Mitigating Overthinking through Reasoning Shaping
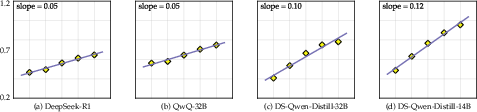
Abstract: Large reasoning models (LRMs) boosted by Reinforcement Learning from Verifier Reward (RLVR) have shown great power in problem solving, yet they often cause overthinking: excessive, meandering reasoning that inflates computational cost. Prior designs of penalization in RLVR manage to reduce token consumption while often harming model performance, which arises from the oversimplicity of token-level supervision. In this paper, we argue that the granularity of supervision plays a crucial role in balancing efficiency and accuracy, and propose Group Relative Segment Penalization (GRSP), a step-level method to regularize reasoning. Since preliminary analyses show that reasoning segments are strongly correlated with token consumption and model performance, we design a length-aware weighting mechanism across segment clusters. Extensive experiments demonstrate that GRSP achieves superior token efficiency without heavily compromising accuracy, especially the advantages with harder problems. Moreover, GRSP stabilizes RL training and scales effectively across model sizes.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Mitigating Overthinking through Reasoning Shaping — Explained Simply
What is this paper about?
This paper looks at a problem with “thinking” AI models (the kind that explain their steps before answering). These models sometimes overthink—they write long, wandering explanations that waste time and computer power. The authors propose a smarter way to guide the model so it thinks just enough, not too much, without hurting accuracy.
What questions are the researchers trying to answer?
They mainly explore:
- How can we stop AI models from rambling without making them less correct?
- Is there a better way to control the length of the model’s thinking than counting every single token (word/character)?
- Can we guide the model at the level of “steps” (like the lines in a math solution) instead of individual tokens?
- Can we make training more stable so the model doesn’t collapse or get worse when we try to shorten its answers?
How did they try to solve it?
Think of the model’s explanation like a student solving a problem on paper:
- Tokens = letters and symbols
- Segments (steps) = a full sentence or line of reasoning
Past methods penalized the total number of tokens. That’s like telling a student, “Write fewer letters.” It saves space but can break sentences and mess up reasoning.
The authors propose GRSP (Group Relative Segment Penalization), which is like saying, “Use fewer unnecessary steps,” not “use fewer letters.” Here’s how it works in everyday terms:
- The model produces several trial answers for the same question.
- Each answer is broken into reasoning steps (segments). This segmentation is done either by:
- Keyword cues (like “Step 1,” “Therefore,” “Compute,” etc.), or
- Confidence dips (finding low-confidence moments where new steps usually begin; this uses the model’s token probabilities to detect step boundaries).
- The method compares how many steps each answer uses relative to the other answers in the same group (this is the “group relative” part). If your answer uses way more steps than your peers, you get a small penalty.
- Steps are grouped by length (short, medium, long). The system penalizes too many short steps more than long ones, because the authors found short, choppy steps happen more in wrong answers. This “length-aware” weighting helps keep accuracy strong while still reducing rambling.
Two key ideas keep things stable and effective:
- Compare within the group: The difficulty of the question is roughly the same for all attempts, so comparing “how many steps you used” to your peers is fair and adaptive.
- Penalize shorter segments more: Short bursts of tiny steps often signal shallow or scattered thinking. Encouraging fewer, more substantial steps makes reasoning both clearer and shorter overall.
What did they find?
The authors tested their approach on tough math problems (like MATH 500, AIMO Prize, and Omni-MATH 500) and across different training algorithms (REINFORCE and GRPO) and model sizes. Their main findings:
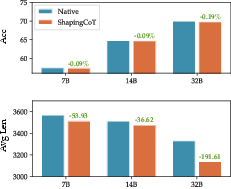
- GRSP reduces the amount of text (token count) without hurting accuracy—and often keeps accuracy as good as or better than other methods.
- It works especially well on hard problems, where models are more likely to overthink.
