline for image tool use. At each turn, the model generates a "thought" and an "action" based on the current observation and interaction history. The action either grounds a region in the image (via a normalized bounding box) or emits a final answer. The observation is the image patch resulting from the action, which is appended to the trajectory and used for subsequent reasoning.
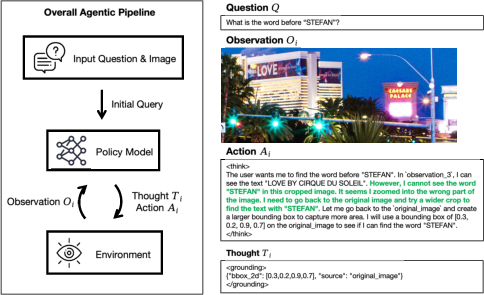
Figure 1: The Mini-o3 framework for multi-turn agentic image tool use, iteratively generating thoughts and actions conditioned on previous observations.
This iterative loop continues until the model produces a final answer or reaches predefined limits on context length or interaction turns. The design supports reasoning strategies such as depth-first search, hypothesis revision, and backtracking, which are essential for solving difficult visual search problems.
Training Methodology
VisualProbe Dataset
Mini-o3 is trained on the VisualProbe dataset, which contains thousands of high-resolution images with small targets, numerous distractors, and questions that require iterative exploration. The dataset is explicitly constructed to elicit diverse reasoning patterns and long-horizon trajectories.

Figure 2: VisualProbe dataset features small targets, distractor objects, and high-resolution images, demanding trial-and-error exploration.
Cold-Start Data Collection
To overcome the base model's lack of exposure to multi-turn agentic trajectories, Mini-o3 employs a cold-start supervised fine-tuning (SFT) phase. Diverse multi-turn trajectories are synthesized by prompting an existing VLM with a small set of exemplars, iteratively generating thoughts and actions until a correct answer is produced. Only successful trajectories are retained, ensuring high-quality supervision.
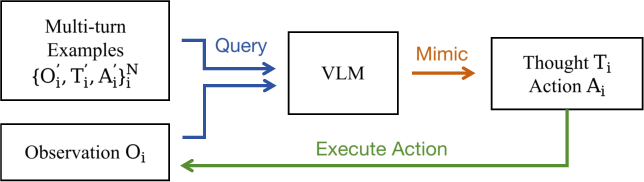
Figure 3: Pipeline for cold-start data collection, leveraging in-context learning to synthesize diverse multi-turn trajectories.
Reinforcement Learning with Over-Turn Masking
Mini-o3 applies GRPO-based reinforcement learning with verifiable, semantics-aware rewards. A key innovation is the over-turn masking technique: responses that hit the maximum turn or context length are masked out during policy updates, preventing negative learning signals from incomplete trajectories. This enables efficient training with a modest turn budget (e.g., 6 turns) while allowing test-time trajectories to scale to tens of turns.
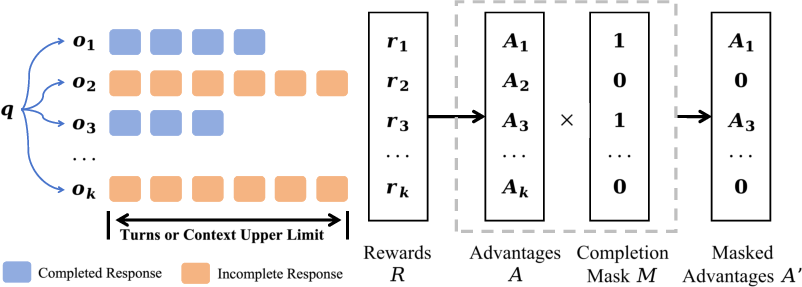
Figure 4: Over-turn masking technique prevents penalization of incomplete responses, supporting test-time scaling of interaction turns.
Empirical Results
Mini-o3 demonstrates a strong test-time turns scaling property: accuracy continues to grow as the upper limit on the number of turns increases from 4 to 32, despite training with only 6 turns. This is in contrast to baselines such as DeepEyes, which plateau early and fail to benefit from additional interaction depth.
