Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Abstract: The rise of AI agent frameworks has introduced agent skills, modular packages containing instructions and executable code that dynamically extend agent capabilities. While this architecture enables powerful customization, skills execute with implicit trust and minimal vetting, creating a significant yet uncharacterized attack surface. We conduct the first large-scale empirical security analysis of this emerging ecosystem, collecting 42,447 skills from two major marketplaces and systematically analyzing 31,132 using SkillScan, a multi-stage detection framework integrating static analysis with LLM-based semantic classification. Our findings reveal pervasive security risks: 26.1% of skills contain at least one vulnerability, spanning 14 distinct patterns across four categories: prompt injection, data exfiltration, privilege escalation, and supply chain risks. Data exfiltration (13.3%) and privilege escalation (11.8%) are most prevalent, while 5.2% of skills exhibit high-severity patterns strongly suggesting malicious intent. We find that skills bundling executable scripts are 2.12x more likely to contain vulnerabilities than instruction-only skills (OR=2.12, p<0.001). Our contributions include: (1) a grounded vulnerability taxonomy derived from 8,126 vulnerable skills, (2) a validated detection methodology achieving 86.7% precision and 82.5% recall, and (3) an open dataset and detection toolkit to support future research. These results demonstrate an urgent need for capability-based permission systems and mandatory security vetting before this attack vector is further exploited.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a new kind of “add-on” for AI tools called agent skills. Think of agent skills like apps or plug-ins that you can install to give an AI extra abilities (for example, to read files, run code, or connect to websites). The authors wanted to know: are these add-ons safe? They collected tens of thousands of skills from public marketplaces and checked them for security problems. Their main finding is that more than a quarter of these skills have weaknesses that could let bad actors steal data, gain extra control, or sneak in harmful code.
Key Questions
The researchers focused on three simple questions:
- What kinds of security problems show up in real agent skills?
- How common are these problems across different types of skills?
- Are some types of skills riskier than others, and what patterns do risky skills share?
Methods (Explained Simply)
To study this at scale, they built a tool called SkillScan. Here’s how it works, using everyday analogies:
- Data collection: They visited two big marketplaces of agent skills (like app stores) and downloaded 42,447 skills. After removing duplicates and low-quality items, they analyzed 31,132 unique skills.
- Static analysis (rule-based checking): Imagine a spell-checker that scans text for suspicious words. SkillScan has a “rulebook” that flags risky patterns in code and instructions, like:
- Using “sudo” (which means elevated system power),
- Sending data to external websites,
- Running downloaded scripts directly (“curl | bash”),
- Accessing secret files (like SSH keys).
- LLM-based checking (context understanding): Rules can miss sneaky tricks. So they also used an AI-powered checker that “reads” the skill’s text and code and judges intent. This helps catch things like:
- “Prompt injection” (instructions that try to trick the AI into ignoring safety),
- Hidden or obfuscated content,
- Language that encourages unsafe actions.
- Hybrid decision: First, the rule-based scan or AI scan flags “candidates.” Then a more careful AI review confirms whether the finding is truly risky. This step tries to reduce false alarms while still catching most bad cases.
- Validation (making sure the tool works): Two security experts manually reviewed 200 skills to create trusted “ground truth” labels. Against these labels, SkillScan was:
- About 87% precise (when it said something was bad, it was right most of the time),
- About 83% complete (it caught most of the bad things).
These scores, called precision and recall, show the tool is reliable enough for large-scale measurement.
Main Findings and Why They Matter
- Big picture: 26.1% of skills had at least one security problem. That’s roughly 1 in 4 skills.
- Risk categories: The team grouped problems into four easy-to-understand types:
- Prompt injection: Tricking the AI with instructions to ignore rules or do unsafe things.
- Data exfiltration: Sneaking out your data (like passwords, environment variables, source code) to someone else.
- Privilege escalation: Gaining more power than the skill should have (like running as admin).
- Supply chain risks: Pulling in risky dependencies or remote code that can be changed later to do harm.
