Stabilizing Efficient Reasoning with Step-Level Advantage Selection
Abstract: LLMs achieve strong reasoning performance by allocating substantial computation at inference time, often generating long and verbose reasoning traces. While recent work on efficient reasoning reduces this overhead through length-based rewards or pruning, many approaches are post-trained under a much shorter context window than base-model training, a factor whose effect has not been systematically isolated. We first show that short-context post-training alone, using standard GRPO without any length-aware objective, already induces substantial reasoning compression-but at the cost of increasingly unstable training dynamics and accuracy degradation. To address this, we propose Step-level Advantage Selection (SAS), which operates at the reasoning-step level and assigns a zero advantage to low-confidence steps in correct rollouts and to high-confidence steps in verifier-failed rollouts, where failures often arise from truncation or verifier issues rather than incorrect reasoning. Across diverse mathematical and general reasoning benchmarks, SAS improves average Pass@1 accuracy by 0.86 points over the strongest length-aware baseline while reducing average reasoning length by 16.3%, yielding a better accuracy-efficiency trade-off.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI LLMs (like the ones that solve math word problems) to think efficiently. Today, these models often “overthink”—they write very long explanations to get the right answer. That uses a lot of time and computer power. The authors show a way to make models reason more briefly without losing accuracy, and to keep training stable while doing so.
What questions are the researchers asking?
- Can we make AI models give shorter, clearer solutions without hurting their correctness?
- Is the reason some models get shorter after training actually because they’re trained with a shorter “memory” (context window), not just because of special “shorter-is-better” rewards?
- How can we fix the unstable training that happens when the model’s answers get cut off by the short memory and are graded as “wrong” even if the steps were good?
How did they approach the problem?
Think of an AI solving a math problem like a student showing their work in steps:
- “Context window” = the model’s writing space or memory. A short context is like being forced to use a small notebook page; long solutions get cut off.
- “Verifier” = an automatic checker that marks the final answer right or wrong.
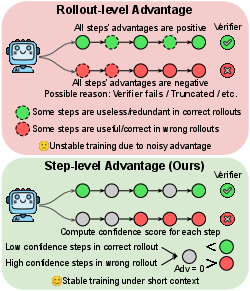
- “GRPO” (a training method) = the teacher who rewards or penalizes the whole solution at once. If the final answer is correct, all steps get rewarded; if it’s wrong (or cut off), all steps get penalized—even if many steps were good.
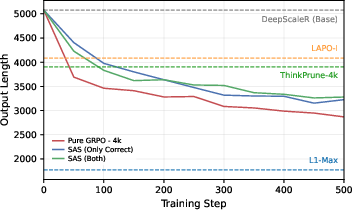
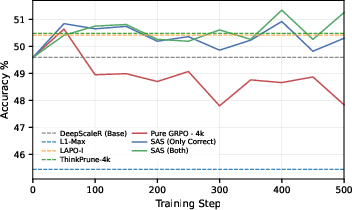
The researchers first trained models using a short memory (short context) but without any special “shorter is better” reward. They discovered that this alone makes the model’s solutions much shorter. But there’s a problem: because long solutions get cut off, many partly correct solutions are marked “wrong,” and the model gets punished for good steps. Training becomes shaky, and accuracy can drop.
To fix this, they created Step-level Advantage Selection (SAS). Instead of treating the whole solution as all good or all bad, SAS looks at each step’s quality and only updates the model using the reliable parts.
Here’s the simple idea behind SAS:
- Break each solution into steps (like separating paragraphs).
- Estimate how confident the model was for each step (how “sure” it sounded).
- If the solution is correct, ignore (don’t reward) the lower-confidence, likely redundant steps.
- If the solution is marked wrong (often because it was cut off), protect (don’t penalize) the high-confidence, likely correct steps.
By “ignoring,” they mean those steps don’t affect the model’s learning—so the model learns from the trustworthy parts and doesn’t learn bad habits from grading mistakes.
What did they find, and why does it matter?
Main findings:
- Training with a short memory naturally makes solutions shorter—even without special rewards. But it also makes training unstable and can reduce accuracy because cut-off solutions get judged as “wrong.”
- SAS fixes this by being picky about which steps affect learning. It avoids rewarding uncertain, extra steps and avoids punishing strong, correct steps in cut-off answers.
