The Topological Trouble With Transformers
Abstract: Transformers encode structure in sequences via an expanding contextual history. However, their purely feedforward architecture fundamentally limits dynamic state tracking. State tracking -- the iterative updating of latent variables reflecting an evolving environment -- involves inherently sequential dependencies that feedforward networks struggle to maintain. Consequently, feedforward models push evolving state representations deeper into their layer stack with each new input step, rendering information inaccessible in shallow layers and ultimately exhausting the model's depth. While this depth limit can be bypassed by dynamic depth models and by explicit or latent thinking that externalizes state representations, these solutions are computationally and memory inefficient. In this article, we argue that temporally extended cognition requires refocusing from explicit thought traces to implicit activation dynamics via recurrent architectures. We introduce a taxonomy of recurrent and continuous-thought transformer architectures, categorizing them by their recurrence axis (depth versus step) and their ratio of input tokens to recurrence steps. Finally, we outline promising research directions, including enhanced state-space models and coarse-grained recurrence, to better integrate state tracking into modern foundation models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains a hidden weakness in today’s most popular AI models, called transformers. Transformers are great at looking back over what they’ve read, but they struggle to keep track of a changing “situation” over time—like keeping score in a game or remembering what’s already been decided in a conversation. The authors argue that to think over time (like humans do), AI needs more than just looking back; it needs internal memory that is updated step by step. They propose ways to add this kind of memory and organize the different ideas into a simple “family tree” of designs.
What questions are the authors asking?
- Why do standard transformers sometimes lose track of what’s going on in a story, conversation, or problem that unfolds over many steps?
- Can we fix this by making transformers “loop” or “think internally” instead of just reading forward?
- What kinds of looping (recurrence) are most useful, and how do they fit into a bigger picture of possible model designs?
- How can we build future models that keep consistent, long-term understanding without wasting lots of time or memory?
How did they study it?
This is a concept and theory paper, not mainly a lab experiment. The authors:
- Use simple examples to show where transformers fail at “state tracking.” For instance:
- A higher/lower guessing game where the model needs to keep track of which numbers are still possible.
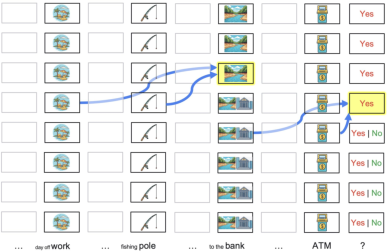
- A sentence with an ambiguous word like “bank” (river bank vs. money bank) where the model flips its meaning mid-conversation.
- Explain how information moves inside a transformer. Picture the transformer as a building with many floors (layers). As new words come in, the “current situation” gets pushed to higher floors. Lower floors can’t easily “see” it anymore. Because the building has a fixed number of floors (depth), the model can “run out of room” to keep updating its internal situation.
- Compare that to models with loops (recurrent models), which update a small “state” every step without pushing it higher and higher. In math terms, this is like —the state at time depends on the previous state plus the new input, over and over.
- Unroll different designs to show how loops can be added to transformers in different ways, and propose a taxonomy (a neat, organized map) of these designs.
What did they find and why is it important?
Main idea: Plain transformers are “feedforward”—information mostly flows upward through layers. That works well for looking up facts in the recent context, but it’s not great for maintaining and updating a compact internal memory (the “belief state”) over many steps.
Key points, in simple terms:
- The “pushing up the stack” problem: Each time a new word arrives, the updated situation gets stored deeper in the model. Shallow parts can’t use it right away, and the model can eventually hit a depth limit.
- Workarounds exist but can be inefficient:
- “Chain-of-thought” or “thinking tokens” (writing out step-by-step thoughts) lets the model pass information back to itself as new input. This helps—but it’s like constantly writing notes to yourself so you don’t forget. It takes time and fills up your notebook (context window).
- Making the model dynamically deeper (running layers multiple times) helps somewhat, but if information still has to move upward, there’s still a limit.
- Better solution: Add recurrence—loops that update an internal state every step. This is closer to how the brain works and lets the model keep a stable, evolving memory without constantly pushing it “upstairs.”
- A taxonomy (family tree) of recurrent transformer styles:
- Looping through layers (depth recurrence): run a layer or stack of layers multiple times per step.
