- The paper introduces a structured, multi-layered audit pipeline using static and dynamic evaluations against ISO/IEC criteria to rigorously assess medical research agent skills.
- The paper presents empirical results from 75 agent skills, highlighting variability in quality and pinpointing failure vectors, especially in script-based executions.
- The study validates the framework’s reliability with strong system–expert agreement, while also identifying key areas for rubric refinement in domain-specific assessments.
MedSkillAudit: Domain-Specific Automated Governance for Medical Research Agent Skills
Introduction
MedSkillAudit ("MedSkillAudit: A Domain-Specific Audit Framework for Medical Research Agent Skills" (2604.20441)) addresses a rapidly emerging necessity for rigorous, domain-specific governance mechanisms within medical agent ecosystems. As medical AI agents increasingly rely on modular skills—distinct, reusable task artifacts—safe, scientifically valid, and reproducible skill deployments require audit standards far more stringent than those used for generic agent skills. MedSkillAudit provides a structured, multi-layered audit pipeline aligned with scientific and medical requirements, explicitly targeting release readiness with reference to ISO/IEC 25010 criteria and formal scientific integrity gates.
MedSkillAudit Architecture and Evaluation Protocol
MedSkillAudit operates through a layered pipeline, evaluating both static skill specification and dynamic execution. Skill artifacts (SKILL.md plus optional code/scripts) undergo structural audit (Veto Gate 1: operational stability, structural consistency, determinism, security) followed by domain-specific dynamic evaluation (Veto Gate 2: scientific integrity, boundaries, methodology, code usability). Each gate comprises hard failure criteria—if any is triggered, the artifact is immediately rejected irrespective of numeric scoring. Skills passing both gates are scored via combined static/dynamic rubrics, weighted at 40/60 respectively, across eight ISO dimensions and category-specific subcriteria.
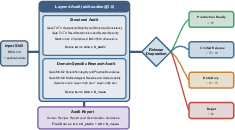
Figure 1: Overview of the MedSkillAudit framework, illustrating the sequential layered audit, veto gates, scoring rubric, and disposition tiers for release readiness.
The evaluation set included 75 agent skills distributed across five categories, representing real-world variability by sampling from different development cycles. Skills were independently rated by two medical research experts using the same rubric, allowing consensus and adjudication for disagreements. MedSkillAudit's outputs were systematically compared to expert reviews using ICC(2,1), weighted Cohen's κ, and Bland-Altman analysis.
Baseline Quality of Medical Agent Skills
The mean consensus quality score across the 75 skills was 72.4, with only 43% of skills qualifying above Limited Release; 16% were outright rejected. Score and disposition distributions highlight broad quality variability: Protocol Design skills achieved the highest mean, Academic Writing the lowest, with Data Analysis presenting the widest variance due to runtime/dependency failures.
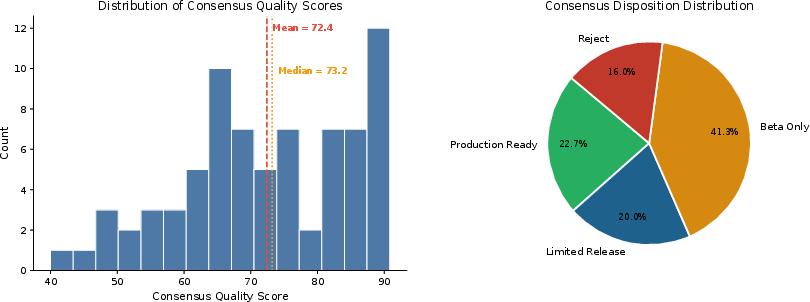
Figure 2: Score distribution and disposition breakdown of the evaluation set, revealing that most skills were not deployment-ready at baseline.
Skill quality varied substantially with functional category and execution mode. Prompt-only (Mode A) skills scored higher than code-based/hybrid skills, reflecting the increased risk surface introduced by dependency and execution complexity.
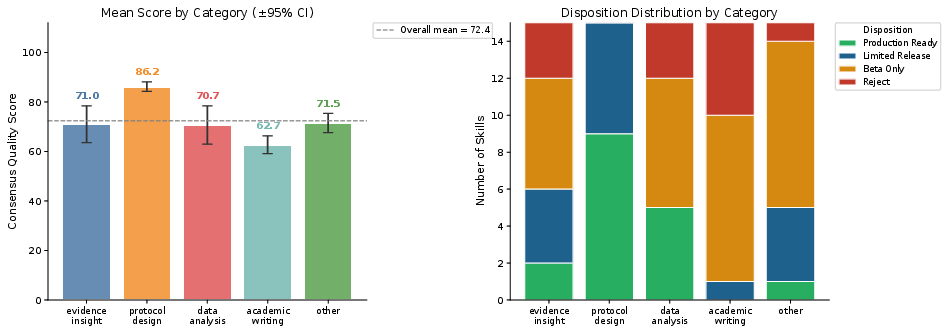
Figure 3: Mean consensus scores by category; production readiness concentrated in Protocol Design, while Academic Writing was frequently rejected.
