- The paper introduces a closed-loop framework that automates the mining, packaging, and validation of agent skills from over 394 heterogeneous resources.
- It demonstrates significant performance gains on benchmarks like MoSciBench, with improvements in Repo-Acc and Paper-Acc compared to baseline agents.
- The framework structures skills hierarchically and supports transparent provenance tracking via an interactive dashboard for robust, scalable knowledge evolution.
SKILLFOUNDRY: Automated Construction and Evolution of Agent Skill Libraries from Heterogeneous Scientific Resources
Introduction
The fragmentation of procedural knowledge across diverse scientific resources presents a substantial barrier to the operationalization of capable, reliable scientific agents. While scientific know-how is pervasive in repositories, documentation, code, and literature, most resources are unstructured and inaccessible to automated systems. "SKILLFOUNDRY: Building Self-Evolving Agent Skill Libraries from Heterogeneous Scientific Resources" (2604.03964) addresses this by introducing a closed-loop framework, SKILLFOUNDRY, which mines, structures, and maintains agent-usable skills from varied sources. These skills encapsulate explicit operational contracts and are validated through multi-stage testing, addressing practical limitations in existing hand-crafted or tool-centric libraries.
Methodology
SKILLFOUNDRY employs a domain knowledge tree as both structural prior and dynamic controller for the iterative mining and refinement process. Internal nodes denote domains/subdomains, and leaves correspond to actionable skill targets, with each node maintaining state over resource coverage, skill validation, and task novelty. The framework operates as a staged pipeline:
- Branch Prioritization: High-value, under-covered branches are prioritized for targeted resource mining, leveraging current coverage and external signals.