- It stabilizes training. A common issue with simple length penalties is that training can “collapse” (accuracy falls). GRSP avoids that.
- Bigger models are naturally more efficient, and GRSP helps all sizes be more concise.
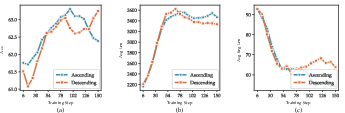
- Penalizing short steps more than long steps (weights that go down for longer segments) leads to better stability and efficiency than the reverse.
- Both segmentation methods (keyword-based and confidence-based) work, with confidence-based sometimes doing slightly better without relying on language-specific keywords.
Why does this matter?
- It makes reasoning models faster and cheaper to run by cutting unnecessary text without cutting correctness.
- It makes training more reliable: you can push the model to be concise without breaking its ability to solve problems.
- It provides a simple, practical tool you can “plug into” existing reinforcement learning setups for reasoning models.
What’s the bigger impact?
If AI can think clearly in fewer steps, it:
- Saves compute and money (important for big, real-world systems).
- Is more eco-friendly (less energy usage).
- Can be applied to many reasoning tasks (math, science, coding) where long, messy explanations are common.
- Encourages future research to guide models at the right “level” (steps, not raw tokens), which aligns better with how humans think and explain.
In short: GRSP teaches AI to write fewer, better reasoning steps—like a good math student—so it stays accurate while being faster and more efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that the paper leaves open for future research:
- Generalization beyond math: Validate GRSP on diverse reasoning domains (code generation, multi-hop QA, commonsense reasoning, planning) to test whether segment-level shaping transfers across task types and modalities.
- Cross-language robustness: Assess keyword-based segmentation in non-English languages and scripts; quantify performance deltas and develop language-agnostic or multilingual segmentation strategies.
- Segmentation accuracy and reliability: Measure precision/recall of segmentation boundaries (both keyword-based and logprob-based) against human-annotated steps; analyze how segmentation errors propagate into GRSP’s penalties and downstream performance.
- Hyperparameter sensitivity: Systematically ablate cluster count (e.g., K from 3 to 10), segment-length bin edges, logprob thresholds/smoothing windows, and penalty coefficient ; publish sensitivity curves and recommended ranges.
- Learned or adaptive weighting: Explore learned weighting functions (e.g., exponential, convex/concave, meta-learned, task-adaptive, curriculum-based, or difficulty-aware schedules) instead of fixed linear descending weights.
- Theoretical justification: Provide formal analysis on why shaping segment-length distributions stabilizes RLVR (e.g., variance reduction, bias in policy gradients, constrained optimization perspective); connect to credit assignment and PPO/GRPO clipping dynamics.
- Causality vs. correlation: Design controlled experiments to test whether shifting segment-length distributions causes stability/accuracy gains, rather than merely correlating with model strength (e.g., intervene on segment distributions while holding other factors fixed).
- Exploration–efficiency trade-off: Quantify how segment-count penalties affect exploration (trajectory diversity, self-consistency gains); measure whether GRSP overly prunes exploratory steps on hard problems.
- Robustness to rollout group size: Study sensitivity to the number of rollouts per prompt (e.g., 1, 5, 10, 50) since group-relative z-scores depend on intra-group statistics; characterize failure modes with small/large groups.
- Single-sample training: Extend GRSP to settings without group rollouts (e.g., single-sample RL or on-policy streaming) and propose alternative normalization schemes that do not require group statistics.
- Evasion and gaming behavior: Investigate whether models learn to “pack” more content into longer segments to avoid penalties, obfuscate step boundaries, or otherwise game the segmentation mechanism.
- Extremely long segments (>300 tokens): The paper excludes >300-token segments; evaluate their prevalence, dynamics, and whether the exclusion introduces bias or incentivizes pathological segment growth.