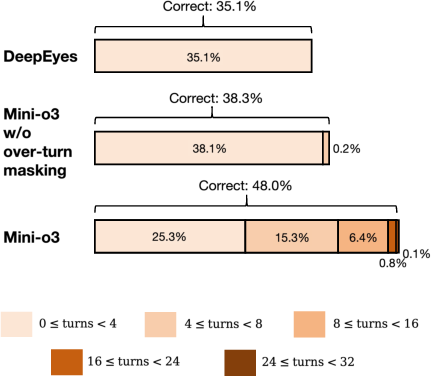
Figure 5: Left: Mini-o3 accuracy increases with more allowed turns during testing. Right: Distribution of correct trajectories shows deeper thinking paths for Mini-o3.
Ablation studies confirm the necessity of each component: hard RL data, cold-start SFT, and over-turn masking all contribute significantly to performance. The choice of maximum pixel budget is also critical; too large a budget induces premature stopping, while too small a budget increases hallucinations. Optimal performance is achieved by balancing perceptual accuracy and interaction depth.
Qualitative Analysis
Mini-o3 produces complex, multi-turn reasoning trajectories in diverse real-world scenarios. Examples include progressive zoom-in and hypothesis revision in urban intersections, targeted zoom-ins and cross-checking in container yards, and coarse-to-fine zooming with verification in cluttered village scenes.
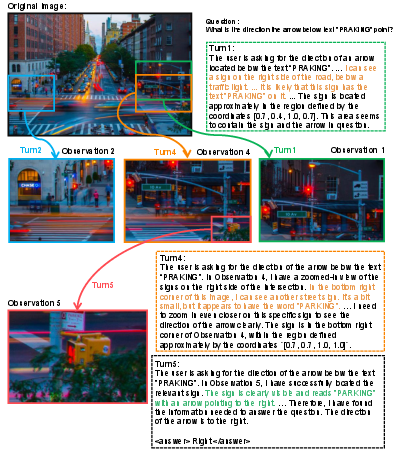
Figure 6: Multi-turn reasoning in a busy urban intersection, identifying the direction of an arrow via progressive zoom-in and backtracking.
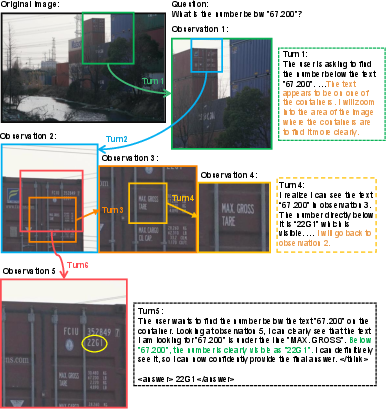
Figure 7: Multi-turn reasoning in a container yard, locating and reading text through targeted zoom-ins and step-by-step verification.

Figure 8: Multi-turn reasoning in a lakeside village, localizing and recognizing digits on a road sign after 18 reasoning turns.
These examples illustrate Mini-o3's ability to sustain deep chains of thought, adaptively revise hypotheses, and perform robust verification across observations.
Implementation Considerations
- Base Model: Qwen2.5-VL-7B-Instruct is used, but the approach is generalizable to other VLMs with sufficient context length and image tool integration.
- Context Length and Pixel Budget: The context length (32K tokens) and pixel budget (2M per image) are tuned to maximize the number of feasible interaction turns without sacrificing perceptual fidelity.
- Training Efficiency: Over-turn masking allows training with a small turn budget, reducing resource requirements (e.g., 3 days for 6 turns vs. 10 days for 16 turns) with negligible impact on test accuracy.
- Inference: Temperature is set to 1.0 to mitigate repetition in long trajectories.
Implications and Future Directions
Mini-o3 establishes a practical recipe for scaling agentic reasoning in VLMs, enabling robust performance on tasks that require deep, trial-and-error exploration. The over-turn masking strategy is broadly applicable to other RL-based agentic systems, facilitating efficient training and test-time scaling. The VisualProbe dataset sets a new standard for evaluating multi-turn visual reasoning.
Future work may explore:
- Extending the approach to larger models and more diverse toolkits (e.g., web browsing, code execution).
- Integrating more sophisticated reward models for semantic evaluation.
- Investigating scaling laws for interaction turns and context length in multimodal RL.
Conclusion
Mini-o3 advances the state-of-the-art in multi-turn visual search by combining a challenging dataset, a cold-start data collection pipeline, and an over-turn masking strategy for reinforcement learning. The model demonstrates scalable reasoning depth, diverse agentic behaviors, and strong empirical performance across benchmarks. The methodology provides actionable guidance for developing multimodal agents capable of deep, iterative exploration in complex environments.

