- The paper introduces COS-PLAY, a framework that co-evolves LLM decision agents and a dynamic skill bank to enhance long-horizon performance.
- The methodology integrates unsupervised skill discovery, contract learning, and group policy optimization to ensure effective skill reuse and aligned decision-making.
- Empirical results across diverse games show notable reward improvements and competitive performance in both single-player and multi-player scenarios.
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks: A Technical Analysis
Introduction and Motivation
Long-horizon decision-making in partially observable, procedurally complex environments presents fundamental challenges for LLM-based agents, particularly regarding the discovery, retention, and effective reuse of structured procedural skills. The "Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks" paper addresses these challenges by proposing COS-PLAY, a framework in which an LLM decision agent continually co-evolves alongside a dynamically maintained skill bank. This tightly coupled loop enables agents to extract, refine, and leverage reusable behavior protocols, substantially improving performance in environments—such as digital games—that demand multi-step reasoning, skill composition, and strategic adaptation under delayed rewards.
COS-PLAY Framework Overview
COS-PLAY is constructed around two central, interacting modules:
- LLM-Based Decision Agent: At every timestep, this agent retrieves skill protocols from a learnable skill bank, maintains a latent "intention" state, and generates primitive actions conditioned on state, retrieved skill, and intention.
- Skill Bank Agent: This unsupervised pipeline continuously segments trajectories to propose candidate skills, infers segment-to-skill assignments, learns effect-based contracts, and maintains the bank through merging, splitting, and retirement routines.
Once an episode concludes, the skill bank agent processes collected trajectories, updating the bank to ensure that skills remain relevant, reusable, and aligned with the evolving policy of the decision agent.
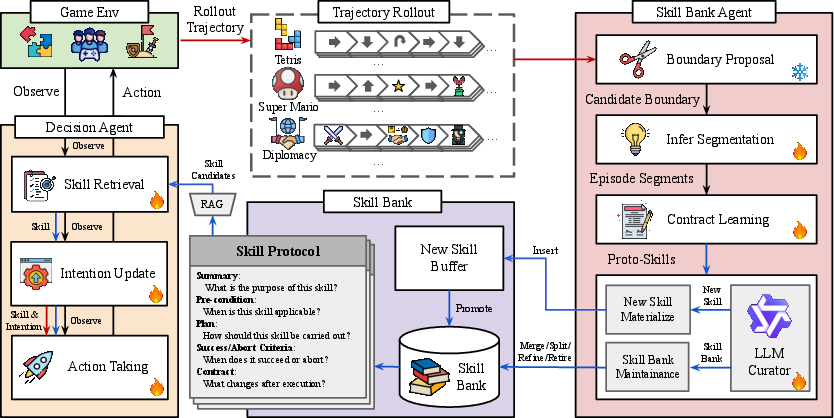
Figure 1: The COS-PLAY architecture couples a decision agent (orange) with a skill bank agent (red) and a dynamically evolving skill bank (purple), facilitating joint learning of skill usage and continual unsupervised skill discovery.
Skill Abstraction and Skill Bank Dynamics
Skills are defined as temporally extended, reusable protocols, each with a descriptive summary, precondition, stepwise plan, success/abort criteria, and an effect "contract" formalizing induced state transitions. Unlike static libraries, COS-PLAY's skill bank is iteratively updated from new rollouts, with a bank agent responsible for contract learning and skill curation.
Decision-making takes the form:
- Skill retrieval πθskill(ot,B)→s~t
- Intention updating πθint(ot,s~t)→zt
- Action selection πθact(⋅∣ot,zt,s~t)→at
Joint optimization is performed using Group Relative Policy Optimization (GRPO) with LoRA adapter specialization for modularization and reward structuring.
Skill Discovery Pipeline
The skill discovery and maintenance process incorporates:
- Boundary Proposal: Heuristic scoring identifies plausible skill-transition points based on predicate flips, intention changes, reward spikes, and switches between primitive and compositional actions.
- Segmentation and Labeling: Candidate segments are matched to existing skills by effect-overlap against contracts; unmatched segments are buffered as new skill candidates.
- Contract Learning: Consensus over state deltas yields effect contracts; only contracts with sufficient empirical support are retained for reuse.
- Bank Maintenance: Pipeline operations enable bank mutation via refinement, materialization, merge, split, and retirement.
