SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
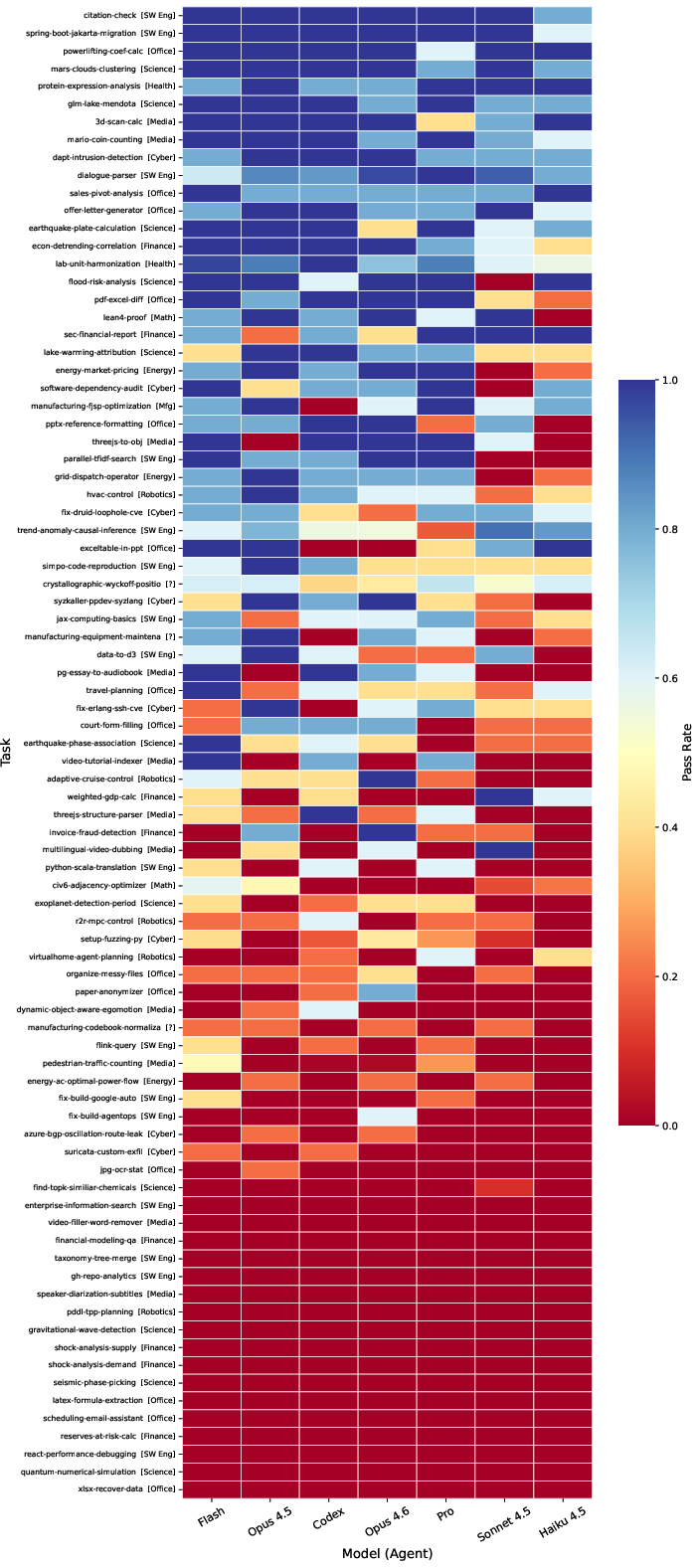
Abstract: Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SkillsBench: A simple explanation for teens
What is this paper about?
This paper introduces SkillsBench, a big test that checks whether giving AI “how‑to guides” (called Skills) actually helps them do real tasks better. Think of an AI agent like a smart assistant that can plan and run steps on a computer. A Skill is like a recipe or a playbook: short instructions, example code, and checklists that tell the AI exactly how to tackle a certain type of problem. The paper measures how much these Skills help across many different kinds of tasks.