- Across many math and general reasoning tests, SAS gave a better balance: solutions were shorter while accuracy stayed the same or improved. On average, it improved accuracy by around 1 point and reduced solution length by roughly 15–30%, beating other methods designed to shorten answers.
Why it matters:
- Shorter solutions mean faster responses, lower costs, and less energy use.
- Keeping accuracy steady (or improving it) while getting shorter answers is a win-win.
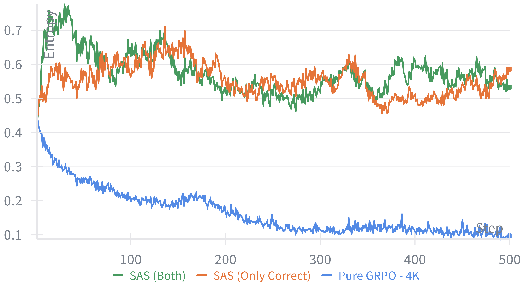
- Training becomes more stable—fewer wild ups and downs in performance.
What’s the bigger impact?
- For users: Quicker answers without sacrificing quality—useful in tutoring, customer support, and coding.
- For developers: A simple add-on to existing reinforcement learning pipelines that improves the “accuracy vs. efficiency” trade-off, without needing extra reward models or big architecture changes.
- For research: It shows that how we assign “credit” within a solution (step by step) matters a lot. It also reveals that short training contexts alone push models to be concise—so future studies should separate that effect from special reward designs.
In short, this paper introduces a practical way to make AI “think just enough” by learning from the right steps and ignoring the noisy ones—leading to faster, more reliable reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Generalization across model families and scales: SAS is only evaluated on DeepScaleR-1.5B; it is unknown how it behaves for larger/smaller models, different architectures (e.g., Llama, Mixtral), or models trained with different RLHF/RLAIF pipelines.
- Effect of training context length: The study fixes training at 4K; a systematic sweep over training windows (e.g., 2K/4K/8K/16K/24K) is needed to isolate how compression and stability scale with context length.
- Curriculum or mixed-context training: It is unclear whether gradually lengthening context during SAS (or mixing short/long windows) yields better stability or compression than fixed 4K.
- Domain coverage: Beyond math and three general reasoning benchmarks, SAS was not tested on code generation, multi-hop knowledge QA, long-form reasoning, multimodal problems, or multilingual datasets.
- Inference setting mismatch: Pass@1 is computed by averaging over k=16 samples; the impact on single-shot greedy decoding (common in production) and the corresponding length/latency trade-offs remain unreported.
- Sensitivity to step segmentation: Steps are heuristically defined by double newlines; robustness to alternative delimiters, languages without this convention, tasks with different formatting, or absence of step breaks is not studied.
- Learned/semantic segmentation: Whether syntactic or learned segmentation (e.g., PRM-guided, discourse-aware, AST-based for code) can outperform newline-based splitting is unexplored.
- Confidence metric choice: Step confidence uses mean token log-prob; alternatives (e.g., entropy, calibrated probabilities, variance across samples, margin to next-best token, PRM scores, ensembles) and their robustness are not evaluated.
- Confounding between confidence and redundancy: High-confidence steps may reflect frequent patterns rather than usefulness; measuring whether SAS over-reinforces generic or superficial steps is left open.
- Dynamic or learned masking: The selection ratio r is fixed; per-prompt, per-rollout, or curriculum-learned r (or thresholding by an absolute confidence margin) could improve adaptivity but was not explored.
- Soft weighting vs hard zeroing: SAS sets advantages to zero; the efficacy of soft attenuation (e.g., confidence-weighted scaling, margin-based clipping) versus hard masking is untested.
- Group-relative normalization dependence: SAS leverages GRPO’s group-relative advantages; behavior under different advantage estimators, PPO variants, GAE/token-level returns, or other RL frameworks (e.g., DPO, IPO, RL with partial-credit rewards) is unknown.
- Group size and normalization sensitivity: The impact of GRPO group size G, alternative normalization strategies, and stability under different batch/group configurations is not analyzed.
- Verifier dependence and failure modes: The approach assumes many verifier failures are truncations; quantifying verifier error rates across datasets and integrating partial-credit verifiers or multi-verifier ensembles remain open.