- Looping across steps (step recurrence): pass state forward from one token to the next inside the same layer (this includes state-space models).
- Both depth and step recurrence: hybrids that can think multiple times per token, or process blocks of tokens before updating.
- They also consider how often you loop: more tokens per loop, one token per loop, or multiple loops per token (like “latent thoughts” where the model silently thinks several times before reading the next word).
- Why this matters: Stronger “state tracking” means models can keep conversations consistent, follow long plots, do multi-step reasoning, and cooperate better in multi-agent tasks—all with less wasteful computation.
What approaches look promising?
To make models better at tracking changing situations without burning lots of compute or memory, the authors highlight several directions. Below is a short list to make it clear:
- Enhanced state-space and attention designs:
- New hybrids (like RWKV-7 and PaTH attention) that can be trained in parallel but still carry forward state better than standard transformers.
- Gated or selective attention that updates state more reliably over time.
- Teaching feedforward models to “approximate” state tracking:
- Special training goals and biases that nudge transformers to keep consistent, compact internal summaries (even without explicit loops).
- Coarse-grained recurrence:
- Instead of updating state every token, update every sentence or “thought.” This reduces cost while keeping longer-term consistency.
- Leveraging representational alignment:
- Transformers already make layer outputs line up well (thanks to residual connections). Methods that reuse or loop these aligned representations can enable recurrence with minimal retraining.
- Efficient training for recurrence:
- Pretrain as usual (fast and parallel), then add recurrence later with smart optimization tricks so training stays practical.
Bottom line: Why does this research matter?
If we want AI that stays coherent across long conversations, plans over many steps, and understands changing situations (like people do), we need models that can maintain and update an internal “belief state” over time. The paper shows that plain transformers hit architectural limits here and rely too much on “thinking out loud,” which is slow and expensive. By adding the right kinds of recurrence—careful loops that let the model quietly update its memory—we can build future AI that is more consistent, more efficient, and better at long, multi-step reasoning.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of the key knowledge gaps and open problems the paper identifies or implies but does not resolve.
- Formalize “state tracking” as a task class: provide precise definitions (e.g., POMDP-style belief updates, deterministic vs probabilistic state, compositional state factors) and complexity measures that distinguish true state tracking from lookback/lookup strategies.
- Tighten theory beyond constructability: establish learnability results (sample complexity, optimization hardness) for transformers vs recurrent variants under practical training (SGD with noise, finite precision, residuals, KV caches, RoPE/ALiBi).
- Quantify depth-budget consumption: develop methods to measure how state representations drift upward through layers over time (e.g., “state depth profile”), and derive analytical bounds for when a feedforward stack becomes depth-exhausted given sequence length and task demands.
- Causally identify “racing thoughts”: create diagnostics that detect when necessary disambiguations or latent inferences occur too deep or too late for subsequent tokens; verify causality via interventions, ablations, and controlled latency manipulations.
- Benchmark suite for state tracking: design standardized, scalable datasets and metrics requiring indefinite or long-horizon state maintenance (multi-agent dialogue, entity/world modeling, program execution, Bayesian belief updates) with provable resistance to shortcutting via pure lookback.
- Scaling laws for statefulness: measure how state-tracking fidelity scales with model depth/width, context length, and recurrence type; identify the regime where depth limits become the dominant failure mode.
- Comparative evaluation of recurrence axes: systematically compare depth recurrence, step recurrence (SSMs, within-layer dynamics), and depth+step hybrids under equalized compute/memory and latency budgets.
- Explore taxonomy “empty cells”: instantiate and study architectures in the unfilled cells (e.g., depth-axis recurrence with ratio=1 and ratio<1; step-axis recurrence with ratio<1 using within-layer attractors), including implementation recipes and training protocols.
- Attractor dynamics in transformers: develop stable, convergent attractor mechanisms (within-layer or multi-layer), with convergence criteria, halting policies, and differentiable training (e.g., recurrent backprop), and prove/measure fixed-point existence and uniqueness.
- Autoregressive training efficiency: devise compute-efficient pretrain–finetune curricula that introduce recurrence late, including truncated gradients, synthetic pretraining objectives for state, and scheduling policies that maintain stability and throughput on modern accelerators.
- Adaptive compute policies for recurrence: learn token-/chunk-level halting and iteration policies (e.g., ponder, mixture-of-recursions) with reliable credit assignment, calibrated stopping, and robustness to distribution shift.