What questions are the researchers asking?
The authors focus on a few easy-to-understand questions:
- Do Skills really help AI agents solve tasks better than trying without them?
- Are human-written Skills better than Skills the AI tries to write for itself?
- How many Skills are best—one, a few, or a lot?
- Do Skills help some areas (like healthcare) more than others (like software)?
- Can a smaller, cheaper AI with good Skills match or beat a larger AI without Skills?
How did they test it?
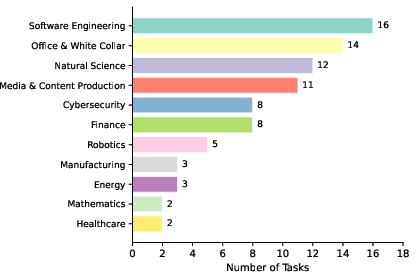
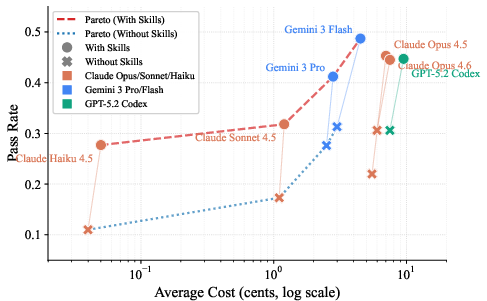
They built a benchmark (a standardized test) called SkillsBench with 84 tasks across 11 areas, like healthcare, finance, cybersecurity, energy, and software. Each task is set up like a self-contained “level” in a game:
- There’s a clear task description (what to do).
- Everything runs inside a controlled “box” on a computer (a container), so every AI sees the same setup.
- There’s an automatic checker (a deterministic verifier)—like a referee—that runs tests to see if the answer is truly correct.
- They prevent cheating: the Skills can’t include the exact answers for any task, just general procedures.
They ran each task under three conditions:
- No Skills: the AI just sees the task instructions.
- With Curated Skills: the AI gets a human-written how‑to guide plus helpful resources.
- With Self-Generated Skills: the AI is told to write its own how‑to guide before solving.
They tried 7 different AI-and-tool setups and ran 7,308 total attempts (called “trajectories”). The main score is pass rate: the percent of tasks the AI completes correctly. When they say “+16 percentage points,” they mean something like going from 30% correct to 46% correct.
What did they find, and why does it matter?
Here are the big takeaways:
- Curated Skills help a lot on average. Giving human-written Skills increased pass rates by about +16 percentage points overall. That’s a meaningful jump.
- But the benefit depends on the domain. Gains were much bigger in areas that rely on practical, step-by-step know‑how (like healthcare and manufacturing), and smaller in areas AIs are already good at (like math and software).
