- The paper shows that naturalness-based data selection in LLMs inadvertently favors longer reasoning steps by diluting low-probability first tokens.
- It introduces two debiasing methods, Aslec-drop and Aslec-casl, which improve selection accuracy with performance gains of up to 9.08%.
- The study’s causal regression analysis reveals systematic biases in token probabilities, prompting a re-design of data selection pipelines for robust LLM fine-tuning.
Step Length Confounding in LLM Reasoning Data Selection
Motivation and Problem Statement
The paper "On the Step Length Confounding in LLM Reasoning Data Selection" (2604.06834) rigorously investigates the efficacy and unintended bias of naturalness-based data selection methods in constructing supervised fine-tuning (SFT) datasets for LLMs targeting complex chain-of-thought (CoT) reasoning tasks. Existing SFT pipelines typically rely on LLM-generated multi-step solutions filtered by naturalness heuristics—commonly based on average log probability or perplexity—to select high-quality samples. The central claim is that these methods consistently exhibit a step length confounding effect, preferentially selecting samples with longer reasoning steps rather than those of genuinely higher quality. The mechanism underlying this bias is traced to the disproportionate influence of the low-probability first token in each step: longer steps dilute this effect, artificially inflating the mean log probability and skewing selection criteria.
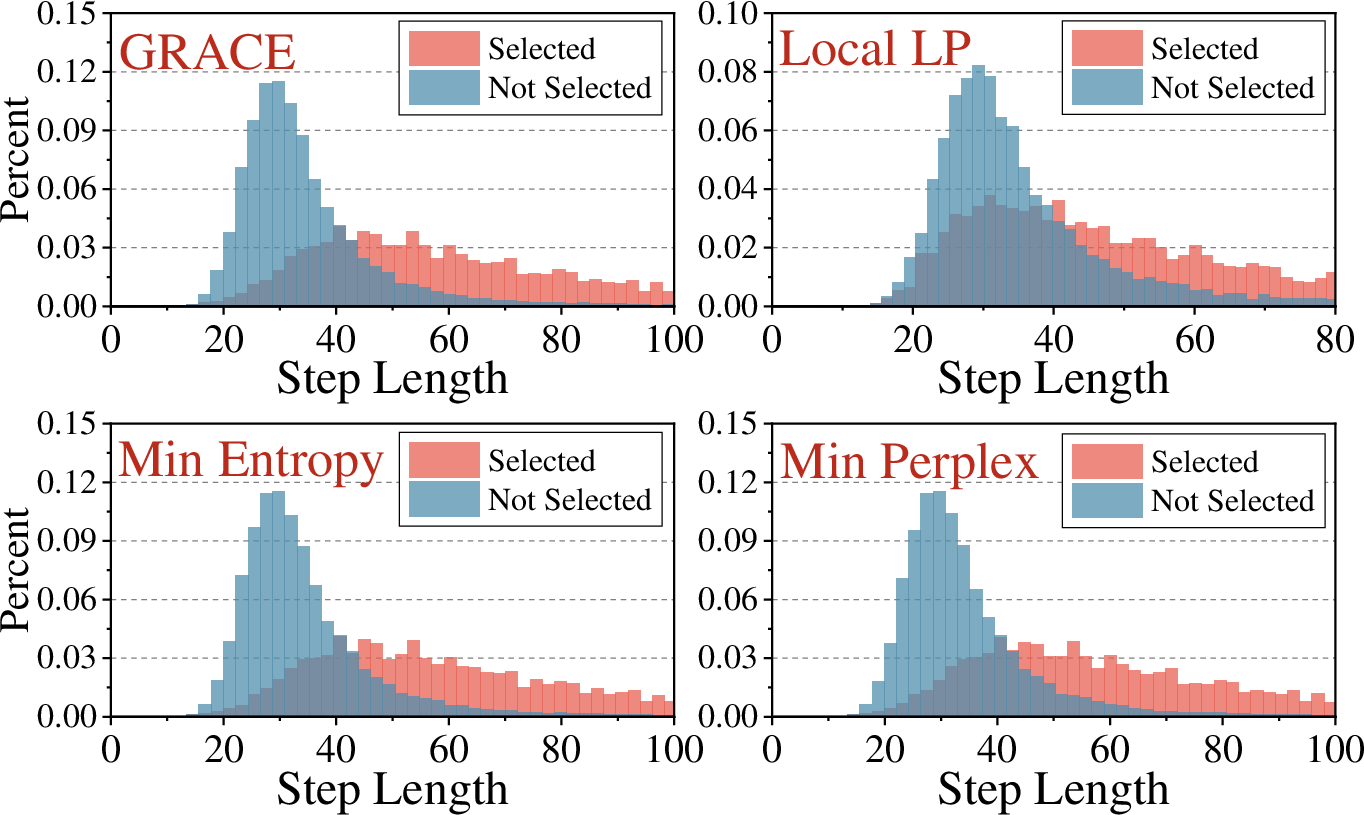
Figure 1: Step length distribution of data samples selected and unselected by different naturalness-based data selection methods.