- Data/labeling for state supervision: propose self-supervised and weakly supervised objectives that expose and stabilize latent state (e.g., auxiliary state heads, future consistency checks, contradiction detection across turns), including protocols to estimate probabilistic belief states.
- Distinguish lookback vs true state updates: design probes that can tell whether a model solved a task via recomputation from context vs persistent state maintenance, using causal masking, delayed feedback, or amortization tests across steps.
- Interpretable state slots: investigate structured, compositional state representations (entity slots, role/factor graphs, dynamic binding) that update asynchronously and remain accessible to shallow layers; evaluate credit assignment and interference.
- RWKV-7/PaTH/GLA expressivity claims: rigorously test the statefulness and expressivity gains under controlled apples-to-apples compute, confirm stability of long-horizon updates, and analyze gradient flow and numerical conditioning over long sequences.
- KV-cache as state mechanism: formalize when and how KV-copying/sharing constitutes effective state propagation (deep-to-shallow feedback), including memory/compression trade-offs, training-time learnability, and inference-time efficiency.
- Latent-thought vs chain-of-thought: quantify compute/memory costs and benefits of latent loops vs natural-language CoT; design training signals to keep micro-state implicit while enabling explicit thought only when beneficial.
- Coarse recurrence granularity: determine optimal chunk/sentence/thought segmentation for blockwise recurrence; compare learned vs linguistic chunkers; assess how granularity affects coherence, latency, and memory consumption.
- Robustness and safety of persistent state: study calibration, reject/abstain behavior, and error persistence in recurrent models; develop reset/repair interventions to avoid sticky misbeliefs or pathological attractors over long interactions.
- Hardware–software co-design: create kernels and execution schedules that preserve parallelism for recurrent updates (e.g., micro-batching, pipeline overlap, cross-layer caching) while supporting halting and attractor iterations efficiently on GPUs/TPUs.
- Interaction with positional encodings: analyze how RoPE/ALiBi and attention span patterns affect state tracking and deep-to-shallow accessibility; propose position schemes tailored to recurrent state updates.
- Multi-modal and embodied settings: extend taxonomy and methods to vision/audio/actuation loops where state is partially observed and continuous; evaluate in embodied agents and planning tasks with long temporal dependencies.
- Generalization under distribution shift: test whether recurrent state models retain coherent state under topic switches, speaker changes, or task transitions, and how quickly they can reset or re-initialize state.
- Formal upper bounds with recurrence: characterize the minimal recurrence needed (iterations per token/layer) to achieve specific state-tracking guarantees, given constraints on depth, memory, and attention sparsity.
- Evaluation protocols for fairness: standardize cost-normalized comparisons (FLOPs, wall-clock, memory, latency) across feedforward, looped-depth, step-recurrent, and latent-thought models to avoid confounding by extra compute.
- Learnability of log-depth compositions: bridge theory and practice by identifying training biases/objectives that reliably discover known log-depth solutions (e.g., parity, regular languages) in large-scale settings without handcrafted curricula.
- Tool/memory integration: study hybrids that externalize only macro-state (databases, scratchpads) while keeping micro-state recurrent and implicit; quantify when external tools outperform recurrent updates and vice versa.
- Metrics for conversational coherence: define longitudinal self-consistency and contradiction metrics over multi-turn dialogue (e.g., belief drift, entity state divergence) sensitive to depth-limited delays and reversals.
- Negative results and ablations: provide controlled demonstrations where added recurrence alone resolves failures like polysemy flip-flops or number-range tracking, isolating recurrence from confounders such as extra compute or prompting.
Practical Applications
Immediate Applications
- Conversational consistency guards for deployed LLMs (customer support, healthcare triage, finance advice, education)
- What: Add lightweight “state managers” that compress each turn into a belief-state summary and feed it back as context to stabilize interpretations (e.g., bank=river) and track valid ranges in games or troubleshooting flows.
- Tools/workflows: Turn- or sentence-level chunking (“coarse recurrence”); response pacing to avoid answering before deeper layers converge; [PAUSE]/“think” control tokens; shallow-to-deep convergence monitors (e.g., Patchscopes-like probes).