- Interaction with reward sparsity: Test GRSP under richer (non-binary, continuous, step-level) verifiers and non-verifiable tasks; study how penalties interact with sparse rewards and whether step-level verifiers reduce instability.
- Training stability quantification: Move beyond qualitative trends; report stability metrics (loss variance, gradient norms, KL/divergence to old policy, clipping ratio, entropy, catastrophic collapse frequency) to substantiate stability claims.
- Temperature effects: Analyze how sampling temperatures (train T=1.0 vs. eval T=0.6) affect segment distributions, penalties, and accuracy/efficiency; propose temperature schedules compatible with GRSP.
- Compute and wall-clock savings: Translate token reductions into real compute/latency/energy savings; report throughput changes and end-to-end cost-benefit (including segmentation overhead).
- Scalability to larger models: Evaluate GRSP on 70B+ and 100B+ models or in production-scale RLVR (e.g., 671B) to test scaling behavior and ensure no unforeseen degradation at frontier capacities.
- Integration with tree-of-thought/MCTS: Study whether GRSP synergizes or conflicts with tree-based prompting or search-based test-time scaling; propose segment-aware pruning policies for trees.
- Combination with other efficiency methods: Benchmark GRSP alongside or combined with speculative decoding, step-adaptive sampling, token-budget prompts, and pruning baselines in a unified protocol.
- Difficulty-aware shaping: Develop mechanisms to detect problem difficulty at inference and adjust segment penalties adaptively so hard problems are not over-pruned.
- SFT pattern dependence: Systematically analyze how different warm-up (SFT) formats (e.g., DeepSeek-R1-style vs. O1-mini-style) influence overthinking and GRSP effectiveness; derive guidelines for SFT data construction.
- Evaluation breadth: Add metrics beyond accuracy and average length (e.g., per-step correctness, solution readability/structure, reflection loops, calibration, error typology) to better capture reasoning quality under GRSP.
- Fairness and reproducibility: Provide code, seeds, and detailed configs; ensure baselines are matched on prompts, lengths, and hyperparameters to avoid confounding in comparisons.
- Penalty scheduling: Investigate annealing or curriculum schedules for and weights across training; test whether early weak penalties and later stronger shaping improve stability.
- Constraint-based formulation: Frame length control as a constrained RL objective (e.g., Lagrangian methods) and compare to GRSP’s reward shaping approach on both stability and optimality.
- On-policy vs. off-policy effects: Examine GRSP under off-policy RLVR or replay buffers; assess whether group-relative penalties remain meaningful with stale distributions.
- Hardness-stratified analysis: Provide fine-grained results across difficulty bins (within Omni-MATH and AIME) to characterize where GRSP helps or harms most strongly.
- Safety and hallucinations: Evaluate whether length penalties encourage shortcutting or brittle reasoning on non-verifiable tasks; include safety, robustness, and hallucination analyses.
- Segment-quality annotation: Create a small, labeled dataset of reasoning segments (useful vs. redundant/misleading) to benchmark segmentation and correlate penalties with human judgments.
- Adaptive segmentation: Investigate dynamic boundary detection (e.g., confidence change-point detection, learned boundary predictors) and compare to static keyword/logprob heuristics.
Practical Applications
Practical Applications of “Mitigating Overthinking through Reasoning Shaping”
The paper introduces Group Relative Segment Penalization (GRSP), a step-level reinforcement learning method for reasoning models that reduces overthinking (unnecessary tokens) while preserving accuracy and stabilizing RLVR training. Below are actionable applications, organized by deployment horizon, sector relevance, and feasibility notes.
Immediate Applications
These can be deployed now by teams operating or fine-tuning reasoning models with verifiable rewards (RLVR) and access to training pipelines.
- Cost and latency reduction for reasoning-heavy LLM services
- Sectors: software, finance, education, enterprise AI platforms, cloud AI providers
- Use cases:
- Code assistants trained with unit-test verifiers (compile/run/pass) to maintain accuracy with fewer tokens and faster responses.