Expert disagreement was pronounced, especially in Academic Writing (100% adjudication), underscoring the inherent subjectivity and variability in manual rubric application. Script-based Data Analysis skills had the highest risk of catastrophic failures, including dependency conflicts and non-executable code.
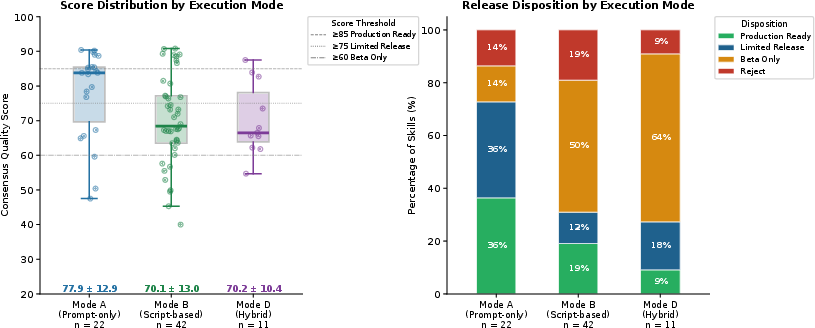
Figure 4: Score and disposition by execution mode; prompt-only skills outperform script-based and hybrid artifacts due to fewer execution failure vectors.
Reliability and Agreement Analysis
MedSkillAudit's core claim is validated empirically: system–expert agreement (ICC=0.449) exceeded the human inter-rater baseline (ICC=0.300). System–consensus differences exhibited lower magnitude (SD=9.5 vs 12.4), and bias was negligible (mean Δ=−1.4, p=0.613). Rank agreement analysis showed the system achieves within-one-tier disposition match in 82.7% of cases, above human comparison.
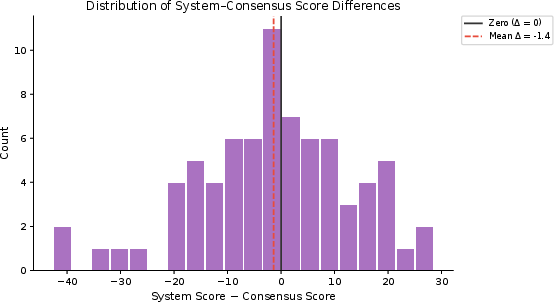
Figure 5: Distribution of system–consensus score differences, showing no systematic bias toward overscoring or underscoring.
Bland-Altman plots confirm tight agreement bounds, with divergence peaks attributable to veto gate collapses or rubric artifacts; system scores penalized structural/compliance failures that expert raters occasionally overlooked.
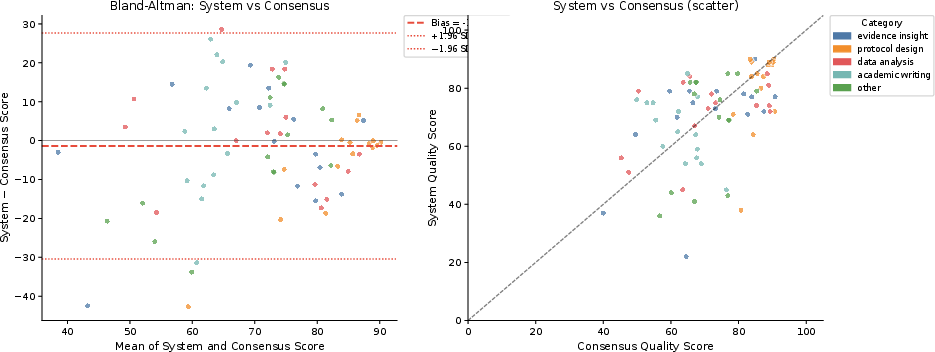
Figure 6: Bland-Altman and scatter plots for system–consensus score agreement; tight limits and near-zero mean bias.
Confusion matrices for disposition agreement highlight robust within-one-tier matching; exact rank agreement rates naturally reflect epistemic uncertainties in scoring.