- Resource Mining: The system retrieves and prioritizes authoritative resources (e.g., repositories, APIs, papers) contextually relevant to the chosen branch.
- Skill Extraction and Packaging: Candidate skills are induced by extracting operational contracts, including scope, IO signatures, dependencies, and provenance. These are compiled into executable, metadata-rich skill packages.
- Hierarchical Validation: Candidate skills undergo execution, system, and synthetic-data testing to ensure reliability in varying infrastructure contexts and under controlled conditions.
- Tree Refinement: Empirical evaluation dictates tree expansion for validated skills and consolidation/pruning for redundant or low-value nodes.
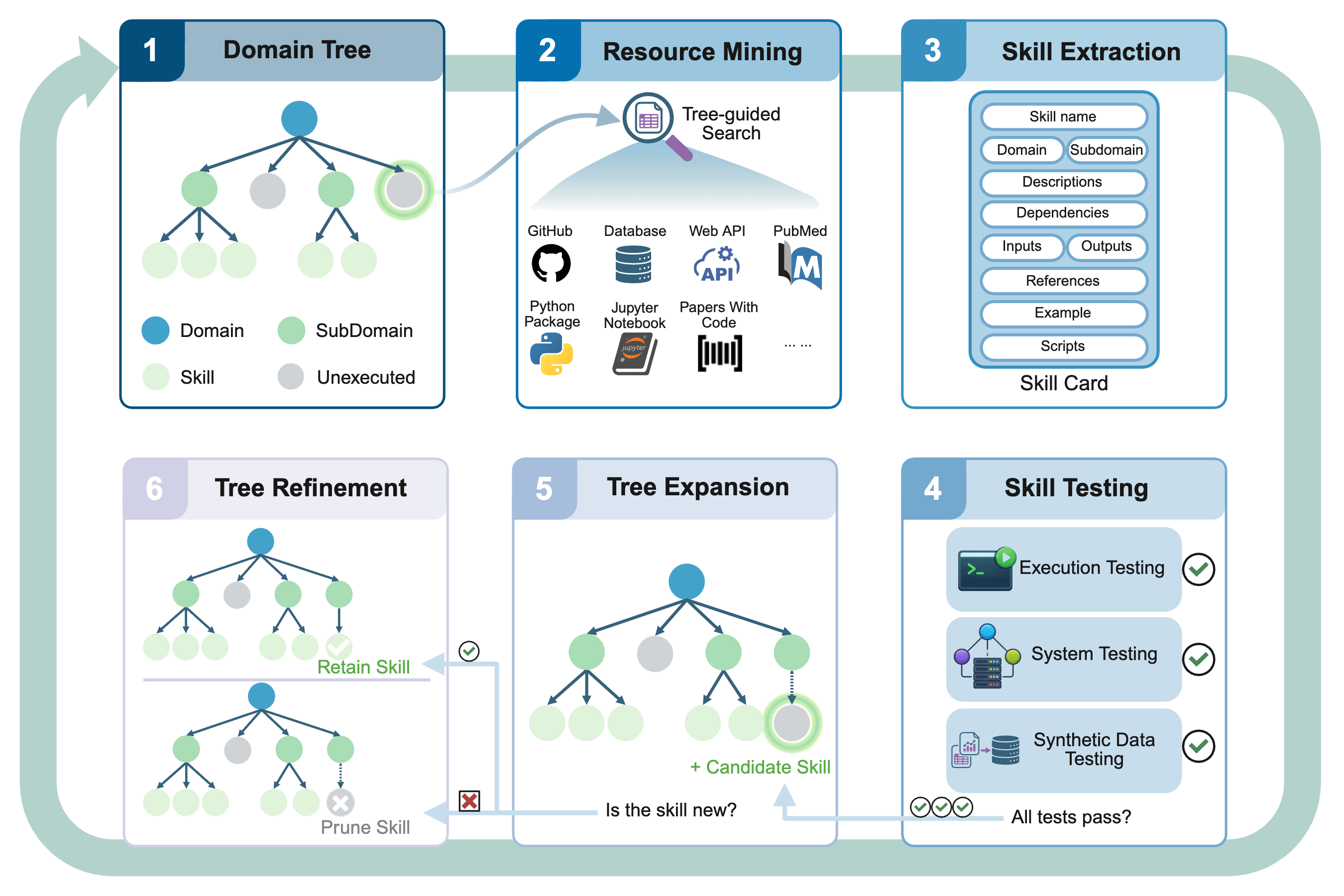
Figure 1: Overview of SKILLFOUNDRY’s pipeline from knowledge tree initialization through resource mining, skill extraction, validation, and tree refinement.
Composition and Efficiency of the Skill Library
At the point of evaluation, SKILLFOUNDRY's library contains 286 skills spanning 27 domains and 254 subdomains, mined from 394 heterogeneous resources. Internal validation ensures 100% executability for all retained skills. Notably, 71.1% of the mined skills are novel by stringent task-equivalence criteria relative to existing libraries such as SkillHub and SkillSMP, with the remainder merged or discarded according to redundancy detected in the novelty review.
Pipeline runtime analysis shows that skill extraction and resource mining are the principal computational costs, while validation and tree updates are comparatively efficient. Controlled exploration budgets further regulate the acquisition overhead.
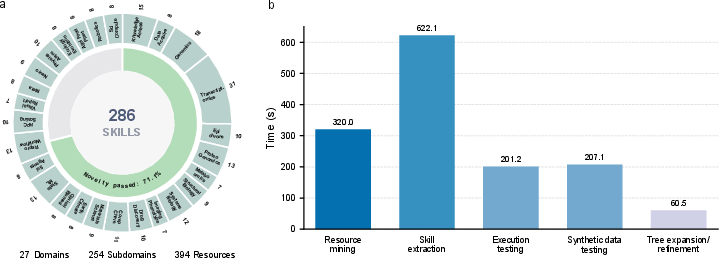
Figure 2: Statistical composition of the skill library across domains and subdomains (left); average runtime for major pipeline stages (right).