- SQL/query generation with execution-based verifiers to minimize verbose reasoning while preserving correctness.
- Math solvers and tutoring systems with exact-answer verifiers (symbolic checks, evaluators) to deliver concise solutions and lower inference costs.
- Rule-based data transformation/ETL agents (data quality checks) where outputs are verifiable deterministically.
- Tools/workflows:
- “GRSP Trainer” module integrated into RL pipelines (Reinforce/GRPO) and open-source RL frameworks (e.g., DAPO/TRl-like).
- Confidence-based segmentation drop-in (log-prob minima) to avoid language-specific keyword lists.
- “Concise-R” model variants marketed as lower-CoT-cost reasoning models.
- Assumptions/dependencies:
- Availability of deterministic verifiers for target tasks.
- Access to RLVR training infrastructure and base models; licensing compatibility.
- Domain shift from math/code to target workload requires minimal adaptation of segmenters and weights.
- Training stability and monitoring for RLVR pipelines
- Sectors: AI research labs, model providers
- Use cases:
- Use GRSP’s length-aware, segment-cluster weights to prevent training collapse and reduce degenerate short-step proliferation.
- Introduce “segment-distribution drift” dashboards to detect overthinking (segments-per-answer, cluster ratios) during training/evaluation.
- Tools/workflows:
- “SegmentScope” monitoring panel (KPIs: avg segments, cluster-wise z-scores, tokens-per-correct, segments-per-correct).
- Assumptions/dependencies:
- Logging token logprobs or boundary features at training/inference time.
- Minor engineering to compute z-score penalties per group rollouts.
- Inference-time “reasoning budget” controllers without retraining
- Sectors: software, education, enterprise assistants
- Use cases:
- Apply confidence-based segmentation online to detect step boundaries and stop early when segment count exceeds a budget or convergence signals appear.
- Auto-switch to terse mode on hard queries to bound costs while preserving answer accuracy via verifier-guided re-tries.
- Tools/workflows:
- “Budgeted Reasoning Controller” that sets max segments, adapts temperature, or prunes branches after boundary detection.
- Assumptions/dependencies:
- Accepting small accuracy trade-offs if using purely inference-time control without GRSP retraining.
- Access to token-level logprobs during decoding.
- Energy and cost reporting improvements (“Green Reasoning” KPIs)
- Sectors: cloud providers, enterprise AI governance, sustainability officers
- Use cases:
- Add tokens-per-correct and segments-per-correct to cost and carbon dashboards to quantify and benchmark reasoning efficiency.
- Tools/workflows:
- “Reasoning Efficiency Scorecard” used in procurement/SLAs for model selection.
- Assumptions/dependencies:
- Standardized logging and simple verifier metrics for the target tasks.
- Education: concise, step-aware math tutoring and assessment
- Sectors: education technology
- Use cases:
- Train math tutors with GRSP to produce fewer, clearer steps; improve readability and reduce latency on large problem sets.
- Automated grading where reasoning is required but should remain coherent and succinct.
- Tools/workflows:
- Tutor fine-tuning with NuminaMATH-like data; apply GRSP with keyword or confidence-based segmentation.
- Assumptions/dependencies:
- Verifiers (exact answers, numeric/symbolic evaluation) are already standard for math tasks.
- Finance and compliance analysis with verifiable checks
- Sectors: finance, legal/compliance tooling
- Use cases:
- Policy/rule conformance assistants that output compact reasoning where checks (e.g., rule matches, threshold tests) are deterministic.
- LLM-based analytics that keep rationales concise for audit trails.
- Tools/workflows:
- Integrate GRSP into RL tuned on synthetic or historical labeled checks; deploy concise reasoning variants in reporting pipelines.
- Assumptions/dependencies:
- Robust rule engines/verifiers and careful scoping to deterministic sub-tasks; human-in-the-loop for edge cases.