- Most common issues:
- Data exfiltration (13.3%): Often involved sending information over the internet or reading sensitive files.
- Privilege escalation (11.8%): Often involved “sudo,” changing file permissions, or accessing protected areas.
- High-severity patterns: 5.2% of skills had strong signs of malicious intent (for example, obfuscated code or direct credential harvesting). These are especially concerning.
- Code-containing skills are riskier: Skills that include executable scripts were about 2.1 times more likely to be vulnerable than instruction-only skills. That’s like saying an app with built-in tools that can run commands is more dangerous than an app that only gives written advice.
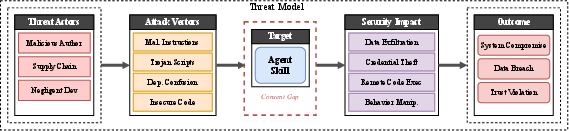
- The “consent gap”: Once users install a skill, it often gets broad permissions (like reading and writing files) without ongoing checks. This mismatch between what users think they approved and what the skill can actually do makes attacks easier.
Why this matters: Agent skills are spreading fast and are often trusted by AI tools with minimal vetting. If unsafe skills are common, users’ data and systems could be at risk without them realizing it.
Implications and Potential Impact
- Platforms need better guardrails: The paper argues for stricter permission systems (only allow the exact capabilities a skill truly needs) and mandatory security reviews before listing skills in marketplaces.
- Developers should follow secure practices: Avoid risky patterns (like running remote scripts blindly), pin dependencies, minimize permissions, and clearly document what a skill does.
- Users should be cautious: Install skills from trusted sources, review what permissions they ask for, and prefer instruction-only skills when possible.
- Researchers and maintainers get tools and data: The authors released an open dataset and their detection toolkit so others can improve defenses, set standards, and keep ecosystems safer.
- Long-term safety: As AI agents become more capable, unsafe skills could be a major attack route. Fixing this early helps prevent widespread problems later.
In short: Agent skills make AI more powerful, but they also open doors for misuse. This study shows the risks are real and common, and it offers practical steps—better permissions, vetting, and tooling—to make the ecosystem safer for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future research can address to strengthen the paper’s findings and improve security for agent skills.
- Longitudinal ecosystem dynamics: quantify how vulnerability prevalence evolves over time and measure removal/retroactive moderation to correct survivorship bias introduced by 404/deleted skills.
- Ecosystem coverage: expand beyond two marketplaces to include platform-native registries, enterprise/private skill repositories, and other ecosystems (e.g., MCP servers), enabling cross-platform comparisons of guardrails and risk.
- Non-English skills: assess vulnerability rates and detection performance on non-English content, including machine-translated scanning pipelines and Unicode/internationalization edge cases.
- Intent vs. capability: develop criteria and tests to distinguish legitimate security/red-team functionality from malicious intent, including dynamic validation and curated ground truth of confirmed-malicious vs. benign-but-dangerous skills.
- Runtime validation: execute flagged skills in instrumented sandboxes across major agent frameworks to verify actual exploitability under real permission models and runtime policies.
- Consent gap measurement: run user studies and telemetry analyses to quantify consent fatigue, prompt design effectiveness, and mismatch between declared permissions and runtime actions.
- Multivariate risk modeling: perform adjusted analyses (e.g., logistic regression) controlling for skill category, script presence, author reputation, and marketplace to isolate confounders behind the reported OR=2.12.
- Popularity-weighted exposure: weight vulnerability prevalence by downloads/installs and activation frequency to estimate real user risk and prioritize remediation.
- Author risk profiling: leverage collected publisher metadata (account age, followers, repo history) to identify risk indicators (e.g., new/throwaway accounts, sudden behavior shifts) and detect supply-chain compromises.
- Supply-chain depth: analyze transitive dependencies, update channels, and remote fetch mechanisms; quantify pinning practices and measure compromise/typosquatting rates in dependency graphs.