- Assumptions/dependencies: Requires prompt-level orchestration or minimal adapters; small latency overhead; access to model logits/activations improves monitoring but is not strictly necessary.
- Blockwise-recurrent inference for reasoning-heavy tasks without retraining (software/IT ops, legal drafting, analytics)
- What: Run multiple input tokens per recurrence step (blockwise loops) to integrate local context before advancing, improving multihop inference without full architectural change.
- Tools/workflows: Inference-time looping over selected layers (“looped”, mixture-of-depths/pondering schedulers); deterministic budgets per block (e.g., k loops per paragraph/section).
- Assumptions/dependencies: Inference cost increases modestly; works best when models already align representations across layers (residual pathways).
- Latent-thought over CoT to cut costs while retaining coherence (enterprise AI assistants, search/RAG)
- What: Replace or reduce verbose chain-of-thought with short latent “thinking” cycles per input step, lowering token usage and privacy exposure while propagating internal state.
- Tools/workflows: Server-side latent-thought scheduling (run m inner steps/token); “pause tokens” to trigger internal processing; compatibility with KV caches.
- Assumptions/dependencies: Some models already support latent thinking; may require adapter fine-tuning to stabilize; marginal latency tradeoff.
- Hybrid attention blocks to improve state propagation in existing stacks (software platforms, model vendors)
- What: Insert or fine-tune RWKV-like, PaTH, or gated-linear-attention blocks to add sequential dependency within layers, strengthening belief-state updates.
- Tools/workflows: Adapter modules or LoRA on specific blocks; selective replacement of attention in middle layers; A/B tests on stateful benchmarks.
- Assumptions/dependencies: Access to fine-tuning; careful stability/throughput evaluation; incremental rollout.
- Belief-state aware tool-use in agents (RAG, function calling, workflow automation)
- What: Explicitly maintain and update compact belief-state objects (e.g., JSON schemas) across tool invocations to prevent flip-flops and redundant queries.
- Tools/workflows: Agent frameworks with typed “state stores,” delta updates, and cross-attention to state; consistency checks before action.
- Assumptions/dependencies: Schema design; guardrails when state uncertainty is high (IDK/reject options).
- “Wait-to-answer” safety rails to avoid shallow-layer snap judgments (consumer chat, tutoring)
- What: Delay emission of high-confidence answers until semantic disambiguation converges; abstain when the model detects shallow, ambiguous interpretations.
- Tools/workflows: Confidence gating; explicit [IDK]/reject options; calibration validation; entropy/consistency monitors across layers.
- Assumptions/dependencies: Mild UX latency; monitoring hooks or proxy signals (e.g., logit dispersion) if internals are inaccessible.
- Evaluation suites and SLAs for temporal consistency (industry QA, procurement, policy audits)
- What: Establish benchmarks for state tracking (e.g., twenty-questions consistency, cross-turn polysemy, long-dialog coherence) and include metrics in model selection.
- Tools/workflows: Automated red-teaming for flip-flops; serial capacity tests; track error rates vs. token budgets/inference loops.
- Assumptions/dependencies: Dataset curation; acceptance of modest compute for QA.
- Coarse recurrence for long-form content generation (media, games, marketing)
- What: Chunk narratives into “thoughts” (sentences/paragraphs/scenes) and carry forward compact state (characters, timelines, constraints) to ensure internal consistency.
- Tools/workflows: Story-state graphs; per-chunk state summarizers; regeneration only when state changes, reducing drift.
- Assumptions/dependencies: Authoring pipelines; light finetuning improves quality.
- Training objectives that bias toward compositional state (research/academia, model vendors)
- What: Apply losses that reward accurate, compact state updates and consistency across steps in pure feedforward models where retraining is feasible.
- Tools/workflows: Auxiliary supervision on latent slots; tube prediction/state matching losses; curriculum with synthetic stateful tasks.
- Assumptions/dependencies: Access to pretraining/finetuning; compute budget; risk of task overfitting mitigated by diversity.
- Cost-aware compute allocation (cloud ops)
- What: Use dynamic depth/recurrence only when signals indicate complex state transitions; fall back to single-pass for straightforward queries.
- Tools/workflows: Mixture-of-depths, adaptive computation time, or loop schedulers driven by confidence/uncertainty.
- Assumptions/dependencies: Policy tuning to balance latency vs. quality.