- Software CI/CD integration
- Sectors: software engineering
- Use cases:
- Model-planning agents that rely on tests/linters as verifiers; GRSP reduces chain-of-thought verbosity and speeds CI loops.
- Tools/workflows:
- CI-in-the-loop RLVR training where failing tests provide negative reward and GRSP shapes reasoning steps.
- Assumptions/dependencies:
- High-quality unit/integration tests; access to compute for RL fine-tuning.
Long-Term Applications
These require further R&D, robust verifiers, broader validation beyond math/code, or scaling to safety-critical settings.
- Healthcare clinical decision support with concise, auditable reasoning
- Sectors: healthcare
- Use cases:
- Train models that produce minimal yet sufficient reasoning trails aligned with clinical guidelines and verifiable checklists.
- Tools/products:
- “Guideline Verifier” modules as RLVR rewards; GRSP to shape reasoning segments for clarity and brevity in EHR notes.
- Assumptions/dependencies:
- High-stakes validation, bias and safety audits, regulatory compliance (HIPAA, MDR, FDA).
- Trusted verifiers for complex medical reasoning are non-trivial to build.
- Robotics and long-horizon planning agents
- Sectors: robotics, autonomous systems, logistics
- Use cases:
- Use segment-shaped planning (fewer steps, longer coherent segments) to reduce meandering in action plans while preserving success rates.
- Tools/workflows:
- Simulator-based verifiers for task completion; GRSP integrated into RLHF/RLVR for multi-step planning.
- Assumptions/dependencies:
- High-fidelity simulators and reliable task success verifiers; sim-to-real transfer.
- Multimodal reasoning efficiency (vision-language, charts, geospatial)
- Sectors: healthcare imaging, manufacturing QA, autonomous driving, business intelligence
- Use cases:
- Apply GRSP to VLMs with deterministic verifiers (e.g., OCR validation, unit conversions, structured answers) to cut reasoning tokens in image+text tasks.
- Tools/workflows:
- Confidence-based segmentation generalized to multimodal token streams; cluster-wise penalties for mixed modalities.
- Assumptions/dependencies:
- Strong multimodal verifiers; adaptation of segmentation heuristics to non-text tokens.
- General-purpose assistants with “reasoning shaping controls”
- Sectors: consumer and enterprise assistants
- Use cases:
- Expose API controls (e.g., segment-weight profiles) to tune verbosity vs. accuracy per user, task, or cost budget.
- Tools/products:
- “Reasoning Shaping API” that toggles weights per segment cluster; profiles like concise, balanced, exploratory.
- Assumptions/dependencies:
- Widespread RLVR adoption with scalable verifiers; safe defaults for open-ended tasks (where verifiers are weak or subjective).
- Edge/on-device reasoning models
- Sectors: mobile, IoT, embedded systems
- Use cases:
- GRSP-trained models distilled for on-device inference to retain accuracy with shorter traces and lower energy.
- Tools/workflows:
- Distillation pipelines preserving segment-level behavior; quantization/pruning aligned with segment shaping.
- Assumptions/dependencies:
- Efficient base models; high-quality on-device verifiers or offline RL pretraining.
- Public-sector policy and procurement standards for efficient reasoning
- Sectors: government, regulators, sustainability
- Use cases:
- Establish “efficiency per correctness” standards (tokens-per-correct, segments-per-correct) in RFPs and model audits to encourage green AI.
- Tools/workflows:
- Benchmarks and reporting templates for reasoning efficiency; certification programs tied to carbon disclosures.
- Assumptions/dependencies:
- Industry consensus on metrics; third-party evaluation infrastructure.
- Auto-verifier generation to unlock GRSP in subjective/complex domains
- Sectors: media, knowledge management, law
- Use cases:
- Programmatically synthesize verifiers (unit tests, rule extractors, data constraints) to make more tasks RLVR-compatible and benefit from GRSP.