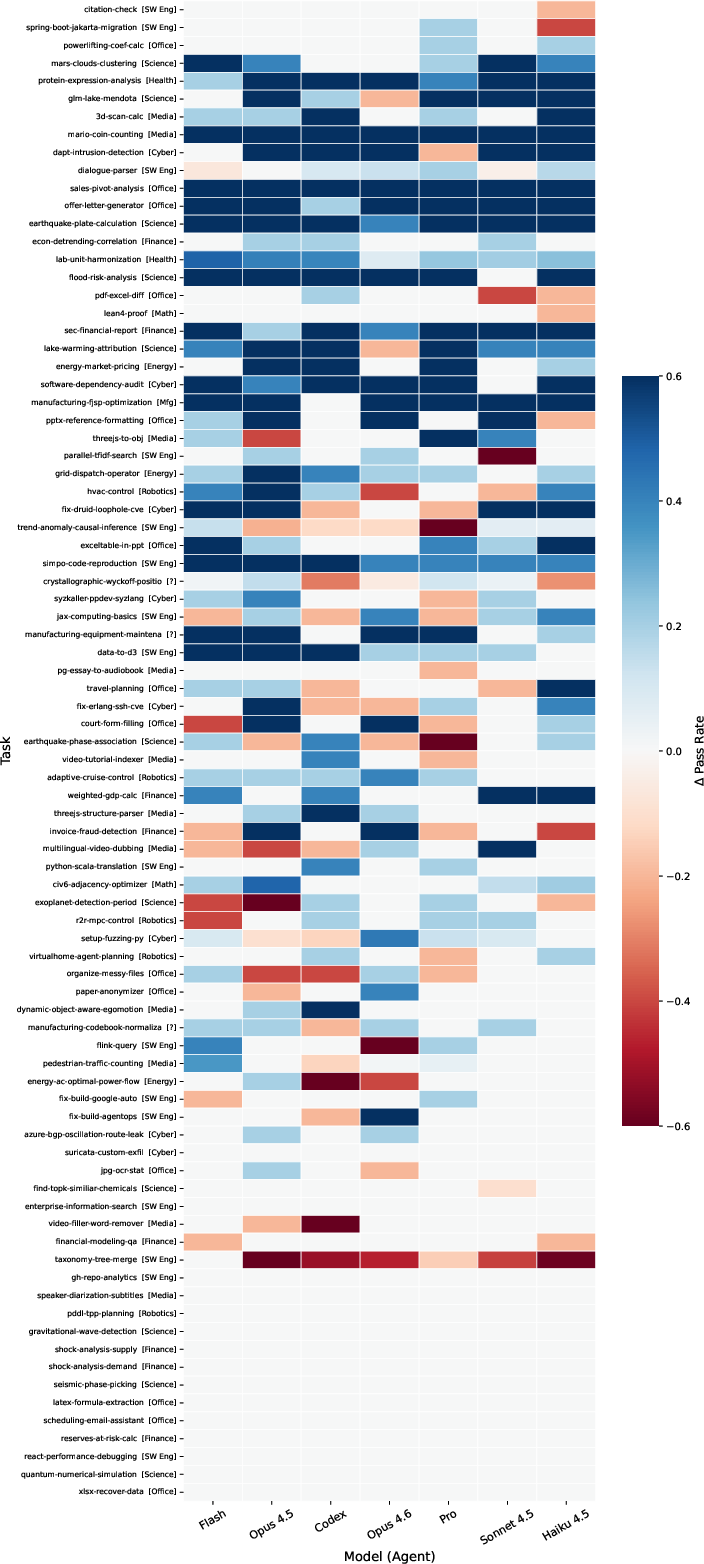
- Self-written Skills don’t help. When AIs tried to write their own how‑to guides, performance didn’t improve on average—and sometimes got worse. In other words, AIs benefit from clear procedures, but they’re not yet reliable at writing those procedures themselves.
- Less is more. The best setup was focused Skills with 2–3 modules. Huge “everything and the kitchen sink” documents often slowed the agent down or distracted it.
- Smaller models + good Skills can match bigger models without Skills. That means organizations might save money by pairing strong Skills with smaller AIs, instead of paying for the largest model.
Why this matters:
- It shows that giving AIs practical, bite-sized procedures (not just facts) can make them more reliable at real work.
- It helps people who build AI systems decide how to invest: write better Skills rather than just buying bigger models, especially in specialized areas.
- It highlights that good structure and clear steps are key—much like a well-written recipe is better than an entire cookbook dumped at once.
What’s the bigger impact?
If AI agents are like interns, Skills are like onboarding guides that teach them proven ways to work. This paper shows that:
- Good guides make interns (the AIs) faster and more accurate.
- Too much material can overwhelm them.
- Interns aren’t ready to write their own playbooks yet. With SkillsBench, the community now has a fair way to measure which Skills help, in which situations, and how much. That can lead to more dependable AI helpers in everyday jobs—from analyzing medical data to organizing spreadsheets—while keeping costs in check.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that SkillsBench leaves unresolved, organized to guide actionable follow-up research:
- Benchmark scope: Extend beyond terminal-based, containerized tasks to GUI agents, multimodal (vision–language) settings, and long-horizon workflows; define skill packaging and deterministic verifiers for these environments.