Long-Term Applications
- Recurrent foundation models with indefinite state tracking (model vendors, research)
- What: Architectures with step+depth recurrence and attractor dynamics for stable, long-horizon state updates, trained via multi-stage (FF pretrain → recurrent finetune).
- Tools/products: “Stateful LLMs” with KV+state memories; compilers for autoregressive unrolling; training with truncated gradients/recurrent backprop.
- Assumptions/dependencies: Scalable training pipelines; hardware/runtime support for autoregressive loops; new evals for stability and serial capacity.
- Longitudinal healthcare assistants maintaining patient belief states (healthcare)
- What: Virtual care agents that track diagnoses, meds, and uncertainty across visits; consistent decision support with explicit belief updates.
- Tools/workflows: EHR-integrated belief-state stores; uncertainty-aware plans; clinician-in-the-loop corrections.
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR), safety validation, robust uncertainty calibration, liability frameworks.
- Memory-aware robotics and embodied agents (robotics, manufacturing, logistics)
- What: Controllers that incrementally update world-state and plans over extended tasks (e.g., assembly, household assistance) with recurrent attention/SSMs.
- Tools/workflows: Hybrid perception-language stacks with stepwise state updates; attractor dynamics for sensor fusion and failure recovery.
- Assumptions/dependencies: Real-time guarantees; sim-to-real transfer; safety certifications.
- Portfolio- and risk-stateful assistants (finance)
- What: Advisory agents that maintain positions, exposures, and scenario beliefs across sessions, avoiding inconsistent recommendations.
- Tools/workflows: Formal belief-state schemas linked to OMS/RMS; abstention when state is ambiguous; audit trails of state transitions.
- Assumptions/dependencies: Regulatory compliance; latency constraints during market hours; robust backtesting.
- Personalized tutors with persistent learner models (education)
- What: Tutors that update fine-grained mastery/affect states and plan curricula over months, improving coherence and efficiency.
- Tools/workflows: Student-state graphs; chunk-level recurrence for lesson segments; consistency and motivation strategies.
- Assumptions/dependencies: Privacy/consent; bias mitigation; content alignment.
- Software engineering copilots with project-state tracking (software)
- What: Agents that maintain evolving architecture/design invariants and task queues across branches/sprints, reducing context-window thrash.
- Tools/workflows: Repository-level belief states; stepwise updates aligned with CI events; multi-agent coordination with shared memory.
- Assumptions/dependencies: Secure repo access; versioned state; organizational adoption.
- Multi-agent coordination with stable theory-of-mind (operations, simulations, games)
- What: Teams of agents maintaining self/other belief states to reduce miscoordination in negotiation, logistics, crisis response.
- Tools/workflows: Shared memory substrates; recurrent updates per turn; arbitration policies when beliefs diverge.
- Assumptions/dependencies: Communication bandwidth; conflict resolution protocols; evaluation in complex environments.
- Grid and process operations with temporally coherent control (energy, manufacturing)
- What: Controllers that maintain latent process states for long-horizon optimization (e.g., demand response, batch processing).
- Tools/workflows: RWKV-/PaTH-like layers for fast sequential updates; attractors for steady-state estimation; human override interfaces.
- Assumptions/dependencies: Integration with SCADA/MES; safety and reliability constraints; certification.
- Standards and regulation for temporal consistency and “stateful AI” (policy)
- What: Define conformance tests for state tracking, disclosure policies for latent thought vs. CoT, and logging of belief-state transitions for auditability.
- Tools/workflows: Benchmarks/metrics (serial capacity, flip-flop rate, consistency under perturbations); procurement checklists; red-team protocols.
- Assumptions/dependencies: Industry consensus; privacy-preserving state logs; enforcement mechanisms.
- Tooling ecosystem for state debugging and design (academia, tooling vendors)
- What: “Belief-state debugger” to visualize when and where disambiguation happens across layers/steps; SDKs implementing the recurrence taxonomy.
- Tools/products: Layer-wise probes, causal traces, and intervention tools; schedulers for blockwise/latent loops; dataset generators for stateful tasks.
- Assumptions/dependencies: Access to model internals or cooperative APIs; community benchmarks and shared datasets.
- Hardware/runtime co-design for autoregressive unrolling (semiconductor, cloud)
- What: Kernels and scheduling primitives optimized for fine-grained recurrent steps and attractor iterations with KV/state reuse.