- Shielding wrong-but-confident steps: In failed rollouts, high-confidence but incorrect steps may be shielded; measuring the fraction of shielded steps that are truly correct (vs confidently wrong) and mitigating this risk is not addressed.
- Truncation analysis breadth: The 29% truncation effect is computed on a specific setup; how truncation-induced failures vary with datasets, temperatures, top-p, and model families is unmeasured.
- Combination with length-aware rewards: Whether SAS yields additive or synergistic gains when combined with explicit length penalties, token budgets, or inference controllers remains an open design space.
- Exploration vs exploitation trade-off: Although entropy is reported, deeper analysis of how SAS biases exploration (e.g., diversity of reasoning paths, mode collapse risk) and its long-horizon effects is missing.
- Long-horizon tasks needing >4K tokens: It is unclear whether compression compromises tasks that genuinely require long chains; evaluating SAS on problems with solutions exceeding the training window is necessary.
- Evaluation robustness and significance: Results are reported for single training runs; variance across random seeds, confidence intervals, and statistical significance tests are absent.
- Validation set selection bias: Using AIME24 for checkpoint selection may induce overfitting; cross-validation or alternative dev sets would clarify robustness.
- AES metric dependence: AES is used as the main trade-off metric, but sensitivity to its formulation, alternative compute-aware metrics (e.g., wall-clock, energy), and per-task weights is not analyzed.
- Computational scaling: SAS adds ~17% per-step overhead on 1.5B models; scaling curves for larger models, distributed efficiency, memory bandwidth, and total training cost vs. gains are not reported.
- Inference-time controls: The paper addresses training-time compression only; whether SAS can inform on-the-fly early stopping, adaptive halting, or budget-aware decoding at inference remains unexplored.
- Reward hacking risks via formatting: The model could learn to insert or avoid delimiters to influence step masking; safeguards against segmentation gaming are not discussed.
- Theoretical grounding: A formal analysis of bias introduced by step-level advantage selection, its convergence properties, and conditions for stability is deferred to future work.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging SAS’s step-level advantage masking to stabilize short-context RL post-training and compress chain-of-thought without explicit length rewards.
- Efficient enterprise LLM fine-tuning to cut inference cost and latency
- Sector: software, customer support, enterprise search, BI analytics
- What: Add SAS to existing GRPO/TRL/VeRL pipelines to produce concise reasoning for chatbots and internal assistants, reducing average output tokens by ~15–30% with maintained or improved Pass@1.
- Tools/workflows: VeRL integration; step segmentation via double newlines; token log-prob confidence scoring; AES as a KPI to balance accuracy and length.
- Assumptions/dependencies: Rule-based verifiers or task correctness signals are available; text is structured enough that step boundaries (e.g., “\n\n”) are meaningful.
- Cost-optimized math and logic tutoring systems
- Sector: education
- What: Fine-tune math tutors to retain correct steps while pruning redundant detours, improving student-facing clarity and reducing token spend on platforms billing by tokens.
- Tools/workflows: Curriculum datasets (AIME/AMC/MATH-style); SAS training with r≈0.3; short-context (4K) RL to compress reasoning.
- Assumptions/dependencies: Automatic verifiers for numeric answers or symbolic checks; step segmentation aligns with pedagogy (clear step-by-step formatting).
- Concise code reasoning assistants
- Sector: software engineering, DevOps
- What: Train code assistants to explain fixes and plans succinctly (fewer verbose confirmations), preserving decision-critical steps while minimizing chatter.
- Tools/workflows: Add SAS to RLHF/GRPO on code QA datasets with test/verifier signals; CI bots with AES-based checkpoints to optimize speed-vs-correctness.
- Assumptions/dependencies: Reliable unit tests or static analyzers as verifiers; step segmentation may need adaptation beyond “\n\n” due to code formatting.
- Faster legal/logic exam prep helpers (LSAT-style reasoning)
- Sector: education, test prep
- What: Apply SAS to general reasoning datasets (e.g., LSAT subsets) to generate concise, high-precision justifications that fit mobile screens and cut latency.
- Tools/workflows: GRPO with short context; SAS to shield strong intermediate steps when responses truncate.