Benchmark and Task-Level Evaluation
MoSciBench
Evaluation on MoSciBench—an agent benchmark encompassing six datasets across climate, biomedical, genomics, and related sciences—demonstrates that integration of SKILLFOUNDRY skills improves agent performance on five out of six datasets. Inclusion of these skills increases average Repo-Acc from 61.19% to 66.73%, and Paper-Acc from 43.85% to 53.05%, with execution success consistently at 100%. The untouched performance on "nurse stress" is attributed to the already high baseline on this task. The gains confirm utility beyond execution, supporting improved reasoning, workflow integration, and domain coverage.
Task-Specific Skill Synthesis
Cell Type Annotation in Spatial Transcriptomics
SKILLFOUNDRY demonstrates the ability to synthesize new, concrete skills from task prompts—for example, annotating cell types in spatial transcriptomics. Codex, equipped with a synthesized marker-signature-based workflow (PCA, Leiden clustering, centroid similarity, rule-based refinement, and neighborhood validation), achieves 99.2% coverage and 82.9% accuracy, outperforming vanilla Codex (81.1%/68.5%). Although a domain-specific agent (SpatialAgent) reaches 100%/87.1% by additionally leveraging external reference datasets, the improvements from the SKILLFOUNDRY-generated skill are substantial.
Figure 3: UMAP visualization of cell-type annotation from ground truth, Codex, Codex+SKILLFOUNDRY, and SpatialAgent, with harmonized major cell type labels.
scDRS Workflow for Disease Association
For the scDRS workflow, which links GWAS and single-cell data, SKILLFOUNDRY-generated skills enhance the generalist biomedical agent Biomni. With these skills, Biomni is the only setting to satisfy all qualitative evaluation criteria (returning comprehensive multi-level analyses and interpretable visualizations), and achieves a mean RMSE reduction from 0.11 to 0.02 versus expert reference results, with two runs exactly matching expert output. The baseline agent without these skills frequently omitted key workflow parameters, resulting in lower quality and incomplete outputs.