The phenomenon is robust across diverse datasets, teacher LLMs, and evaluation targets. Figure 1 demonstrates the systematic drift in step length distributions induced by naturalness-based selection, signifying the confounding effect.
Empirical Analysis of Step Length Confounding
The paper employs both qualitative and quantitative analyses to dissect the origins of step length confounding. The relationship between step-level log probability and step length is shown to be monotonically increasing, in accordance with the hypothesis that longer steps are selected due to their diluted low-probability first tokens.
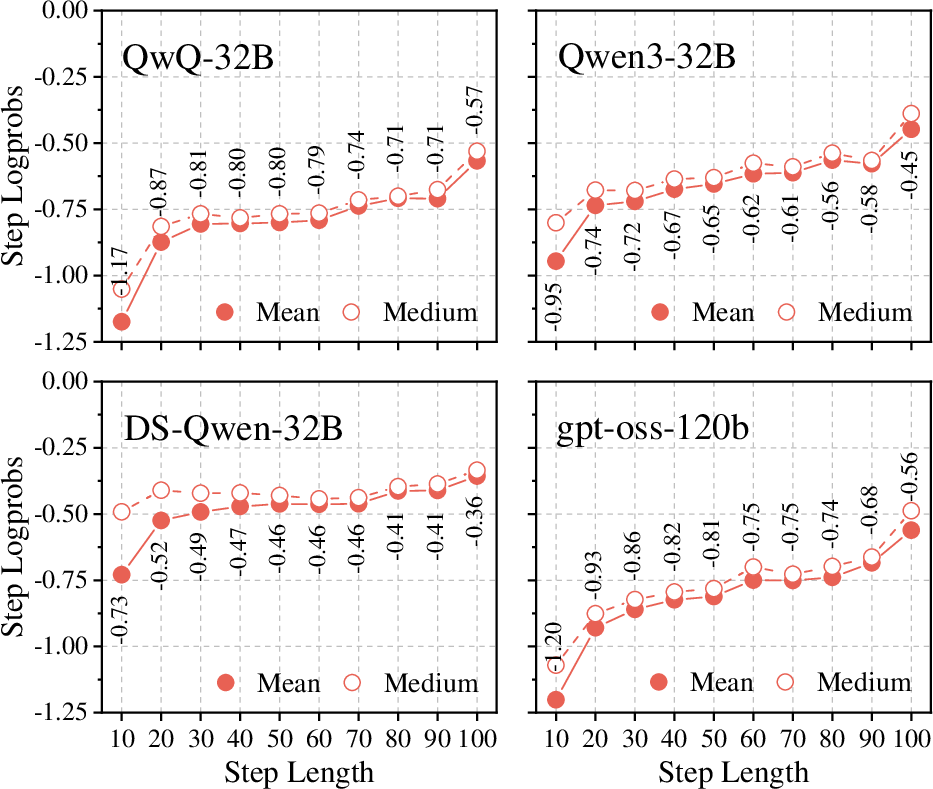
Figure 2: Relationship between step-level log probability and step length.
This is further corroborated with token-level examination (Figure 3), revealing that the first token in each reasoning step consistently exhibits low log probability, stemming from branching into new reasoning pathways and increased entropy.

Figure 3: Representative cases illustrating token-level log probabilities for varying step lengths.
The empirical conclusions are bold: naturalness-based data selection methods do not inherently select higher-quality or more adaptable reasoning samples, but are structurally biased toward verbosity at the step level due to their scoring methodology.