- Tools/workflows: Memory-efficient caches, low-latency loop control, compiler support for mixed FF/recurrent graphs.
- Assumptions/dependencies: Vendor cooperation; economic justification via QoR improvements.
Notes on feasibility across items:
- Many immediate tactics (coarse recurrence, latent-thought, blockwise loops, abstention) are deployable now via prompting, orchestration, and lightweight adapters, trading small latency for large consistency gains.
- High-fidelity, indefinite state tracking requires architectural recurrence along steps (and optionally depth), which in turn requires new training regimes and possibly hardware/runtime support; these are long-term but unlock qualitatively new capabilities in temporal coherence and planning.
Glossary
- Activation dynamics: The pattern of internal neural activations evolving over time to carry computation or state implicitly. "requires refocusing from explicit thought traces to implicit activation dynamics via recurrent architectures."
- Attractor dynamics: Recurrent updating that iterates until the network converges to a stable state (an attractor). "This model may have attractor dynamics since each layer continues to update, converging only when all previous steps have reached asymptote."
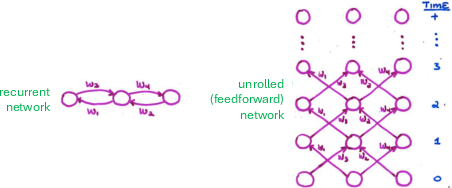
- Autoregressive unrolling: Executing a model step-by-step so each step depends on previous computed states, precluding sequence-parallel training. "This necessary sequentiality is what we mean by autoregressive unrolling, not the sequentiality that arises from token-by-token generation in a pure feedforward model."
- Belief state: A compact representation (often probabilistic) of what an agent currently knows about the environment. "The term belief state is often used to refer to this compact, sufficient summary of the knowledge an AI agent has about its environment \citep{Chrisman1992,kaelbling1998planning}."
- Belief-state cascades: Layer-by-layer chains of state updates that push state deeper into the network. "However, when belief-state cascades push deeper and deeper into a network, computational limitations arise because the resulting representations are unavailable to shallower layers."
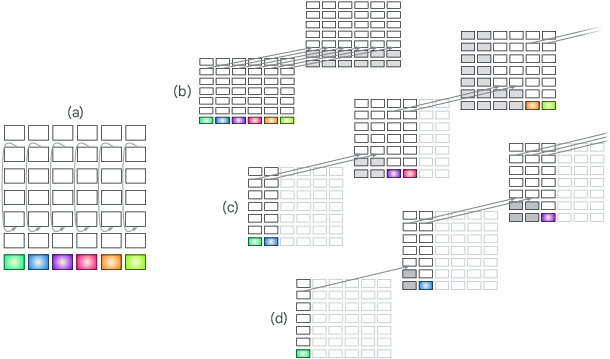
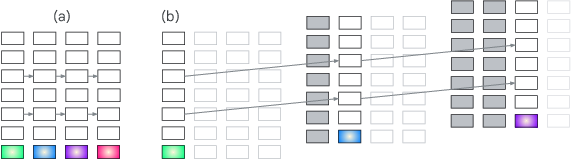
- Blockwise-recurrent model: A model that processes blocks of tokens in parallel, then performs a recurrent update between blocks. "Figure~\ref{fig:unrolling_transformer}c depicts a blockwise-recurrent model \citep{hutchins2022,chevalier2023adaptinglanguagemodelscompress,chen2025melodi,borazjanizadeh2026} in which a subsequence of input steps is run in parallel (two in the Figure) followed by an autoregressive iteration;"
- Chain-of-thought: Generating intermediate reasoning steps (often as text) to aid problem solving and state propagation. "One solution to the depth dilemma is chain-of-thought style ``thinking'' where the model recasts a deep representation as one or more output tokens, which are then available to the model on its input \citep{wei2022chain}."
- Context window: The span of prior tokens the model can attend to when producing outputs. "The transformer, with an audaciously long context window, retains all information in its history, often postponing the selection of relevant data until required for inference \citep{meng2022locating}."