- Assumptions/dependencies: Availability of correctness checks or multiple-choice scoring; careful calibration to avoid omitting legally relevant caveats.
- Cloud serving optimization for long-CoT models
- Sector: cloud platforms, MLOps
- What: Re-tune existing long-context reasoning models with SAS to shorten default generations, increasing throughput and reducing queue time under peak load.
- Tools/workflows: Deployment presets with lower max_new_tokens for SAS-tuned models; autoscaling rules tied to AES and tokens/output.
- Assumptions/dependencies: Serving stack supports per-model decoding limits; monitoring for distribution shift after length changes.
- PRM-free RL pipelines for reasoning tasks
- Sector: academia, startups
- What: Replace Process Reward Models with SAS’s token-log-prob confidence proxy to cut training complexity and avoid reward hacking.
- Tools/workflows: Confidence computation from model logits; ablations to confirm nDCG-like alignment with PRMs in the target domain.
- Assumptions/dependencies: Confidence correlates with step quality in the domain (validated in math; should be re-checked elsewhere).
- Budget-constrained RL training for small labs
- Sector: academia
- What: Use short-context (4K) post-training plus SAS for stable compression without scaling infrastructure to long-context RL, enabling cost-effective experiments.
- Tools/workflows: 8 rollouts/prompt GRPO; SAS masking; checkpoint selection via AES on a small validation set.
- Assumptions/dependencies: 17% per-step training time overhead is acceptable; availability of mid-range GPUs and verifier scripts.
- Concise financial/compliance Q&A assistants
- Sector: finance, compliance
- What: Produce determinate answers with minimal extraneous reasoning to reduce review time while preserving correctness.
- Tools/workflows: SAS fine-tuning on labeled Q&A or synthetic rule-check datasets; AES and audit logs tracking token reductions.
- Assumptions/dependencies: Strong verifiers (e.g., rule engines); rigorous evaluation for regulatory use.
- Personal assistants with “just-enough” explanations
- Sector: daily life, consumer apps
- What: Mobile assistants that present only high-confidence, essential steps (recipes, travel planning, budgeting) for faster, clearer interactions.
- Tools/workflows: SAS-tuned models with shorter max output; UX toggles for “concise vs detailed.”
- Assumptions/dependencies: No formal verifier for open-ended tasks—use implicit correctness (e.g., task completion) and careful A/B testing.
- Research reproducibility and evaluation standardization
- Sector: academia, open-source
- What: Adopt AES and entropy monitoring to report accuracy–efficiency trade-offs and exploration stability in reasoning papers.
- Tools/workflows: Logging of entropy, Pass@1, tokens/output; SAS as a baseline for short-context RL studies.
- Assumptions/dependencies: Community agreement on AES or similar composite metrics.
Long-Term Applications
These applications require further research, broader validation, larger models, domain-specific verifiers, or integration with complex systems.
- On-device/edge “slow-think” models for robotics and AR
- Sector: robotics, wearables
- What: SAS-trained compact models that reason efficiently within strict latency/compute budgets for task planning, scene understanding, and instructions.
- Tools/products: Edge-optimized RL fine-tunes; adaptive decoding policies that terminate after high-confidence steps.
- Dependencies: Robust step segmentation for multimodal inputs; embodied task verifiers (sim-to-real).
- Multimodal SAS for vision-language and tool-using agents
- Sector: autonomous agents, industrial automation
- What: Extend step-level advantage selection to multimodal plans and tool-calls, shielding reliable subplans in failed runs and pruning unnecessary tool invocations.
- Tools/products: Planner-verifiers that score partial tool traces; SAS masking across API/tool steps.
- Dependencies: Process verifiers for tool outcomes; standardized step boundaries for tool graphs.
- Domain-certified clinical decision support with concise rationale
- Sector: healthcare
- What: Produce compact, auditable rationales that reduce cognitive load for clinicians while preserving critical decision steps.
- Tools/products: SAS-tuned models with medical verifiers (guideline adherence checks); EHR-integrated “rationale lite.”
- Dependencies: High-quality medical verifiers and guardrails; regulatory validation; careful risk assessment.