- Context-length confound: Quantify how much of the improvement comes from “more context” rather than procedural structure via length-matched controls (e.g., random/irrelevant text, tool documentation, RAG-only documents) and report effect sizes under strict context budgets.
- Skill-component attribution: Perform factorial ablations to isolate the marginal utility of SKILL.md instructions vs. code templates vs. executable scripts vs. worked examples; identify which components drive gains in which domains.
- Skill quantity and composition: Systematically study how multiple skills interact (synergy vs. interference), define composition guidelines, and build predictive models for composite performance from atomic skill effects.
- Self-generated skills protocols: Standardize and compare prompting strategies (iterative planning, self-reflection, retrieval-augmented authoring), evaluate the reusability and transferability of model-authored skills across tasks, and establish quality metrics for generated procedural content.
- Harness mediation and utilization: Instrument agent harnesses to log skill access and invocation; quantify skill utilization rate, measure reasons for non-use, and test harness modifications (e.g., retrieval, routing, reminders) that improve skill uptake.
- Domain representativeness: Audit domain/task distribution, report per-domain sample sizes, and add underrepresented professional domains; assess generalization to out-of-domain tasks and real-world datasets beyond curated containers.
- Metrics beyond pass rate: Track time-to-solution, number of actions/steps, tool calls, token usage, trajectory length, and error types; report variance, confidence intervals, and reliability across repeated runs to enable robust statistical conclusions.
- Determinism and contamination: Measure sensitivity to environment nondeterminism (dependencies, OS variance), detect training-set leakage more rigorously, and test replicability across seeds, versions, and offline evaluations.
- Reporting inconsistencies: Reconcile conflicting figures (e.g., 86 vs. 84 tasks; +16.2pp vs. +12.66pp average improvement), fix malformed normalized-gain equation, and correct placeholder labels in domain tables; provide a transparent errata and data release to support reproducibility.
- Skill discovery at scale: Evaluate agents’ ability to identify relevant skills in large repositories, measure cognitive load and retrieval performance, and design indexing/ranking mechanisms for large-scale skill ecosystems.
- Cost–performance methodology: Use official API pricing (and wall-clock compute) across providers to report standardized cost per task/trajectory; study how skills shift Pareto frontiers under equal budget constraints.
- Model-scale generality: Expand model families and scales to test whether “smaller model + skills” consistently matches/exceeds “larger model without skills” across domains and tasks; analyze scaling laws with and without skills.
- Skill quality rubric and reliability: Formalize a skill-quality rubric (procedural clarity, actionability, consistency, example coverage), measure inter-rater reliability, and correlate quality scores with observed gains; include lower-quality and automatically curated skills to assess ecosystem realism.
- Safety and compliance: Investigate whether skills can encode harmful or non-compliant procedures; add red-teaming tasks and domain-specific compliance checks (healthcare, finance, cybersecurity) with safety verifiers.
- Verifier robustness: Assess false pass/false fail rates, expand tests for edge cases and adversarial solutions, and publish verifier coverage metrics; explore semi-formal specifications to reduce “brittle” correctness criteria.
- Statistical rigor: Provide per-task and per-domain significance tests, adjust for multiple comparisons, and report confidence intervals for deltas and normalized gains; include power analyses for trajectory counts.
- Difficulty calibration: Validate human-provided difficulty labels with timed human trials and inter-rater agreement; analyze whether skill benefits differ across calibrated difficulty tiers.
- Multi-agent and collaboration: Examine how skills function in multi-agent coordination (division of labor, shared memory), and whether skill composability improves team performance.
- Memory and context constraints: Study skills under limited context windows, persistent memory stores, and long projects; measure forgetting, drift, and the effectiveness of periodic skill reminders.
- Cross-harness portability: Stress-test skill packages across heterogeneous harnesses and models (prompt formats, tool APIs, filesystem conventions) to quantify true portability and required adaptation.
- Parameter sensitivity: Analyze sensitivity to sampling temperature, reasoning frameworks (CoT vs. ReAct), and tool-use configurations; determine stable defaults for skills-augmented agents.