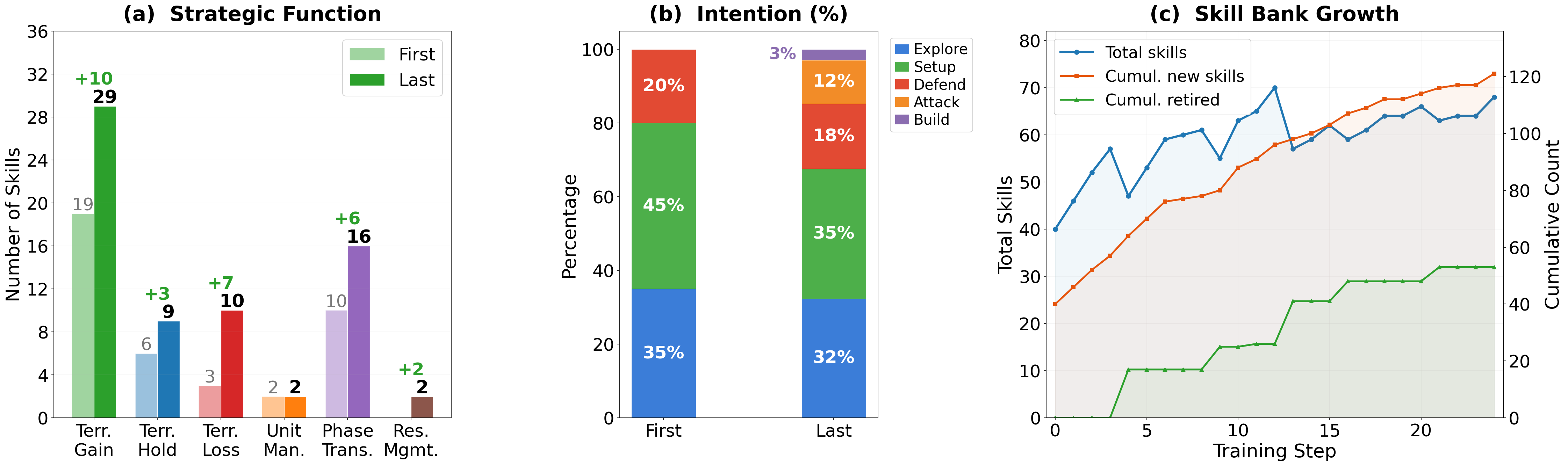
Figure 2: Skill bank evolution in Diplomacy—(a) increased functional diversity and specialty over training, (b) more goal-directed, category-diverse intention composition, (c) growth and curation dynamics maintaining a compact and efficient active set.
Co-Evolution Dynamics
The co-evolution loop alternates between trajectory generation (by the decision agent) and skill bank updates (by the bank agent), continually aligning the actionable policy distribution with current skill abstractions in the bank. This prevents divergence between skill utility and policy deployment, addressing the distributional mismatch found in non-joint training.
Experimental Evaluation
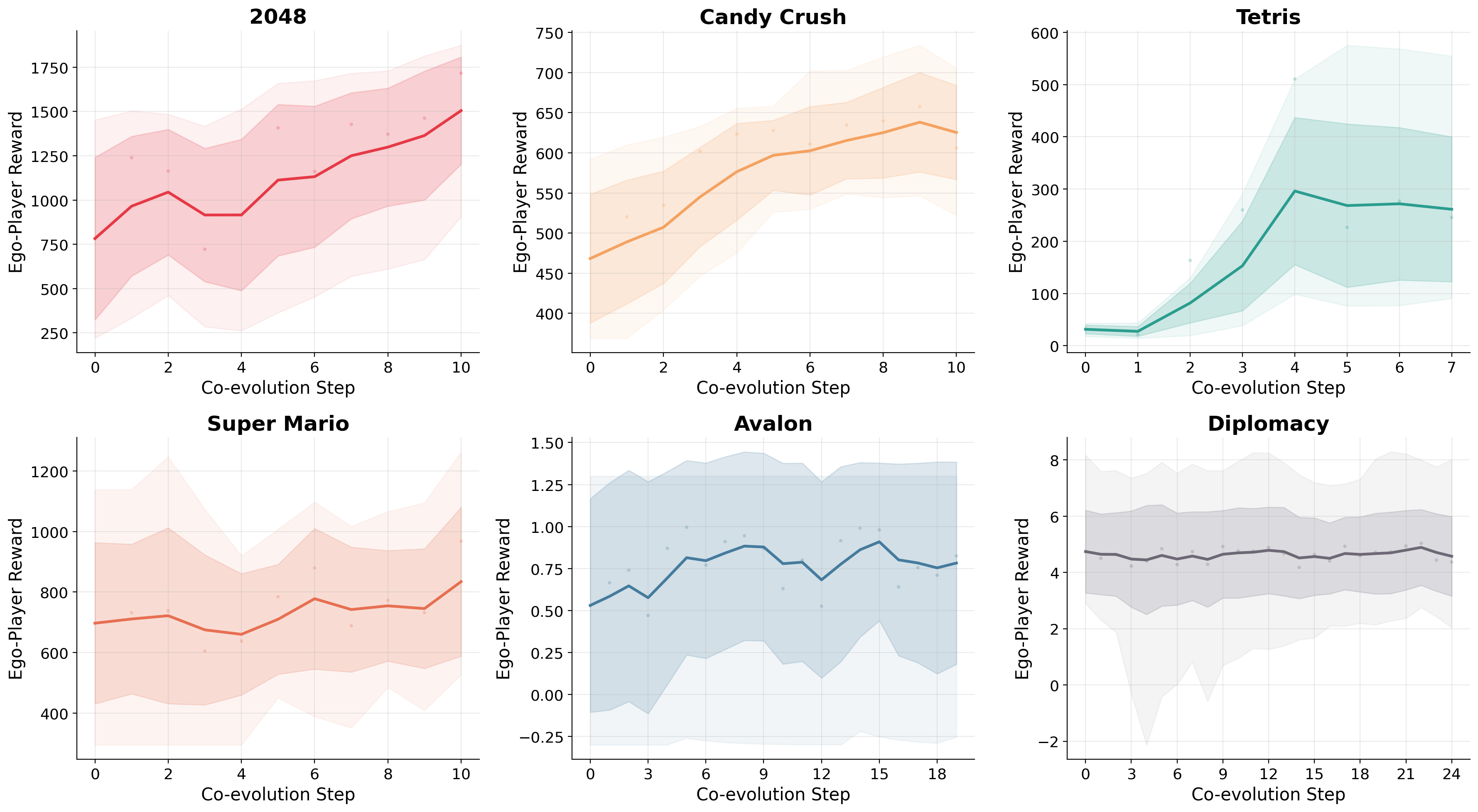
The framework is evaluated in six environments (2048, Candy Crush, Tetris, Super Mario Bros, Avalon, and Diplomacy) covering both classic single-agent puzzles and multi-agent social reasoning games. Observations are structured into textual states; all agent-game interaction proceeds via discrete text actions.
Empirical results demonstrate:
Ablation studies validate the necessity of co-evolution: mere skill library addition or RL fine-tuning, without mutual adaptation, underperforms full COS-PLAY. Only tight policy-skill alignment permits effective skill retrieval and execution—mismatched or stale banks can degrade performance by introducing non-aligned priors.
Analysis of Skill Reusability and Dynamics
COS-PLAY's unsupervised skill discovery avoids skill bloat and trajectory memorization by continually curating a compact, high-utility skill library. In Diplomacy case studies, the bank achieves a strategic repertoire spanning early exploration, setup, defense, and aggression, with disciplined phase boundaries and low redundancy.
Table: Skill reusability metrics (abbreviated)
| Game |
#Skills |
#Categories |
Max Instances |
Gini (concentration) |
Mean Contract Versions |
| Diplomacy |
64 |
5 |
45 |
0.52 |
2.4 |
| 2048 |
13 |
6 |
236 |