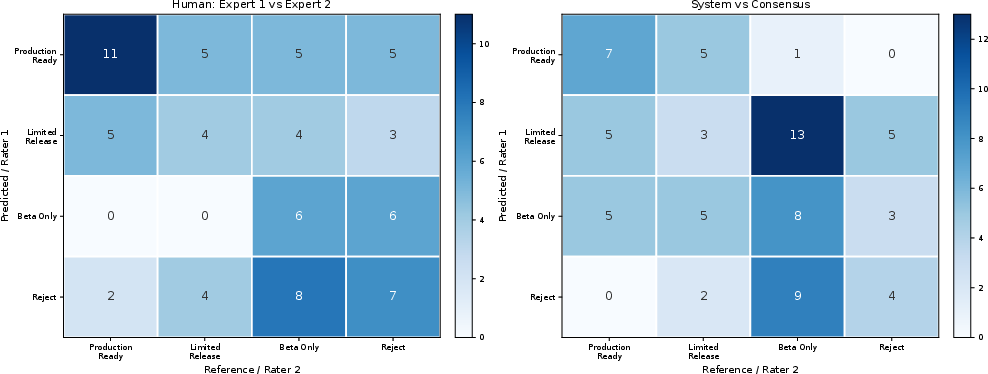
Figure 7: Confusion matrices for disposition rank agreement; system–consensus achieves strong within-tier reliability versus human baseline.
Stratified agreement analyses reveal highest reliability for Evidence Insight and Data Analysis, moderate for Protocol Design, and negative correlation in Academic Writing (system and expert scores move inversely). The latter reflects rubric–domain mismatch, particularly in penalizing “academic tone” and structural conventions valued by experts.
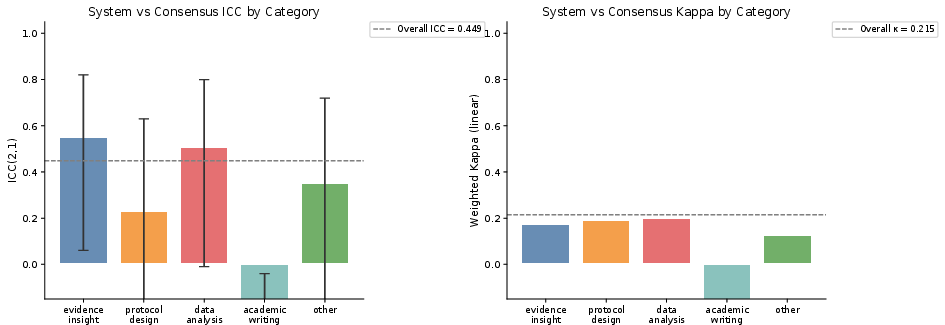
Figure 8: ICC and weighted κ stratified by category; negative values in Academic Writing diagnose rubric misalignment.
Category-level bias analysis confirms statistically significant underscoring for Protocol Design (mean Δ=−6.1, p=0.033), linked to inappropriate application of operational stability gates in prompt-only contexts.
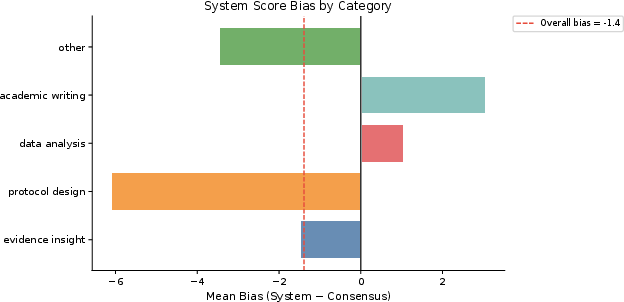
Figure 9: Mean system–consensus score bias per category, with Protocol Design showing significant underscoring.
Architectural and Practical Implications
MedSkillAudit distinguishes itself by targeting the artifact-level properties (code, schema, reproducibility, integrity) that generic capability benchmarks or agentic evaluation environments overlook. The framework’s two-gate design ensures catastrophic failures are not masked by strong outputs elsewhere. Its dynamic execution emphasis exposes real-world failure cases (unresolvable dependencies, broken APIs) that static reviews miss. Category-specific rubrics afford nuanced detection of domain risks, while ISO/IEC alignment supplies governance defensibility.
Scene override mechanisms enable institutions to adapt rubrics for domain sub-specialties without redesigning core pipeline—a critical requirement as medical research skills diversify.
Limitations and Prospective Developments
Limitations include modest per-category sample sizes (n=15), high adjudication rates due to absence of calibration, and rubric weighting mismatches for prompt-only skills. The negative ICC in Academic Writing is diagnostic; upcoming rubric adaptations aim to synthesize artifact and behavioral reliability measures. Future versions ([email protected]+) are planned to incorporate mode-adaptive weighting and more sophisticated scene overrides, improving reliability for new skill categories and execution modes.
MedSkillAudit’s iterative calibration pathway—refining rubrics category-by-category based on diagnostic failures—provides a principled mechanism for continuous improvement as the medical agent skill ecosystem evolves.
Conclusion
MedSkillAudit offers a scientifically grounded, operationally robust framework for pre-deployment audit and governance of medical agent skills. Automated evaluation achieves reliability comparable to expert review, identifying catastrophic and borderline failures with high fidelity. Its architecture and calibration methodology allow for adaptive extension to new skill categories, supporting scalable governance as medical agent systems mature from experimental tools to institutional infrastructure.