- The paper presents a novel test-time multimodal reasoning framework using agent coordination to overcome fixed modality limitations.
- It leverages individual foundation models for text, image, audio, and video with an iterative self-improvement loop for coherent output.
- Experimental results demonstrate high accuracy across benchmarks (e.g., 83.21% on MMLU-Pro) despite increased inference latency.
Agent-Omni: Test-Time Multimodal Reasoning via Model Coordination for Understanding Anything
Motivation and Problem Statement
The Agent-Omni framework addresses the limitations of current multimodal LLMs (MLLMs), which are typically restricted to fixed modality pairs and require extensive fine-tuning with large, aligned datasets. Existing omni models suffer from modality interference and trade-offs, where improvements in one modality can degrade performance in others. Furthermore, robust omni-modal reasoning—integrating arbitrary combinations of text, image, audio, and video—remains an unsolved challenge due to the lack of comprehensive datasets and the complexity of cross-modal integration.
Agent-Omni Framework Architecture
Agent-Omni introduces a modular, agent-based system that coordinates existing foundation models at inference time, obviating the need for retraining or joint fine-tuning. The architecture is hierarchical, with a master agent orchestrating the reasoning process and delegating subtasks to modality-specific agents. The workflow consists of four stages: perception, reasoning, execution, and decision, with iterative self-improvement loops for answer refinement.
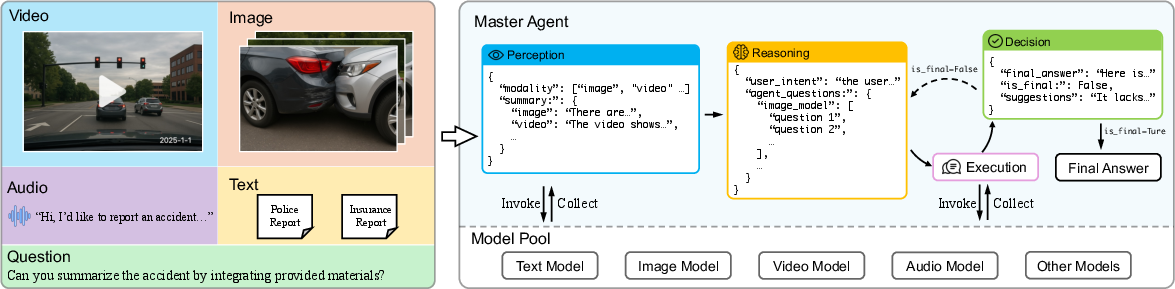
Figure 1: Agent-Omni architecture: master agent interprets queries, delegates to modality-specific agents, and iteratively integrates outputs for coherent multimodal reasoning.
Perception
The master agent first analyzes the input modalities and generates structured semantic representations (e.g., JSON summaries), aligning heterogeneous data into a unified space for downstream reasoning.
Reasoning
User queries are decomposed into modality-specific sub-questions, each explicitly linked to the relevant agent. This decomposition is explicit and interpretable, facilitating traceable execution plans.
Execution
Sub-questions are dispatched to the corresponding foundation models in the model pool. Each model processes its assigned modality and returns structured outputs, which are paired with their respective sub-questions.
Decision and Iterative Self-Improvement
The master agent integrates all outputs to synthesize a final answer, evaluates completeness, and determines if further refinement is necessary. If gaps or inconsistencies are detected, the agent triggers another reasoning-execution-decision loop, guided by feedback instructions. This iterative process continues until the answer is deemed complete or a maximum number of loops is reached.
Model Pool and Modularity
The model pool comprises specialized foundation models for each modality: LLMs for text, vision-LLMs for images and video, and speech-text models for audio. Models are invoked on demand, and the pool is extensible—new models can be added without retraining the system. This decoupling of model selection from reasoning enables dynamic orchestration and scalability.
Experimental Evaluation
Agent-Omni is evaluated on a comprehensive suite of benchmarks spanning text (MMLU, MMLU-Pro, AQUA-RAT), image (MathVision, MMMU, MMMU-Pro), video (VideoMathQA, STI-Bench, VSI-Bench), audio (MMAU, MELD-Emotion, VoxCeleb-Gender), and omni-level tasks (Daily-Omni, OmniBench, OmniInstruct).