0.71 |
3.1 |
Disciplined temporal gating of skill transitions (e.g., exploration strictly ends after a fixed number of turns) yields both robustness—COS-PLAY maintains a higher minimum outcome in adverse scenarios—and diversity of outcomes through action-space expansion within skill phases.
Implications and Future Directions
Practical implications involve superior sample efficiency for long-horizon adaptation, drop-in modularity for new tasks via skill bank transfer (potential for cross-domain generalization), and enhanced transparency/controllability in agent strategy through explicit protocols.
Theoretically, COS-PLAY highlights advantages of explicit, contract-based skill abstraction and agentic skill bank evolution driven by mutual feedback from both policy deployment and skill utility evaluation. This stands in contrast with static or purely memory-augmented LLM agent paradigms.
Extensions to multi-modal domains—integrating visual, symbolic, and text observations—will be critical for generalizing the proven compositionality and co-evolution machinery of COS-PLAY. More advanced attention and curriculum mechanisms for skill activation are likely to further improve adaptability, especially for open-ended environments with expanding state and action spaces.
Conclusion
COS-PLAY introduces a principled, co-evolving architecture where the skill acquisition pipeline is explicitly aligned and iteratively co-trained with the decision policy, fostering robust, reusable abstractions for long-horizon reasoning. The framework achieves strong empirical gains against frontier LLM baselines in both classic and social games, substantiating the value of closed-loop skill-policy co-adaptation.
Limitations involving reliance on text-based state summaries underscore the need for broader multi-modal grounding and dynamic summarization mechanisms. Pursuing these avenues opens a path toward more generalizable, modular agents, capable of self-improvement in complex, interactive environments.