- RAG vs. skills: Directly compare procedural skills to retrieval-based augmentation and to tool documentation; evaluate hybrid strategies (RAG that fetches skills, skills that invoke retrieval) and when each is preferable.
- Negative-delta diagnosis: For tasks where skills hurt performance, perform root-cause analyses (conflicting guidance, overload, misalignment with harness) and derive concrete mitigation patterns (pruning, disambiguation, stepwise restructuring).
- Public artifacts for replication: Release full trajectories, verifiers, skill packages, harness configs, and injection formats; provide scripts for leakage audits and utilization tracking to enable third-party replication and extension.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that organizations can deploy now, derived from the paper’s benchmark findings and methodology.
- Skills-driven ROI evaluation for AI agents — industry, software, finance, healthcare
- Description: Use paired “with Skills vs. no Skills” evaluations and deterministic verifiers to quantify uplift before deploying agents in production.
- Tools/products/workflows: Internal SkillsBench-like harness built on Dockerized tasks with pytest verifiers; dashboards reporting pass rate deltas and normalized gain; A/B test pipelines.
- Dependencies/assumptions: Access to an agent harness that can inject Skills; engineering capacity to containerize tasks and write deterministic tests; representative tasks and data.
- Cost/performance optimization via model–skill pairing — industry, software, finance, energy
- Description: Replace larger models without Skills with smaller models + curated Skills to reduce cost while maintaining or improving performance.
- Tools/products/workflows: Pareto frontier dashboards (pass rate vs. cost), policy that defaults to “small model + Skills” for procedural tasks, token-budget governors.
- Dependencies/assumptions: Clear task classification as “procedural”; procurement/pricing visibility; harness supports robust Skills utilization.
- Proceduralization of SOPs into deployable Skills — healthcare, manufacturing, cybersecurity, finance, office/white-collar
- Description: Convert standard operating procedures and playbooks into concise SKILL.md packages with 2–3 focused modules and one working example.
- Tools/products/workflows: “Skills-as-code” repositories; SKILL.md authoring templates; examples/snippets folder; versioning and code review.
- Dependencies/assumptions: Subject-matter experts available to author and maintain Skills; IP/compliance review; organizational knowledge management support.
- Skills quality and governance pipeline — industry, regulated sectors, academia
- Description: Treat Skills as first-class artifacts with CI/CD: automated structural checks, oracle runs, leakage audits, and human review.
- Tools/products/workflows: Skills linting; automated oracle execution; leakage detectors (disallow task-specific constants/paths); reviewer checklists.
- Dependencies/assumptions: CI infrastructure; deterministic tests; governance policies defining acceptable content and change control.
- Harness selection and configuration for better Skills utilization — software, platform teams
- Description: Choose agents/harnesses that reliably retrieve and apply Skills (e.g., those that showed higher utilization in the benchmark) and add telemetry to detect neglect of Skills.
- Tools/products/workflows: Harness adapters with Skills injection, usage logs (which Skills were read/invoked), “skill-use required” gates on critical tasks.
- Dependencies/assumptions: Access to multiple harness options; observability hooks; alignment between vendor features and Skills spec.
- Domain-targeted Skills rollouts (prioritize high-uplift areas) — healthcare, manufacturing, cybersecurity, natural science, energy, finance
- Description: Start with domains where curated Skills delivered the largest gains in the benchmark (e.g., healthcare +51.9pp; manufacturing +41.9pp).
- Tools/products/workflows: Roadmaps for domain-specific Skills (e.g., clinical data harmonization, SPC analysis, grid data pipelines, SEC report parsing, SOC playbooks).
- Dependencies/assumptions: Domain datasets for testbeds; SME availability; regulatory review where required.
- Documentation refactoring to “Focused Skills” — industry, education
- Description: Trim exhaustive docs into concise, stepwise guidance with examples (2–3 modules) to avoid context overload and conflicts.