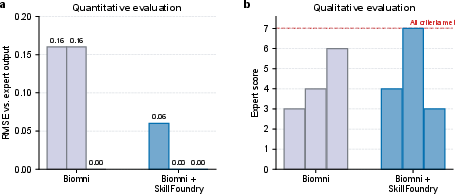
Figure 4: RMSE (left) and expert-derived qualitative scores (right) for the scDRS workflow, showing superior performance for Biomni with SKILLFOUNDRY-generated skills.
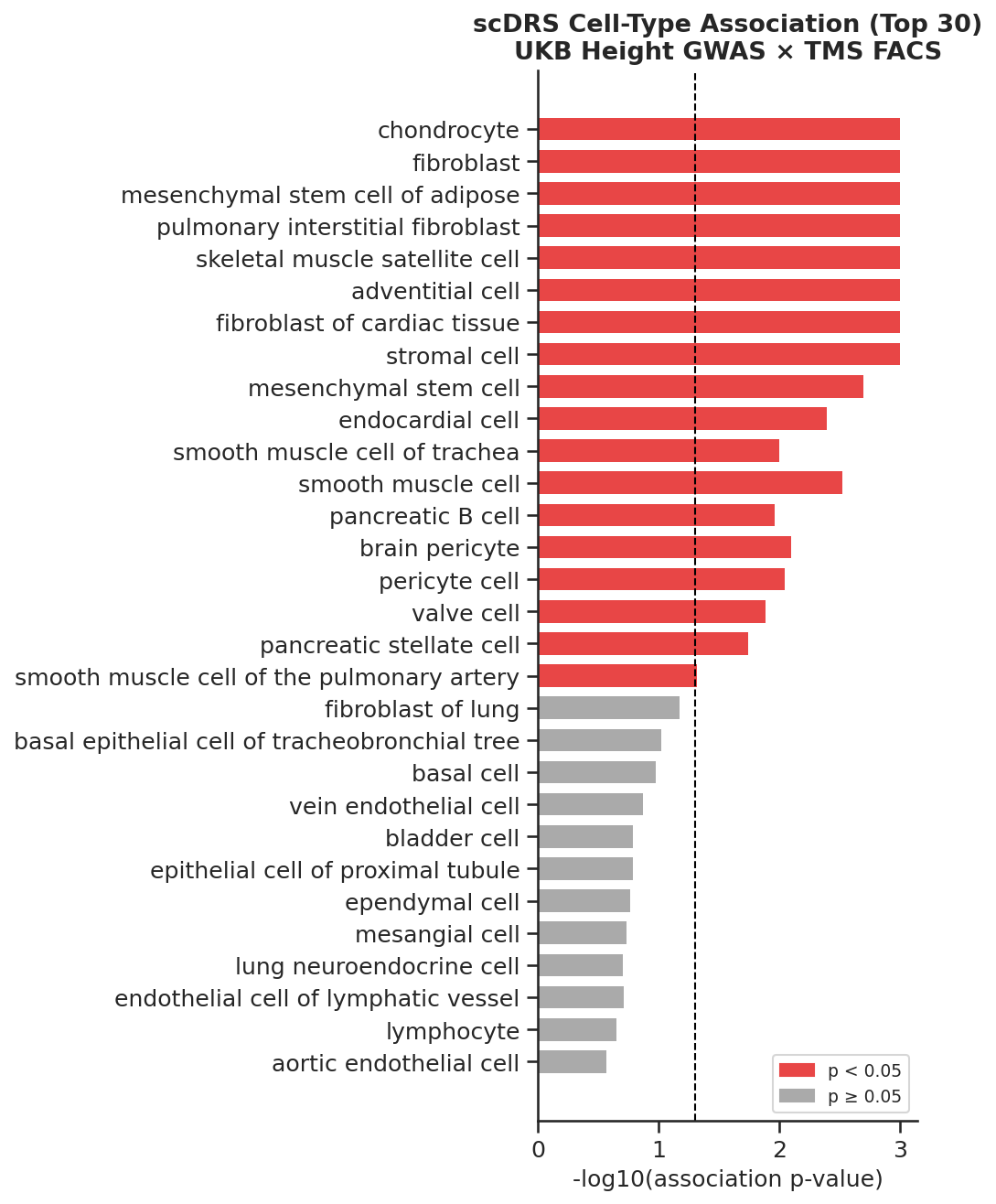
Figure 5: Basic scDRS output from Biomni without SKILLFOUNDRY—ranking cell types by association only.
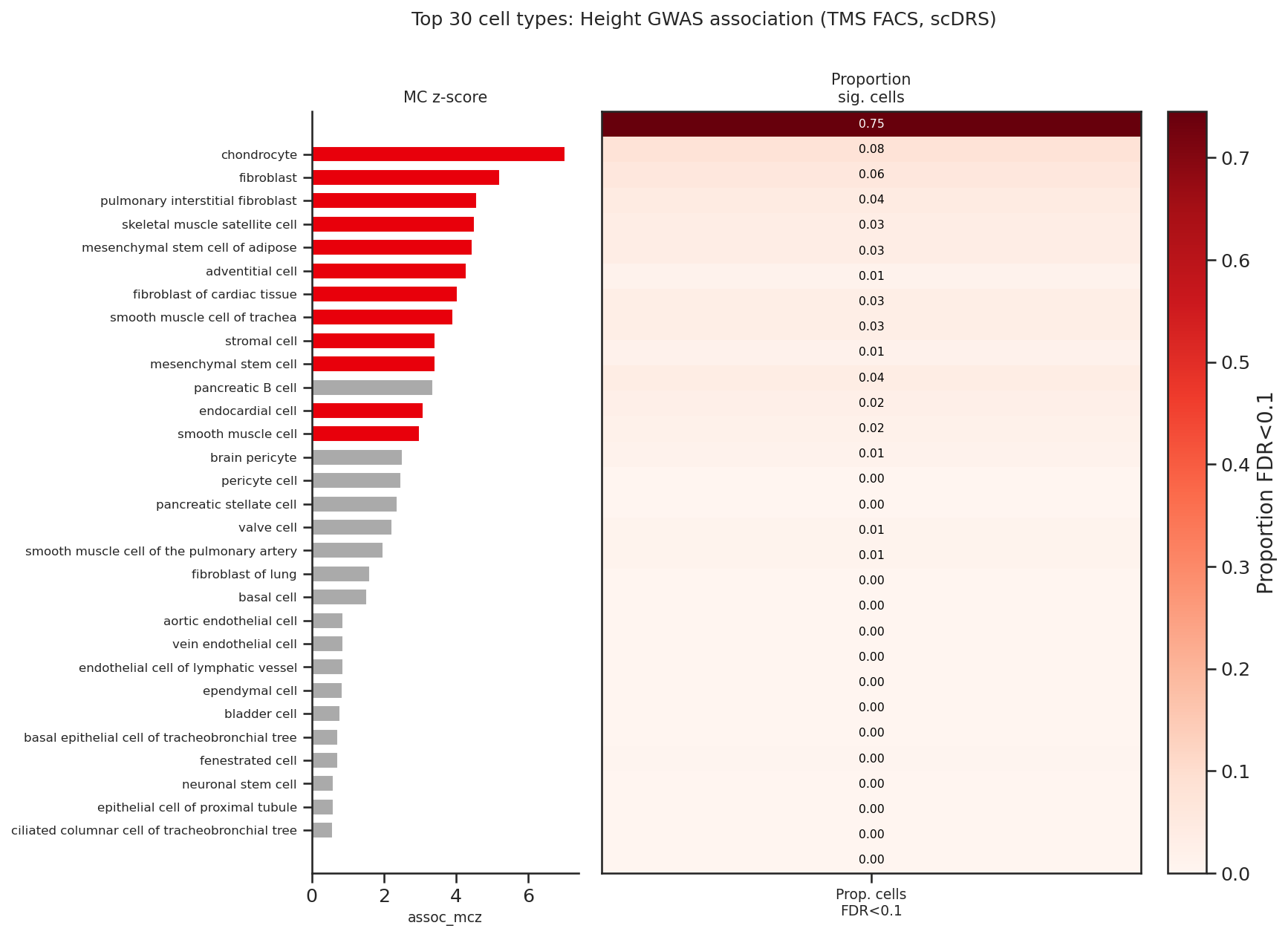
Figure 6: Enhanced scDRS output from Biomni with SKILLFOUNDRY—adding cell-level FDR significance supporting richer interpretability.
Library Management and Provenance
The framework presents a web dashboard designed for interactive exploration, querying, and analysis of the ever-evolving skill library. The dashboard surfaces the domain-specific taxonomy, metadata, provenance, and validation status for each skill, supporting robust transparency and downstream auditing.