- Tools/workflows:
- “VerifierOps” toolchains to author, test, and maintain verifiers; weak-to-strong verifier bootstrapping.
- Assumptions/dependencies:
- Reliability of automatic verifiers; human oversight pipelines; handling ambiguity and partial credit.
- Unified step-level credit assignment frameworks
- Sectors: AI research and model tooling
- Use cases:
- Generalize GRSP with group sequence policy optimization and other PPO variants; standardized step-level penalties and diagnostics.
- Tools/workflows:
- Open libraries implementing segment-based z-score penalties, cluster weighting, and stability monitors.
- Assumptions/dependencies:
- Community adoption, benchmarks beyond math/code, and comparative studies vs. token-level baselines.
Cross-cutting assumptions and risks
- Verifier availability and quality is the key enabler; benefits are largest where correctness is deterministically checkable (math, code, structured analytics).
- Results are demonstrated on math reasoning; generalization to less-structured tasks (creative writing, open QA) needs validation and careful choice of verifiers (LLM-as-judge introduces noise/bias).
- Compute access for RLVR fine-tuning is required; small teams may prefer inference-time controllers as a stopgap.
- Segment boundary detection must be reliable; keyword segmentation may be language-dependent, while confidence-based segmentation requires logprob access and calibration.
- In safety-critical domains, rigorous evaluation, auditing, and governance are prerequisites before deployment.
Glossary
- Advantage: In policy-gradient RL, a baseline-adjusted estimate of how much better an action (or sequence) is than expected; used to weight gradients. "It also replaces the token-level advantage with a sequence-level score "
- Chain-of-Thoughts: A prompting technique where models generate intermediate reasoning steps before the final answer. "Unlike conventional Chain-of-Thoughts~\cite{wei2022chain}, such trajectories often involve exploration and self-reflection over multiple possible solution paths"
- Clip operator: The clipping function in PPO that limits policy update magnitude to stabilize training. "and a clip operator inherited from PPO~\cite{schulman2017proximal}"
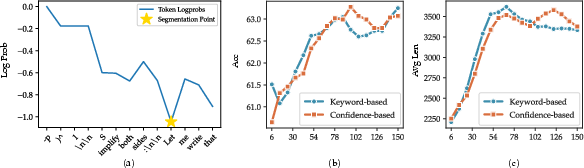
- Confidence-based segmentation: A method to split reasoning into steps by locating low-confidence (low log-probability) positions. "We conduct experiments using the confidence-based segmentation under the Reinforce+GRSP framework on Qwen-2.5-14B, and compare it with the proposed keyword-based segmentation"
- Deterministic verifier: A non-stochastic checker that provides a correctness signal (reward) for a generated answer. "where is the policy and is the accuracy signal obtained from a deterministic verifier"
- Dynamic sampling: A training scheme where the effective batch size varies due to on-the-fly sampling. "Dynamic sampling~\cite{yu2025dapo} is applied, so the actual batch size varies across iterations"
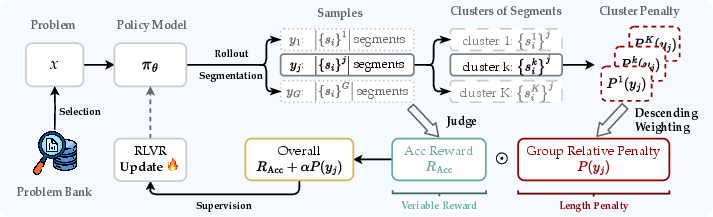
- Group Relative Segment Penalization (GRSP): The paper’s method that penalizes reasoning at the segment level with length-aware weights to reduce overthinking while preserving accuracy. "In this work, we introduce Group Relative Segment Penalization~(GRSP), a novel method that balances computational efficiency and task performance by operating at the reasoning-step granularity"
- GRPO: An RL algorithm related to PPO that introduces group-wise objectives and clipping; here, it adds an importance-sampling ratio and sequence-level scoring. "and GRPO~\cite{shao2024deepseekmath}, which adds an importance-sampling ratio"
- Importance-sampling ratio: The ratio between new and old policy probabilities used to correct sampling bias in off-policy updates. "which adds an importance-sampling ratio"
- Keyword-based matching: Heuristic segmentation by detecting predefined keywords that indicate step boundaries. "The first is keyword-based matching, similar to \citet{guo2025segment}"