- Tools/products/workflows: Doc-to-Skill refactoring sprints; editorial guidelines enforcing length and structure; content linting for actionability.
- Dependencies/assumptions: Willingness to deprecate long-form docs in agent-facing contexts; change management for teams.
- Disable “self-generated Skills” for critical workflows — industry, regulated sectors
- Description: Prevent models from auto-authoring procedures on the fly and require human-curated Skills for safety and efficacy.
- Tools/products/workflows: Policy switches in harness to forbid self-generated procedures; allow only approved Skills packages.
- Dependencies/assumptions: Mature Skills library; enforcement in agent policy layers; clear exception processes.
- Compliance and safety embedding — healthcare, finance, cybersecurity
- Description: Encode compliance checks and verifier-friendly guardrails as Skills; produce audit trails linking Skills usage to outcomes.
- Tools/products/workflows: Compliance Skill suites (e.g., HIPAA/PII redaction steps, KYC/AML checks, incident response playbooks) with deterministic checks.
- Dependencies/assumptions: Up-to-date regulatory content; legal sign-off; evidence capture for audits.
- Education and research reproducibility kits — academia
- Description: Use containerized tasks with verifiers to teach reproducible agent evaluation and procedural writing; run lab assignments as Skills packages.
- Tools/products/workflows: Course repos mirroring SkillsBench structure; student-authored Skills with leakage audits; grading via deterministic tests.
- Dependencies/assumptions: Instructor capacity to prepare containers/tests; student familiarity with CLI and version control.
- Office/white-collar productivity Skills — daily life, enterprise ops
- Description: Package routine workflows (e.g., sales pivot analysis, monthly reporting, CSV cleanup) into reusable Skills for personal/departmental assistants.
- Tools/products/workflows: Team Skills libraries for spreadsheets, email templates, report generation; task runners invoking scripts/examples.
- Dependencies/assumptions: Access to an agent that can read local files and run scripts; data privacy controls.
- Cybersecurity incident-response Skills — cybersecurity
- Description: Codify triage and containment procedures into procedural Skills with verification (e.g., log parsing, IOC extraction, playbook steps).
- Tools/products/workflows: SOC Skills bundles; test harnesses with red-team scenarios and assertions.
- Dependencies/assumptions: Controlled lab data; secure execution environments; oversight by security engineers.
- Data science workflow Skills — media/content, science/engineering
- Description: Provide agent-ready pandas/matplotlib workflows and code templates for EDA, plotting, and data cleaning.
- Tools/products/workflows: Example notebooks converted to scripts/templates; dataset-specific preflight checks as verifiers.
- Dependencies/assumptions: Library/tooling availability in containers; data licensing; deterministic evaluation.
Long-Term Applications
The following opportunities require additional research, scaling, standardization, or ecosystem development before broad deployment.
- Automated skill synthesis and refinement from user traces — software, enterprise knowledge management
- Description: Learn Skills from execution logs, demos, or PRs; auto-summarize into focused SKILL.md with examples; enforce length and actionability.
- Tools/products/workflows: Trace-to-skill miners; length-matched evaluation controls; human-in-the-loop editors.
- Dependencies/assumptions: High-quality telemetry; privacy-preserving logging; reliable summarization and de-duplication.
- Skill selection, composition, and planning agents — cross-sector
- Description: Meta-controllers that choose which Skills to load/apply, resolve conflicts, and adapt granularity based on task and context budget.
- Tools/products/workflows: Skill routers; conflict detectors; adaptive summarization; composition graphs with success predictors.
- Dependencies/assumptions: Standardized Skill metadata; harness APIs for dynamic loading; evaluation datasets measuring composition effects.
- Multimodal and GUI/robotics Skills — robotics, operations, design
- Description: Extend Skills to vision-language and GUI agents for tool use, RPA, and robot task sequencing with procedural checks.
- Tools/products/workflows: GUI/vision Skill spec; simulator-backed verifiers; ROS/PLC integration Skills; screen-state validators.
- Dependencies/assumptions: Stable multimodal APIs; deterministic oracles for non-text environments; safety envelopes.