- Detection coverage gaps: extend exfiltration detection beyond HTTP to DNS, SMTP, WebSockets, gRPC, cloud SDKs (e.g., S3, GCS), and covert channels; broaden privilege-escalation patterns for Windows (PowerShell, registry edits) and macOS (launchd, TCC).
- Static analysis enhancements: incorporate AST/CFG-based analysis, taint tracking from sensitive sources (env, ~/.ssh, secrets files) to sinks (network, logs, responses), and command-construction detection beyond regex.
- LLM dependency and variability: benchmark detection across multiple models/vendors/versions, quantify run-to-run and prompt sensitivity, and provide deterministic fallback rules for reproducibility.
- Ground truth scale and balance: expand manual annotations well beyond n=200, ensure per-category statistical power, and include cross-validation with external experts (e.g., marketplace security teams).
- Known-incident validation: test SkillScan against a labeled set of confirmed malicious skills (e.g., ransomware-delivery examples) to measure true positive/false negative rates on real attacks.
- Skill chaining and multi-agent effects: investigate vulnerabilities emerging from interactions between multiple skills, cascaded permissions, and multi-tenant contexts not covered in the current threat model.
- Environment-specific exploitability: evaluate flagged patterns under diverse OSes, containerized runtimes, corporate EDR/AV, and agent-specific sandboxes to separate theoretical from practical risk.
- Marketplace vetting efficacy: design and experimentally evaluate pre-publication security checks (precision/recall, operational cost), including mandatory permission audits and automated static/semantic scans.
- Capability-based permissions: prototype and A/B test granular permission systems (least privilege, time-bounded consent, per-action prompts), measuring exploit reduction vs. usability impact.
- Reproducibility and auditability: document how model updates affect detection outputs, provide version-pinned pipelines, and publish deterministic rule sets to ensure consistent results over time.
- Documentation vs. runnable content: develop methods to separate dangerous examples/snippets in SKILL.md from executable instructions and enforce policies that prevent example code from being executed by default.
- Deduplication effects: quantify how script deduplication influenced per-skill attribution and ensure context-aware analysis that preserves instruction-script linkages when identical scripts appear across skills.
- Covert and staged payloads: add detectors for encrypted blobs, steganography, polyglot files, staged downloads (curl|bash chains with indirection), and delayed/time-bomb execution conditions.
- Cross-lingual obfuscation and Unicode abuse: improve detection of mixed-script content, homoglyph attacks, zero-width/invisible characters, and RTL/LTR overrides in both instructions and code.
- Impact quantification: map skill vulnerabilities to standardized severity (e.g., CVSS-like scoring for skills), enumerate data types at risk (credentials, code, customer data), and prioritize remediation pathways.
- Operationalization at scale: assess pipeline throughput, cost, and scheduling for continuous marketplace monitoring; define alerting, triage, and remediation workflows with platform maintainers.
- Responsible disclosure outcomes: track the number of reported high-severity skills, platform responses, time-to-remediation, and post-removal re-uploads to measure practical impact of disclosures.
Glossary
- Agent skills: Modular packages that extend AI agents with instructions and executable code. Example: "AI agents increasingly rely on modular capability extensions called agent skills."
- Attack surface: The total set of points where an attacker could try to exploit a system. Example: "creating a significant yet uncharacterized attack surface."
- Cohen’s κ (kappa): A statistic measuring inter-annotator agreement beyond chance. Example: "Cohen's = 0.83"
- Confidence intervals: Ranges that quantify the uncertainty of an estimated metric. Example: "We computed 95\% confidence intervals using the Wilson score method"
- Consent fatigue: User desensitization to frequent permission prompts, leading to less careful approval. Example: "runtime prompts suffer from consent fatigue"
- Consent Gap: The mismatch between what users think they have approved and what a component actually does. Example: "The Consent Gap. All three adversary types exploit a common enabler: the mismatch between what users approve and what skills actually do."