Methodological Contributions: Aslec-drop and Aslec-casl
To counteract step length confounding, the authors propose two mitigations:
- Aslec-drop: Drops the first token in each reasoning step when computing the average log probability, directly excluding the confounding variable.
- Aslec-casl: Applies causal debiasing via linear regression. The average log probability is decomposed as a function of first-token probability, non-first-token probability, and first-token ratio. The confounding effect (γ) associated with the first-token ratio is estimated and subtracted, yielding a debiased metric for data selection.
Both methods are computationally efficient: Aslec-drop incurs no overhead relative to vanilla naturalness metrics; Aslec-casl requires only a small-scale regression fitting.
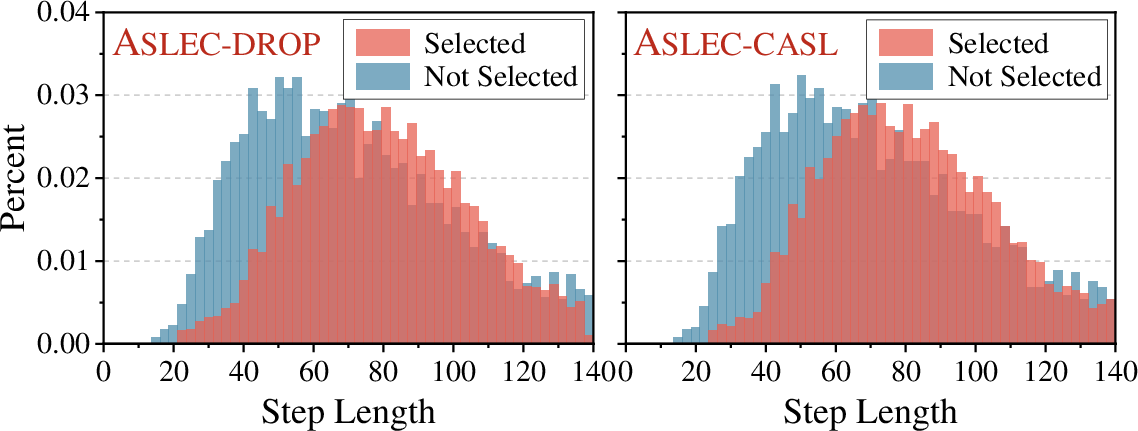
Figure 4: Step length distributions for data selected versus unselected by our two proposed variant methods.
Figure 4 confirms that both approaches substantially reduce step length disparities between selected and unselected samples, indicating successful mitigation of the confounding effect.
Comparative Evaluation and Numerical Results
The methods are assessed across four source LLMs (QwQ-32B, Qwen3-32B, DeepSeek-R1-Distill-Qwen-32B, gpt-oss-120b) and two SFT datasets (LIMO-v2, AceReason-1.1-SFT), spanning five evaluation benchmarks (AIME24, AIME25, MATH500, OlympicBench, GPQA). Strong numerical results are observed:
- Aslec-drop achieves average accuracy improvements of ~6.28% over the best prior naturalness-based method (Local LP).
- Aslec-casl outperforms Aslec-drop, with an average gain of ~9.08%, exemplifying the efficacy of causal debiasing in preserving relevant information while removing structural bias.
Performance gains are especially pronounced in low-resource or smaller model training settings, where noisy or confounded samples have a heightened negative impact. Furthermore, the causal regression analysis quantifies the magnitude of the confounder (γ), showing it to be significant and consistent across teacher models.
Supplementary Analyses of Response Length and Token Position
The paper conducts an extensive supplementary analysis of total response length bias. In contrast to step length, biases induced by overall response length are empirically minor, further reinforcing that step length is the critical confounder in naturalness-based selection.