- Skills standards and certification — policy, regulated industries
- Description: Establish cross-vendor packaging standards and certification regimes for safety-critical Skills (e.g., medical coding, grid operations).
- Tools/products/workflows: Standards bodies defining Skill schema, test coverage, leakage controls; third-party cert labs.
- Dependencies/assumptions: Industry coordination; regulator engagement; compliance frameworks harmonized across jurisdictions.
- Skill marketplaces with reputation and telemetry — industry ecosystem
- Description: Curated marketplaces where Skills are discoverable, versioned, rated by normalized gain, and auto-tested on public benchmarks.
- Tools/products/workflows: Skill registries; reputation systems; continuous benchmark badges; dependency resolution.
- Dependencies/assumptions: IP/licensing models; scalable validation infra; incentives for high-quality contributions.
- Safety and verification advances for procedural augmentation — policy, safety engineering
- Description: Formal methods and static analyzers to detect leakage, unsafe commands, and non-deterministic behaviors in Skills; provable guardrails.
- Tools/products/workflows: Static/dynamic Skill analyzers; differential testing; formal specifications for critical routines.
- Dependencies/assumptions: Formal languages for procedural specs; verified toolchains; integration with harness policy engines.
- Organizational knowledge-to-Skills pipelines — enterprise KM
- Description: Continuous conversion of wikis/tickets/runbooks into validated Skills with testers and change tracking; “living SOPs” maintained via CI.
- Tools/products/workflows: ETL from knowledge bases; reviewer queues; drift detection (Skills vs. actual systems).
- Dependencies/assumptions: Clean, current knowledge sources; change management; stakeholder incentives.
- Skill-aware resource schedulers and cloud policies — IT/FinOps
- Description: Orchestrators that select model size and Skills set jointly to meet SLAs and budget constraints.
- Tools/products/workflows: Schedulers optimizing pass-rate-per-dollar; policy engines preferring “small model + right Skills.”
- Dependencies/assumptions: Accurate cost/perf telemetry; predictable workloads; robust fallback strategies.
- Expanded benchmarks for long-horizon and multi-agent workflows — academia, industry R&D
- Description: SkillsBench extensions to collaborative tasks, GUI environments, and very long horizons with robust oracles and leakage controls.
- Tools/products/workflows: Multi-agent containers; coordination verifiers; benchmark suites with composition metrics.
- Dependencies/assumptions: New evaluation primitives; reproducibility at longer horizons; community contributions.
- Education: Skills-first curricula and credentialing — education, workforce development
- Description: Degrees/micro-credentials focused on procedural authoring for AI agents; capstones that publish certified Skills.
- Tools/products/workflows: Courseware aligned to Skills standards; student marketplaces; employer-validated assessments.
- Dependencies/assumptions: Academic–industry partnerships; assessment reliability; adoption by employers.
- Consumer-grade personal Skills — daily life
- Description: End-user tools to create/share “home Skills” (tax prep, budgeting, photo curation) with privacy-preserving local evaluation.
- Tools/products/workflows: No-code Skill builders; local-orchestrated verifiers; private marketplace among trusted peers.
- Dependencies/assumptions: Consumer-friendly harnesses; on-device runtimes; straightforward privacy controls.
- Policy-driven procurement and oversight — public sector, critical infrastructure
- Description: Require Skills-centric, paired evaluations for AI procurements and ongoing audits; mandate leakage audits and deterministic verifiers.
- Tools/products/workflows: Procurement templates; audit checklists; reference test suites per domain.
- Dependencies/assumptions: Policy frameworks; testing capacity; vendor cooperation.
Notes on feasibility dependencies across applications:
- Effective Skills require human-curated, procedural content; self-generated procedures are not reliable today.
- Harness behavior materially affects outcomes; integration quality and Skills retrieval are critical.
- Deterministic, execution-based verification and containerization underpin trustworthy evaluation but add engineering overhead.
- Context-window limits and token costs constrain Skills length; focused, high-signal content is preferable.