- CVE: Common Vulnerabilities and Exposures; standardized identifiers for publicly known security flaws. Example: "24 CVEs"
- Data exfiltration: Unauthorized extraction of sensitive information to an external destination. Example: "Data exfiltration (13.3\%)"
- Deduplication: The process of removing duplicate items to retain unique instances. Example: "After filtering and deduplication, we analyzed 31,132 unique skills"
- Dependency confusion: A supply-chain attack where a malicious package with the same name as an internal dependency is installed. Example: "dependency confusion"
- Dynamic loading: Loading components or code at runtime rather than at install/compile time. Example: "community-developed, dynamically loaded, broad permissions."
- F1 score: The harmonic mean of precision and recall, summarizing a classifier’s accuracy. Example: "F1 ."
- Ground truth: Manually verified labels used as the authoritative reference for evaluation. Example: "ground truth dataset"
- Inter-method reliability: The consistency of results across different measurement or labeling methods. Example: "indicating excellent inter-method reliability."
- Inverse probability weighting (IPW): A reweighting technique to correct for sampling bias. Example: "we apply inverse probability weighting (IPW):"
- Jailbreak attacks: Techniques that coerce LLMs into bypassing safety controls. Example: "jailbreak attacks"
- Lateral movement: An attacker’s progression within a network to access additional systems and data. Example: "lateral movement"
- LLM-Guard: A toolkit of security scanners for LLM inputs/outputs used to detect risky content. Example: "LLM-Guard's semantic classifiers"
- LLM-based semantic classification: Using LLMs to interpret context and categorize content beyond simple pattern matching. Example: "integrating static analysis with LLM-based semantic classification."
- Model Context Protocol (MCP): A protocol that organizes tools, resources, and prompts for model-centric applications. Example: "The Model Context Protocol (MCP) extends this pattern with tools, resources, and prompts as primitives"
- Odds Ratio (OR): A statistic quantifying the strength of association between exposure and outcome. Example: "Odds Ratio [OR]=2.12, "
- OWASP Top 10 for Agentic Applications: A curated list of the most critical security risks for agent-based systems. Example: "The OWASP Top 10 for Agentic Applications"
- Precision-recall tradeoff: The balance between identifying relevant positives and avoiding false alarms. Example: "The precision-recall tradeoff (precision +15.3pp, recall 8.7pp)"
- Privilege escalation: Gaining higher access rights than intended, often to perform unauthorized actions. Example: "privilege escalation (11.8\%)"
- Progressive disclosure: A staged loading approach that reveals more information or capability only as needed. Example: "The architecture uses progressive disclosure"
- Prompt injection: Crafting inputs that manipulate an LLM/agent to follow malicious instructions. Example: "prompt injection"
- Responsible disclosure: Reporting vulnerabilities to maintainers in a coordinated, ethical manner before public release. Example: "responsible disclosure practices"
- Static code analysis: Examining code without executing it to detect vulnerabilities or risky patterns. Example: "static code analysis"
- Stratified sample: A sampling method that ensures representation across defined subgroups. Example: "stratified sample of 1,218 skills"
- Supply chain risks: Security threats arising from dependencies, external packages, or upstream components. Example: "supply chain risks"
- Survivorship bias: Bias introduced by analyzing only items that remain after some have been removed or failed. Example: "survivorship bias"
- Threat model: An explicit description of assumed adversaries, their capabilities, and targeted assets. Example: "Threat model: attack vectors, vulnerabilities, and security impacts for agent skills."
- Tool poisoning: Tampering with or providing malicious tools/services to influence an agent’s behavior. Example: "tool poisoning"
- Unpinned dependencies: Dependencies without fixed version constraints, increasing the risk of malicious updates. Example: "unpinned dependencies"
- Wilson score method: A statistical technique for computing confidence intervals for binomial proportions. Example: "Wilson score method"
Practical Applications
Overview
Based on the paper’s large-scale measurement, taxonomy, and SkillScan detection pipeline, the following are practical, real‑world applications organized by time horizon. Each item notes sectors, potential tools/products/workflows, and key assumptions/dependencies that could affect feasibility.