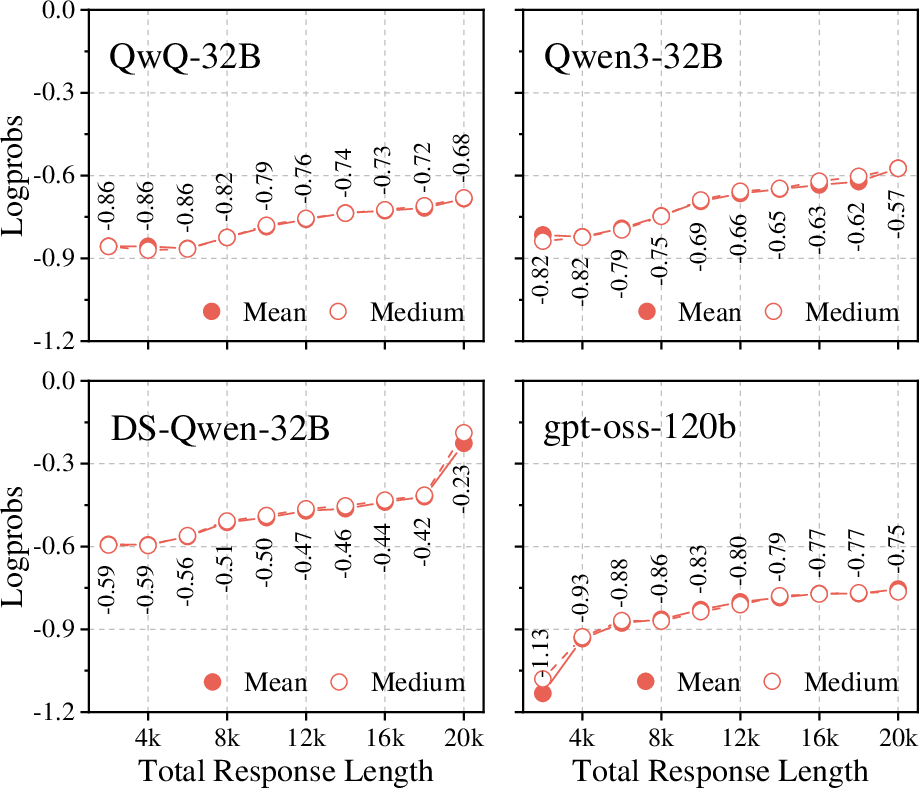
Figure 5: Relationship between response-level log probability and total response length.
Average log probability increases with response length due to increased confidence in tail-end tokens, but this effect is negligible compared to the bias introduced by step splitting.
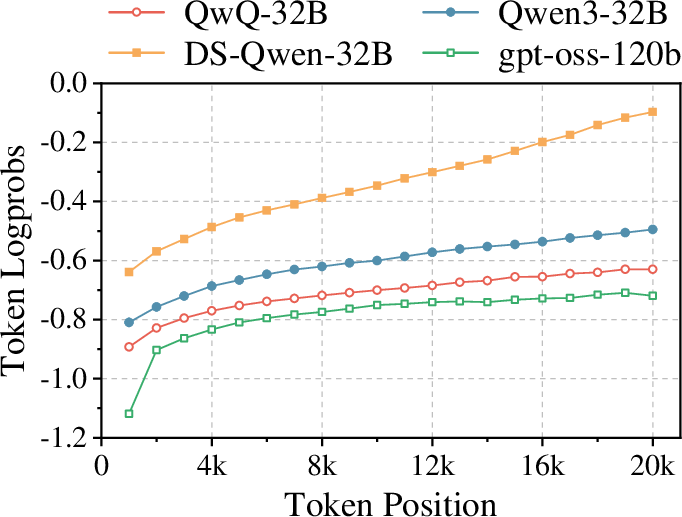
Figure 6: Average log probability of tokens at different positions for four source LLMs.
Monotonic increase of token probabilities along the sequence is observed, supporting the hypothesis that longer responses are not inherently problematic for data selection, while step length confounding remains the primary concern.
Practical and Theoretical Implications
Practically, these findings mandate a re-design of data selection pipelines for reasoning SFT in LLM training. Step length confounding can induce spurious correlations, negatively impacting generalization, robustness, and multi-source data diversity. Debiasing strategies such as Aslec-casl enable more principled adaptation, ensuring the selected data reflect genuine alignment rather than structural artifacts. Theoretically, the work deepens the understanding of sequence-level and step-level entropy dynamics, prompting further exploration of confounders in model selection and evaluation.