- Regulatory and IP considerations must be addressed for sector-specific SOPs.
Glossary
- agent harness: A runtime system that manages context, tools, and interactions for an LLM agent. "agent harnesses orchestrate context and tools (operating systems)"
- Agent Skills: Structured, reusable packages of procedural guidance and resources that augment agent behavior at runtime. "Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time."
- agent-model configuration: A specific pairing of an agent harness with a particular model for evaluation. "We test 7 agent-model configurations over 7,308 trajectories."
- baseline augmentation: Non-Skills context added to a model to improve performance, used as a comparison baseline. "How much do Skills help compared to baseline augmentation?"
- ceiling effects: When performance is near the maximum, making improvements difficult to detect. "These represent different phenomena (ceiling effects vs.\ genuine scaffolding)."
- cognitive architecture: A structured design for an agent’s reasoning and control processes. "and cognitive architectures for language agents"
- containerized: Packaged to run inside an isolated container with its dependencies. "each task adopts a containerized structure"
- context budget: The limited amount of context an agent can process, often measured in tokens. "overly elaborate Skills can consume context budget without providing actionable guidance."
- curated Skills: Human-authored and vetted Skills provided to the agent. "Curated Skills raise average pass rate by 16.2 percentage points(pp)"
- deterministic sampling: Generation with fixed randomness (e.g., temperature 0) to ensure repeatability. "All models use temperature 0 for deterministic sampling."
- deterministic verifier: A fixed, programmatic test that yields the same pass/fail result given the same outputs. "paired with curated Skills and deterministic verifiers."
- Docker: A container platform used for reproducible, isolated environments. "A Docker container with task-specific data files and a skills/ subdirectory"
- execution-based evaluation: Scoring by running code/tests rather than subjective judgments. "following execution-based evaluation best practices"
- foundation model: A large pretrained model providing broad base capabilities for downstream tasks. "foundation models provide base capabilities (analogous to CPUs)"
- frontier model: A state-of-the-art, most capable model at the time of evaluation. "We select seven frontier models"
- inference time: The phase when a model generates outputs for a task. "augment LLM agents at inference time."
- leakage audit: A check to ensure Skills don’t encode task-specific answers or test details. "conduct leakage audits to ensure Skills provide guidance rather than solutions."
- LLM-as-a-judge: An evaluation setup where an LLM grades outputs, which can introduce variance or bias. "without LLM-as-a-judge variance"
- normalized gain: A metric measuring proportional improvement relative to the maximum possible score. "Normalized gain has known limitations:"
- options framework: A reinforcement learning framework for temporally extended actions (options). "builds on the options framework for temporal abstraction"
- oracle solution: A reference implementation known to solve the task correctly. "and an oracle solution."
- Pareto frontier: The set of configurations not dominated on multiple objectives (e.g., cost vs. performance). "Pareto frontier of pass rate vs.\ cost across model-harness configurations."
- procedural knowledge: Know-how about steps, workflows, and processes, rather than static facts. "Skills encode procedural knowledge"
- RAG retrieval: Retrieval-Augmented Generation; fetching documents to inform generation. "RAG retrievals~\citep{lewis2021retrievalaugmentedgenerationknowledgeintensivenlp}"
- scaffolding: Structured guidance that helps a model perform multi-step tasks. "ceiling effects vs.\ genuine scaffolding"
- self-generated Skills: Procedural guidance authored by the model itself before solving. "Self-generated Skills provide no benefit on average"
- standard operating procedure (SOP): A formal, step-by-step procedure for consistent task execution. "standard operating procedures, domain conventions"
- temporal abstraction: Representing multi-step behaviors as higher-level actions spanning time. "options framework for temporal abstraction"
- trajectory: A recorded sequence of agent actions and states during a single task attempt. "7,308 trajectories."
- verifier: The program that checks whether outputs satisfy deterministic success criteria. "The verifier then executes deterministic assertions to produce a binary pass/fail outcome."
Collections
Sign up for free to add this paper to one or more collections.