- Energy- and carbon-aware AI procurement and governance
- Sector: policy, public sector, sustainability
- What: Use AES and token-per-answer metrics as procurement criteria for “efficient reasoning,” incentivizing models that balance accuracy and compute.
- Tools/products: Policy templates specifying efficiency thresholds; audits that measure reasoning length reduction vs baseline.
- Dependencies: Broad acceptance of composite metrics; standardized evaluation suites for government tasks.
- Distillation of concise reasoning into smaller students
- Sector: model compression, platform engineering
- What: Distill SAS-tuned teachers into smaller models that internalize concise step structures, reducing memory and serving cost further.
- Tools/products: Step-aware KD (knowledge distillation) objectives; teacher-student pipelines that align masked/kept steps.
- Dependencies: Robust transfer of step saliency; generalization beyond math/logic.
- Federated or privacy-preserving efficient reasoning
- Sector: privacy, edge analytics
- What: Federated SAS training to compress reasoning on-device without sharing raw data, lowering communication and compute footprints.
- Tools/products: Federated GRPO variants with step-level masking; on-device verifier proxies.
- Dependencies: Communication-efficient RL; privacy-preserving verifiers; robustness under heterogeneous data.
- Dynamic stopping and adaptive test-time compute controllers
- Sector: serving systems, MLOps
- What: Controllers that terminate generation when remaining steps are low-confidence or redundant, leveraging SAS-learned behavior.
- Tools/products: Confidence-based early stopping; entropy-aware schedulers; per-query compute budgets.
- Dependencies: Reliable per-step confidence calibration; safeguards against premature stopping on hard cases.
- Process-level RLHF that fixes credit assignment
- Sector: RLHF/RLAIF research
- What: Combine preference models with SAS-style masking to avoid penalizing good partial solutions, improving sample efficiency and stability.
- Tools/products: Hybrid advantage selection using preferences + verifier signals; replay buffers tagged with step confidence.
- Dependencies: Preference data at step granularity; theoretical convergence analysis.
- Sector-specific verifiers and step parsers
- Sector: finance, law, engineering
- What: Domain verifiers that can score partial reasoning (e.g., governance rules, engineering constraints), enabling SAS in domains beyond math.
- Tools/products: Open verifier libraries; step segmentation tuned to domain documents (contracts, schematics).
- Dependencies: Annotation and standardization costs; agreement on step semantics and failure modes.
- Curriculum learning for efficient reasoning under constraints
- Sector: education technology, training efficiency
- What: Start with longer contexts and progressively shorten during SAS training to maintain stability while increasing compression.
- Tools/products: Iterative context-length schedules; adaptive r (masking ratio) schedules.
- Dependencies: Robust curricula across tasks; safeguards against late-stage over-compression.
- Safety and reliability analytics for compressed reasoning
- Sector: safety, assurance
- What: Analyze whether shorter reasoning omits safety-critical caveats; develop metrics that detect harmful compression.
- Tools/products: Safety verifiers for partial rationales; dashboards correlating length cuts with error types.
- Dependencies: Domain-specific safety taxonomies; human-in-the-loop audits.
- Marketplace and SDKs for “Efficient Reasoning Tuning”
- Sector: AI tooling
- What: Turn SAS into SDKs/plugins for TRL/VeRL with configurable step delimiters, masking ratios, and AES/entropy monitors.
- Tools/products: One-click “SAS fine-tune” on popular model hubs; evaluation harnesses for AES-by-domain.
- Dependencies: Maintenance for diverse tokenizers and languages; community benchmarks to certify gains.
Notes on feasibility across applications
- SAS requires: short-context RL (e.g., 4K) with GRPO/PPO, access to logits for confidence scores, and verifiers for outcome correctness (or suitable proxies).
- Step segmentation: “\n\n” works well for math-style CoT; domains like code, law, or multimodal plans need custom parsers.
- Training cost: ~17% per-step overhead vs GRPO due to masking/segmentation; no extra model passes or PRMs.
- Generalization: Results reported on math and general reasoning (GPQA/LSAT/MMLU) with a 1.5B base model; behavior with larger models, multilingual data, and other domains should be validated before mission-critical deployment.