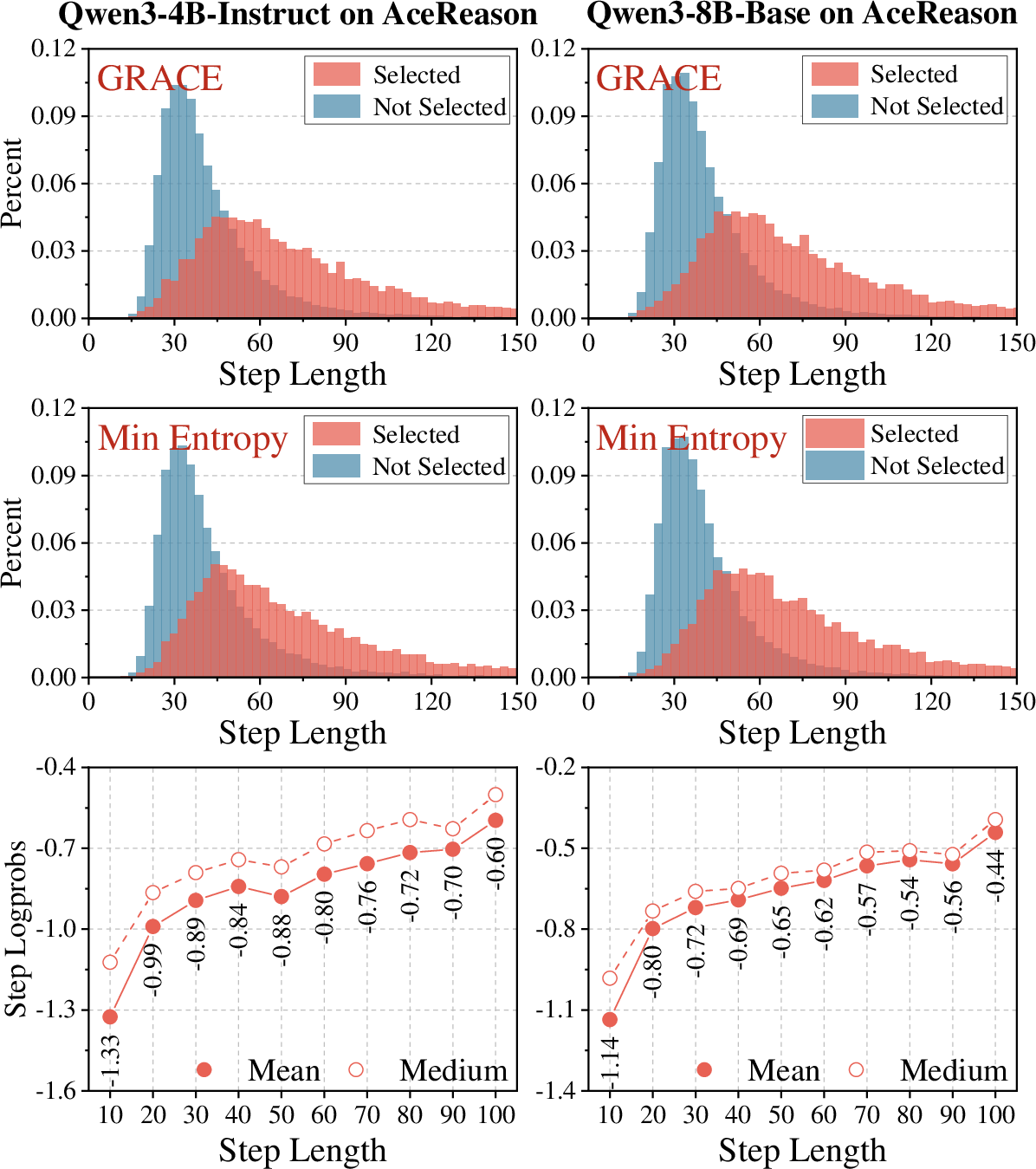
Figure 7: Step length distributions for selected and unselected data and relationship between step-level log probability and step length on AceReason-1.1-SFT.
The implications for future AI developments extend to both off-policy and on-policy SFT, RLHF, and iterative distillation schemes—particularly as LLMs evolve toward more granular step-wise reasoning and longer CoT trajectories. The causal methodology for debiasing lays groundwork for robust downstream metrics and evaluation strategies.
Conclusion
This paper exposes and systematically analyzes the step length confounding inherent in naturalness-based data selection for LLM reasoning SFT. By leveraging token-level statistics and causal regression, it introduces efficient debiasing techniques that substantially improve accuracy and robustness across multiple datasets and models. The work compels the community to reconsider scoring and selection protocols in large-scale reasoning model training, emphasizing the necessity for structural debiasing to ensure genuine sample quality and alignment.