- Cross attention: An attention mechanism where one set of representations (queries) attends to another source of keys/values. "it could represent a source of keys for cross attention \citep{fan2021},"
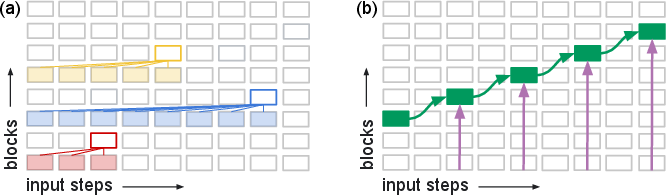
- Depth recurrence: Recurrence that reuses layers (or layer ranges) across iterations to increase compute along the depth axis. "Depth recurrence---whether of individual layers or ranges of layers, and whether deterministic or adaptive---is a very popular and successful approach."
- Dynamic depth: Architectures that adaptively vary the number of layer applications (compute) per input. "While this depth limit can be bypassed by dynamic depth models and by explicit or latent thinking that externalizes state representations, these solutions are computationally and memory inefficient."
- Feedforward transformer: A standard transformer without recurrent dependencies across steps during training. "In cases where these representations depend on previous states and current inputs, the state tracking capability of a feedforward transformer is fundamentally limited by the depth of the model."
- KV cache: Stored key/value tensors from prior steps used to speed up inference and preserve context. "The gray filled rectangles indicate blocks that can be replaced by the frozen KV cache as their values no longer change."
- Latent-thought models: Models that perform multiple internal autoregressive steps per input token using non-text latent states. "Latent-thought models have this form \citep[e.g.,] []{hao2025coconut,jolicoeurmartineau2025,galashov2025}."
- Looped transformer: A transformer unrolled in depth by repeatedly applying the same layers across recurrent iterations. "Figure~\ref{fig:unrolling_transformer}b depicts a transformer unrolled in depth, sometimes referred to as a looped transformer."
- LoRA: Low-Rank Adaptation; a lightweight parameter-efficient adapter inserted into layers to modify behavior. "or it might represent a direct connection through a linear layer, an MLP, or an adapter such as LoRA \citep{hu2022lora}."
- MAP estimate: Maximum a posteriori estimate; the most probable state under a posterior distribution. "mental models most consistent with premises \citep{johnson1983}, like a MAP estimate."
- Multihop inference: Reasoning that requires chaining multiple intermediate steps to reach a conclusion. "such as state tracking, multihop inference, and planning."
- Patchscopes: A technique for probing and patching internal activations to interpret model behavior. "Using a technique called Patchscopes \citep{ghandeharioun2024}, \citet{lepori2025} observed that the embedding of the polysemous word `bank' was ambiguous..."
- Polysemous word: A word with multiple related meanings that must be disambiguated by context. "Without proper state tracking, models flip-flop in their interpretations and fail to detect their inconsistencies, e.g., the meaning of a polysemous word \citep{lepori2025}:"
- Recurrent backpropagation: A training method for recurrent/attractor networks that computes gradients through fixed-point dynamics. "optimization techniques such as truncated gradient methods and---for training attractor dynamics---recurrent backpropagation \citep{almeida1987learning,pineda1987generalization,liao2018}."
- Recurrent neural network (RNN): A neural architecture that updates a hidden state over time via explicit recurrence. "an ideal architecture for modeling temporally extended cognition would be a recurrent neural network (RNN), which explicitly performs such a state-update operation."
- Residual connections: Skip connections that add inputs to outputs of layers, aiding gradient flow and representation alignment. "the model is well predisposed to communication of representations across layers, due to the alignment resulting from the residual connections."
- State compositionality: Decomposing overall state into multiple components that can be updated independently. "Another factor in the success of transformers is their support of state compositionality."
- State-space models (SSMs): Sequence models that maintain and update a hidden state using state-transition equations. "State-space models (SSMs) are often touted as a means of state propagation, but SSMs with linear updates are no more expressive than an ordinary transformer \citep{merrill2025illusion}."
- Teacher forcing: Training strategy that feeds ground-truth previous outputs to the model instead of its own predictions. "many forms of recurrence require that even when a model is trained via teacher forcing, it must still be unrolled autoregressively"
- Variable-depth models: Models that dynamically choose how many layer iterations or block repetitions to apply per input. "Variable-depth models dynamically select the number of iterations of a layer or the number of times a range of layers repeats."
Collections
Sign up for free to add this paper to one or more collections.