Immediate Applications
- Marketplace pre‑publication vetting and risk labeling
- Sectors: AI platforms, app stores/marketplaces, software distribution
- What to do: Integrate SkillScan (or equivalent) into submission CI to auto‑scan SKILL.md and bundled scripts; quarantine or require human review for high‑severity patterns; display standardized risk labels (e.g., “Exfiltration patterns detected”) and permission summaries on listing pages.
- Tools/products/workflows: Submission CI hooks; “Skill Risk Dashboard”; automated triage queues; daily re‑scans for drift.
- Assumptions/dependencies: Access to source/bundles; acceptable false‑positive rate (precision ≈86.7%); legal terms allow content scanning; operational budget for human reviewers.
- Enterprise AI skill allowlisting and deployment gates
- Sectors: Finance, healthcare, government, tech enterprises (CISOs, DevSecOps)
- What to do: Maintain a centrally approved list of skills; enforce pre‑deployment scanning in CI/CD; block skills with unpinned dependencies, sudo usage, or curl|bash; require dependency pinning and signed releases.
- Tools/products/workflows: Policy‑as‑code guardrails (e.g., OPA), GitHub Actions/GitLab CI scanning jobs, internal artifact registries, agent runtime egress policies.
- Assumptions/dependencies: Ability to route installs via internal registries; buy‑in from platform teams; compatible licensing for mirroring skills.
- Runtime containment for agent processes
- Sectors: IT/security operations, managed security providers
- What to do: Run agents and skills in containers/VMs with file system scopes, read‑only mounts, and egress allowlists; add process monitoring for HTTP POSTs, env var access, and sudo; prioritize extra scrutiny for skills with bundled scripts (2.12× higher odds of vulnerabilities).
- Tools/products/workflows: Container/AppArmor/SELinux profiles; eBPF sensors; SIEM detections mapped to the 14 patterns.
- Assumptions/dependencies: Sufficient observability; acceptable performance overhead; consistent process labeling for agent components.
- Consent‑gap UX hardening in agent products
- Sectors: Product management, UX for AI tools
- What to do: Replace blanket “install once, trust forever” flows with granular, just‑in‑time prompts tied to concrete actions (e.g., “send 3 files to example.com”); time‑bound privileges; explicit network destination previews; progressive disclosure aligned to the platform’s permission model.
- Tools/products/workflows: Permission scope UI; runtime consent prompts; telemetry for consent fatigue analytics.
- Assumptions/dependencies: Engineering capacity; willingness to trade some friction for safety; clear permission taxonomy.
- Developer‑side linting and pre‑commit hygiene
- Sectors: Software development, DevSecOps, open‑source maintainers
- What to do: Provide linters for SKILL.md and scripts that enforce least‑privilege permissions, pinned dependencies, and ban patterns (curl|bash, eval/exec); adopt secure templates and checklists derived from the taxonomy.
- Tools/products/workflows: Pre‑commit hooks; VS Code extensions; Semgrep rules tuned to agent skills; repo templates.
- Assumptions/dependencies: Community adoption; rule set maintenance; compatibility with diverse build systems.
- Vendor procurement and compliance controls for AI agents
- Sectors: Regulated industries (HIPAA, SOX, PCI), procurement/legal
- What to do: Require scan reports, SBOMs, signature/attestation, and dependency pinning for any third‑party skills; add contractual clauses for patch SLAs and disclosure; align with OWASP Agentic Top 10.
- Tools/products/workflows: Security questionnaires; bidirectional attestation (Sigstore/SLSA); audit evidence collection.
- Assumptions/dependencies: Supplier cooperation; standardized reporting formats.
- Threat hunting and SOC content for agent ecosystems
- Sectors: SOC/MSSP, threat intel
- What to do: Build detections from the 14 patterns (e.g., anomalous env var harvesting, unexpected external POSTs) and enrich with author/repo metadata; focus hunts on new or recently updated skills and on those bundling executables.
- Tools/products/workflows: Sigma rules; enrichment pipelines; watchlists for newly listed skills and suspicious publishers.
- Assumptions/dependencies: Indexed logs from agent hosts; baseline profiles.