- LCPO: A baseline method that weights rewards by the ratio of generated length to a reference length to encourage brevity. "LCPO~\cite{aggarwal2025l1} uses the ratio between the generated response length and the reference one as a weighting factor for the verifiable reward"
- Length-aware weighting: Assigning different penalties to segments based on their lengths, typically penalizing shorter segments more. "we design a length-aware weighting mechanism across segment clusters"
- Monte Carlo Tree Search: A search algorithm that explores decision trees via stochastic sampling, used for reasoning and planning. "One line of such work is Monte Carlo Tree Search or tree-structured prompting~\cite{wu2024inference, yao2023tree}"
- O1-Pruner: A baseline approach that adds a length-related auxiliary reward to prune excessive reasoning. "O1-Pruner~\cite{luo2025o1} computes a ratio factor similar to LCPO, while adding it as an auxiliary reward term to the verifiable reward"
- Policy: The probability distribution over next tokens (actions) conditioned on context; in LLMs, the model’s generative distribution. "where is the policy and is the accuracy signal obtained from a deterministic verifier"
- Proximal Policy Optimization (PPO): A policy-gradient RL method using clipped objectives for stable updates. "inherited from PPO~\cite{schulman2017proximal}"
- Reinforce: A classic policy-gradient algorithm using Monte Carlo returns to update the policy. "Prevalent algorithms include Reinforce"
- Reinforcement Learning from Verifier Reward (RLVR): RL framework where a verifier provides correctness-based rewards to train reasoning models. "Large reasoning models~(LRMs) boosted by Reinforcement Learning from Verifier Reward~(RLVR) have shown great power in problem solving"
- Reasoning Shaping: Guiding the structure of reasoning (e.g., segment length distribution) via penalties to stabilize training and improve efficiency. "we propose stabilizing RL training by explicitly shaping the distribution of segments through segment-level penalties, which we term Reasoning Shaping"
- Rollout: Generating trajectories (model outputs) from the current policy to compute rewards and updates. "Each RL training run consists of 150 steps, with a rollout performed every 3 steps"
- Segment clusters: Groups of reasoning segments bucketed by length for differential penalization. "we design a length-aware weighting mechanism across segment clusters"
- Segment-count penalty: A penalty proportional to the number of reasoning segments to discourage unnecessary steps. "we first introduce the core segment-count penalty"
- Sequence-level score: A single advantage-like score computed for an entire output sequence rather than per token. "It also replaces the token-level advantage with a sequence-level score "
- Supervised fine-tuning (SFT): Post-training the base model on curated input-output pairs before RL. "The training pipeline consists of two post-training stages: supervised fine-tuning (SFT) followed by RLVR"
- Test-time Scaling: Improving performance by spending more compute during inference (e.g., more samples/steps). "Test-time Scaling with RLVR has greatly accelerated the development and adoption of Large Reasoning Models (LRMs)"
- Token log-probabilities: The model’s logarithmic probabilities for each generated token, reflecting confidence. "segment boundaries often correspond to local minima in token log-probabilities"
- Verifiable reward: A correctness-based signal (often binary) produced by a verifier to evaluate outputs. "as a weighting factor for the verifiable reward"
- Z-score normalization: Standardizing counts by subtracting the mean and dividing by the standard deviation to compute relative penalties. "we compute a relative penalty using a z-score normalization:"
Collections
Sign up for free to add this paper to one or more collections.