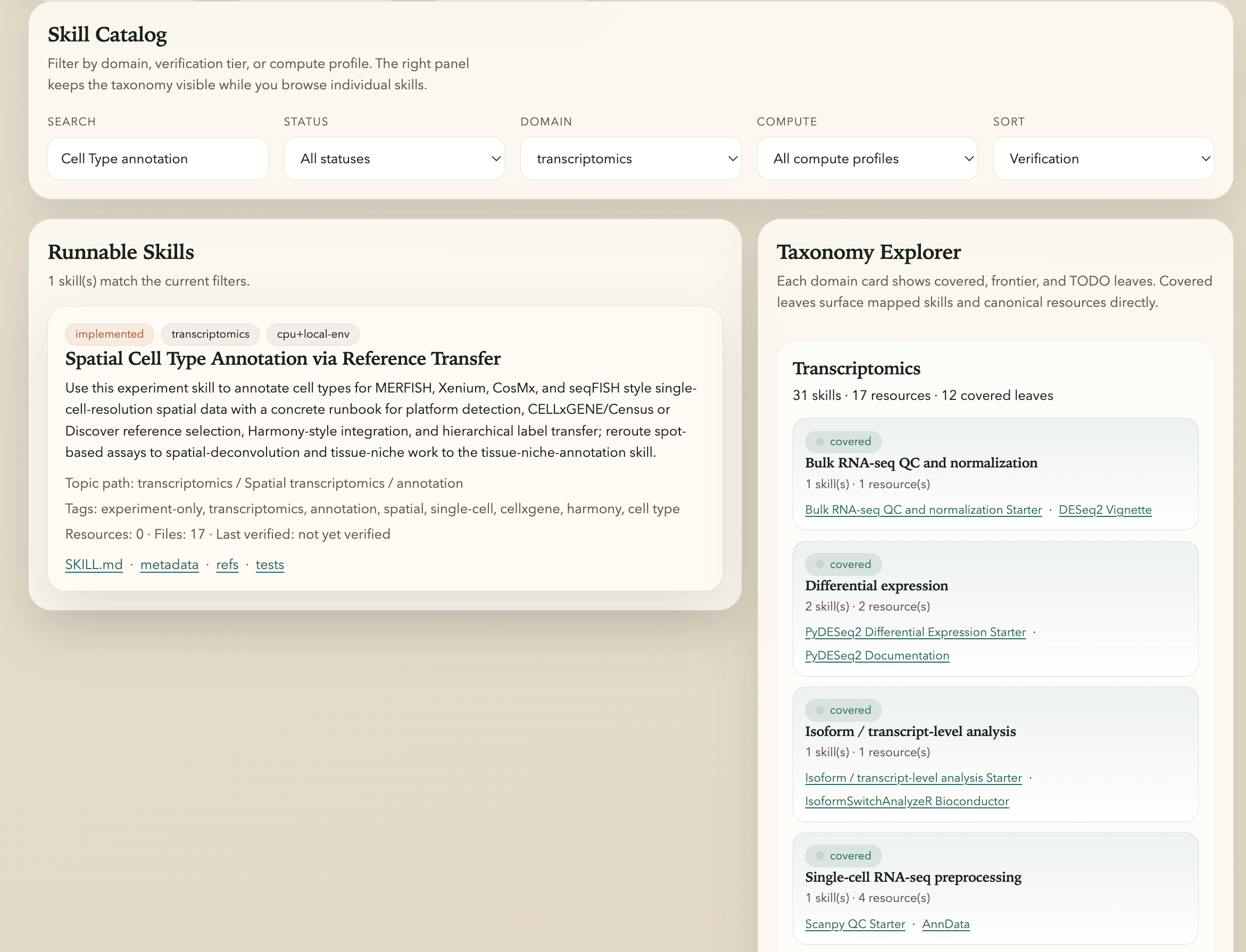
Figure 7: Dashboard screenshot highlighting cell type annotation skill metadata, taxonomy position, and resource links.
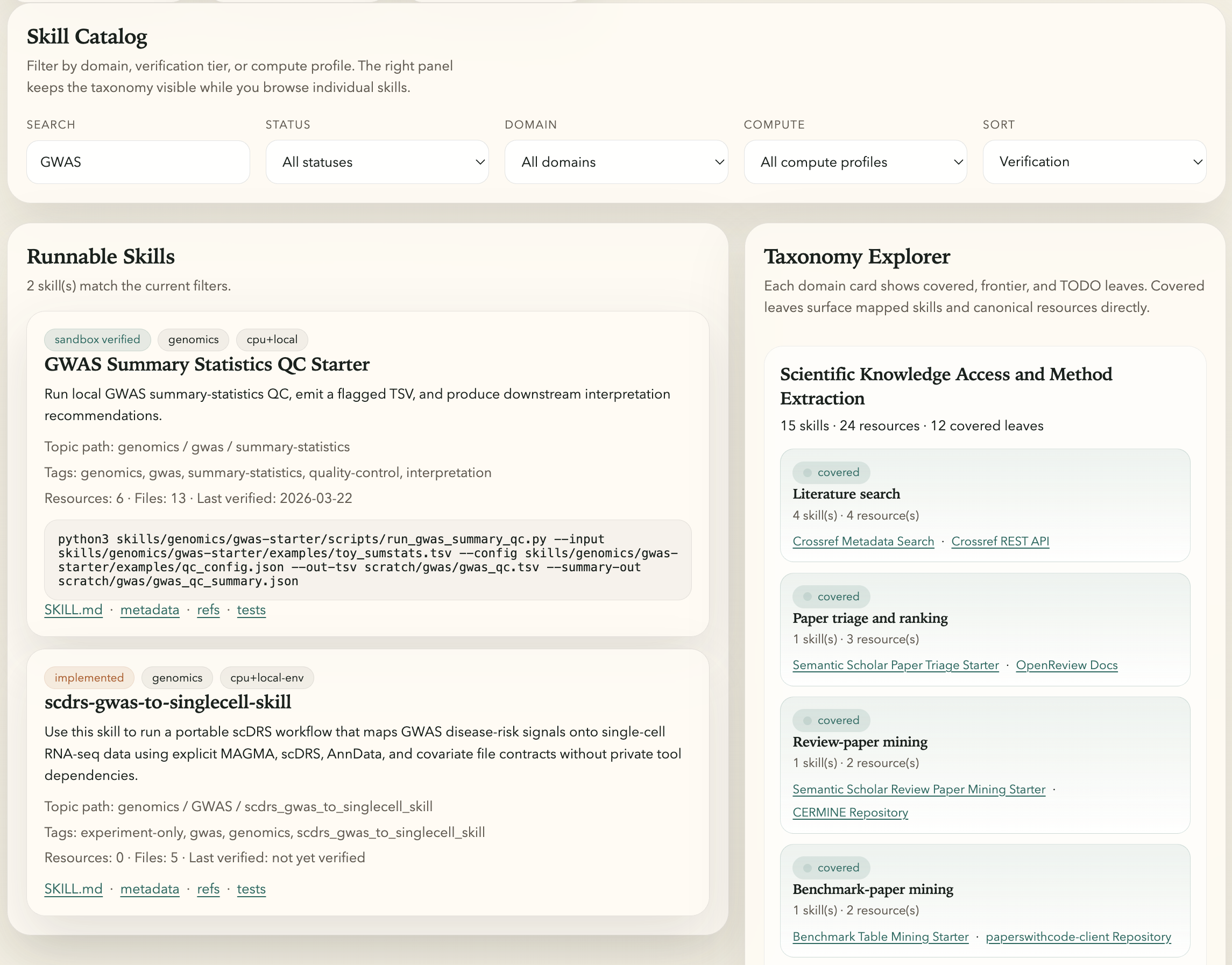
Figure 8: Dashboard screenshot of searchable, filterable scDRS-related skills with verification and provenance metadata.
Implications and Future Directions
SKILLFOUNDRY establishes a generalizable, protocol-rich methodology for augmenting agent capabilities directly from scientific domain artifacts. The strong quantitative performance improvement and high library novelty index challenge the assumption that hand-curated or tool-centric repositories are sufficient for advanced agentic workflows in science. The iterative, validation-driven design enables robust adaptation and minimizes the risk of propagating incomplete or redundant abstractions.
Limitations remain in domain coverage and resource diversity, reflecting the necessity for continuous expansion and community-informed evaluation. Prospective directions include extension to underrepresented scientific domains, enhanced coverage of infrastructure-dependent skills, and combining automated acquisition with expert curation workflows. Broader adoption could accelerate the operationalization of multimodal, multi-domain scientific agents and foster a robust ecosystem around reusable, validated procedural knowledge.
Conclusion
SKILLFOUNDRY represents a systematic effort to operationalize scientific procedural knowledge for agentic workflows by automating the discovery, structuring, testing, and evolution of agent-usable skills from heterogeneous resources. The resulting libraries deliver high internal validity, strong task-level improvements on both standardized and domain-specific benchmarks, and substantial extension beyond existing curated repositories. The approach presents a scalable paradigm for enhancing the reliability, coverage, and evolvability of scientific agents.