- Academic benchmarks and replication studies
- Sectors: Academia, security research
- What to do: Use the open dataset and SkillScan toolkit as benchmarks; run cross‑ecosystem comparisons (skills vs. MCP servers); reproduce precision/recall; study error modes (dynamic URLs, natural‑language obfuscation).
- Tools/products/workflows: Public leaderboards; shared evaluation harnesses; teaching modules/labs.
- Assumptions/dependencies: Continued access to artifacts; IRB for studies involving potentially harmful code.
- Red‑team test suites for agent platforms
- Sectors: Security consulting, platform assurance
- What to do: Package the 14 patterns into automated adversarial test cases to validate platform defenses (sandboxing, permissions, consent prompts) without relying on live marketplace risk.
- Tools/products/workflows: Synthetic malicious skills; CI “chaos security” jobs; regression suites across platform releases.
- Assumptions/dependencies: Safe test environments; vendor coordination to avoid cross‑tenant impact.
- User‑level safe usage guidance
- Sectors: Daily users, SMEs, educators
- What to do: Recommend installing from trusted publishers; prefer instruction‑only skills when possible; review permissions; run agents in sandboxed profiles; disable network access by default; snapshot/rollback environments.
- Tools/products/workflows: “Skill Sandbox Launcher” scripts; plain‑language checklists; school/enterprise awareness campaigns.
- Assumptions/dependencies: User willingness and basic technical literacy.
- Cyber insurance underwriting adjustments
- Sectors: Insurance, risk management
- What to do: Incorporate controls (pre‑scan, containerization, egress controls, attestation) into underwriting; incentivize marketplaces that enforce vetting; leverage prevalence baselines (e.g., ≈26.1% with at least one vulnerability) to calibrate risk.
- Tools/products/workflows: Control questionnaires; premium credits for verified controls.
- Assumptions/dependencies: Reliable attestations; auditor expertise in AI agent risk.
Long‑Term Applications
- Capability‑based permission systems for agents and skills
- Sectors: AI platforms, OS vendors, security architecture
- What to build: Fine‑grained, revocable capabilities (file paths, network destinations, tool scopes) enforced at runtime; default‑deny with just‑in‑time, time‑boxed grants; policy portability across platforms.
- Tools/products/workflows: Capability brokers; policy compilers; standardized permission manifests in SKILL.md.
- Assumptions/dependencies: Cross‑vendor standardization; acceptable overhead; backward compatibility for existing skills.
- Skill notarization, signing, and provenance (SLSA/Sigstore)
- Sectors: Marketplaces, open‑source, compliance
- What to build: Reproducible builds, signed artifacts, tamper‑evident provenance, and “skill SBOMs” with pinned dependencies; mandatory notarization for marketplace publication.
- Tools/products/workflows: Sigstore‑based signing; SPDX‑like SBOM format for agent skills; attestation validators in runtimes.
- Assumptions/dependencies: Ecosystem consensus; CA infrastructure; incentives for maintainers.
- Behavior‑aware runtime sandboxes with policy enforcement
- Sectors: Endpoint/cloud security, platform engineering
- What to build: eBPF/WASM‑based monitors to enforce policies (e.g., no outbound to unknown domains, no access to ~/.ssh) and detect anomalous sequences; risk‑adaptive throttling.
- Tools/products/workflows: Declarative policies; behavioral baselines; auto‑remediation playbooks.
- Assumptions/dependencies: Kernel features; tuning to manage false positives and latency.
- Dynamic analysis pipelines for skill vetting at scale
- Sectors: Marketplaces, research labs, vendors
- What to build: Instrumented sandboxes to observe runtime exfiltration, delayed execution, and dynamic URL construction (error modes noted in the paper) under realistic stimuli.
- Tools/products/workflows: Deterministic harnesses; network sinkholes; malicious behavior scoring.
- Assumptions/dependencies: Realistic input generation; evasion‑resistant instrumentation; compute costs.