Glossary
- Accuracy–Efficiency Score (AES): A metric that combines accuracy and output length to quantify the trade-off between performance and computational cost. Example: "AccuracyâEfficiency Score (AES, see details in \cref{app:aes}; \citealp{luo2025opruner})"
- accuracy–efficiency trade-off: The balance between maintaining task accuracy and reducing computational overhead or reasoning length. Example: "yielding a better accuracyâefficiency trade-off."
- chain-of-thought (CoT): An explicit, step-by-step textual reasoning process generated by a model to solve a problem. Example: "generate longer chain-of-thought traces"
- clipped surrogate (PPO-style): The clipped objective in Proximal Policy Optimization that stabilizes policy updates by limiting the size of changes. Example: "PPO-style clipped surrogate"
- credit assignment (rollout-level): The process of attributing rewards to parts of a generated trajectory, applied at the whole-rollout level. Example: "how the short context window interacts with rollout-level credit assignment"
- entropy collapse: A rapid decline in the policy’s entropy, indicating reduced exploration and diversity in generated outputs. Example: "rapid entropy collapse"
- Group Relative Policy Optimization (GRPO): An RL algorithm that computes advantages relative to other samples within a group of responses and optimizes the policy accordingly. Example: "Group Relative Policy Optimization (GRPO; \citealp{shao2024deepseekmath})"
- group-relative advantage normalization: Normalizing rewards within a sampled group so that advantages are relative, not absolute. Example: "Under GRPO's group-relative advantage normalization"
- KL penalty: A regularization term using Kullback–Leibler divergence to penalize deviation from a reference policy during RL fine-tuning. Example: "regularized by a KL penalty against a fixed reference policy"
- length-aware rewards: Reward functions that penalize longer outputs to encourage concise reasoning. Example: "length-aware rewards"
- nDCG@k: Normalized Discounted Cumulative Gain at cutoff k, a ranking metric that evaluates the quality of ordered lists. Example: "using nDCG@k."
- Pass@1: The probability that the first (top) generated response is correct, often averaged across multiple samples to reduce variance. Example: "we report "
- policy drift: Undesired and gradual deviation of the learned policy due to noisy or misaligned updates. Example: "exacerbate policy drift during training."
- policy entropy: The entropy of the model’s token distribution, reflecting exploration vs. exploitation during generation. Example: "Policy entropy throughout training."
- Process Reward Model (PRM): A model that scores intermediate reasoning steps (process) rather than only final outcomes. Example: "Process Reward Model, Qwen2.5-Math-PRM-7B"
- pruning mechanisms: Techniques that remove redundant tokens or steps from reasoning traces to shorten them while preserving correctness. Example: "pruning mechanisms"
- rollout: A single sampled trajectory or generated response from the current policy for a given prompt. Example: "samples a group of rollouts"
- rule-based verifier: A deterministic checking system that validates whether a generated solution is correct based on rules. Example: "the same rule-based verifier."
- short-context post-training: Post-training conducted with a shorter context window than that used in base model training, often inducing output compression. Example: "short-context post-training"
- Step-level Advantage Selection (SAS): The proposed method that assigns zero advantage to selected reasoning steps to stabilize training and compress reasoning. Example: "Step-level Advantage Selection (SAS)"
- step-level confidence score: A confidence measure for a reasoning step, often computed as the mean token log-probabilities within that step. Example: "compute a step-level confidence score"
- test-time scaling: Improving performance by allocating more computation during inference, such as generating longer traces or more samples. Example: "test-time scaling"
- token-budget constraints: Explicit limits on the number of tokens a model is allowed to generate during training or inference. Example: "token-budget constraints"
- token-level log probabilities: The per-token log-likelihoods output by the model, used here as a proxy for step confidence. Example: "token-level log probabilities"
- top-p: A nucleus sampling parameter that restricts sampling to a subset of tokens with cumulative probability mass p. Example: "a top-p of 0.95"
- truncation: Cutting off a generated sequence due to context window limits or maximum length, potentially losing crucial final steps. Example: "truncation under short context"
- verifier-failed rollouts: Generated responses labeled incorrect by the verifier, which may still contain useful intermediate reasoning. Example: "verifier-failed rollouts"
- zero advantage: Setting the advantage to zero for certain tokens or steps so they do not influence the gradient update. Example: "assigns a zero advantage"
Collections
Sign up for free to add this paper to one or more collections.