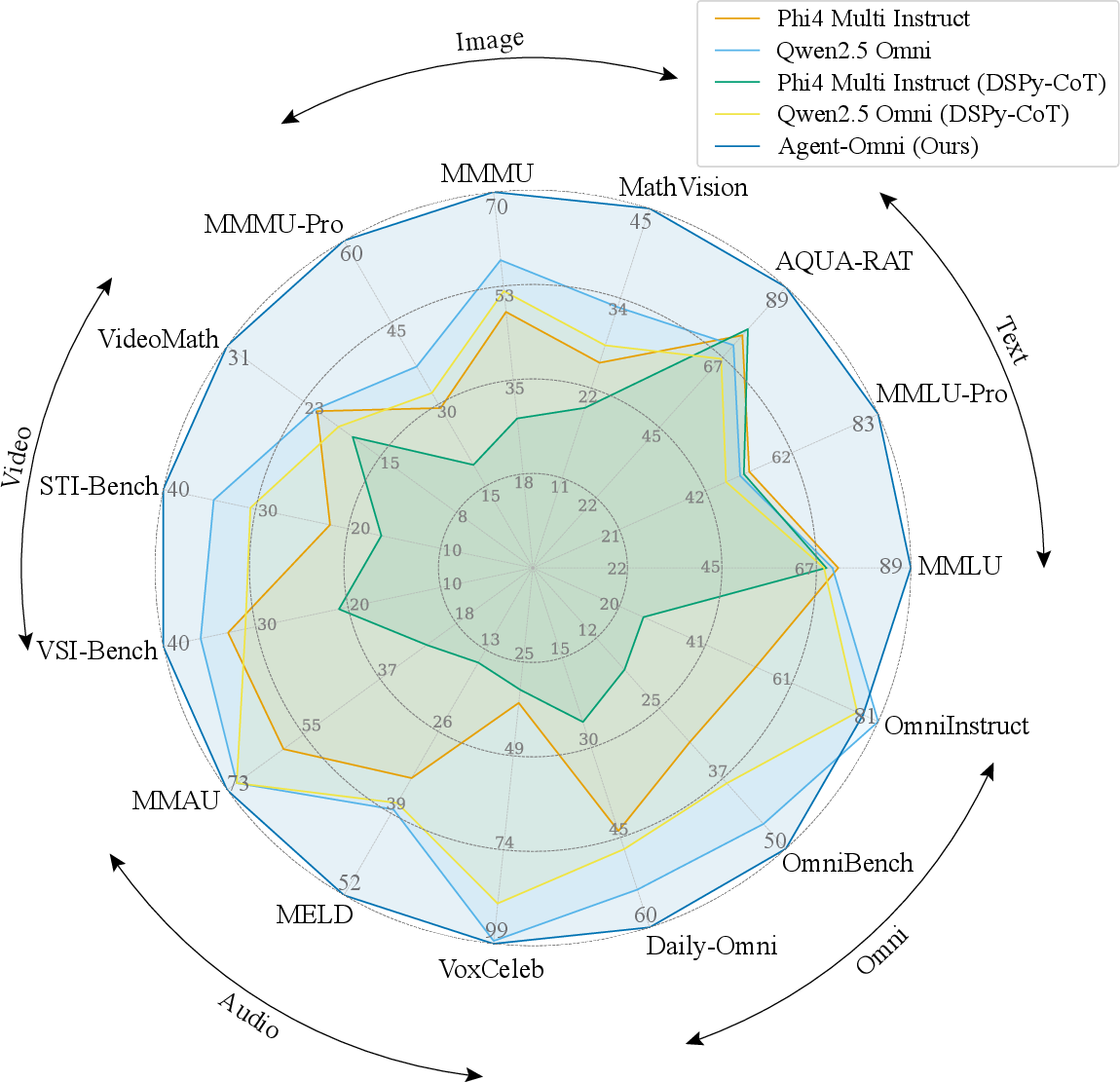
Figure 2: Agent-Omni achieves superior accuracy across multimodal benchmarks compared to other omni methods.
Accuracy Across Modalities
Agent-Omni consistently matches or exceeds the performance of the strongest single-modality models and omni baselines. Notably, it achieves the highest accuracy on challenging datasets such as MMLU-Pro (83.21%), MMMU-Pro (60.23%), and Daily-Omni (60.03%). The agent-based coordination avoids the trade-offs inherent in joint training, preserving the strengths of individual expert models.
Latency and Computational Trade-offs
Agent-Omni introduces additional inference latency (4–7s for unimodal tasks, up to 20s for video) due to master-agent coordination and iterative reasoning. However, this overhead is justified by substantial gains in reasoning quality and robustness, especially for complex cross-modal tasks. Parallelized execution and optimized orchestration are potential avenues for reducing latency.
Ablation Studies
Ablation experiments reveal that most queries terminate after the first iteration, but more complex tasks benefit from additional reasoning loops, yielding incremental accuracy improvements. The choice of foundation models in the pool directly impacts end-task performance, confirming that leveraging high-quality specialized models is critical for optimal results.
Implementation Considerations
- Integration: The framework requires API access to foundation models and a robust orchestration layer for agent communication. Structured JSON schemas are used for inter-agent messaging.
- Extensibility: New modalities or models can be added by updating the model pool and agent selection logic.
- Resource Requirements: Experiments were conducted on multi-GPU servers, but the modular design allows for distributed or cloud-based deployment.
- Latency: Iterative reasoning increases inference time; batching and parallelization can mitigate this.
- Transparency and Interpretability: The explicit reasoning and decision stages, along with structured outputs, facilitate traceability and debugging.
Implications and Future Directions
Agent-Omni demonstrates that test-time model coordination is a viable alternative to unified omni-model training, enabling scalable, robust, and interpretable multimodal reasoning. The framework is particularly suited for domains where data alignment is impractical or where rapid integration of new modalities is required. Future work may explore:
- Parallelized agent execution to further reduce latency.
- Adaptive agent selection based on input characteristics and task requirements.
- Extension to non-textual outputs (e.g., image or audio generation).
- Robustness to noisy or adversarial inputs and real-world deployment scenarios.
- Integration with safety and bias mitigation pipelines for high-stakes applications.
Conclusion
Agent-Omni provides a principled framework for omni-modal reasoning by orchestrating specialized foundation models through a master-agent loop. It achieves state-of-the-art performance across diverse benchmarks without retraining, offering a scalable and interpretable solution to the challenges of multimodal understanding. The modular design ensures adaptability and future extensibility, positioning Agent-Omni as a robust foundation for next-generation AI systems requiring comprehensive multimodal reasoning.