- Specialized ML models for semantic risk classification
- Sectors: Security vendors, academia
- What to build: Fine‑tuned models on the open dataset to improve precision/recall beyond generic LLM‑Guard; model‑based triage that combines code, instructions, and metadata (author history).
- Tools/products/workflows: Continual learning pipelines; ensemble with static rules; explanation tooling for auditor trust.
- Assumptions/dependencies: High‑quality labels; drift management; inference cost control.
- Standardized consent UX and “risk‑adaptive prompting” protocols
- Sectors: HCI, platform UX, standards bodies
- What to build: Cross‑platform UX standards that mitigate consent fatigue (contextual prompts, intent previews, progressive disclosure), backed by user studies and measurable safety gains.
- Tools/products/workflows: UX pattern libraries; usability benchmarks; certification badges.
- Assumptions/dependencies: Vendor alignment; rigorous HCI research; localization.
- Cross‑platform publisher reputation and registry federation
- Sectors: Marketplaces, trust/reputation systems
- What to build: Unified publisher identities, reputation scores, and revocation across registries; optional on‑chain attestations for transparency; coordinated abuse response.
- Tools/products/workflows: Reputation APIs; revocation propagation; “trust tiers” for skills.
- Assumptions/dependencies: Governance and anti‑gaming controls; privacy/legal considerations.
- Sector‑specific compliance profiles and certifications
- Sectors: Healthcare (HIPAA), finance (GLBA/PCI), government (FedRAMP)
- What to build: Predefined permission profiles and logging requirements; certification schemes for “HIPAA‑ready” or “PCI‑ready” skills/agents; audit‑friendly defaults.
- Tools/products/workflows: Control catalogs; conformity assessments; continuous monitoring integrations.
- Assumptions/dependencies: Regulator engagement; accredited assessors; clear scoping (data boundaries).
- Safety frameworks for agent skills in robotics/OT
- Sectors: Robotics, manufacturing, energy, IoT
- What to build: Physical‑action gating tied to verified intent; interlocks; digital‑twin validation for high‑risk actions; dual‑channel approvals for privileged tasks.
- Tools/products/workflows: Action simulators; hazard analysis tooling; runtime policy co‑processors.
- Assumptions/dependencies: Domain‑specific risk models; latency constraints; fail‑safe designs.
- Policy and regulatory baselines for agent ecosystems
- Sectors: Public policy, standards organizations
- What to build: Baseline marketplace vetting requirements; disclosure and recall obligations; vulnerability reporting mandates; liability frameworks for negligent distribution.
- Tools/products/workflows: Model regulations; conformity assessment schemes; public dashboards of ecosystem health.
- Assumptions/dependencies: Legislative timelines; stakeholder consensus; international harmonization.
- Education, certification, and workforce development
- Sectors: Higher education, professional training
- What to build: Curricula on agent skill security; secure‑by‑design patterns; hands‑on labs using the dataset; developer/operator certifications.
- Tools/products/workflows: MOOCs; CTFs; capstone projects; continuing education credits.
- Assumptions/dependencies: Access to safe datasets/labs; industry sponsorship.
- OS‑level “Agent Quarantine Mode” for personal computing
- Sectors: Operating systems, endpoint vendors
- What to build: One‑click sandbox profiles that constrain agent processes (filesystem/network scopes, ephemeral creds), with time‑boxed exceptions and easy rollbacks.
- Tools/products/workflows: OS policy templates; guided wizards; restore points.
- Assumptions/dependencies: OS vendor buy‑in; usability research; minimal performance impact.
Notes on feasibility across items:
- Many immediate applications rely on the paper’s validated pipeline and taxonomy; precision/recall and the “security‑conservative” aggregation imply some false positives that require manual review capacity.
- Long‑term directions generally depend on cross‑vendor standardization (permission schemas, SBOM formats, signing/attestation) and usability research to avoid consent fatigue while providing real protection.
- Dynamic/runtime solutions must balance detection power with latency and false‑positive rates to be viable in production.
Collections
Sign up for free to add this paper to one or more collections.